






从公众号转载,关注微信公众号掌握更多技术动态

---------------------------------------------------------------
一、领域事件
1.领域事件简介
(1)什么是领域事件
举例而言:用户提交一个订单,系统在完成订单保存后,可能还需要发送一个通知,另外可以产生一系列的后台服务的活动。如果把这一系列的动作放入一个处理过程中,会产生几个的明显问题:
一个是订单提交的的事务比较长,性能会有问题,甚至在极端情况下容易引发数据库的严重故障;另外订单提交的服务内聚性差,可维护性差,在业务流程发生变更时候,需要频繁修改主程序。
如果改为事件驱动模式,把订单提交后触发一个事件,在订单保存后,触发订单提交事件。通知和后续的各种服务动作可以通过订阅这个事件,在自己的实现空间内实现对应的逻辑,这样就把订单提交和后续其他非主要活动从订单提交业务中剥离,实现了订单提交业务高内聚和低耦合性。
(2)如何识别领域事件
在做用户旅程或场景分析时,捕捉业务、需求人员或领域专家口中的关键词:“如果发生...则...”、“当做完...的时候,请通知...”、发生...时,则...“等。这些场景发生某种时间后会触发进一步操作,那么这个事件很可能时领域事件。
(3)领域事件的作用
领域事件驱动设计可以切断领域模型之间的强依赖关系,事件发布完成后,发布方不必关系后续订阅方事件处理是否成固,这样可以实现领域模型的解耦,维护独立性和数据一致性。在领域模型映射到微服务系统架构时,领域事件可以解耦微服务,微服务之间的数据不必要求强一致性,而是基于事件的最终一致性。
2.使用领域事件的时机
aggregate是用来保证数据一致性的一个单位,但是如果设计大的aggregate的话,容易产生并发问题和资源浪费等问题。所以我们要尽量设计小的aggregate,但是同时也要解决小aggregate带来的数据一致性问题。
当一个User账号删除后,与User关联的Post也必须删除。我们可以通过事务的方式去保证这个数据的一致性。
class AuthorApplicationService {@Transactionalpublic void deactivateAccount(Long userId){User user = userRepository.findOne(new UserSpecificationById(userId);user.deactivate();userRepository.save(user);Posts posts = postRepository.find(new PostSpecificationByUserId(user.getUserId()));posts.forEach(post -> {post.delete();postRepository.save(post);});}}
然而这种方式不被提倡,aggregate需要保证数据的一致性,自身就代表了一个事务的边界。因此把对多个aggregate的处理放在一个事务中是很不合适的。 这可能会引起并发问题并且导致数据的低效,比如一个拥有很多文章的用户注销的时候,导致对Post的更新很频繁,结果博主想要注销时,可能造成锁等待(悲观锁)或者提交失败(乐观锁)。
而当在一个事务中针对多个aggregate进行更新操作,其实也就是设计了一个大的聚合根,这与设计之初的思想相违背。当你发现自己必须把对多个aggregate的操作放进一个事务,很有可能你的建模是有问题的,应该重新审视自己的模型。
如此提倡小的aggregate设计,而跨aggregate的数据一致性却有又没有有效的手段来保证,那怎么办?
从当数据的一致性只需要达到最终一致的话,DDD提倡利用event的设计模式。event也是解耦的一种常规操作,DDD也借鉴了这个模式来解决数据最终一致的问题。
当我们要对两个aggregate进行操作。两个处理会进行在独立的事务中。当第一个处理完成后,抛出一个event(事件),然后监听event的组件在接受到event后开始第二个操作。
