







1、需求背景
在零售场景中,有大量的搜索和排序的场景,比如典型的商品名称,商品条码,外部商品编码等搜索,还有按照价格,销量排序等操作,在微服务的架构下,这些数据大多数都是异构的,代码实现在不同的服务中,用mysql来实现这样复杂的操作,就显得捉襟见肘,就需要额外的工具或中间件来完成这样的功能。总体来说,有以下两种思路:
-
设计一个大宽表,每次业务的增删改操作都再写一份到这张表中。
-
引入专门的中间件来解决该问题,比如es。
前者的双写需要花大量的开发成本,而且在复杂业务场景下,容易出错,性能也是问题。
为了使海量数据能够提供实时快速的查询,mysql很显然力不从心,于是我们需要利用es提供大数据搜索服务。
2、常⻅的5种 ES 同步⽅案
在引入es后,同样面临一个问题,db中的数据如何同步到中,常见的有5种方案:
| 同步方案 | 优点 | 缺点 |
| 同步双写 | 业务逻辑简单 | ①硬编码:有需要写入mysql的地方都需要添加写入ES的代码;业务强耦合; ②存在双写失败丢数据风险; ③性能较差:本来mysql的性能就不是很高,再加写一个ES,系统的性能必然会下降 |
| 异步双写(MQ) | ①性能高; ②不存在丢数据问题 | ①硬编码问题:依然存在业务强耦合; ②复杂度增加:系统中增加了mq的代码; ③可能存在延时问题:程序的写入性能提高了,但是由于MQ的消费可能由于网络或其它原因导致用户写入的数据不一定可以马上看到,造成延时 |
| 定时增量同步 | ①不改变原来代码,没有侵入性、没有硬编码; ②没有业务强耦合;不改变原来程序的性能; ③Worker代码编写简单不需要考虑增删改查 | ①时效性较差,由于定时器工作周期不可能设在秒级,所以实时性不是很好 ②对数据库有一定的轮询压力 ③业务每次更新都需要将更新时间写入 |
| 开源同步插件 | ①无侵入代码无感知; ②接入相对比较简单,只需配置即可 | ①业务每次更新都需要将更新时间写入; ②每次处理单表,聚合能力太差 |
