






一 简介
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子
序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序
表,称为二路归并。
二 原理
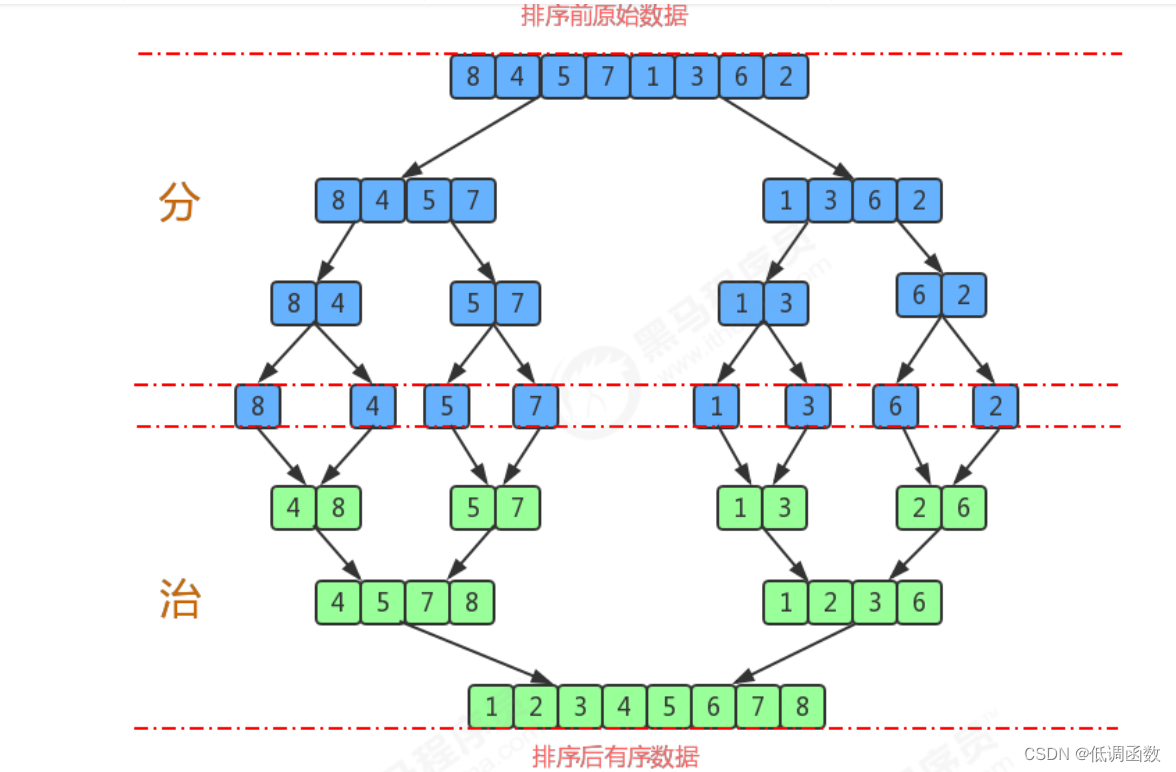
1.尽可能的一组数据拆分成两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是
1为止。
2.将相邻的两个子组进行合并成一个有序的大组;
3.不断的重复步骤2,直到最终只有一个组为止
三 动图分析

四 代码设计
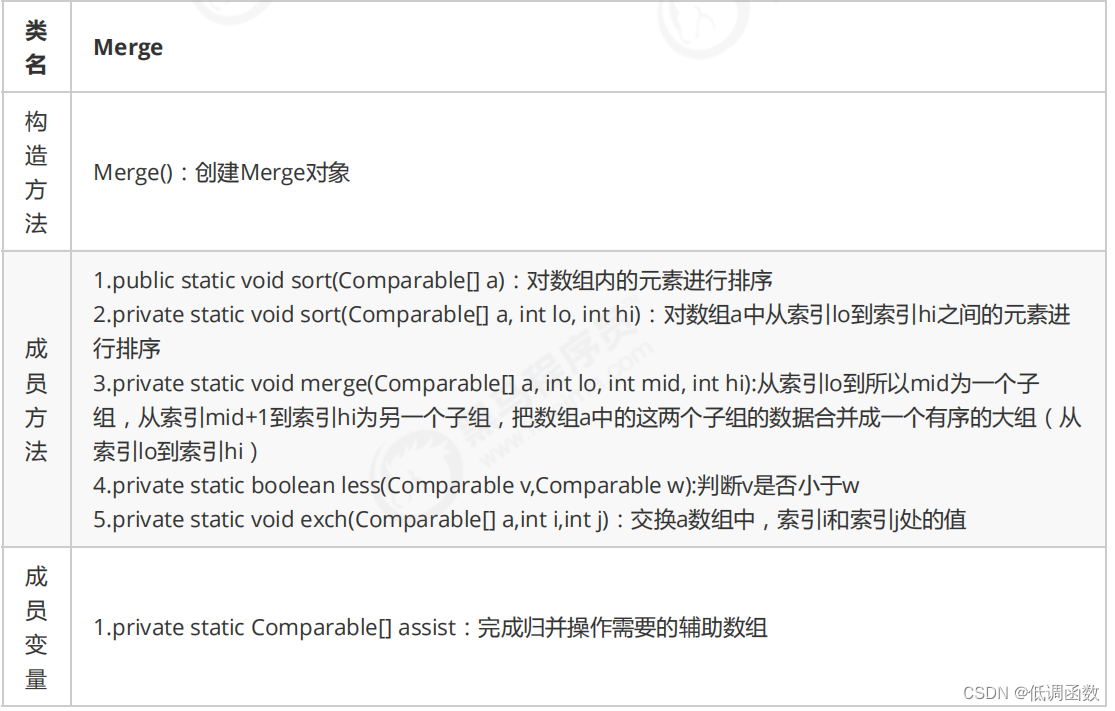
4.1 API设计
4.2 API实现


public class Merge {
//归并所需要的辅助数组
private static Comparable[] assist;
/*
比较v元素是否小于w元素
*/
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w)<0;
}
/*
数组元素i和j交换位置
*/
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
/*
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a) {
//1.初始化辅助数组assist;
assist = new Comparable[a.length];
//2.定义一个lo变量,和hi变量,分别记录数组中最小的索引和最大的索引;
int lo=0;
int hi=a.length-1;
//3.调用sort重载方法完成数组a中,从索引lo到索引hi的元素的排序
sort(a,lo,hi);
}
/*
对数组a中从lo到hi的元素进行排序
*/
private static void sort(Comparable[] a, int lo, int hi) {
//做安全性校验;
if (hi<=lo){
return;
}
//对lo到hi之间的数据进行分为两个组