比如上面例子当用户注销后,可以抛出一个UserDeactivatedEvent的事件,监听 UserDeactivatedEvent的组件会在接收到事件后进行文章删除的操作。
如此一来,便可以把处理分拆成两个事务,保证了性能和用户体验,同时也能达成数据的一致性。
当A,B两个处理处在同一个事务中,A,B要么同时成功,要么同时失败。而通过event模式来做的话,A成功的话并不代表B一定会成功。那么B不成功时该怎么办?这会有多种策略
-
不断尝试进行B处理,直到B成功为止。
-
B失败后抛出事件,对A处理进行回滚或者其他挽救处理
结合上边的两种方式,无疑为了实现最终一致性,我们引入了很多复杂度,需要考虑的状况会更多。 另外我们还需要一个事件订阅和分发的系统来帮我们实现这个功能。
Spring Data 1.13后有一个AbstractAggregateRoot 实现了aggregate的抽象类。
其中有一个registerEvent()的方法,可供调用,它是用来创建事件的。注意当调用这个方法是,事件只是被创建,而没有被发布。
class User {private UserId userId;private String email;private String username;private AccountStatus accountStatus;public void deactivate(){accountStatus = AccountStatus.DEACTIVATED;registerEvent(UserDeactivatedEvent(this.userId)); // 创建用户注销的事件}}
在用户注销的方法里,调用刚才提到的regsiterEvent()来创建事件。 而Spring data会在Repository.save()被调用的时候把实现发布出去。
class AuthorApplicationService {@Transactionalpublic void deactivateAccount(Long userId){User user = userRepository.findOne(new UserSpecificationById(userId);user.deactivate();userRepository.save(user); // UserDeactivatedEvent会被发布}}
然后订阅事件部分的实现会是下面这样。
@Servicepublic class PostService {@Autowiredprivate IPostRepository postRepository;@Async@TransactionalEventListenerpublic void handleUserDeactivatedEvent(UserDeactivatedEvent event) {Posts posts = postRepository.find(new PostSpecificationByUserId(event.getUserId()));posts.forEach(post -> {post.delete();postRepository.save(post);});}}
3.不同类型的领域事件
有的领域事件发生在微服务内的聚合之间,有的发生在微服务之间,还有两者皆有的场景,一般来说跨微服务的领域事件处理居多。
(1)微服务内的领域事件
当领域事件发生在微服务内的聚合之间,领域事件发生后完成事件实体构建和事件数据持久化,发布方聚合将事件发布到事件总线,订阅方接收事件数据完成后续业务操作。微服务内大部分事件的结成,都发生在同一个进程内,进程自身可以很好的控制事务,因此不一定需要引入消息中间件。但一个事件如果同时更新多个聚合,就要考虑是否引入事件总线。但微服务内的事件总线,会增加开发难度。微服务内应用服务,可以通过跨聚合的服务编排和组合,以服务调用的方式完成跨聚合的访问,这种方式通常应用于实时性和数据一致性要求高的场景。这个过程会用到分布式事务,保证发布方和订阅方数据同时更新成功。