| 基于binlog数据同步 | ①无代码侵入;原有系统不需要任何变化,没有感知; ②性能高; ③业务解耦,不需要关注原来系统的业务逻辑 | ①构建Binlog系统复杂; ②存在延时风险。 |
在上述的开源插件中,在多表聚合层⾯,都存在不⾜,但是在单表同步⽅⾯,还是⼀个很不错的选择。
常见的es数据同步插件主要有以下四种:
| 插件名称 | 优点 | 缺点 |
| Elasticsearch-jdbc | ①相对比较通用; ②社区活跃更新及时 | 删除操作无法同步 |
| Elasticsearch-river-mysql | 目前已经停止维护 | |
| Go-mysql-elasticsearch | 能够同步实现增删改查 | ①目前处于开发期,不稳定 ②日志功能缺少,问题排查比较难 |
| Logstash-input-jdbc | ①版本更新快,相对文档 ②相对功能比较齐全 ③es固有插件,简单易用 | 删除操作无法同步 |
在上述的5种方案中,零售基于现实的业务,选择了第五种基于 binlog 的数据同步⽅案。并且在实践中,经过了多次迭代,出现了多个版本。
3、数据同步1.0
3.1 整体架构设计
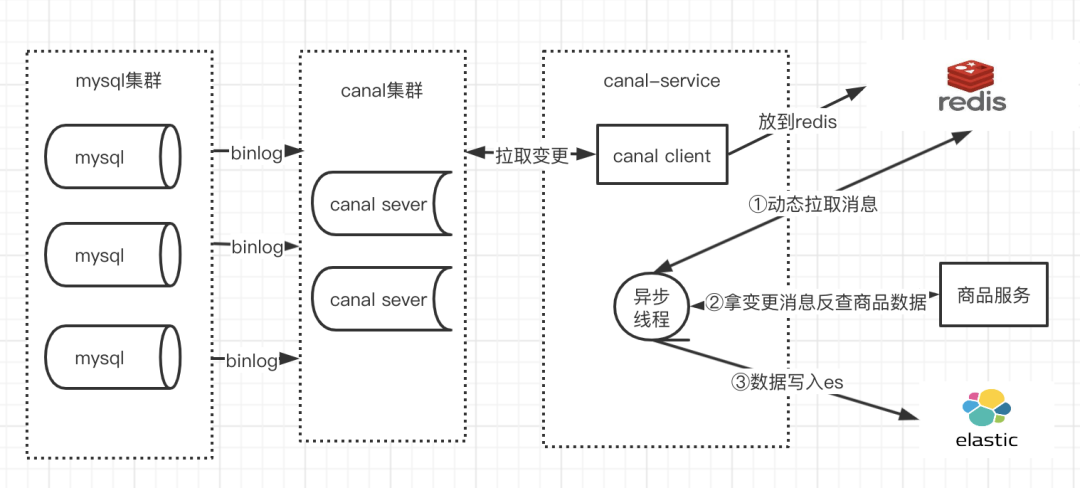
3.2 同步流程
从上⾯的架构图中,大致可以分为⼀下⼏个步骤:
-
Step1: canal 伪装成⼀个 MySQL 的从库,读取 binlog 日志;
-
Step2: canalClient 读取变更信息,放到 Redis 进行区去重;
-
Step3: 定时任务从 Redis 去重队列放到 Redis 消费队列;
-
Step4: 定时任务消费业务队列,反查商品接口,将数据写⼊到 ES 中。
3.3 针对可能的数据丢失的补偿⽅案
不禁有⼀个疑问,如果 Redis 数据丢失,或者中间变更数据丢失,变更信息不是同步不了到 ES ?商户某件商品搜索不出来,那客户不得炸毛?
为了解决该问题,专⻔设计了⼀个定时任务,每天晚上进⾏数据的全量的同步,所以⾄少可以保证 T+1 的时效性,保证用户⾄少可以再第⼆天看到数据。
