







一. Elasticsearch 安装
ES 官网文档学习经常会查阅 RESTS APIS 页面(与索引,文档,字段有关的内容大部分在这个页面可以找到);
jdk 版本要求至少 1.8 以上(不过好像在 ES 启动的时候会自动绑定内置的 java 环境),进入 ES 官网之后使用迅雷下载解压,解压之后就可以使用了,熟悉 ES 解压之后的各个目录;
- bin:启动文件
- config:配置文件:log4j2.properties:日志配置文件;jvm.options:java 虚拟机的相关配置;
- elasticsearch.yml:elasticsearch 的配置文件(默认 9200 端口);
- lib:相关 jar 包,例如基于 Lucene 的相关 jar 包;
- modules:功能模块
- plugins:插件模块,例如 IK 分词器,可以复制到 plugins 目录下就可以使用了;
- logs:日志;
二. Elasticsearch 启动
进入 ES 解压之后的 bin 目录,双击 elasticsearch.bat 文件或者使用以命令行方式启动elasticsearch.bat 文件,当 ES 正常启动的时候不会显示报错信息,而且会生成 elastic 用户以及密码,配置 kibana 的 token 等信息(我的 elasticsearch 版本是8.2.0):
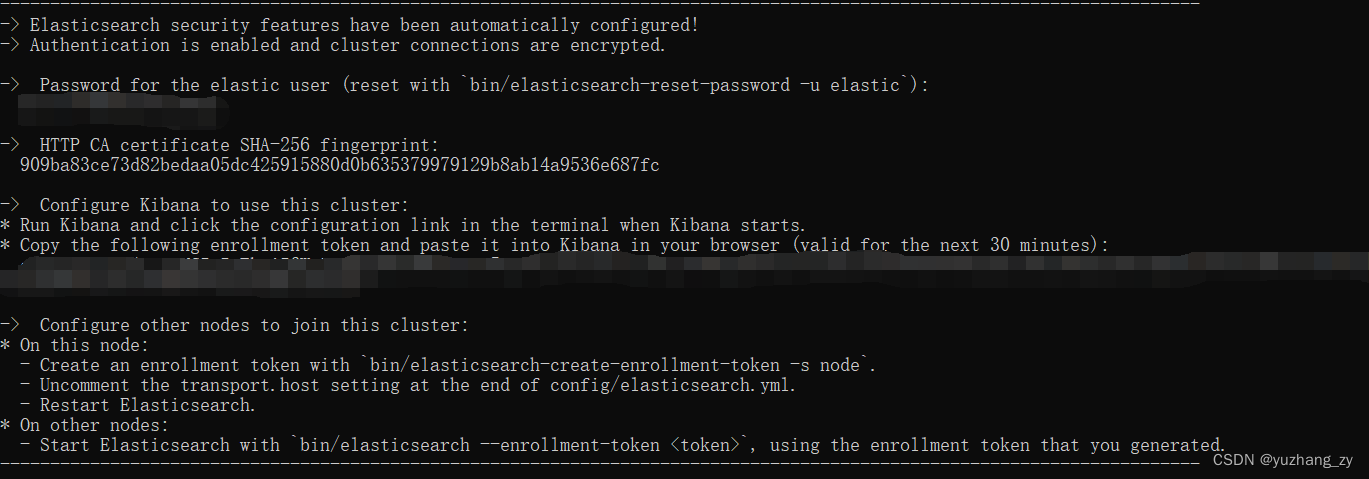
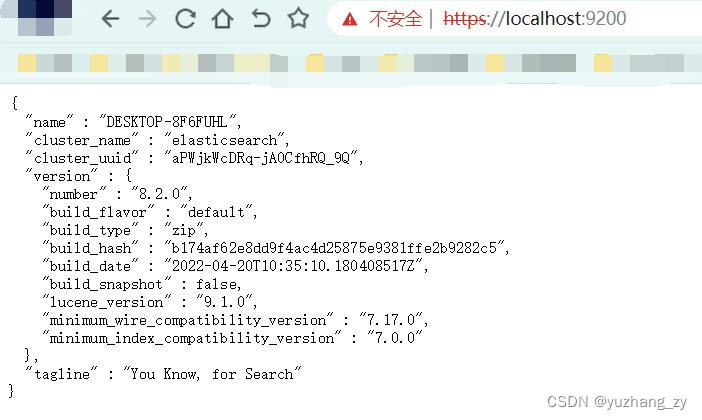
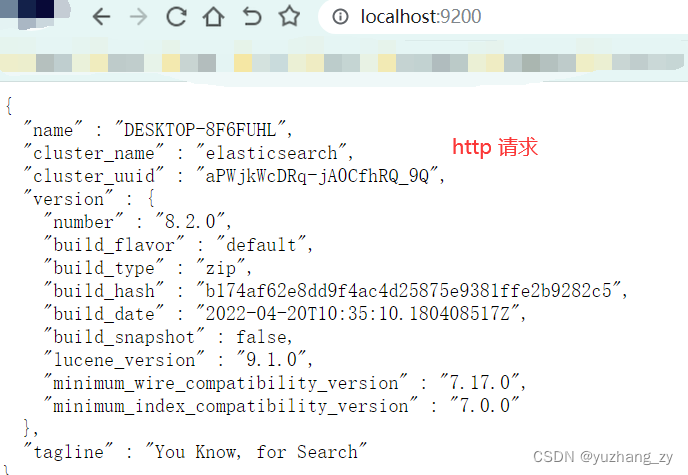
我们可以在浏览器中使用 ip 地址:9200(例如:https://12.20.20.15:9200)访问或者使用https://127.0.0.1:9200 访问,注意是 https 请求,这个时候会显示不安全的连接此时我们可以点击转到这个连接,转到这个连接之后需要输入 elasticsearch 的用户名和密码,用户名可以输入:elastic,密码输入使用 elasticsearch.bat 文件启动成功之后生成的密码(上图中生成的密码),成功登陆之后我们可以在页面中看到下面的信息:
安装可视化界面:es head 插件,head 插件可以方便看到 es 集群节点、索引和分片信息,安装 head 插件需要依赖 nodejs 和 grunt 环境,head 插件下载地址:https://gitee.com/cyberton/elasticsearch-head/repository/archive/master.zip:
