







Linux命令三剑客之AWK
1、基本用法
1.1 AWK 简介
AWK 是一种强大的文本处理工具,逐行扫描数据,从第一行到最后一行,寻找匹配的特定模式,并在这些行上进行指定的操作。如果没有指定处理动作,则匹配的行会被显示到标准输出(屏幕)。如果没有指定模式,则所有被操作所指定的行都会被处理。
1.2 数据来源
AWK 的数据来源可以是:
- 标准输入
- 管道
- 文本文件
1.3 命令格式
AWK 的命令格式为:awk [-F field-separator] 'commands' [input-file(s)]
其中:
* `-F` 是用来指定分隔符的。
* `commands` 是在逐行处理时所要执行的动作,通常包括处理行的特定模式。
* `input-file(s)` 是要处理的文件。例如:`awk -F: '/root/' /etc/passwd` 或 `awk '{print $1,$3}' filename`。
1.4 内部变量
AWK 有许多内部变量,包括:
$0(保存当前行的内容)NR(记录号,每处理完一条记录,NR 值加 1)NF(保存记录的字段数)FS(输入字段分隔符,默认是空格)OFS(输出字段分隔符)等。
2、AWK 工作原理
AWK 在处理文件时,首先会逐行读取文件内容,然后根据所指定的模式进行匹配,并且对匹配成功的行执行相关的操作。如果未指定行分隔符,AWK 将使用内置变量 FS 的值作为默认的行分隔符。当 AWK 处理完一行后,会将这一行分解成若干字段(或域),每个字段存储在已编号的变量中,编号从 $1 开始,最多达 100 个字段。然后根据所指定的操作进行相应的处理。
3、awk 流程控制
除了简单的逐行处理,AWK 还提供了更为复杂的流程控制语句,包括赋值、条件、循环和数组等。
3.1 赋值
awk -F: 'BEGIN{a="HELLO"}{print a,$1}' /etc/passwd
3.2 条件 if…else if…else 语句
awk -F: '{if($3==0){i++} else if($3>499){k++} else{j++}} END{print "管理员个数: "i; print "普通用个数: "k; print "系统用户: "j}' /etc/passwd
3.3 循环 while 和 for
awk -F: '{i=1; while(i<=10) {print $0; i++}}' /etc/passwd # 将每行打印 10 次 while 循环实现