如果有的商户⽐较急,提出的问题要快速解决怎么办?
这类问题其实在真实的场景中⽐⽐皆是,毕竟我们的公司⽂化最核⼼的就是客户⾄上,所以如果出现这类问题,就需要立马解决。
针对上述问题,就需要准备好按照 业务维度的刷数据脚本,保证第一时间解决问题,客户至上!!!
3.4 实践场景存在的问题点
-
canal-redis线
如果发⽣了⼤量的变更,需要将消费 binlog 到 Redis,本⾝canal client 的消费速度有限,导致 binlog 的变更不能及时同步到 Redis。
canal client 消费提交位点的不能保证高稳定性,导致位点消息错乱,拉取不到消息。
-
redis -es线
通过架构图可以看到,从 Redis 读数据理论上不存在性能瓶颈,主要耗时是从业务服务反查商品信息和写入es,这两块的性能有限,是整个同步架构整个木桶中的最短的两块板,从而导致redis中的队列数据堆积。
-
canal中间件
当前的canal 版本较低,变更消息没有变更前后的数据,所以存在以下的局限:
-
由于现有的 binlog 是基于 ROW 模式,所以数据库某⼀⾏任何字段有变更都会发在 Redis 队列,⽽其中的某些字段的变更如果不涉及搜索,其实是可以不做数据同步的。
-
由于现有业务是有许多是全量更新 DB 数据的,在更新前后本⾝字段都没有发⽣实际值的改变,这些是可以不做数据同步的,现有的业务也是放到了 Redis 队列,需要同步的。
4.数据同步2.0
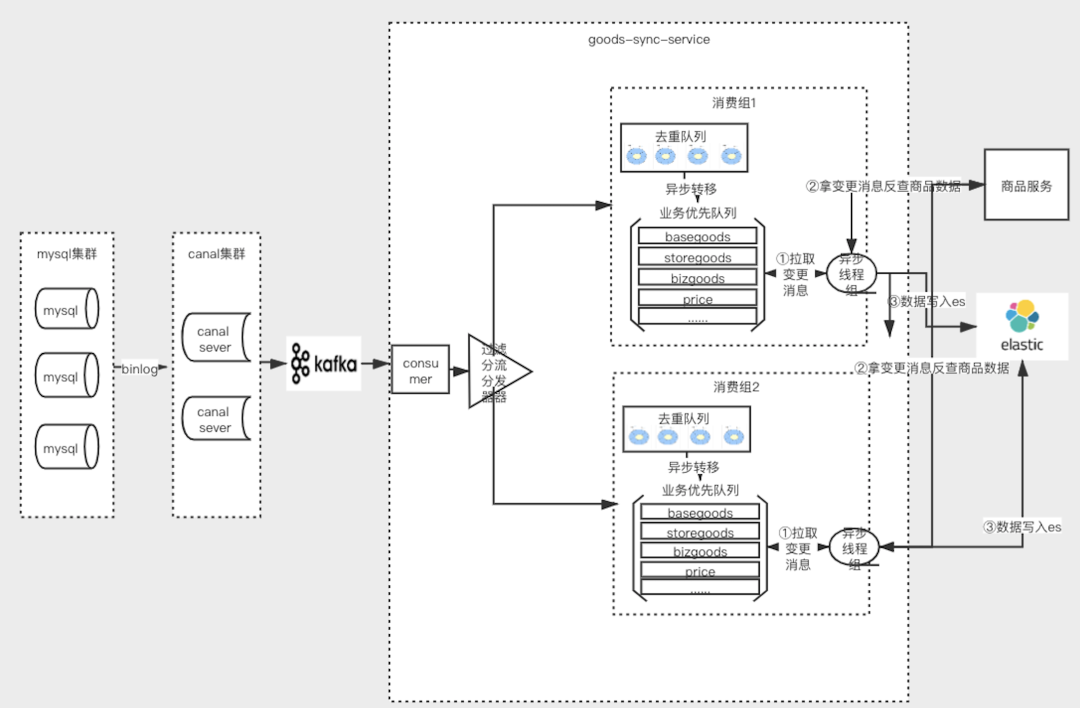
4.1 goods-sync同步架构设计
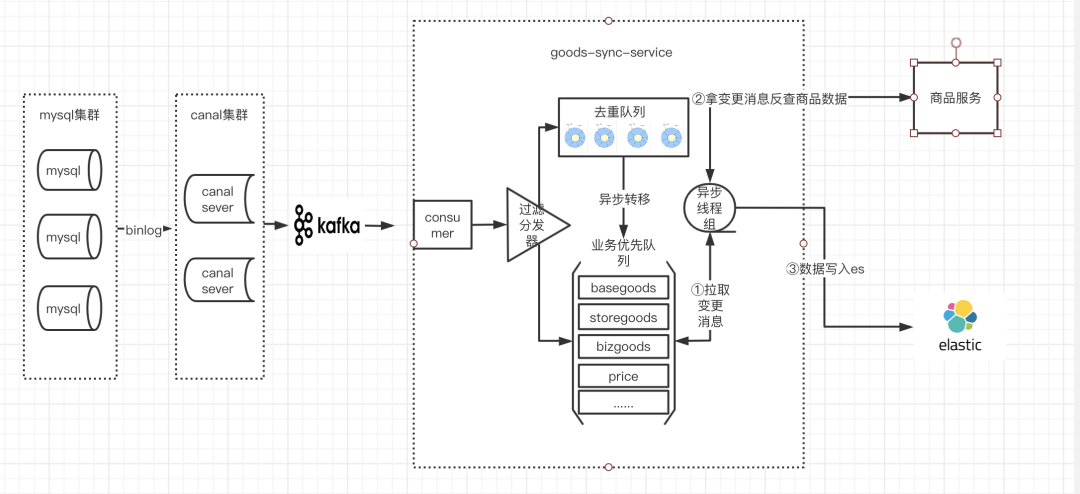
4.2 核⼼组件
4.2.1 动态配置
⽀持配置的动态修改,秒级响应,包括⿊⽩名单,表字段映射,线程池的⼤⼩等,⽆需重启服务,⽀持动态更新。
4.2.2 业务维度⿊⽩名单
该功能的开放可以为以下的场景提供了便利:
-
在上线初期,要进⾏验证,可以开启⽩名单操作,做到灰度发布上线 。