安装 ES head 插件步骤:1. 安装 nodejs:在官网下载 nodejs 按照提示进行安装;在 cmd 命令行中使用 node -v 检查是否可以显示 nodejs 版本;2. 进入到 nodejs 安装目录,使用 cmd 命令进入到这个nodejs 安装目录,使用命令:npm install -g grunt -cli 安装;3. 进入到下载好的 es head 插件目录下,使用命令:npm install(这个命令下载很慢很有可能下载失败);或者是使用 cnpm install (在 cmd 命令行中先使用:npm install -g cnpm --registry=https://registry.npm.taobao.org 命令安装淘宝镜像,这样后面就可以使用 cnpm install 命令快速安装)下载 head 插件需要的各种依赖:

安装好了上面的环境之后进入到 head 插件目录,可以发现多了一个node_modules 文件夹,里面保存的就是各种下载好的依赖:
在 head 目录的 cmd 模式下然后使用命令:npm run start:

在浏览器中访问可以得到下面的页面:
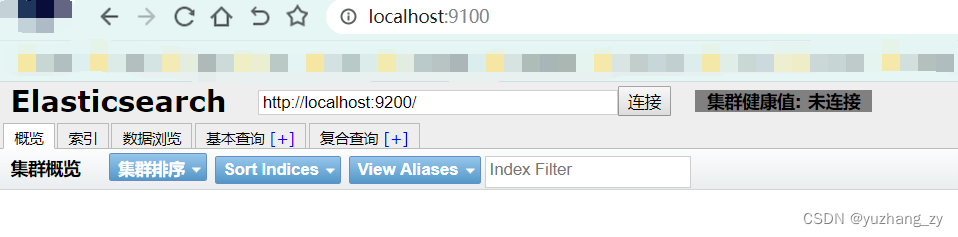
9100 访问 9200 就是跨域问题,如何解决这个问题呢?把 elasticsearch 关掉,在 elasticsearch 解压目录下编辑 elasticsearch.yml 文件,添加:http.cors.enabled: true 开启跨域;http.cors.allow-origin: "*"(运行所有人访问)可以在 gitee 上找到这个插件的相关使用说明:
http.cors.enabled: true # 允许跨域访问
http.cors.allow-origin: "*" # "*"表示所有域名但是修改完成之后点击连接之后发现还是无法连接,使用快捷键 fn + f12 打开浏览器的开发者模式,查看点击连接发送的请求,发现出现了 401 用户没有权限访问的错误,将 elasticsearch/config 目录下的 elasticsearch.yml 文件中的:xpack.security.enabled: true 修改为 false 才可以使用 head 插件正常访问 http 请求的 9200 