






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
以下问题的研究,是基于网上的一些观点进行的梳理。
提示:以下是本篇文章正文内容,下面案例可供参考
一、为什么使用分库分表?
将传统的数据集中存储到单一数据节点的解决方案,在性能、可用性和运维成本来说已经满足不了海量的数据场景了。
1)性能:由于关系型数据库大多采用B+树类型索引,在数据超过阈值的情况虾,索引深度的增加也将磁盘访问IO次数的增加,进而导致查询性能的下降,这在用户使用体验来说很难接受。
2)可用性:数据扩容的的压力在于数据库,单一的数据节点或者简单的主从架构已经难以承担。
3)运维成本:当一个数据库数据达到阈值以上,数据备份和恢复时间随着数据增加而不可控。单一数据库的数据阈值控制在1TB之内比较合适。
二、什么是分库分表
sharding的基本思想就是把一个数据库切分城多个部分放在不同数据库上,从而缓解单一数据库的性能问题。不严格来讲,对于海量数据来讲,如果因为表多而数据多,这个时候适合使用垂直切分,垂直切分根据业务进行拆分,这个比较简单。但是如果因为单表的数据比较多,这个时候就适合水平拆分,即把表的数据按某种规则,(比如按ID散列)切分到多个数据库上。现实中更多是两个情况混合。
1. 垂直拆分
垂直拆分比较简单,在程序配置不同数据源即可。
缺点是:单表或单库高热点访问依旧对DB压力非常大。
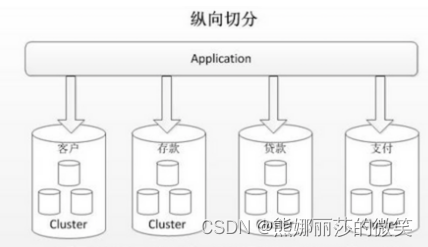
2.水平分片
分表:解决了单表大数据问题
分库:解决了单库性能问题
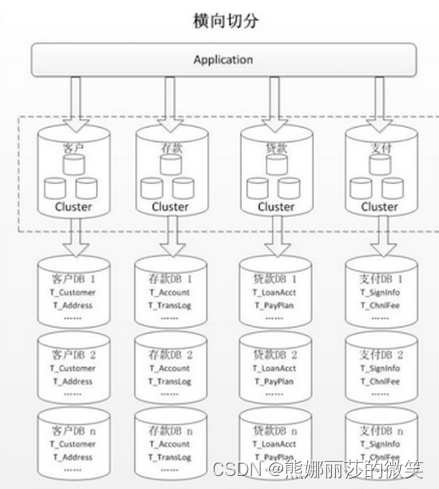
三、分库分表需要解决的问题
1. 事务问题
-
a.方案一:使用分布式事务
优点:交由数据库管理,简单有效
缺点:性能代价比较高,特别是shard越来越多 -
b.方案二:使用应用程序和数据库共同控制
将一个跨多个数据库的分布式事务拆成多个单个数据库上的本地事务。
跨分片事务也是分布式事务,一般采用"XA协议"和“两阶段提交”处理。
最终一致性:对于一致性要求不高的系统,只要在允许时间段内一致性即可,可采用事务补偿方法。
2.跨数据库查询
- a.join:只要是进行切分,跨节点join的问题就不可避免。解决方法是分两次查询,第一次查询出来的id,在第二次请求中得到关联数据。
- b. 排序。可以先在获取不同分片中排序好的数据,再通过程序再排序,最终返回给用户。
- c.聚合count, order by, group by;这个解决问题和join类似,都是可以并行执行,将各个结果集合在应用程序端合并。
3.全局序列号
- a. uuid:是一种最简单的实现,比较长,占用空间大,在索引创建和基于索引的查询会有一定性能瓶颈。
- b.使用数据库表sequence,专门生成id.
- c.雪花算法:由毫秒级时间41位,机器id 10位, 毫秒内序列12位置组成,按照时间自增,效率高。
- d.redis自增,依赖redis自增的单线程特性,使用integer来保证全局唯一。
4.分库策略
- a.根据数值范围:比如订单1-9999分到第一个库,10000-20000到第二个库,以此类推。
- b.根据数值取模:比如订单id mod n,按照余数放到对应编号的库中。这样子比较平均。
- c.比如日志表,根据create_time进行分片。
5.分库数量
- a.对mysql来说,单表保持在500w以下性能最好,都是分多少库,每个实例创建多少分库,这个需要综合考虑。一般一个实例创建4-8个库就可以了。
四、框架对比
1. 当当sharding-jdbc
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
这种是在jdbc级别的框架,跟tddl是一个设计思路,通过侵入业务代码(依赖相关jar包),修改sql的方式达到路由的目的,这种的无需数据库端任何的支持,只需要在数据库中创建好对应的数据库和表即可,然后配置对应的路由规则,sharding-jdbc就会在执行sql时根据配置的规则,自动改写sql,达到访问对应的数据库中的对应表。
2、mycat