-
某些商户在⾮正常的流量下,可以配置商户级⿊名单,进⾏商户或者业务级别的熔断,防⽌影响其他商户的正常数据同步。
4.2.3 精细化监控表变更
在之前的变更中,只能粗略的监控到表级别,搜索排序等场景只关⼼部分字段,其余字段变更根本不需要进⾏数据同步。
例如⼀个商品表有以下四个字段:

针对搜索的场景,只关注商品标题的变更,影响商品的搜索,后面的图⽚,标语信息的变更不应该引起 ES 数据的同步,所以针对这类的变更,应该直接丢弃掉。
该⼯程中实现了统⼀的过滤组件,直接基于Apollo配置,可以配置到表字段级别,如果单纯的增加已有表的字段,⽆需重启服务,直接生效,核心的关注的配置项如下:

在⼀些场景下,其实 DB 中的某⾏收据发⽣了变更,但是核心关注的字段并没有发⽣变更,⽐如:

发现数据变更前后,只有标语这个字段发⽣了变更,虽然检测到了⾏变化,title 字段并没有发⽣变更,所以此次变更为无效便跟,进行直接丢弃。
4.2.4 ⾼效去重合并
在商品的更新商品的场景中,会同时更新商品的多个信息,⽽这些信息是存储于不同的业务表中,⽽商品同步的维度多以商品 ID 主键作为表示,所以⼀次更新会引起多条 binlog 变更。
针对上述的场景,就会引起 N 次的商品反查和 ES 同步,会给下游查询业务和 ES 的写⼊造成 N 倍压⼒,这种场景是不是可以考虑进⾏去重合并,减少下游服务的压⼒呢?答案是肯定的,所以去重队列应运⽽⽣。
⼯程中的去重队列采⽤了时间分⽚的思路,也就说在某⼀时间窗⼝内进⾏去重。所以设计了⼀个环状的队列,⽬前设定了60个分⽚,每⼀个分⽚表示在⼀定时间内或者⼀定数量内的数据去重。
具体的设计如下所示:
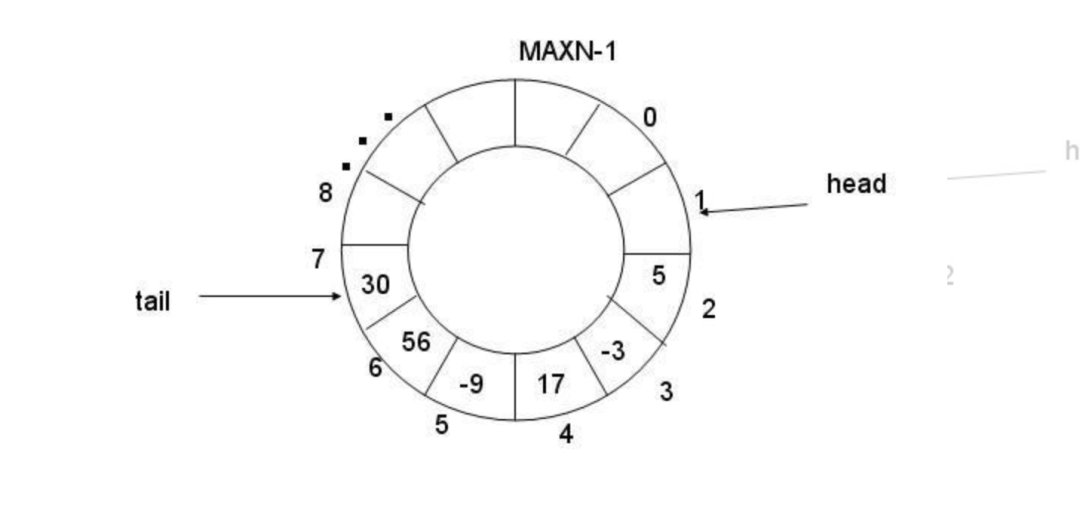
其中 head 移动的条件公式:
当前数组中的容量>阈值 || 停留当前位置的时间 >时间
由上⾯的同时判定:
-
如果变更较快,时间还没有达到阈值,但是当前段数量已经堆积达到了段规定的数量,则进⾏队列的游标的后移。
-