端口,如果为 true 在浏览器中会报 401 没有权限的错误(报错的时候连接的是 https 请求),修改为 false 之后在浏览器中需要通过 http 请求来访问 9200 端口,默认这个属性值设置的是 true,官方推荐将其设置为 true 这样使用才比较安全,先将xpack.security.enabled 这个属性修改为 false,后面再看看还有哪些解决方案:
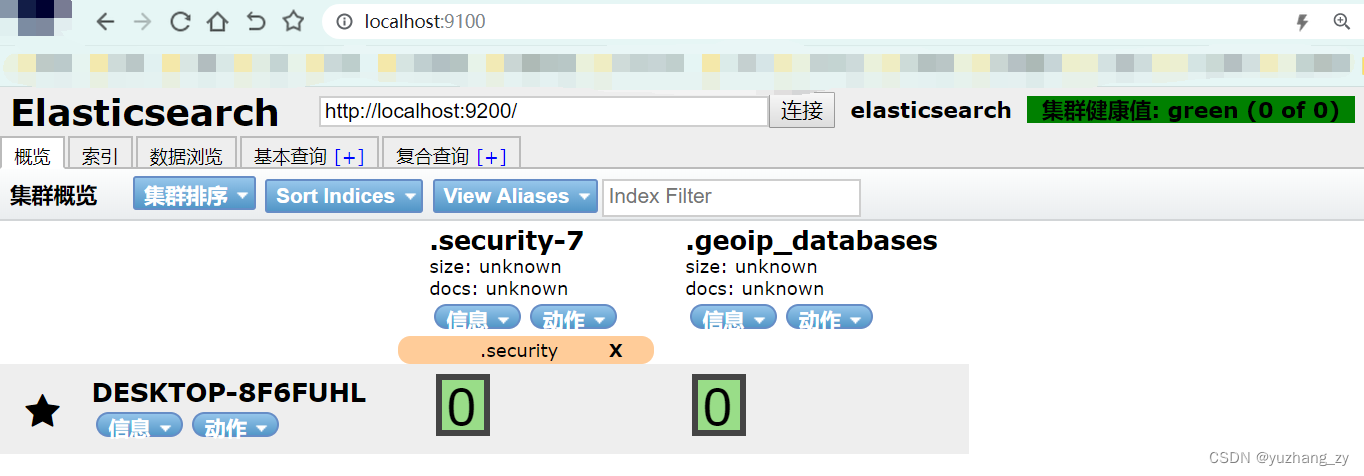
es 中的索引可以看成是数据库;
三. Kibana 的安装
ELK 是 Elasticsearch、Logstash、Kibana 三大开源框架首字母大写简称,市面上也被成为 Elastic Stack,其中 Elasticsearch 是一个基于 Lucene、分布式、通过 Restful 方式进行交互的近实时搜索平台框架;像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用 Elasticsearch 作为底层支持框架,可见 Elasticsearch 提供的搜索能力确实强大,市面上很多时候我们简称 Elasticsearch 为 es。
Logstash 是 ELK 的中央数据流引擎,用于从不同目标(文件/数据存储/MQ) 收集的不同格式数据,经过过滤后支持输出到不同目的(文件/MQ/redis/elasticsearch/kafka等)
Kibana 可以将 elasticsearch 的数据通过友好的页面展示出来,提供实时分析的功能。市面上很多开发只要提到 ELK 能够一致说出它是一个日志分析架构技术栈总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。(收集清晰数据 Logstash --> 搜索,存储 elasticsearch --> 数据展示 Kibana )
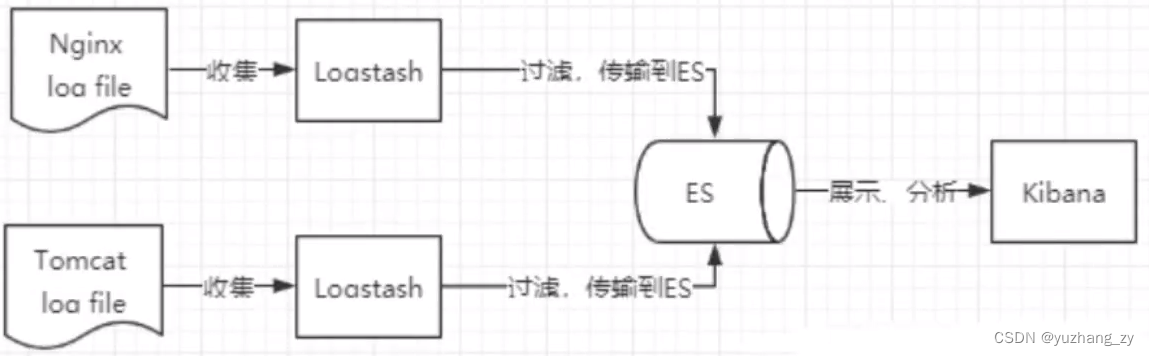
Kibana 是一个针对 Elasticsearch 的开源分析及可视化平台,用来搜索、查看交互存储在 Elasticsearch 索引中的数据,使用Kibana 可以通过各种图表进行高级数据分析及展示,Kibana 让海量数据更容易理解,它操作简单,基于浏览器的用户界面可以快速创建仪表板 (dashboard) 实时显示 Elasticsearch 查询动态,设置 Kibana 非常简单,无需编码或者额外的基础架构,几分钟内就可以完成 Kibana 安装并启动 Elasticsearch 索引监测。
