




 本文介绍了当前流行的LLMs模型,如LLaMA、BLOOM和GLM,以及它们的训练数据集和优化策略。Alpaca、Vicuna和BELLE等数据集用于增强对话理解和多轮交互能力。此外,文章还提到了不同领域的应用,如医疗、金融和教育,并讨论了分布式训练和量化的重要性。
本文介绍了当前流行的LLMs模型,如LLaMA、BLOOM和GLM,以及它们的训练数据集和优化策略。Alpaca、Vicuna和BELLE等数据集用于增强对话理解和多轮交互能力。此外,文章还提到了不同领域的应用,如医疗、金融和教育,并讨论了分布式训练和量化的重要性。
本篇文章整理下目前常用的LLMs模型们和数据集简介。
BackBones
https://github.com/FreedomIntelligence/LLMZoo
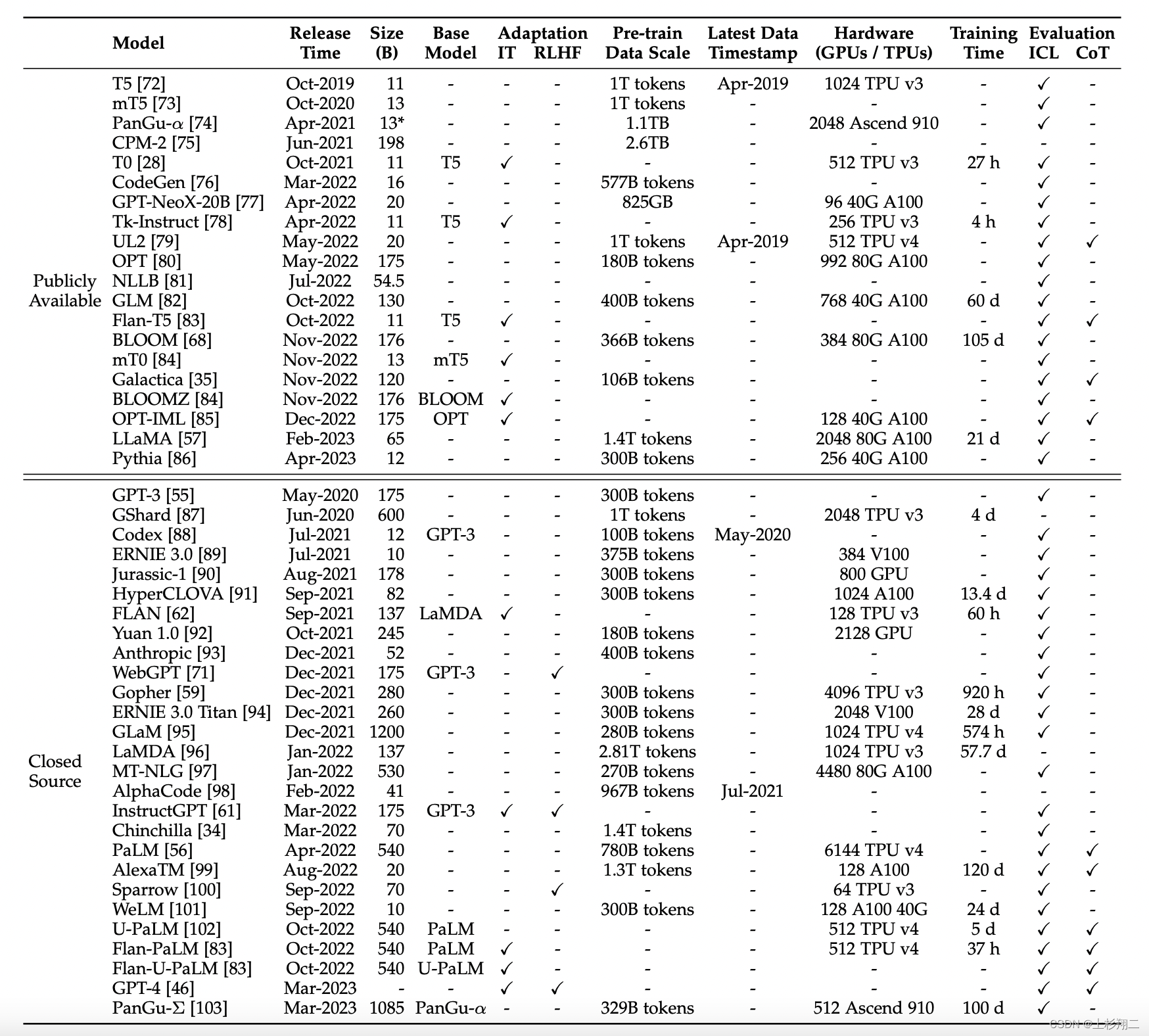
可以看到目前被广泛用来作为LLMs的backbone的模型有以下特点:
- Backbone:基于某个开源backbone,如GLM、LLaMA、BLOOMZ(GPT-style)
- Datasets:分为两类Instruction、Conversation
- Tuning Strategies:分为两类SFT、RLHF
- Optimization:开源项目参数规模一般都不是很大,Params 6/7B、13B
LLaMA:
- Meta AI 。
- 7B、13B、33B 和 65B。
- 使用比通常更多的 tokens 训练一系列语言模型,以证明在相对较小的模型上使用大规模数据集训练能达到更好性能 。一般推荐在 200B tokens 上训练 10B 规模的模型,而 LLaMA 使用了 1.4T 和1T tokens 训练模型。