如果数据变更较慢,数据量也没有达到改段的阈值,也进⾏进⾏队列切换,游标的后移,保证delaytime在合理区间内。
该⽅案也存在⼀个问题,因为去重是基于时间窗⼜的,所以会造成⼀定时间的数据同步延迟,默认是1s,当然该值是⽀持动态调整的。
如何调整切换的时间,是要基于经验和实践得出的:
如果设置过⼩,那么段切换过快,去重效率过低。
如果设置过⼤,那么段切换过慢,数据逗留过久,delayTime增加。
如何设置上⾯的值,可以联合⾃⼰的业务,如果业务允许⾼延迟,可以讲这个值设置的稍微⼤⼀些。
4.2.5 动态优先队列
在真实的业务场景中,ES 中作为⼀个聚合的⼤表,每个信息的变更都需要同步到 ES,ES 中的字段相对就会很多,但是在实际的场景中,商户更关注某些业务场景。
例如:商品的上下架信息,商品的分组信息,商品的新增,客户希望第一时间在⻚⾯上看到反馈,⽽对于⼀些价格排序,库存排序,可以容忍稍许的延迟。
针对上述的场景,可以从业务角度进⾏优先级的处理。
假如当前每个队列中的数据如下:
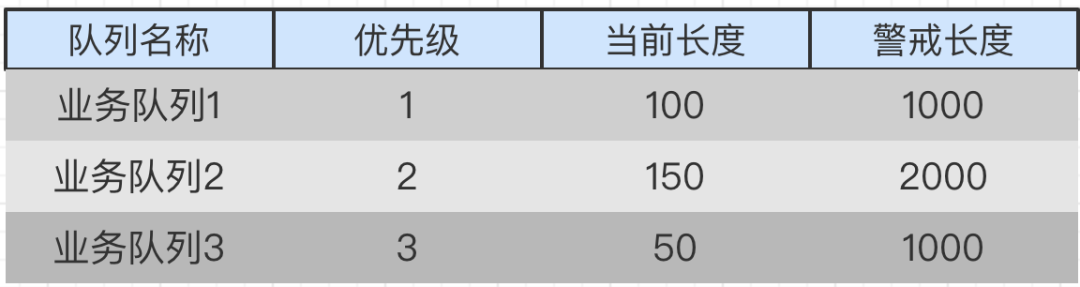
假设⽬前设定了5个线程进⾏轮询消费:
线程1消费业务队列1;
线程2消费业务队列2;
线程3消费业务队列3;
。。。。。
数据变更情况下,每个队列都进⾏消费,⾬露均沾,和平共处,保证数据的同步。
但是在某些特殊场景下业务队列发⽣了数据倾斜,数据分布如下:
![]()
同样的5个线程进⾏消费:
线程1消费业务队列1;
线程2消费业务队列2;
线程3进⾏消费的时候,发现优先级更⾼的业务队列2已经到了警戒队列,所以就放弃本次消费,直接进⾏下⼀次的消费,将资源倾斜到了业务队列1和业务队列⼆。
。。。。
当业务队列⼆的当前数量小于警戒数量时,低优先级的队列才可以进⾏消费。
就是⽤这种思路来重点保证优先级更⾼的队列进⾏最优先的同步。
4.2.6 多⽅式ES DOC的更新

在诸多的业务字段中,有些筛选条件值在特定的业务场景,只更新某⼀个字段,业务含义明确,⽐如门店商品的上下架操作,只影响某⼀业务维度的特定场景,针对于这种变更,不需要反查接⼝获取全量数据,可以进⾏直接进⾏更新 ES 操作。