int mid = (lo+hi)/2;// 5,9 mid=7
//分别对每一组数据进行排序
sort(a,lo,mid);
sort(a,mid+1,hi);
//再把两个组中的数据进行归并
merge(a,lo,mid,hi);
}
/*
对数组中,从lo到mid为一组,从mid+1到hi为一组,对这两组数据进行归并
*/
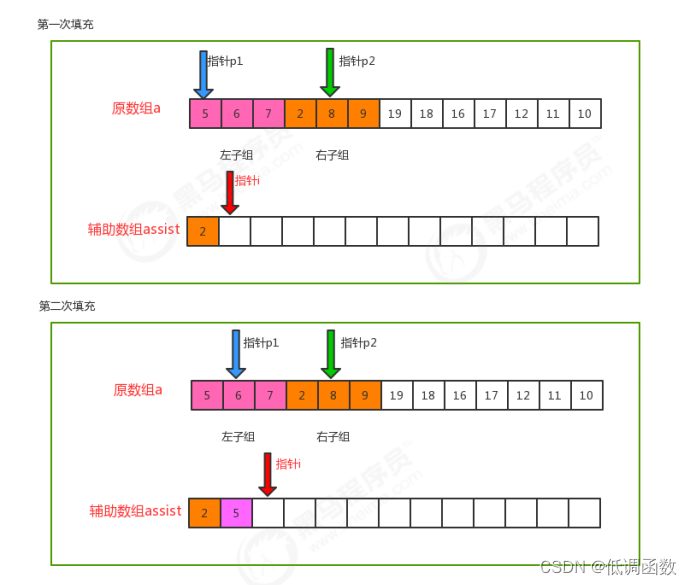
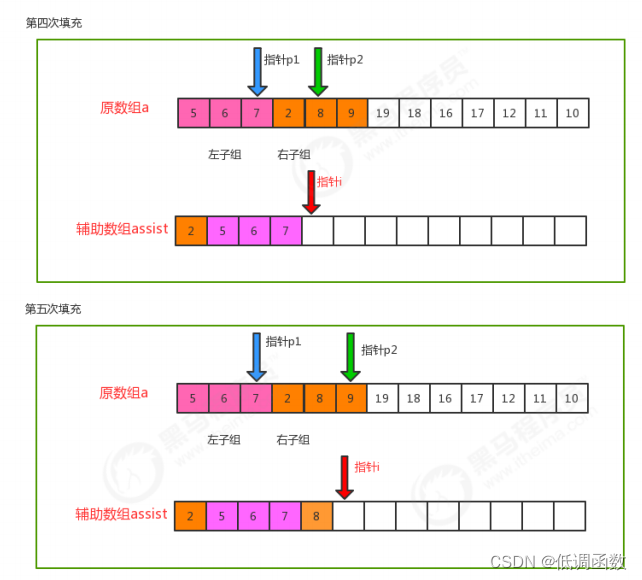
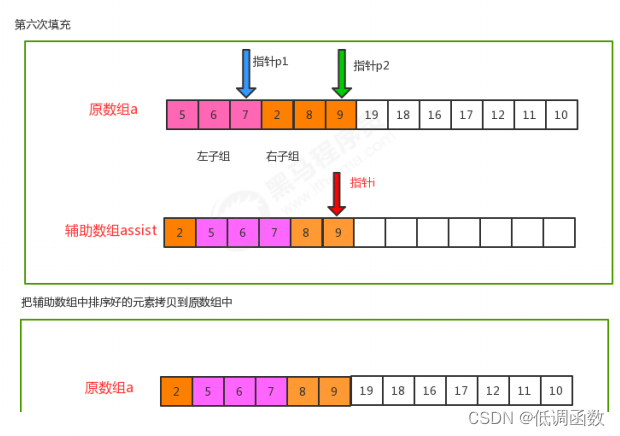
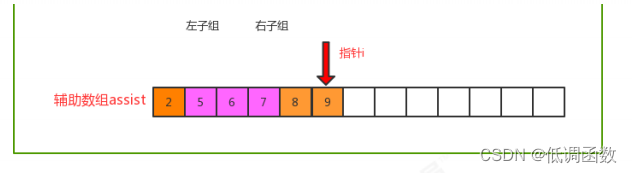
private static void merge(Comparable[] a, int lo, int mid, int hi) {
//定义三个指针
int i=lo;
int p1=lo;
int p2=mid+1;
//遍历,移动p1指针和p2指针,比较对应索引处的值,找出小的那个,放到辅助数组的对应索引处
while(p1<=mid && p2<=hi){
//比较对应索引处的值
if (less(a[p1],a[p2])){
assist[i++] = a[p1++];
}else{
assist[i++]=a[p2++];
}
}
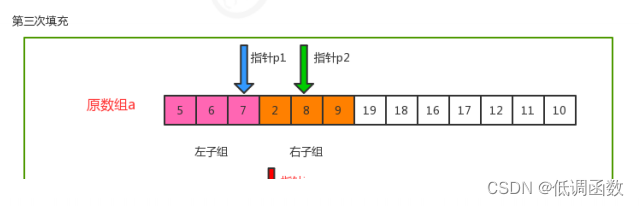
//遍历,如果p1的指针没有走完,那么顺序移动p1指针,把对应的元素放到辅助数组的对应索引处
while(p1<=mid){
assist[i++]=a[p1++];
}
//遍历,如果p2的指针没有走完,那么顺序移动p2指针,把对应的元素放到辅助数组的对应索引处
while(p2<=hi){
assist[i++]=a[p2++];
}
//把辅助数组中的元素拷贝到原数组中
for(int index=lo;index<=hi;index++){
a[index]=assist[index];
}
}
}
4.3 测试代码
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Integer[] a = {9,1,2,5,7,4,8,6,3,5} ;