awk -F: '{for(i=1;i<=10;i++) print $0}' /etc/passwd # 将每行打印 10 次 for 循环实现
3.4 数组
awk -F: '{a[$NF]++} END{for(i in a) {print i,a[i]} }' /etc/passwd # 统计每个用户的出现次数
3.5 控制语句
控制语句包括
break(结束当前的循环体)continue(中止本次循环,转入下一次循环)next(跳过当前行,读入下一行文本)
例如:awk -F: '{break if($1==0)}' filename。
4、常用内置函数
在AWK中,还有一些常用的内置函数,可以帮助你处理和操作数据。
4.1 字符串切割
split(String, A, [Ere] ) 返回切割后的数组长度
- String : 待切割的字符串
- A:切割完后的数组
- Ere:分隔符
4.2 字符串(数组)长度
length (string)
4.3 转化大小写
tolower(string) 转化为小写
toupper(string) 转化为大写
4.4 截取子串
substr( String, M, [ N ] )
4.5 获取子串位置
index( String1, String2 )
4.6 输出格式化字符串
printf()
4.7 查找子串
match( String, Ere )
5. 高级用法
5.1 引用外部变量
awk -F: -v user=$LOGNAME '$1 == user' /etc/passwd

5.2 多个分隔符
awk -F '[:/]' '{print $1,$3}' /etc/passwd
5.3 执行shell语句
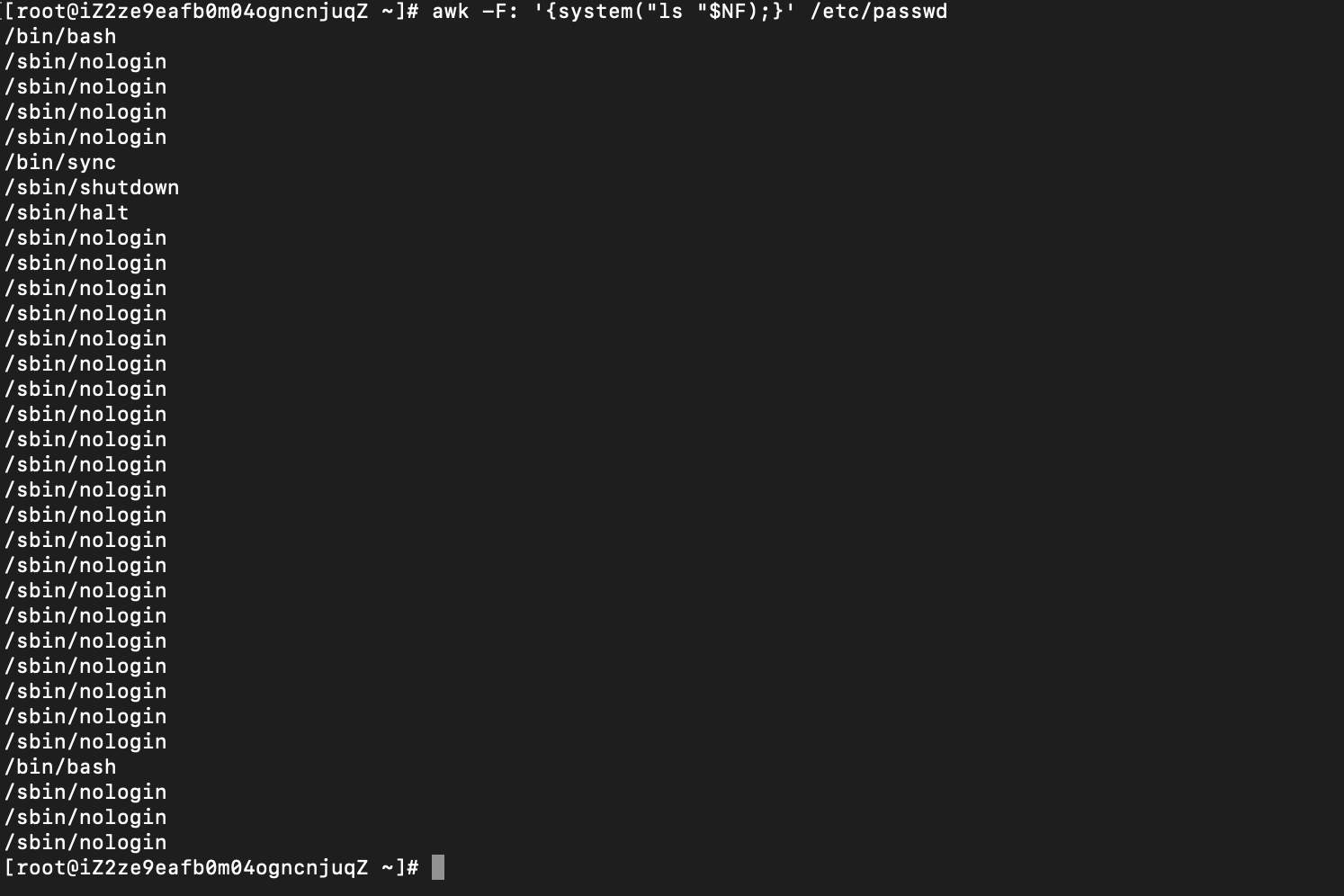
awk -F: '{system("ls "$NF);}' /etc/passwd
5.4 FIELDWIDTHS
一旦设置了 FIELDWIDTH 变量,awk 就会忽略 FS 变量,并根据提供的字段宽度来计算字段
echo 123456789 | awk 'BEGIN{FIELDWIDTHS="1 2 3 4"}{print $1,$2,$3,$4}'

5.5 指定记录分隔符
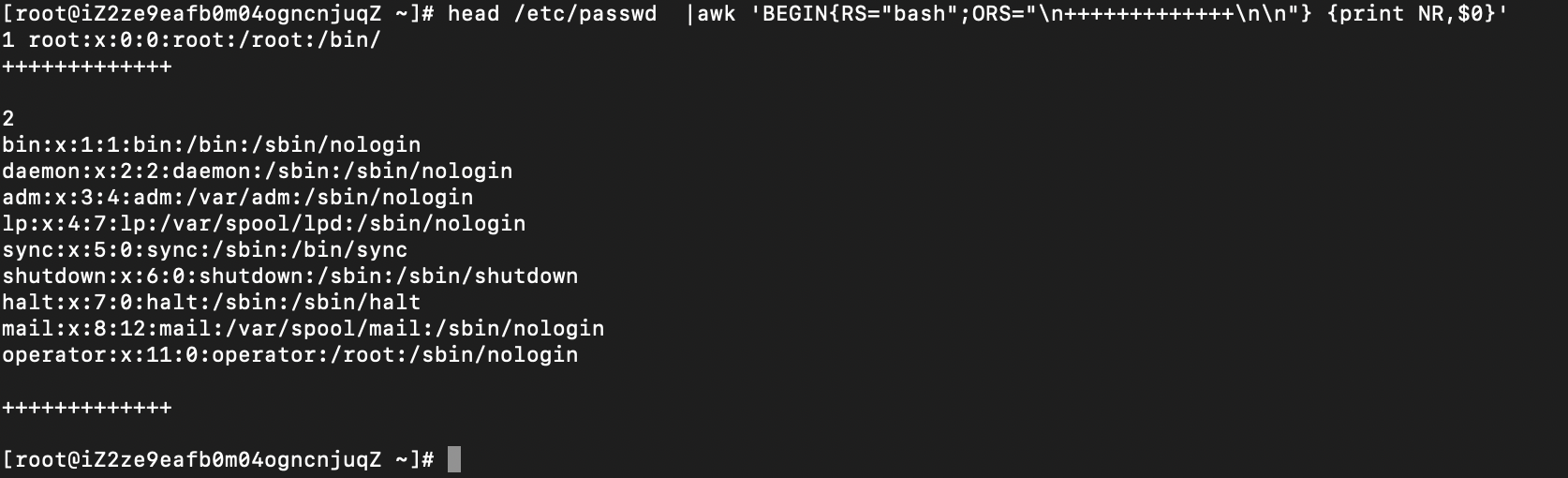
head /etc/passwd |awk 'BEGIN{RS="bash";ORS="\n+++++++++++++\n\n"} {print NR,$0}'