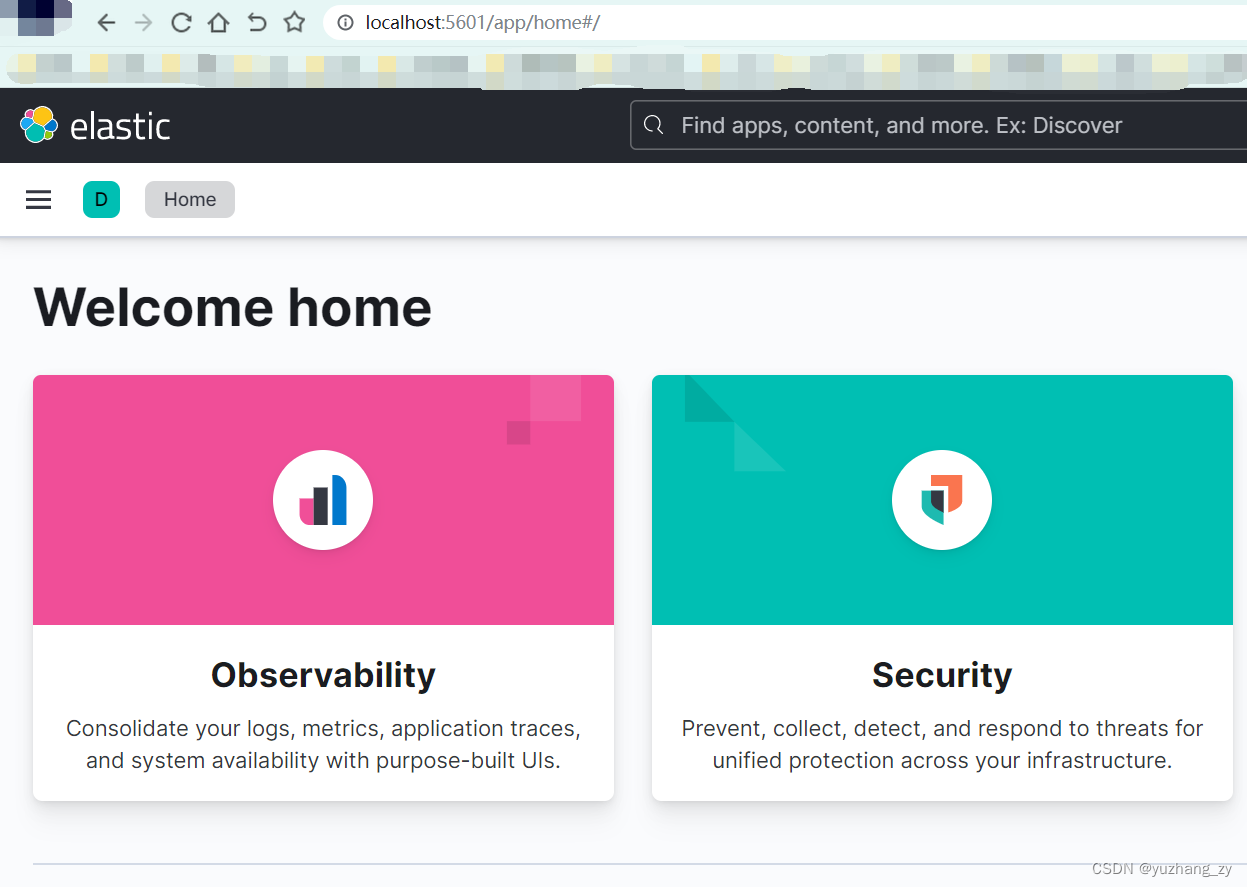
1. 进入 Kibana 的解压目录,双击启动 kibana.bat,kibana 默认是 5601 端口;2. 在浏览器中输入http://localhost:5601/ 访问测试:
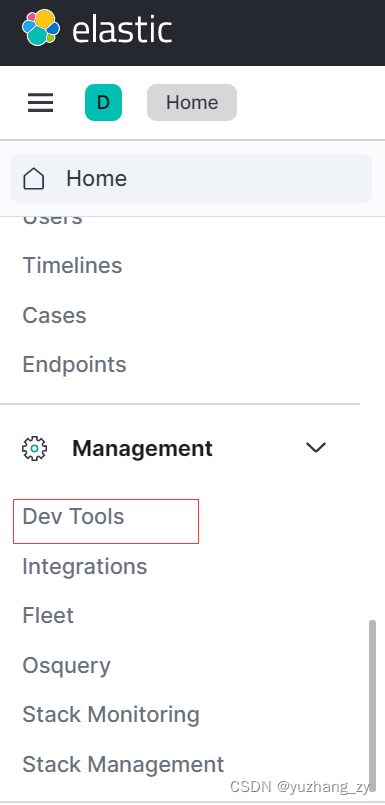
3. 开发工具:(postman,curl,head,谷歌浏览器插件),这里使用 kibana 进行测试,找到面板中的开发工具,之后我们的命令会写到这个面板:
我们可以显示的 kibana 页面修改为中文,找到 kibana.yml 文件将注释打开并且修改为(kibana 中有一个默认的插件文件夹 x-pack,里面可以找到国际化的相关文件),修改之后重启 kibana 然后在浏览器中访问 kibana 页面:
i18n.locale: "zh-CN"在浏览器中访问可以观察到 kibana 的中文页面:
四. ES 核心概念理解
elasticsearch 是面向文档,关系型数据库和 elasticsearch 客观的对比:
Relational DB Elasticsearch
数据库 (database) 索引 (indices)
表 (tables) types
行 (rows) documents
字段 (columns) fields
elasticsearch (集群) 中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计:
elasticsearch 在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移;(一个人就是一个集群,默认的集群名字就是 elasticsearch)
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2,当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引-->类型--> 文档,通过这个组合我们就能搜索到某个具体的文档,注意:id 不必是整数,实际上它是个字符串。
文档:
文档就是一条条的数据,之前说 elasticsearch 是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch 中,文档有几个重要属性:
1. 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含 key:value;
2. 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的(json 字符串);
3. 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在 elasticsearch 中,对于字段是非常灵活的,有时候我们可以忽略该字段,或者动态的添加一个新的字段;尽管我们可以随意的新增或者忽略某个字段,但是每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型,因为 elasticsearch 会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在 elasticsearch 中,类型有时候也称为映射类型。
类型:
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如 name 映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 elasticsearch 是怎么做的呢?elasticsearch 会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch 就开始猜,如果这个值是 18,那么 elasticsearch 会认为它是整型,但是 elasticsearch 也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用;
索引:
索引可以理解为数据库;索引是映射类型的容器,elasticsearch 中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置,然后它们被存储到了各个分片上了,我们来研究下分片是如何工作的。物理设计:节点和分片如何工作?一个集群至少有一个节点,而一个节点就是一个 elasricsearch 进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个 5 个分片 (primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
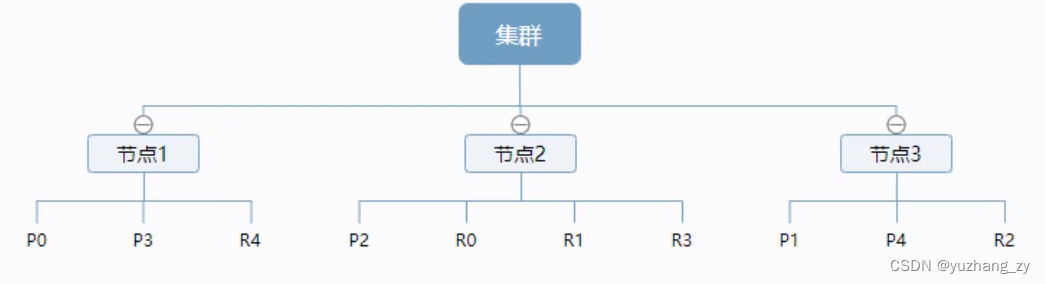