TIPS
这种直接更新ES的操作,需要额外注意时序,故在发送BINLOG 的时候,KAFKA消息要保证有序性。
针对常规的操作,可以直接⾛反查接口,拿到全量数据后,写⼊ ES,由于查询的天然幂等性,不会存在并发时序的问题。
4.2.7 可配置的业务同步链路
⼀个完整的数据同步应该包含以下的步骤:

如果存在⼀些业务,根本不需要进⾏去重,⽐如新增商品这种,⼀个商品只能新增⼀次,去重带来的效益近乎为0,⽽且要保证时效性,所以去重就显得有些鸡肋。所以要⽀持可定制和可配置的业务同步链路。
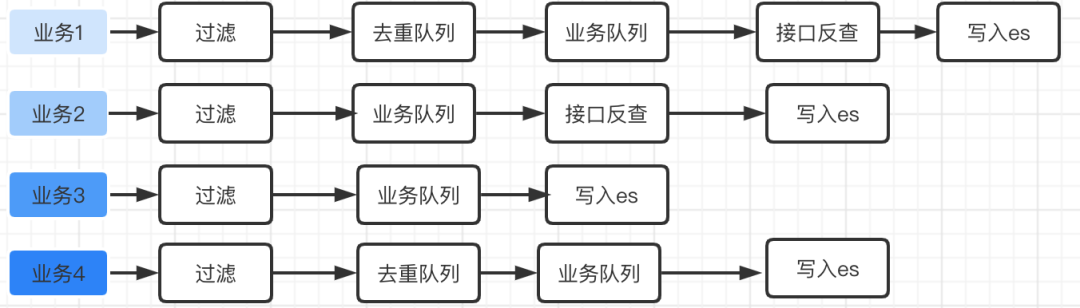
如上图所示,针对不同的业务,可以配置不同的链路,得到数据同步的最短路径。
4.2.8 动态调整的消费速率
在消费业务队列反查 ES 写⼊时,采⽤线程池控制,服务对线程池进⾏了封装,实现了基于 Apollo 的动态线程池,可以通过Apollo 配置实现近实时的线程池扩容缩容,从⽽提⾼消费的速率。
4.2.9 低成本业务接⼊
当⼀个新的业务需要接⼊后,如何能够快速的完成迭代呢?goods-sync需要做⼀下5件事情:
-
配置表和关注的字段;
-
配置同步业务链路(去重队列,业务优先队列,ES 相关配置);
-
编写反查 ES ⽂档的接口;
-
增加反查的路由,编写rpc调⽤;
-
发布服务即可。
这块⼤多数都是配置工作,只需要完成 ES 反查的接⼝两个模块即可。
4.3 在实践中遇到的问题隐患
在实际的业务场景中,尤其在saas场景下,有⼩部分⼤商户会在某⼀个瞬间触发⼤量的变更。
系统中有n个商户,编号为p1,p2,p3…pn
假定p3 是个ka客户,在同时⼀瞬间操作导致了⼤量的变更,导致的结果如下图所示:
在同⼀瞬间 p3 产⽣了⼤量的变更,都⼊了消费队列,假定消费这个队列的速度是5w/min,拿消费完这100w的数据就要花费20分钟,对于商户p4来说,这块的数据同步就要延迟近20分钟,对于商户b的体验太差.