(2)微服务之间的领域事件
跨微服务的领域事件会在不同的限界上下文或领域模型之间实现业务协作,主要为了实现微服务解耦,减轻微服务之间实时访问的压力。这种场景比较多,事件处理机制也更复杂。跨微服务的事件可以推动业务流程或者数据在不同的子域或微服务间直接流转。跨微服务的事件机制要总体考虑事件构建、发布和订阅、事件数据持久化、消息中间件,甚至事件数据持久化时还要考虑引入分布式事务。
微服务之间的访问也可以采用应用服务直接调用的方式,实现数据的服务的实施访问,弊端就是跨微服务的数据同时变更需要引入分布式事务,这样会影响系统性能,增加服务之间耦合,还是要避免使用分布式事务。
4.领域事件相关案例
保险承保业务。一个保单的生成,经历了很多子域、业务状态变更和跨微服务业务数据的传递。产生了很多领域事件,促成了保险业务数据、对象在不同微服务和子域之间的流转和角色转换。
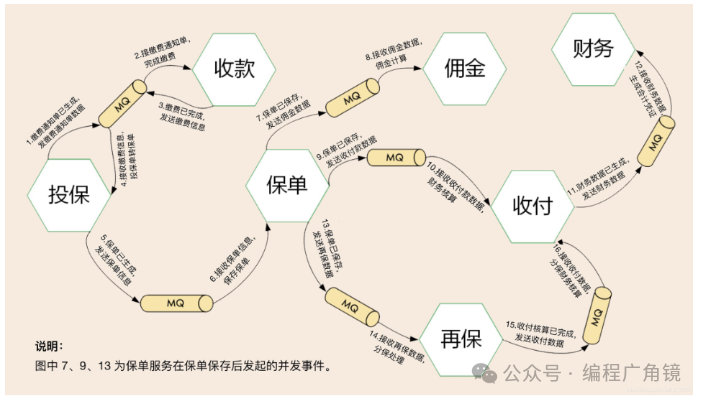
如何用领域事件驱动设计来驱动承保业务流程:
事件起点:客户购买保险 - 业务完成保单录入 - 生成投保单 - 启动缴费动作。
(1)投保微服务生成缴费通知单,发布第一个事件:将缴费通知单数据发布到MQ。收款微服务订阅该MQ,完成缴费操作。缴费通知单已生成,领域事件结束。
(2)收款微服务缴费完成后,发布第二个事件:缴费已完成,将缴费数据发布到MQ。投保微服务收到该MQ并确认缴费完成,完成投保单转保单的操作。缴费已完成,领域事件结束。
(3)投保微服务在投保单转保单完成后,发布第三个事件:保单已生成,将保单数据发布MQ。保单微服务接受到该MQ,完成保单数据保存操作。保单已生成,领域事件结束。
(4)后面还会发生一系列领域事件,并发的将保单数据通过MQ发送到佣金、收付费、和再保等微服务,完成后续所有业务流程。
总之,通过领域事件驱动的异步化机制,可以推动业务流程和数据在各个微服务之间流转,实现微服务解耦。
5.领域事件总体架构
领域事件的执行需要一系列组件和技术做支撑。领域事件处理包括:事件构建和发布、事件数据持久化、事件总线、消息中间件、事件接受和处理等。
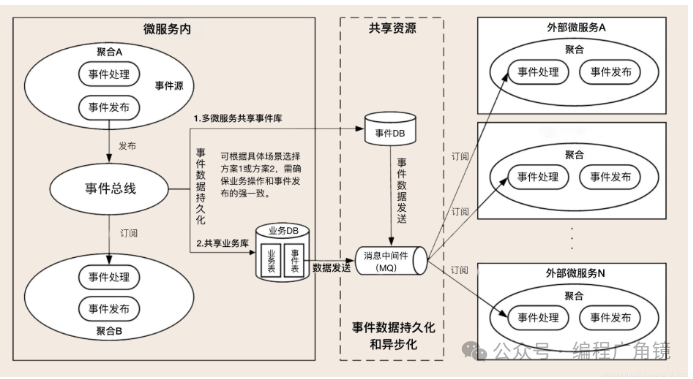
(1)事件构建与发布
事件基本属性至少包括:事件唯一标识、发生时间、事件类型和事件源。事件唯一标识应该是全局唯一的,以便无歧义的在多个限界上下文中传递。事件基本属性记录事件滋生以及事件发生背景的数据。时间还有业务属性,用于记录事件发生时的业务数据,会随事件传输到订阅方。事件基本属性和业务属性一起构成事件实体,事件实体依赖聚合根。领域事件发生后,事件中的业务数据不再修改,因此业务数据可以以序列化值对象的形式保存,这样在MQ中也比较容易解析和获取。

事件发布前要县构建事件实体并持久化。事件发布的方式:可以通过应用服务或领域服务发布到事件总线或者MQ,也可以从事件表中利用定时程序或数据库日志捕捉技术获取增量事件数据,发布到MQ。
(2)事件数据持久化
可用于系统之间的数据队长,或实现发布方和订阅方事件数据的审计。当遇到MQ、订阅方宕机或网络中断,在问题解决后仍可继续后续业务流转,保证数据一致性。持久化方案有两种:
①持久化到本地业务数据库中,利用本地事务保证业务和事件数据的一致性
②持久化到共享的事件数据库中。业务数据库和事件数据库不是一个,他们的数据持久化操作会跨数据库,因此需要分布式事务来保证业务和事件数据的强一致性。
(3)事件总线(EventBus)
事件总线是实现微服务内聚合之间领域事件的重要组件,提供事件分发和接收等服务。是进程内模型,会在微服务内聚合之间遍历订阅者列表,采取同步或异步的模式传递数据。事件分发流程大致如下:
-
如果是微服务内的订阅者(其他聚合),则直接分发到指定订阅者;
-
如果是微服务外的订阅者,将事件数据保存到事件库并异步发送到消息中间件;