上图是一个有 3 个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失,实际上一个分片是一个 Lucene 索引,一个包含倒排索引的文件目录,倒排索引的结构使得 elasticsearch 在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字;
倒排索引
elasticsearch 使用的是一种称为倒排索引的结构,采用 Lucene 倒排索作为底层,这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
study every day,good good up to forever #文档1包含的内容
To forever,study every day,good good up #文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者 tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
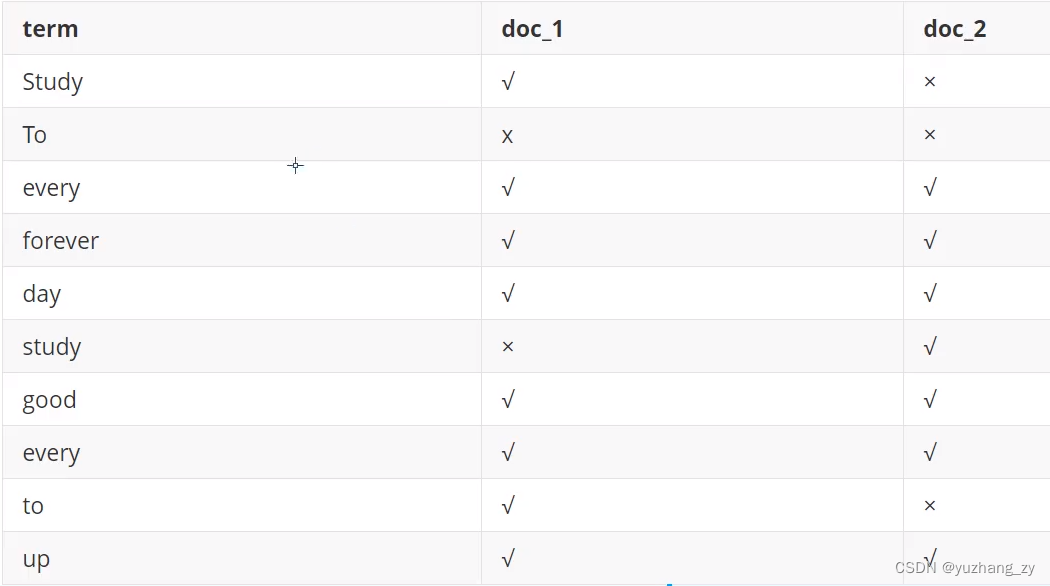
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在这两个包含关键字的文档都将返回;再来看一个示例,比如我们通过博客标签来搜索博客文章,那么倒排索引列表就是这样的一个结构:
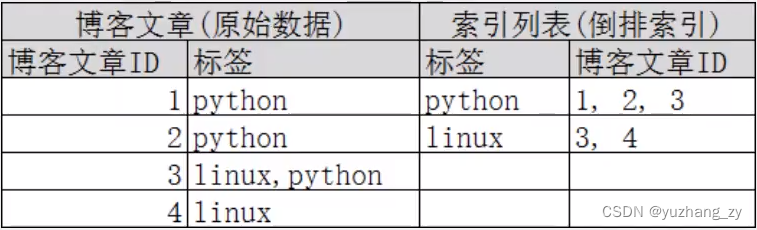
如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章 id 即可,完全过滤掉无关的数据提高效率;elasticsearch 的索引和 Lucene 的索引对比:在elasticsearch中,索引这个词被频繁使用,这就是术语的使用,在elasticsearch中,索引被分为多个分片,每个分片是一个 Lucene 的索引,所以一个 elasticsearch 索引是由多个 Lucene 索引组成的;如无特指,说起索引都是指 elasticsearch 的索引。接下来的一切操作都在 kibana 中开发者工具下的控制台里完成 ;
五. IK 分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中文分词器 IK 来解决这个问题。