Merge.sort(a);
System.out.println(Arrays.toString(a));
}
}
4.4 测试结果

五 归并排序时间复杂度分析
归并排序是分治思想的最典型的例子,上面的算法中,对a[lo…hi]进行排序,先将它分为a[lo…mid]和a[mid+1…hi]
两部分,分别通过递归调用将他们单独排序,最后将有序的子数组归并为最终的排序结果。该递归的出口在于如果
一个数组不能再被分为两个子数组,那么就会执行merge进行归并,在归并的时候判断元素的大小进行排序。
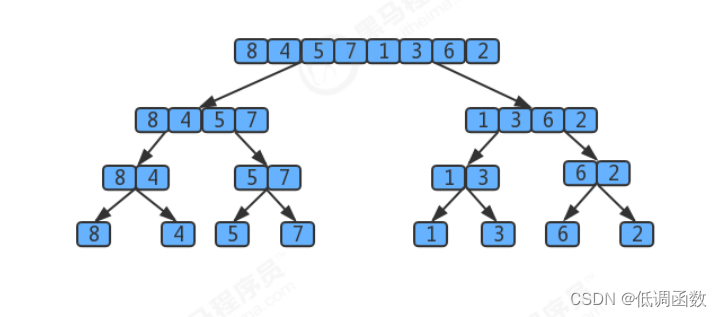
用树状图来描述归并,如果一个数组有8个元素,那么它将每次除以2找最小的子数组,共拆log8次,值为3,所以
树共有3层,那么自顶向下第k层有2k个子数组,每个数组的长度为2(3-k),归并最多需要2^(3-k)次比较。因此每层
的比较次数为 2^k * 2(3-k)=23,那么3层总共为 32^3。
假设元素的个数为n,那么使用归并排序拆分的次数为log2(n),所以共log2(n)层,那么使用log2(n)替换上面32^3中
的3这个层数,最终得出的归并排序的时间复杂度为:log2(n)* 2^(log2(n))=log2(n)*n,根据大O推导法则,忽略底
数,最终归并排序的时间复杂度为O(nlogn);
归并排序的缺点:
需要申请额外的数组空间,导致空间复杂度提升,是典型的以空间换时间的操作。
归并排序与希尔排序性能测试:
之前我们通过测试可以知道希尔排序的性能是由于插入排序的,那现在学习了归并排序后,归并排序的效率与希尔
排序的效率哪个高呢?我们使用同样的测试方式来完成一样这两个排序算法之间的性能比较。
在资料的测试数据文件夹下有一个reverse_arr.txt文件,里面存放的是从1000000到1的逆向数据,我们可以根据
这个批量数据完成测试。测试的思想:在执行排序前前记录一个时间,在排序完成后记录一个时间,两个时间的时
间差就是排序的耗时。
public class SortCompare {
public static void main(String[] args) throws Exception{
ArrayList<Integer> list = new ArrayList<>();
//读取a.txt文件
BufferedReader reader = new BufferedReader(new InputStreamReader(new
FileInputStream("reverse_merge_shell.txt")));
String line=null;
while((line=reader.readLine())!=null){
//把每一个数字存入到集合中
list.add(Integer.valueOf(line));
}
reader.close();
//把集合转换成数组
Integer[] arr = new Integer[list.size()];
list.toArray(arr);
// testMerge(arr);//使用归并排序耗时:1200
testShell(arr);//使用希尔排序耗时:1277
}
public static void testMerge(Integer[] arr){
//使用插入排序完成测试
long start = System.currentTimeMillis();
Merge.sort(arr);
long end= System.currentTimeMillis();
System.out.println("使用归并排序耗时:"+(end-start));
}
public static void testShell(Integer[] arr){
//使用希尔排序完成测试
long start = System.currentTimeMillis();
Shell.sort(arr);
long end = System.currentTimeMillis();
System.out.println("使用希尔排序耗时:"+(end-start));
}
}
通过测试,发现希尔排序和归并排序在处理大批量数据时差别不是很大。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