6. awk 实例
6.1 统计每个用户的出现次数
awk -F: '{a[$NF]++} END{for(i in a) {print i,a[i]} }' /etc/passwd

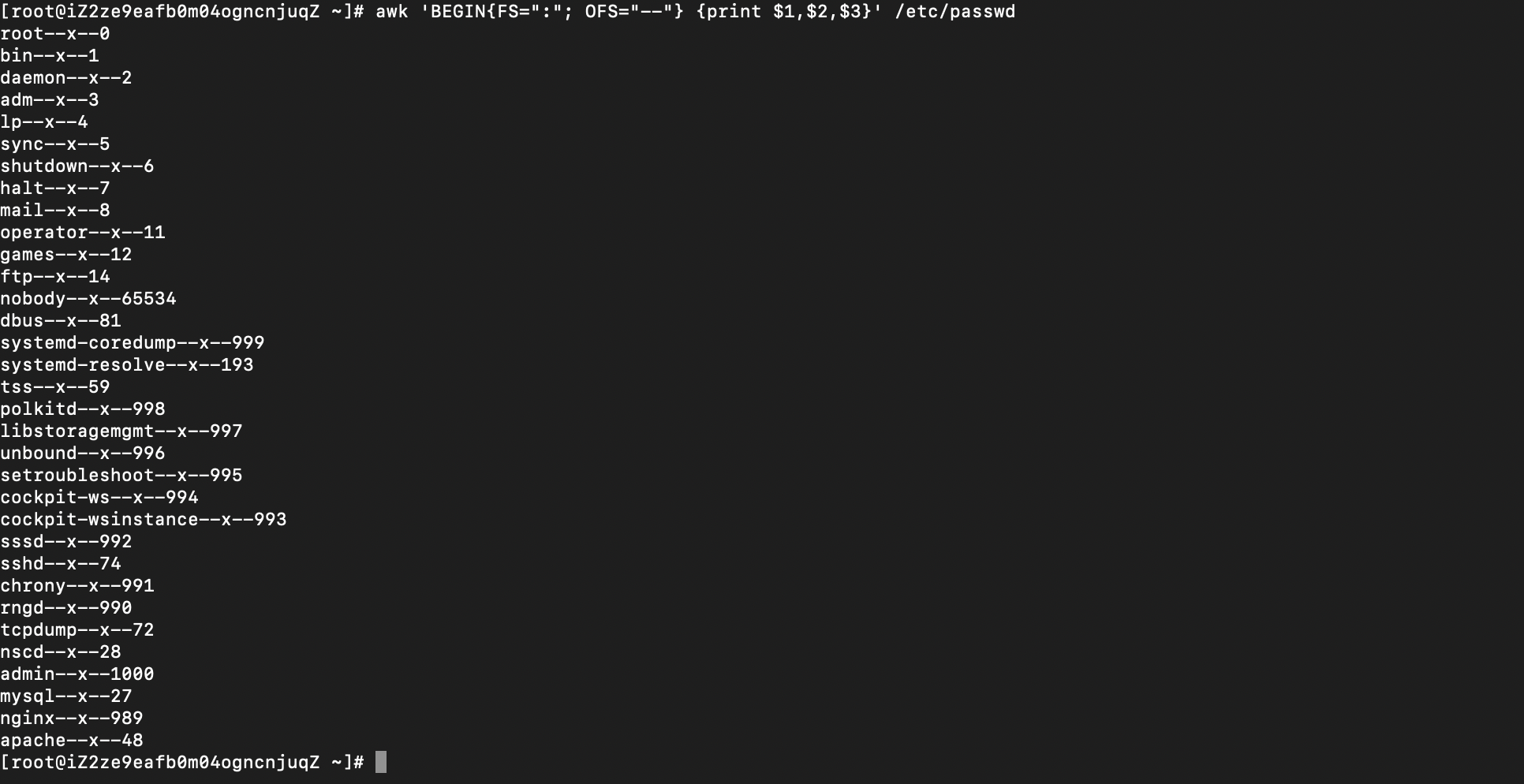
6.2
awk 'BEGIN{FS=":"; OFS="--"} {print $1,$2,$3}' /etc/passwd
awk -F: '!a[$NF]++ {print $0}' /etc/passwd
7. awk 内置函数
| 函数类别 | 函数原型 | 函数功能 |
|---|---|---|
| 数学函数 | atan2(x, y) | x/y 的反正切,x 和 y 以弧度为单位。 |
| – | cos(x) | x 的余弦,x 以弧度为单位。 |
| – | exp(x) | x 的指数函数。 |
| – | int(x) | x 的整数部分,取靠近零一侧的值。 |
| – | log(x) | x 的自然对数。 |
| – | srand(x) | 为计算随机数指定一个种子值。 |
| – | rand() | 比 0 大比 1 小的随机浮点值。 |
| – | sin(x) | x 的正弦,x 以弧度为单位。 |
| – | sqrt(x) | x 的平方根。 |
| 位运算函数 | and(v1, v2) | 执行值 v1 和 v2 的按位与运算。 |
| – | compl(val) | 执行 val 的补运算。 |
| – | lshift(val, count) | 将值 val 左移 count 位。 |
| – | or(v1, v2) | 执行值 v1 和 v2 的按位或运算。 |
| – | rshift(val, count) | 将值 val 右移 count 位。 |
| – | xor(v1, v2) | 执行值 v1 和 v2 的按位异或运算。 |
| 字符串函数 | asort(s[,d]) | 将数组 s 按数据元素值排序。索引值会被替换成表示新的排序顺序的连续数字。另外,如果指定了 d,则排序后的数组会存储在数组 d 中。 |
| – | asorti(s[,d]) | 将数组 s 按索引值排序。生成的数组会将索引值作为数据元素值,用连续数字索引来表明排序顺序。另外如果指定了 d,排序后的数组会存储在数组 d 中。 |