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
mycat是一个数据库的代理,通过实现
优势
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。业界优秀的开源项目和创新思路被广泛融入到MYCAT的基因中,使得MYCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
MYCAT背后有一支强大的技术团队,其参与者都是5年以上软件工程师、架构师、DBA等,优秀的技术团队保证了MYCAT的产品质量。
MYCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设。
3、DRDS
DRDS 是一款基于 MySQL 存储、采用分库分表技术进行水平扩展的分布式 OLTP 数据库服务产品,支持 RDS for MySQL 以及 POLARDB for MySQL,产品目标旨在提升数据存储容量、并发吞吐、复杂计算效率三个方面的扩展性需求。
DRDS 核心能力采用标准关系型数据库技术实现,构建与公共云( cloud native ),配合完善的管控运维及产品化能力,使其具备稳定可靠、高度可扩展、持续可运维、类传统单机 MySQL 数据库体验的特点。
DRDS 于公共云和专有云环境沉淀打磨多年,历经各界天猫双十一核心交易业务及各行业阿里云客户业务的考验。承载大量用户核心在线业务,横跨互联网、金融&支付、教育、通信、公共事业等多行业,是阿里巴巴集团内部所有在线核心业务及众多阿里云客户业务接入分布式数据库的事实标准。
五. 如何迁移分库分表部署上线
1.停止部署法
大致思路就是,挂一个公告,半夜停机升级,然后半夜把服务停了,跑数据迁移程序,进行数据迁移。
(1)出一个公告,比如“今晚00:00~6:00进行停机维护,暂停服务”
(2)写一个迁移程序,读 db-old 数据库,通过中间件写入新库 db-new1 和 db-new2 ,具体如下图所示
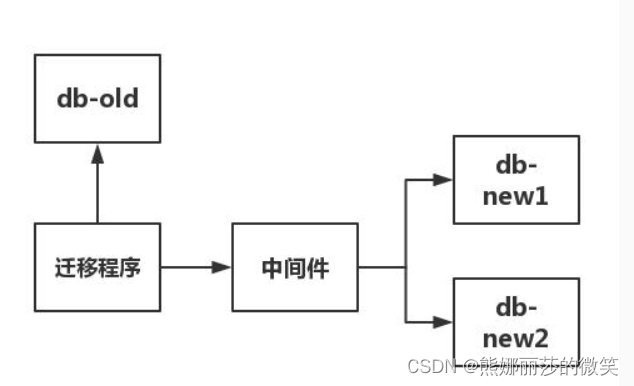
(3)校验迁移的前后一致性。没有问题就切换该部分业务到新库。
现在流行的中间件有两种,一种是proxy形式的,例如mycat,需要额外部署一台服务器。还有一种是client形式的sharding-jdbc,使用起来比较轻便,就是一个jar包,无需额外部署。比较推荐。
2.双写部署法,基于业务层
这个就是不停机部署法,这里需要引入两个概念:历史数据和增量数据。
(1)先计算你要迁移的那张表的max主键,在迁移过程中,只迁移了db-old中test_tb表中主键小于max的主键。
(2)在代码中,与test_tb有关的业务,多加一条往消息队列中法消息的代码,将写操作发送到消息队列中。
(3)系统上线,写一段迁移程序,只迁移db-old的数据,将大于记录主键的数据操作写入消息队列。
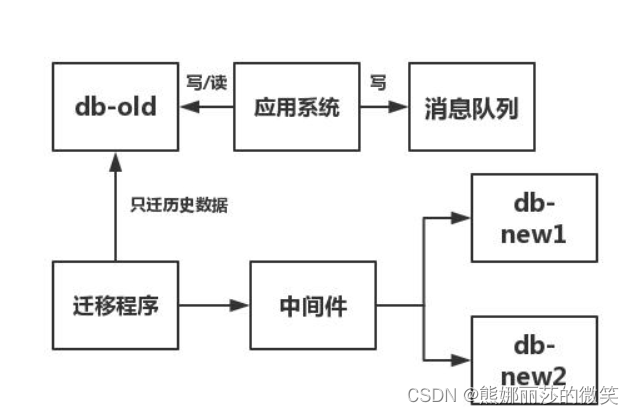
(4)将迁移程序下线,写一段订阅程序订阅消息队列中的数据,写入新库。
(5)新老库数据一致性验证,去除双写代码,将设计test_tb表的读写操作,指向新库。
3. 双写部署法,基于mysql的binlog。
(2)在代码中,与test_tb有关的业务,多加一条往消息队列中发消息的代码,将操作的sql发送到消息队列中,至于消息体如何组装,大家自行考虑。
1)打开binlog日志,系统正常上线就好
(2)还是写一个迁移程序,迁移历史数据。
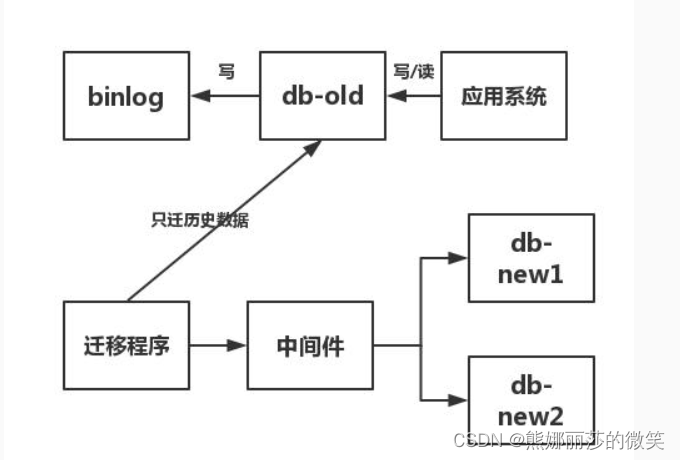
(3)写一个订阅程序,订阅binlog(mysql中有 canal 。至于oracle中,大家就随缘自己写吧)。然后将订阅到到数据通过中间件,写入新库。
(4)检验一致性,没问题就切库。
总结
站在巨人的肩膀上能省力很多,目前分库分表已经有一些较为成熟的开源解决方案,可以重点研究一下sharding-jdbc的操作。















 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