-
如果同时存在微服务内和外订阅者,则先处理内部订阅者,再处理外部订阅者
(4)消息中间件
跨微服务的领域事件大多会用到消息中间件,实现跨微服务的事件发布和订阅。Kafka,RabbitMQ等
(5)事件接收和处理
微服务订阅方再应用层采用监听机制,接收MQ中的事件数据,完成持久化后,可以开始进一步的业务处理。
6.领域事件运行机制案例
承保业务流程的通知缴费通知单事件为例。发生再投保和收款微服务之间。领域事件是:缴费通知单已生成。下一步业务操作是:缴费。
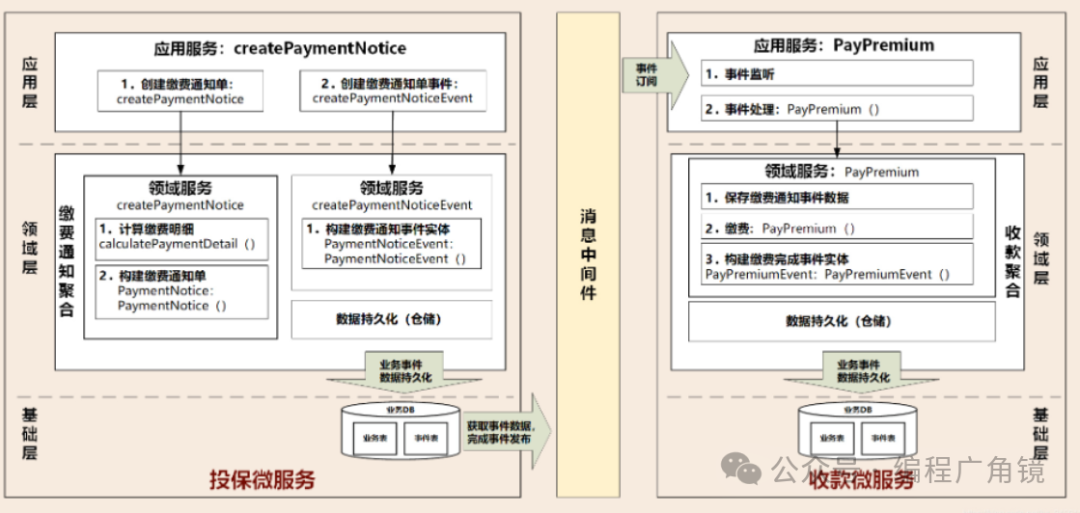
事件起点:出单员生成投保单,核保通过后,发起生成缴费通知单的操作。
(1)投保微服务应用服务,调用聚合中的领域服务createPaymentNotice和createPaymentNoticeEvent,分别创建缴费通知单、缴费通知单事件。缴费通知单类PaymentNoticeEvent继承基类DomainEvent。
(2)利用仓储服务持久化缴费通知单相关的业务和事件数据。为避免分布式事务,这些数据都持久化到本地投保微服务数据库中。
(3)通过数据库日志捕获技术或定时程序,从数据库事件表中获取事件增量数据,发布到MQ。事件发布也可以通过应用服务或领域服务完成发布。
(4)收款微服务再应用层从MQ订阅缴费通知单事件消息主题,监听并获取事件数据后,应用服务调用领域层的领域服务将事件数据持久化到本地数据库。
(5)收款微服务调用领域岑的领域服务PayPremium,完成缴费。
(6)事件结束。
提示:缴费完成后,后续还会产生很多新的领域事件。
二、DDD分层架构推动架构演进
1.微服务架构的演进
领域模型中对象的层次从内到外依次是:值对象、实体、聚合、限界上下文。
实体或值对象的简单变更,一般不会使领域模型和微服务发生大的变化。但聚合的重组或拆分却可以。因为聚合内业务功能内聚,能独立完成特定的业务逻辑。可以以聚合为基础单元,完成领域模型和微服务架构的演进。聚合可以作为一个整体在不同的领域模型之间重组或拆分,或者直接将一个聚合独立为微服务。
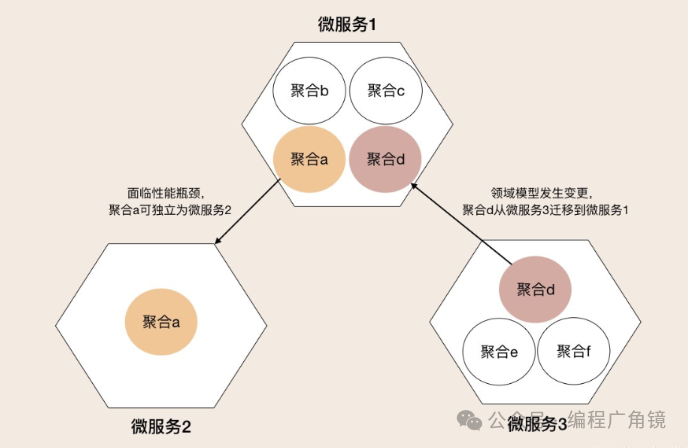
上图为例:①当发现微服务1中的聚合a的功能被高频访问,甚至拖垮整个微服务1的性能,可以把聚合a的代码,独立为微服务2,它可以轻松应对高性能场景;②发现微服务3的领域模型有了变化,聚合d更适合放到微服务1中。可以将d整体搬迁到微服务1中,如果合计时已经定义好了聚合之间的代码边界,这个过程不会太复杂。③经历模型和架构演进后,微服务1已经从最初包含聚合a、b、c,演进为包含聚合b、c、d。
2.微服务内服务的演进
微服务内部,实体的方法被领域服务组合和封装,领域服务又被应用服务组合和封装。在逐层组合和封装时,会出现:
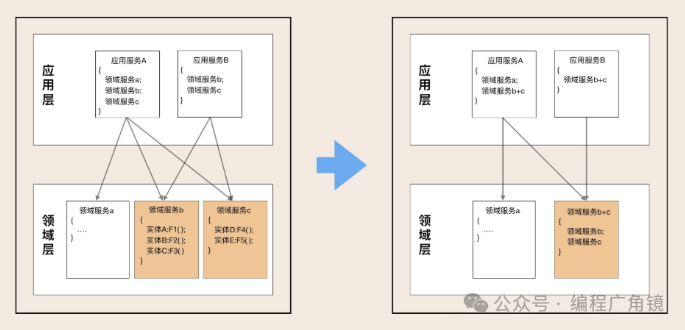
服务设计时,并不一定能完整预测有哪些下层服务会被多少个上层服务组装,因此领域层通常只提供一些原子服务,比如领域服务 a、b、c。但随着系统功能增强和外部接入越来越多,应用服务会不断丰富。有一天你会发现领域服务 b 和 c 同时多次被多个应用服务调用了,执行顺序也基本一致。这时你可以考虑将 b 和 c 合并,再将应用服务中 b、c 的功能下沉到领域层,演进为新的领域服务(b+c)。这样既减少了服务的数量,也减轻了上层服务组合和编排的复杂度。服务演进的过程是随着系统发展的。
3.三层架构如何演进到DDD分层架构
首先,由于层间松耦合,我们可以专注于本层的设计,而不必关心其它层,也不必担心自己的设计会影响其它层。DDD 成功地降低了层与层之间的依赖。其次,分层架构使得程序结构变得清晰,升级和维护更加容易。我们修改某层代码时,只要本层的接口参数不变,其它层可以不必修改。即使本层的接口发生变化,也只影响相邻的上层,修改工作量小且错误可以控制,不会带来意外的风险。
4.该怎样转向DDD分层架构?