| – | gensub(r, s, h[,t]) | 查找变量 $0 或目标字符串 t(如果提供了的话)来匹配正则表达式 r。如果 h 是一个以 g 或 G 开头的字符串,就用 s 替换掉匹配的文本。如果 h 是一个数字,它表示要替换掉第 h 处 r 匹配的地方。 |
| – | gsub(r, s[,t]) | 查找变量 $0 或目标字符串 t(如果提供了的话)来匹配正则表达式 r。如果找到了,就全部替换成字符串 s。 |
| – | index(s, t) | 返回字符串 t 在字符串 s 中的索引值,如果没找到的话返回 0。 |
| – | length([s]) | 返回字符串 s 的长度;如果没有指定的话,返回 $0 的长度。 |
| – | match(s, r[,a]) | 返回字符串 s 中正则表达式 r 出现位置的索引。如果指定了数组 a,它会存储 s 中匹配正则表达式的那部分。 |
| – | split(s, a[,r]) | 将 s 用 FS 字符或正则表达式 r(如果指定了的话)分开放到数组 a 中,并返回字段的总数。 |
| – | sprintf(format, variables) | 用提供的 format 和 variables 返回一个类似于 printf 输出的字符串。 |
| – | sub(r, s[,t]) | 在变量 $0 或目标字符串 t 中查找正则表达式 r 的匹配。如果找到了,就用字符串 s 替换掉第一处匹配。 |
| – | substr(s, i[,n]) | 返回 s 中从索引值 i 开始的 n 个字符组成的子字符串。如果未提供 n,则返回 s 剩下的部分。 |
| – | tolower(s) | 将 s 中的所有字符转换成小写。 |
| – | toupper(s) | 将 s 中的所有字符转换成大写。 |
| 时间函数 | mktime(datespec) | 将一个按 YYYY MM DD HH MM SS [DST] 格式指定的日期转换成时间戳值。 |
| – | strftime([format[,timestamp]]) | 将时间戳值 timestamp 转换成一个字符串,格式由 format 指定。如果未提供 timestamp,则使用当前时间。 |
| – | systime() | 返回当前时间的时间戳值。 |















 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