为了解决上述问题,所以要对当前的系统进⾏升级,所以分流式的同步方案应运⽽⽣。
5.商品同步3.0-分流型同步⽅案
5.1 整体架构
相对于2.0版本,该版本保留了基础的去重队列,业务队列等核⼼组件能力,并且将其包装为⼀个基础组,并且⽀持多个组。每个组同时消费,可以配置不同的消费能⼒。这种⽅案可以支持做业务隔离和过载流量隔离。
5.2 业务隔离扩展
这种⽅案可以拥有相当于做业务隔离,⽐如商品同步的业务和单品同步的业务,可以配置2组队列,商品的同步过程和单品的同步过程互不影响,队列相互独⽴。
5.3 过载流量分流
针对4.3中提到的问题,就可以为同⼀个业务配置多个同步组,根据商户的流量阈值进⾏配置,将过载流量分到备选业务消费组消费,常规业务消费组和备选业务消费组相互隔离,所以⼤多数的商户都在常规业务组消费,从⽽避免⼤ ka 导致的其他商户的阻塞。
串联起来的思路如下:
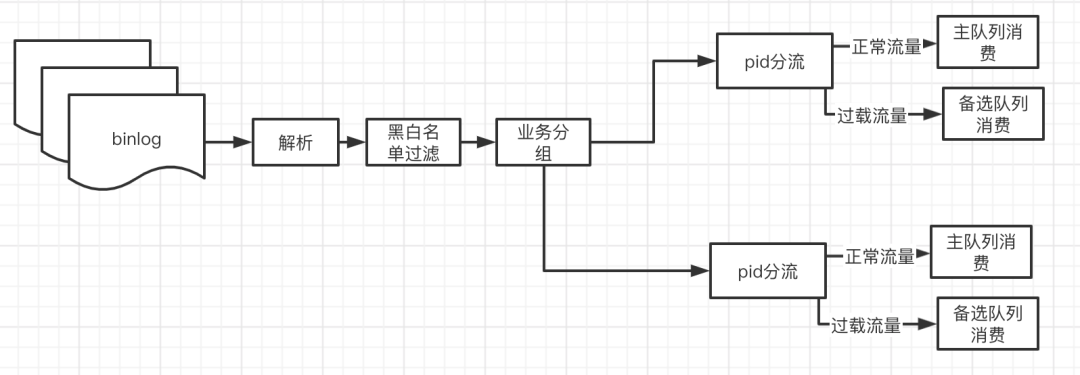
如何识别过载业务 流量,可以从事先和事中两⽅⾯来考虑:
-
事先,直接进⾏⽩名单控制,直接将⽩名单内的商户⾛到备选业务队列。
-
事中,动态识别过载流量的,将其⾛到备选业务队列。
⽩名单 pid 的方式是⼀种事后处理⽅案,如果商户不在⽩名单的话,就会直接直接放到正常消费队列中,会导致阻塞。同时这种⽅案相当于要⼿动去设置 pid 名单,但是⽬前 pid 的⾃动发现还是做不到.
动态识别过载流量的核⼼难点是如何识别过载流量,从实现上来讲,可以有以下⼏个⽅案。
5.3.1 ⼩范围阻塞⽅案
可以使⽤令牌桶算法实现,实现思路如下:
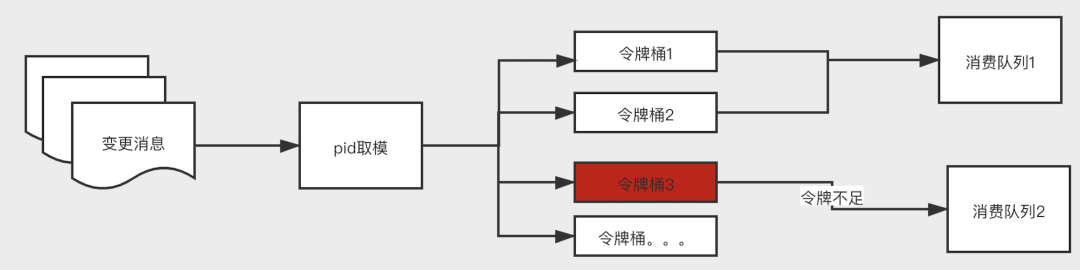
如果设定1000个桶,那么就按照业务维度pid 对1000取模,然后根据取模后的桶编号获取令牌,如果令牌不⾜,则放到备选消费队列。
这种做法能够避免因为某个特殊商户的⼤批量操作造成堆积导致的其他商户造成延迟过⾼,但是也会存在误杀的情况:
如果pid分布的不是很均匀,假设pid 1001⼤批量的变更,达到限流放到队列⼆,那么pid,2001,3001,4001的这些商户也会获取不到令牌,导致放到队列2,在队列2中造成了堆积。
5.3.2 近实时的热点数据发现⽅案
针对5.3.1的⽅案中会存在误杀的情况和pid后置发现,可以对此做⼀个扩展,针对有问题的分组再进⾏流控,筛选出过载流量的pid,自动加到pid名单。
其实现思路如下:
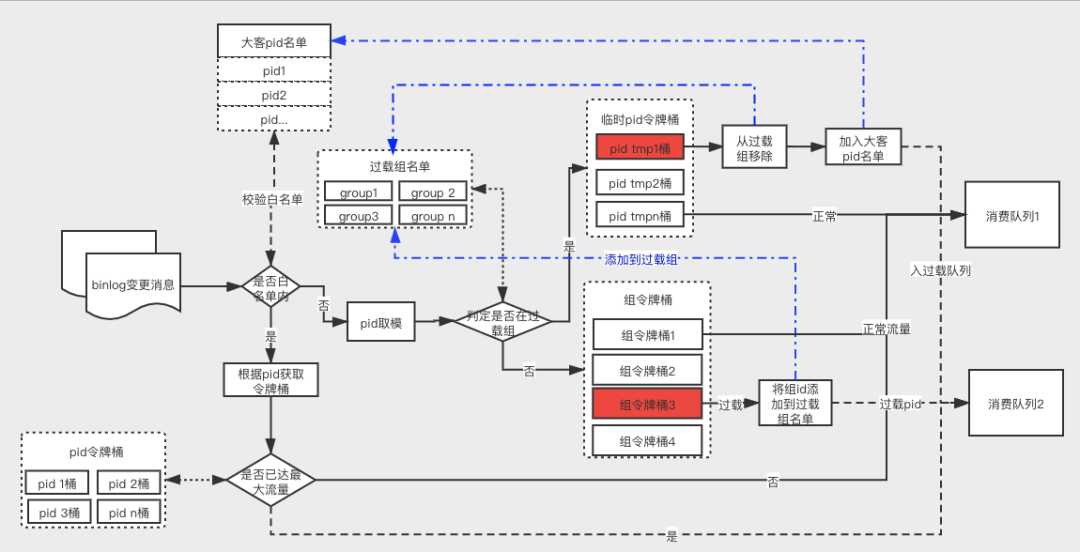
上述⽅案的核⼼思路是分治思路,对有问题的组进⾏再分组,直⾄筛选出过载流量的商户,然后⾃动加载到名单中,直接然后单独的pid进⾏流控。
该⽅案实际是基于经验的一种⽅案,如果某个商户进⾏过⼀次操作,就标记为改商户有污点,直接关⼊⼩⿊屋,浪费了⼀个令牌桶。不够实时。
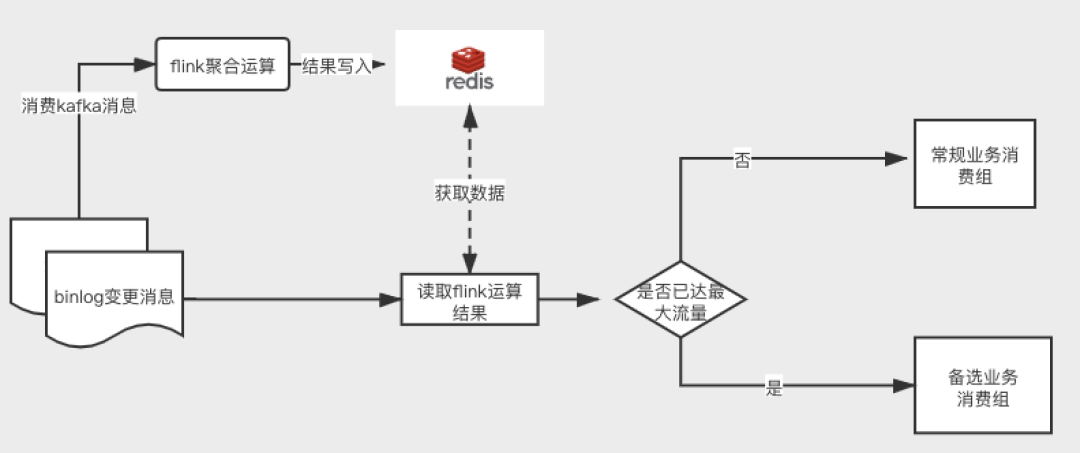
5.3.3 基于flink的热点数据发现。
该分流⽅案完全基于flink的实时计算能⼒,具有⼀定的接⼊成本,但是这种是可以实时的进⾏数据统计,算是⼀种最佳实现⽅案。















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