传统企业应用大多是单体架构,而单体架构则大多是三层架构。三层架构解决了程序内代码间调用复杂、代码职责不清的问题,但这种分层是逻辑概念,在物理上它是中心化的集中式架构,并不适合分布式微服务架构。DDD 分层架构中的要素其实和三层架构类似,只是在 DDD 分层架构中,这些要素被重新归类,重新划分了层,确定了层与层之间的交互规则和职责边界。
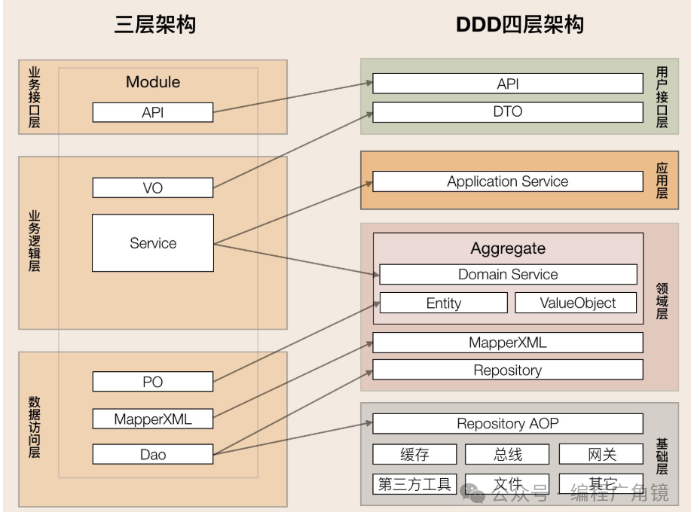
首先,架构向 DDD 分层架构演进,主要发生在业务逻辑层和数据访问层。DDD 分层架构在用户接口层引入了 DTO,给前端提供了更多的可使用数据和更高的展示灵活性。DDD 分层架构对三层架构的业务逻辑层进行了更清晰的划分,改善了三层架构核心业务逻辑混乱,代码改动相互影响大的情况。DDD 分层架构将业务逻辑层的服务拆分到了应用层和领域层。应用层快速响应前端的变化,领域层实现领域模型的能力。另外一个重要的变化发生在数据访问层和基础层之间。三层架构数据访问采用 DAO 方式;DDD 分层架构的数据库等基础资源访问,采用了仓储(Repository)设计模式,通过依赖倒置实现各层对基础资源的解耦。仓储又分为两部分:仓储接口和仓储实现。仓储接口放在领域层中,仓储实现放在基础层。原来三层架构通用的第三方工具包、驱动、Common、Utility、Config 等通用的公共的资源类统一放到了基础层。
三、架构模型
1.整洁架构
又名“洋葱架构”,体现了分层分设计思想。在整洁架构里,同心圆代表应用软件的不同部分,从里到外依次是领域模型、领域服务、应用服务和最外围的容易变化的内容,比如用户界面和基础设施。整洁架构最主要的原则是依赖原则,它定义了各层的依赖关系,越往里依赖越低,代码级别越高,越是核心能力。外圆代码依赖只能指向内圆,内圆不需要知道外圆的任何情况。
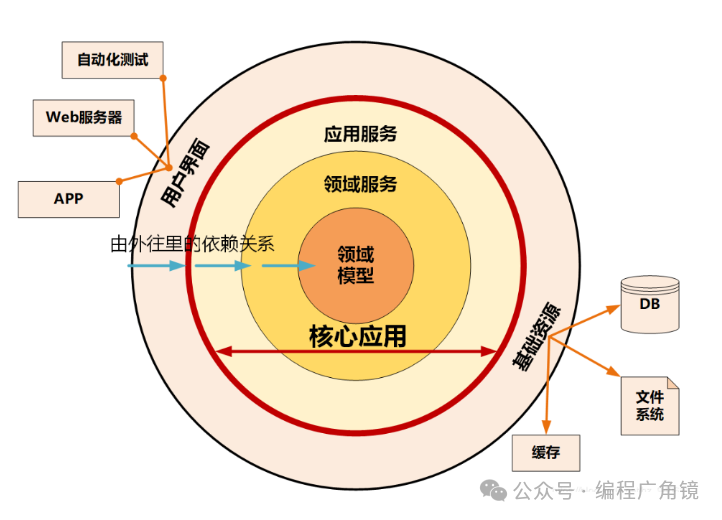
在洋葱架构中,各层的职能是这样划分的:
-
领域模型实现领域内核心业务逻辑,它封装了企业级的业务规则。领域模型的主体是实体,一个实体可以是一个带方法的对象,也可以是一个数据结构和方法集合。
-
领域服务实现涉及多个实体的复杂业务逻辑。
-
应用服务实现与用户操作相关的服务组合与编排,它包含了应用特有的业务流程规则,封装和实现了系统所有用例。
-
最外层主要提供适配的能力,适配能力分为主动适配和被动适配。主动适配主要实现外部用户、网页、批处理和自动化测试等对内层业务逻辑访问适配。被动适配主要是实现核心业务逻辑对基础资源访问的适配,比如数据库、缓存、文件系统和消息中间件等。
-
红圈内的领域模型、领域服务和应用服务一起组成软件核心业务能力。
2.六边形架构(端口和适配器)
在DDD的设计思想下,六边形架构风格,让领域模型处于架构的核心区域,让开发人员将焦点聚集到领域。DDD和六边形架构是天然契合的,是DDD的首选架构。
所谓的六边形架构,其实是分层架构的扩展,原来的分层架构通常是上下分层的,比如常见的MVC模式,上层是对外的服务接口,下层是对接存储层或者是集成第三方服务,中层是业务逻辑层。我们跳出分层的概念,会发现上面层和下面层其实都是端口+适配器的实现,上面层开放http/tcp端口,采用rest/soap/mq协议等对外提供服务,同时提供对应协议的适配器;下层也是端口+适配器,只不过应用程序这时候变成了调用者,第三方服务或者存储层提供端口和服务,应用程序本身实现适配功能。