BLOOM:
- BigScience。
- 176B、560M、1.1B、1.7B、3B、7.1B 。
- BLOOM支持46种自然语言和13种编程语言,BLOOMZ(instruction tuning)。
GLM:
- 清华、智谱。
- 130B。
- GLM 预训练方式:自回归的空白填充,将单双向注意力同时引入模型。当使用[MASK]时,GLM同BERT和T5;当使用[gMASK]时,GLM类似于PrefixLM。
- ChatGLM。类似GLM-130B ,在6B参数上经过约 1T tokens的中英双语训练,辅以SFT、RLHF。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/972d4c957b94b2ee63e49c1132709f5a.png#pic_center)
LLaMA、BLOOMZ、ChatGLM是被开源社区fine-tune最多的backbones,当然也有完全自研的框架。
- ChatYuan。元语智能,基于T5,基于PromptClue进行SFT。
- Colossal AI。SFT、RM和RLHF的完整框架,backbone可选GPT2、OPT和BLOOM。
- DeepSpeedChat :微软基于DeepSpeed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,如13B模型只需训1.25小时。
- 其他:对标GPT4多模态能力的OpenFlamingo、LLaVA等等。
Datasets
Fine-tune数据集主要来源:
- ChatGPT/GPT4。
- 共享数据。
- 其他:已有数据集造数据、纯人工标数据。
Alpaca:
- 斯坦福大学。
- 基于LLaMA-7B/13B + instruction-following
- 数据来源于利用 OpenAI 的 text-davinci-003 模型以 self-instruct方式(Instruction Tuning 在 LLM 上性能极限的探究 )生成 52K 的数据,然后以有监督的方式训练 LLaMA。

Alpaca主要支持英文任务,目前逐渐被扩展到:韩语羊驼KoAlpaca,日语羊驼 Japanese-Alpaca-LoRA,中文则是 Chinese-Vicuna(小羊驼)、 Luotuo(骆驼)等等。
{
"instruction": "What are the three primary colors?", #描述了模型应该执行的任务。
"input": "", #可选上下文或输入。例如,当指令是“总结以下文章”时,输入就是文章。
"output": "The three primary colors are red, blue, and yellow." #答案
}
Vicuna:
- UC伯克利、CMU、斯坦福等。
- 基于LLaMA-7B + conversation-following
- 数据来源于ShareGPT收集的用户共享对话,大约70K对话,使模型能够更好地处理多轮对话和长序列。
{
"id": "identity_0", #多轮对话
"conversations":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5402
5402



 到【灌水乐园】发言
到【灌水乐园】发言