基于上述思考,将分层接口中的上层和下层统一起来就变成了六边形架构,基于端口和适配器的实现,示意图如下:
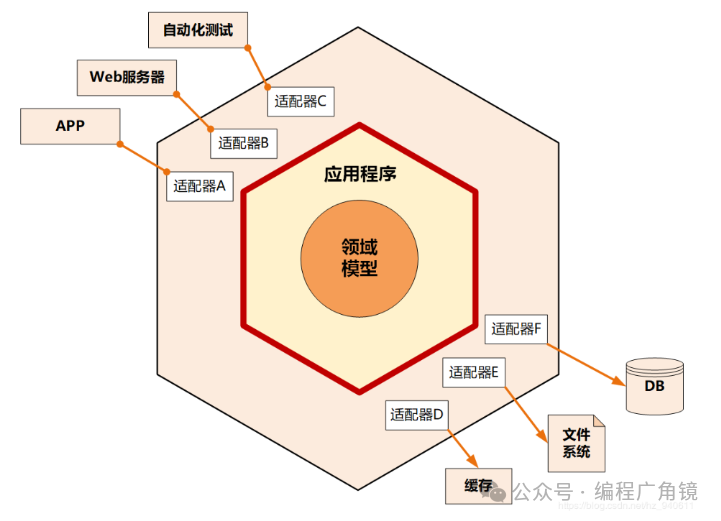
六边形架构的核心理念是:应用是通过端口与外部进行交互的。这也是微服务架构下 API 网关盛行的主要原因。也就是说,在下图的六边形架构中,红圈内的核心业务逻辑(应用程序和领域模型)与外部资源(包括 APP、Web 应用以及数据库资源等)完全隔离,仅通过适配器进行交互。它解决了业务逻辑与用户界面的代码交错问题,很好地实现了前后端分离。六边形架构各层的依赖关系与整洁架构一样,都是由外向内依赖。
红圈内的六边形实现应用的核心业务逻辑;
外六边形完成外部应用、驱动和基础资源等的交互和访问,对前端应用以 API 主动适配的方式提供服务,对基础资源以依赖倒置被动适配的方式实现资源访问。
六边形架构的一个端口可能对应多个外部系统,不同的外部系统也可能会使用不同的适配器,由适配器负责协议转换。这就使得应用程序能够以一致的方式被用户、程序、自动化测试和批处理脚本使用。
3.REST
RESTful风格的架构将‘资源’放在第一位,每个‘资源’都有一个URI与之对应,可以将‘资源’看着是ddd中的实体;RESTful采用具有自描述功能的消息实现无状态通信,提高系统的可用性;至于‘资源’的哪些属性可以公开出去,针对‘资源’的操作,RESTful使用HTTP协议的已有方法来实现:GET、PUT、POST和DELETE。
在DDD的实现中,我们可以将对外的服务设计为RESTful风格的服务,将实体/值对象/领域服务作为'资源'对外提供增删改查服务。但是并不建议直接将实体暴露在外,一来实体的某些隐私属性并不能对外暴露,二来某些资源获取场景并不是一个实体就能满足的,因此我们在实际实践过程中,在领域模型上增加了dto这样一个角色,dto可以组合多个实体/值对象的资源对外暴露。
4.CQRS
CQRS读写分离,通常读写分离的目的是为了提高查询性能,同时达到读/写的解耦。让DDD和CQRS结合,我们可以分别对读和写建模,查询模型通常是一种非规范化数据模型,它并不反映领域行为,只是用于数据显示;命令模型执行领域行为,且在领域行为执行完成后,想办法通知到查询模型。
那么命令模型如何通知到查询模型呢? 如果查询模型和领域模型共享数据源,则可以省却这一步;如果没有共用数据源,则可以借助于‘消息模式’(Messaging Patterns)通知到查询模型,从而达到最终一致性(Eventual Consistency)。
Martin在blog中指出:CQRS适用于极少数复杂的业务领域,如果不是很适合反而会增加复杂度;另一个适用场景为获取高性能的服务。
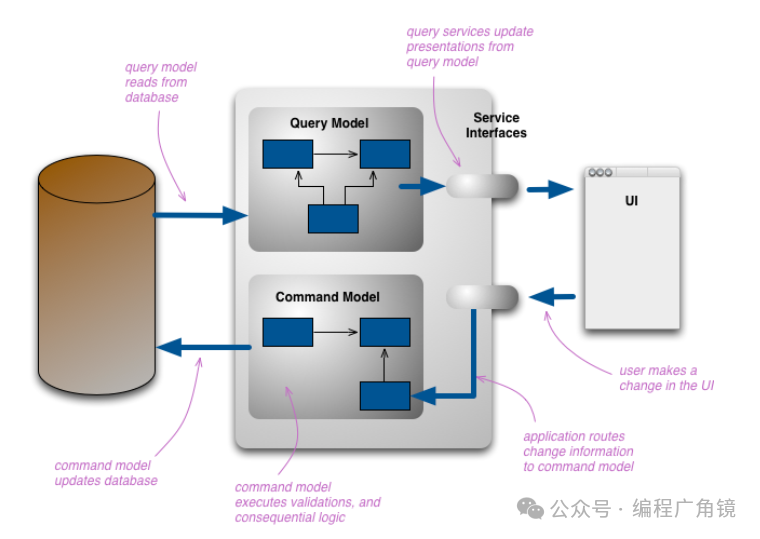
因为DDD中有工厂和仓库来管理领域模型,前者主要用于创建,而后者则用于存储。这就表明在DDD中是默认将读写分离的,DDD似乎就天生和CQRS有着无缝的链接。CQRS往往要求数据库进行读写分离,具体来说,所有的更新操作均无返回值(void),而读操作才返回对应的值。在实现CQRS时,又和事件源(Event Source)相结合,以下是一个简单的交互过程:
客户端发起一个请求,服务端将其映射为一个命令,该命令会从仓库中读取一个相关的聚合,对该聚合进行操作,将会生成一个事件源,将该事件发送出去,接收方收到消息后(并不是立刻)将会更新领域对象,完成一次更新操作。
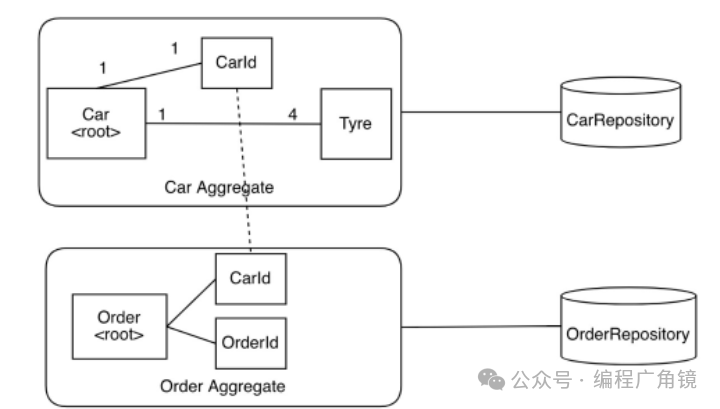
案例解析:
如图,Car是aggregate,它有对应的CarRepository,
aggregate之间是通过entity的ID来引用的。Car这个entity,有一个CarId的value object作为Car的识别符。 现在我们想象要做一个购物平台,其中处理订单是我们的一个业务。那我们自然而然会想到需要一个表示订单的domain object。那我们就创建一个Order的entity,Order通过CarId来引用Car这个aggregate 。
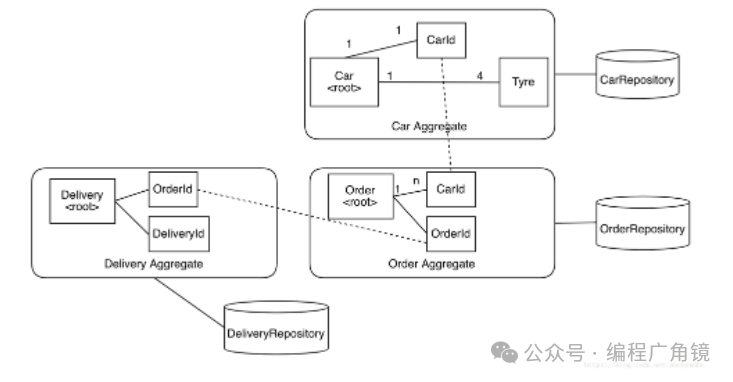
如果还有关于运输的需求。我们为此创建一个叫Delivery的domain object。
当我们要实现一个订单列表功能的时候

| public ListviewDeliveryList(UserId userId){ Listdeliveries=deliveryRepository.find(new DeliverySpecByUserId(userId)); ListorderIds=deliveries.toStream().map(delivery->delivery.getOrderId()).collect(Collectors.toList()); Listorders=orderRepository.find(new OrderSpecByIds(orderIds)); ListcarIds=orders.toStream().flatMap(order->order.getCarIds()).collect(Collectors.toList()); Listcars=carRepository.find(new CarSpecByIds(carIds)); return ListorderDTOs=buildDTO(deliveries, orders, cars); } |
大致的处理是从各个repository中获取entity(aggregate)。最后把取得的3种entity拼装成画面需要的DeliveryDTO。 直观的感觉是对数据库进行了3次查询,而实际上如果使用关系型数据库的话,明明可以用一个集联查询来实现的东西,用了3次查询显得有些笨拙。
表面上看可能是我们选择ORM和模型设计的问题。比如如果是jpa的话,下面的模型设计是可以减少查询数量的。
但结果是,这样的实现并不符合我们设计的domain object。而我们在entity中引用了entity(Order中直接引用了Delivery),等于我们设计了一个很大的aggregate,包含了很多entity。
但是又要满足需求又要满足DDD设计策略,我们该怎么做呢?
要实现画面显示功能时,domain entity具体有什么行为,需要保证那些数据完整性显然不是我们关心的。而且模型的大小一般也不是考虑的因素,画面需要的信息我们都必须返回。
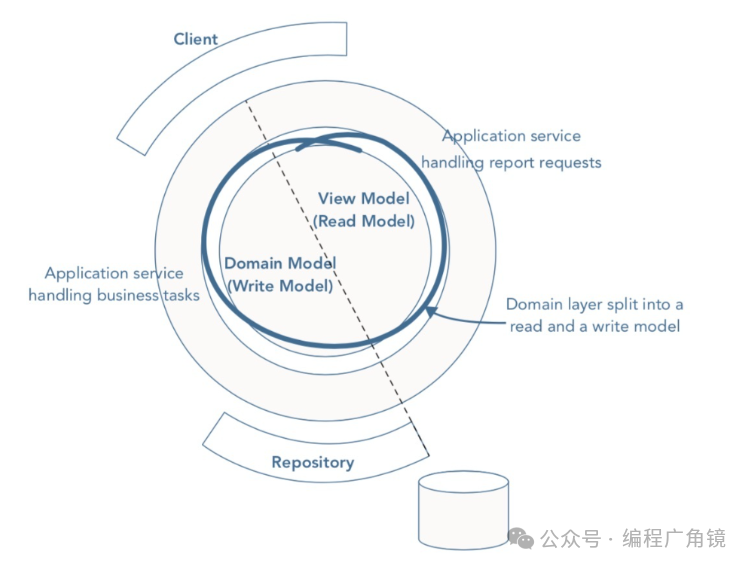
我们使用DeliveryDTO放最终数据,现在问题在于,我们是用domain object转成DTO的,我们可以采用CQRS的方式省略掉这一步。在application层中,我们将本来的application service分成两种service,command service与query service。
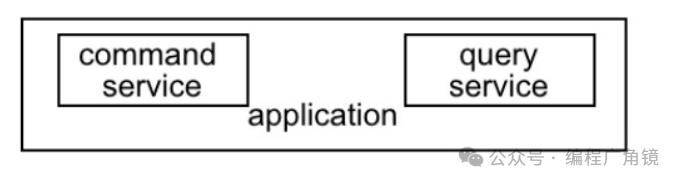
Command处理
首先是command处理。command service会专门负责command处理。command处理包括创建与更新类型的处理。比如例子中下订单,取消订单的功能就会属于command service。
| public OrderCommandService { private OrderRepository orderRepository; public orderId createOrder(UserId userId, Long carModelId){ Order order = Order.createOrder(userId, carModelId); orderRepository.save(order); return order.getOrderId(); } public void cancelOrder(User userId, OrderId orderId){ Order order = orderRepository.findOrderById(new OrderSpecificationById(orderId)); if(order.getUserId() != userId) { throw new IllegalAccessException(); } order.cancel(); orderRepository.save(order); } } |
Query处理
query部分的处理采用的方法是不通过domain model,直接获取数据。概念是这样,实际上的实现是多种多样,一个重要的因素是用来与数据库交互的框架。个人感觉一些能直接写sql语句的框架是比较不错的选择。
| @Component public class OrderQueryService { private final DSLContext jooq; public ListgetOrderList(Long userId){ return jooq.select() .from(ORDER) .join(DELIVERY).on(DELIVERY.ORDER_ID.eq(ORDER.ORDER_ID)) .join(CAR).on(CAR.CAR_ID.eq(ORDER.CAR_ID)) .where(ORDER.ORDER_ID.eq(userId)) .fetch() .map(record -> OrderDTO.builder() .orderId(record.get(ORDER.ORDER_ID)) .deliveryId(record.get(DELIVERY.ORDER_ID)) .deliveryAddress(record.get(DELIVERY.ADDRESS)) .deliveryStatus(record.get(DELIVERY.STATUS)) .carId(record.get(CAR.CAR_ID)) .carModelId(record.get(CAR.MODEL_ID)) .carImageUrl(record.get(CAR.IMAGE_URL)) .build() ); } } |
注意:因为CQRS中query和command不能相互调用,所以当两者紧密关联的时候很难分离,即使分离了也加大了理解难度,所以不推荐使用该模式,只有再性能出现问题的时候才会考虑使用该种方式。















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