IK 提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word 为最细粒度划分;
安装 IK 分词器:
1. 从 github上下载 中文 IK 分词器(注意要与 ES 版本对应上);
2. 在 elasticsearch 解压的 plugins 目录下将 IK 分词器的所有文件拷贝进去即可;
3. 重启观察 ES ,可以看到 IK 分词器插件被加载成功了:

也可以使用命令来查看:
 4. 使用 Kibana 进行测试,判断 ik_smart 和 ik_max_word 的区别:
4. 使用 Kibana 进行测试,判断 ik_smart 和 ik_max_word 的区别:
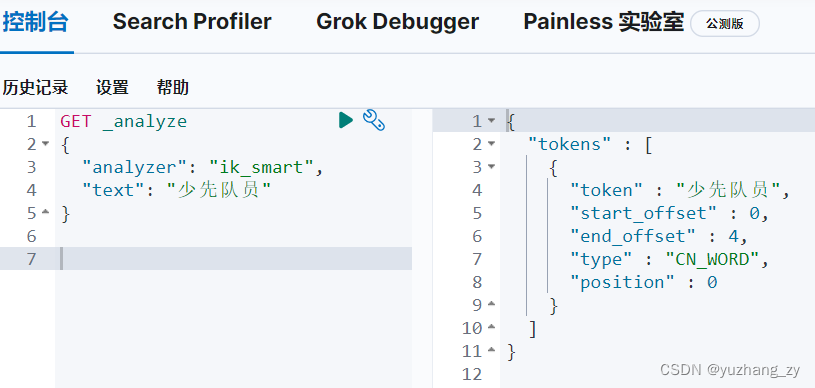
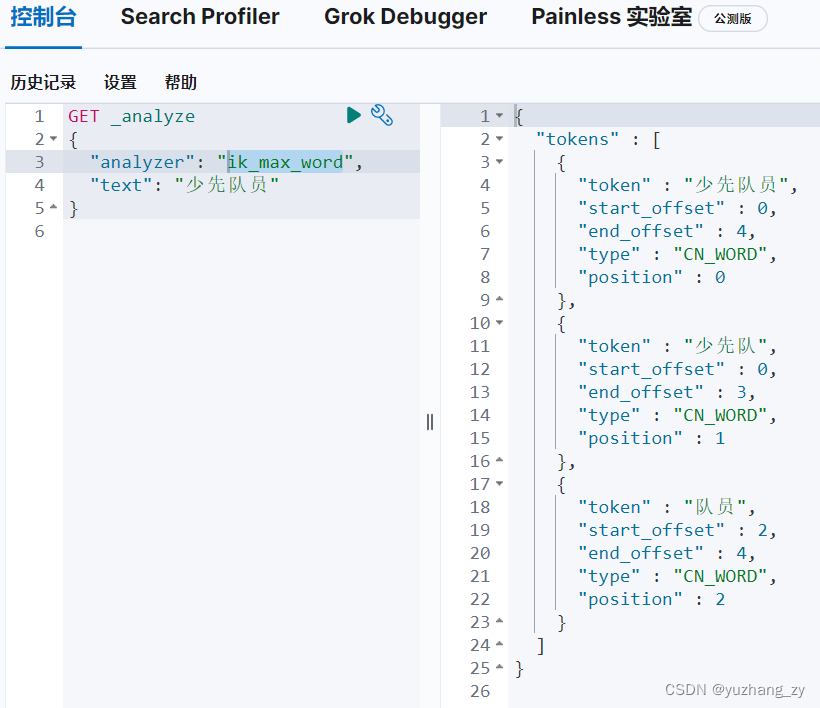
ik_max_word 为最细粒度划分,穷尽词库的可能,有的时候我们有些词不能够分开,此时就需要将自己需要的词加入到 IK 分词器的字典中,创建一个.dic 后缀的文件,将自己需要的词加入到这个文件中,在IKAnalyzer.xml 文件中配置当前.dic 文件:
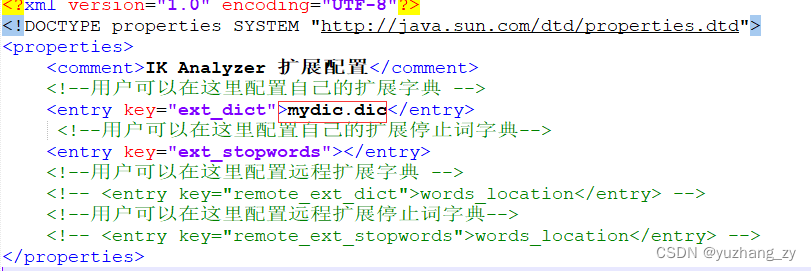

重启 ES 观察加载的过程,可以发现会加载自定义的字典文件,后面我们就可以将自己的词加入到字典中即可:
![]()
可以发现之前之前被划分开的词设置自定义字典之后又变成了一个词语:
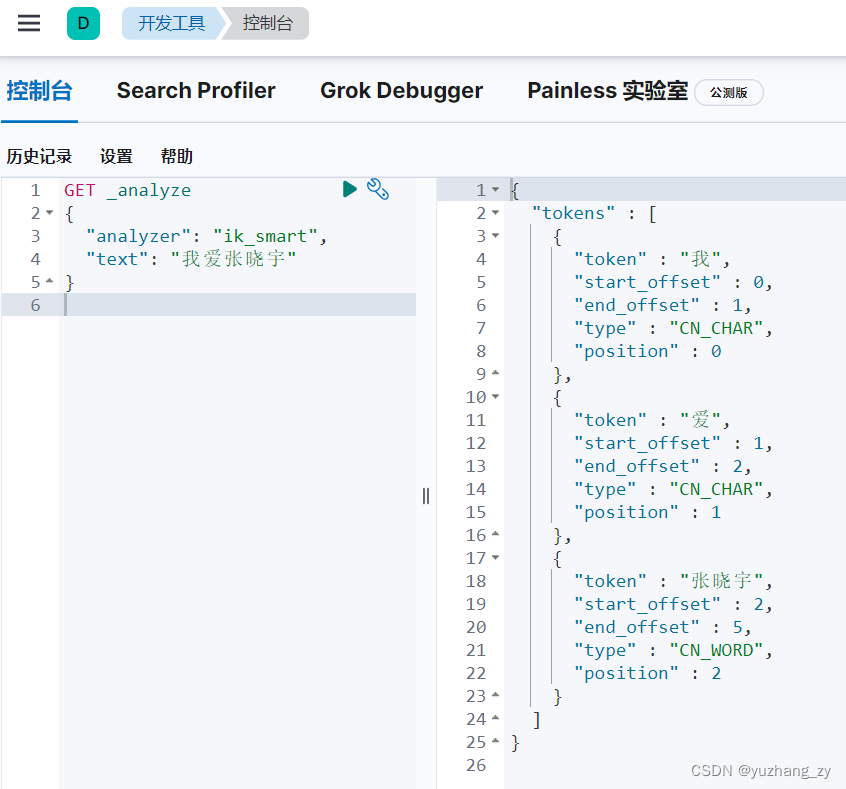
六. Rest 风格操作
不同版本的 ES restful 风格差别还是蛮大的,下面是 ES 8.2.0 版本的 restful 风格相关规则。 restful 是一种软件架构风格而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件,基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本 restful 命令可以参照官方文档的说明(不同版本的 elasticsearch restful 命令差别还是挺大的:直接在 es 页面中搜索找到 rest api,官方文档说明的还是挺详细的)
基本测试:
索引的基本操作
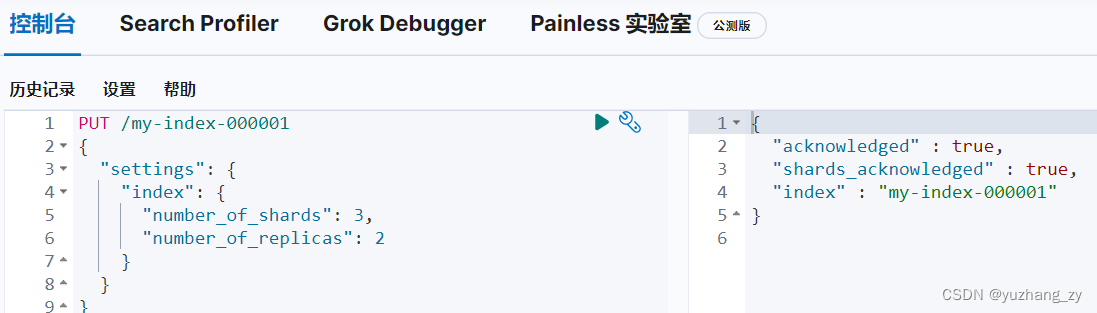
1. 使用 PUT 创建一个索引:
创建与文档相关的索引,与 doc 文档相关的创建索引的规则如下图所示,target 为目标数据流或者索引的名字,<_id>为 文档 id 编号,不写的时候会自动生成一个文档 id,


数据类型:
字符串类型:text、keyword;
数值类型:long,integer,short,byte,double,float,half float,scaled float;
日期类型:date;
布尔值类型:boolean;
二进制类型:binary;
创建一个映射,映射中规定字段的类型,但是后面由于映射类型类似于关系型数据库的时候出现了一些问题所以到后面从 7.x 版本的 es 移除掉了;
2. 使用 GET 请求获得索引(在创建索引的时候 8.x 版本不需要指定具体类型,es 会默认分配配置字段类型)
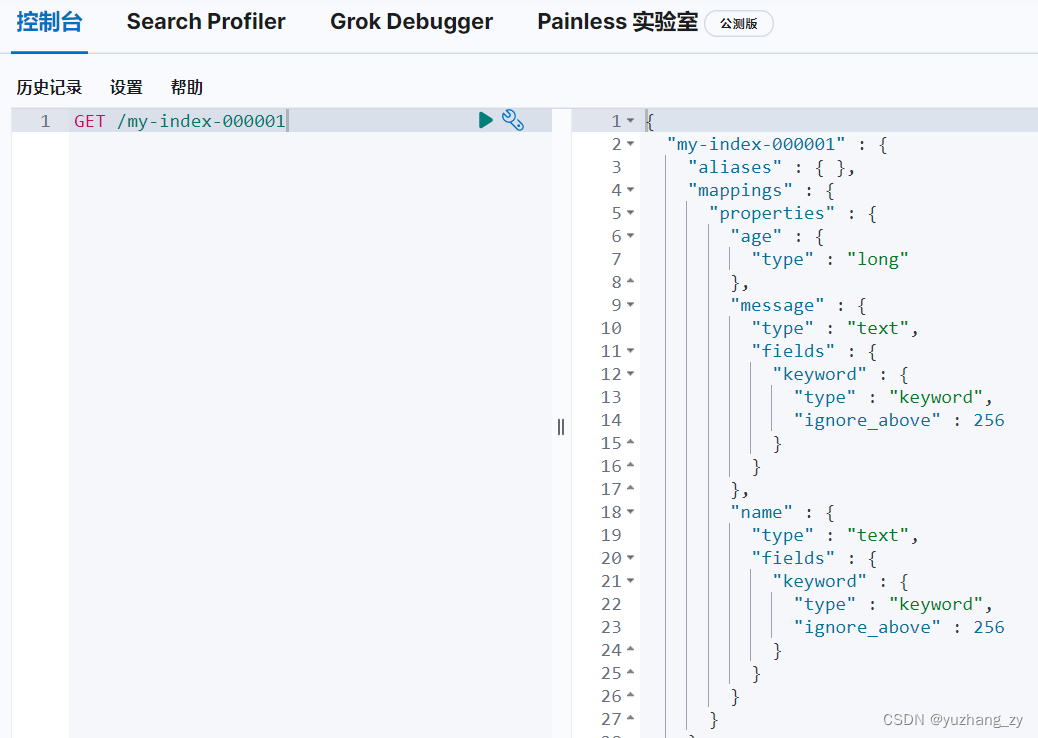

3. 修改索引
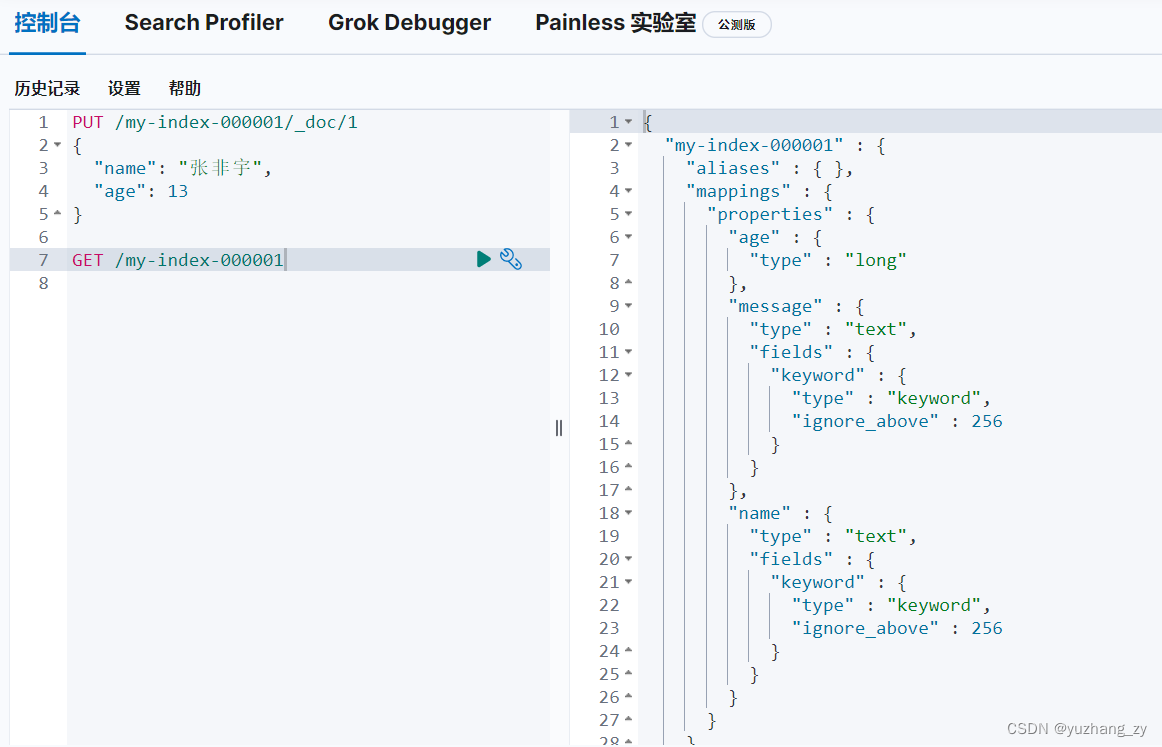
第一种是使用 PUT 请求可以覆盖值:PUT /index_name/_doc/<_id>(有一个弊端是如果有的字段漏了那么对应的新的字段就会没了):
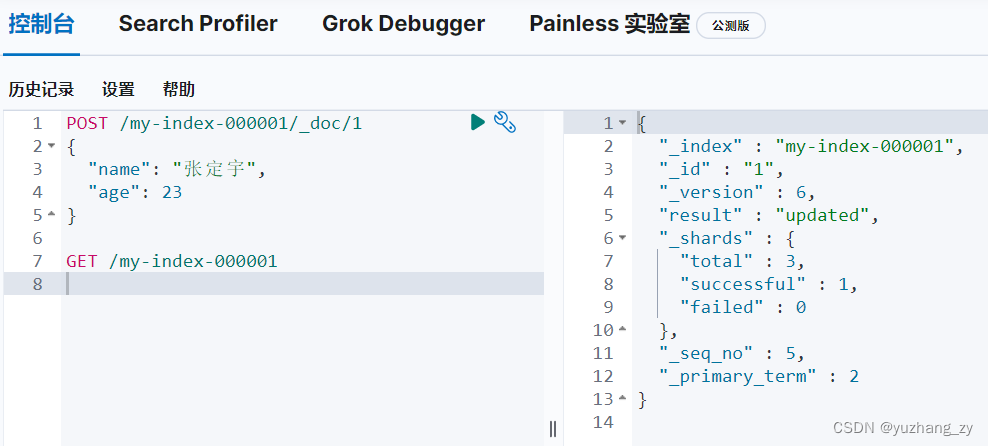
第二种是使用 POST 请求进行更新:
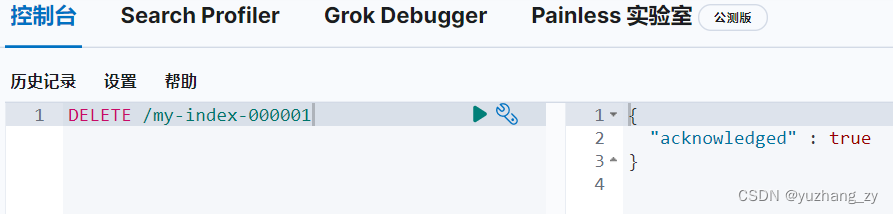
4. 删除索引
根据请求判断删除的是索引还是文档:
文档的基本操作
ES 中文档的基本操作是重点,并且还有一些复杂操作;
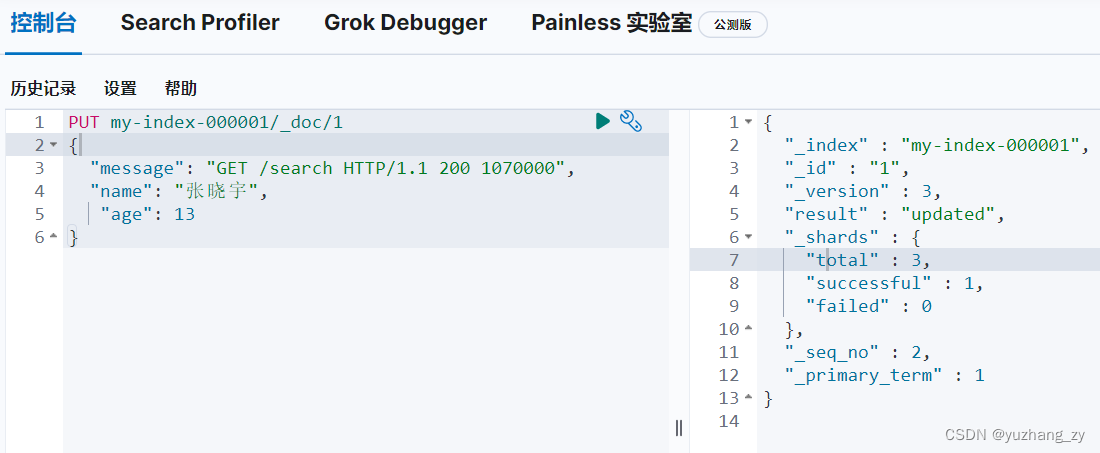
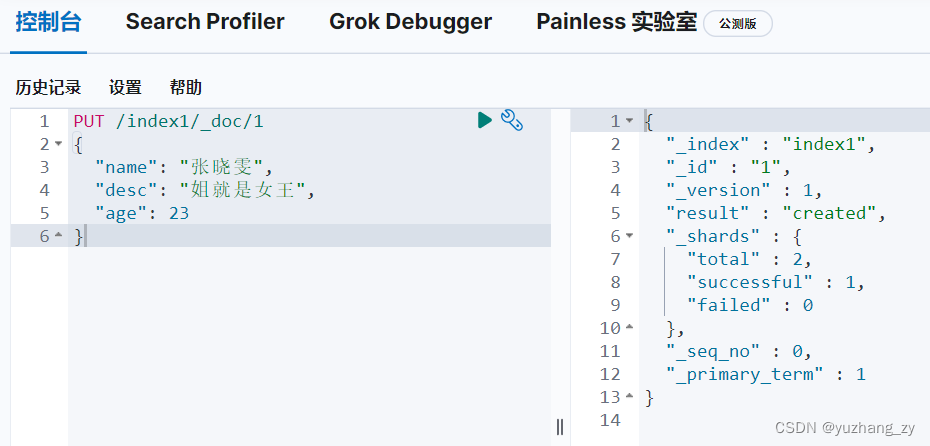
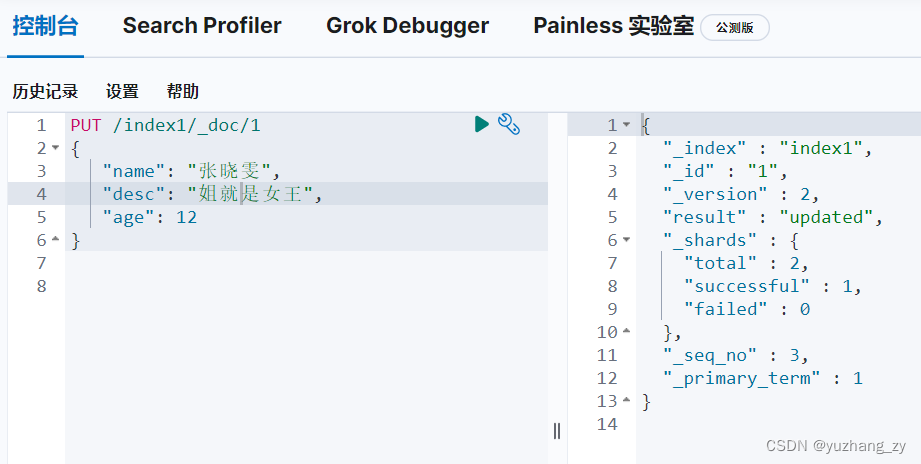
PUT /index1/_doc/1
{
"name": "张晓雯",
"desc": "姐就是女王",
"age": 12
}
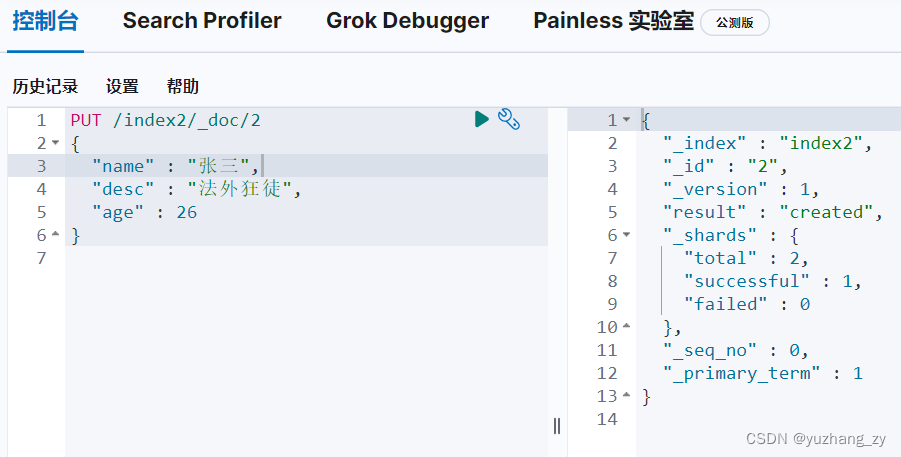
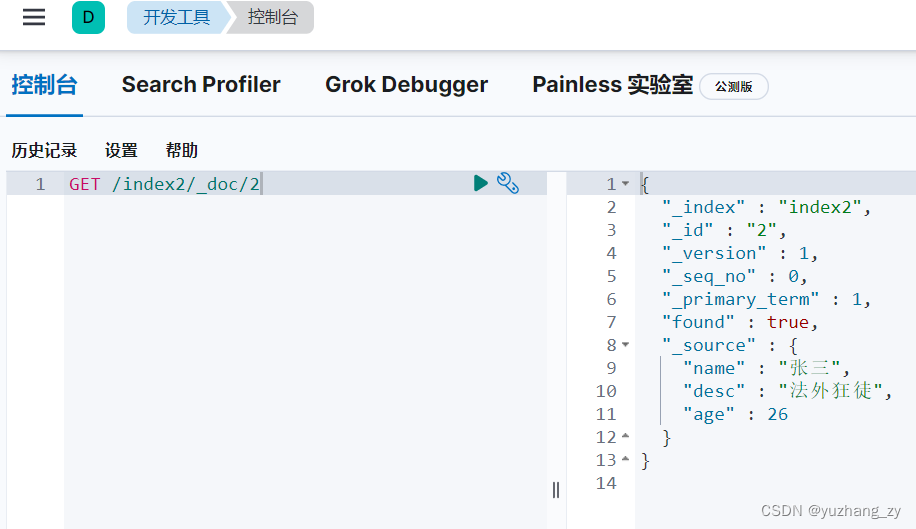
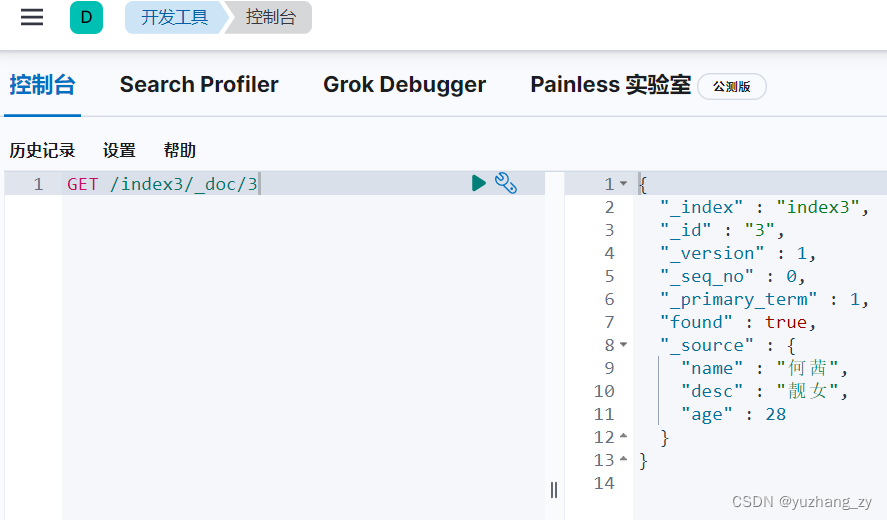
POST 请求更新(如果更新的字段没有写全那么这些字段就置为空了):
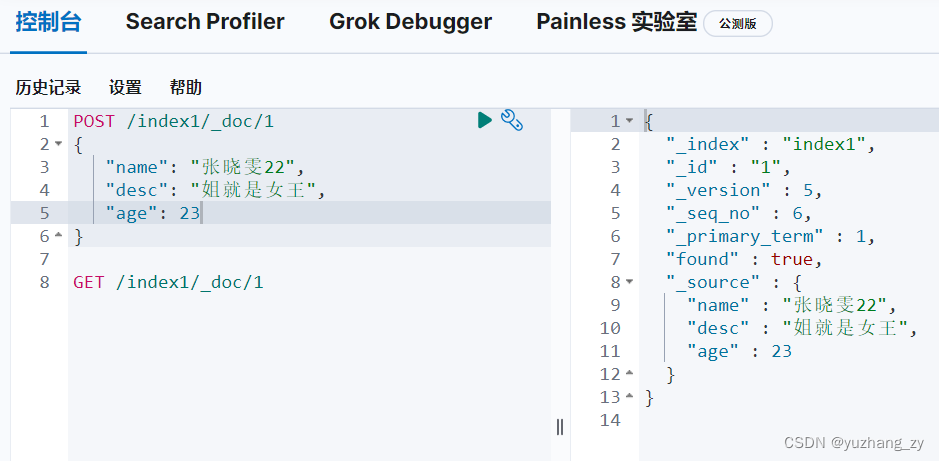
POST 请求更新则更为推荐使用,因为可以更新任意一个字段:
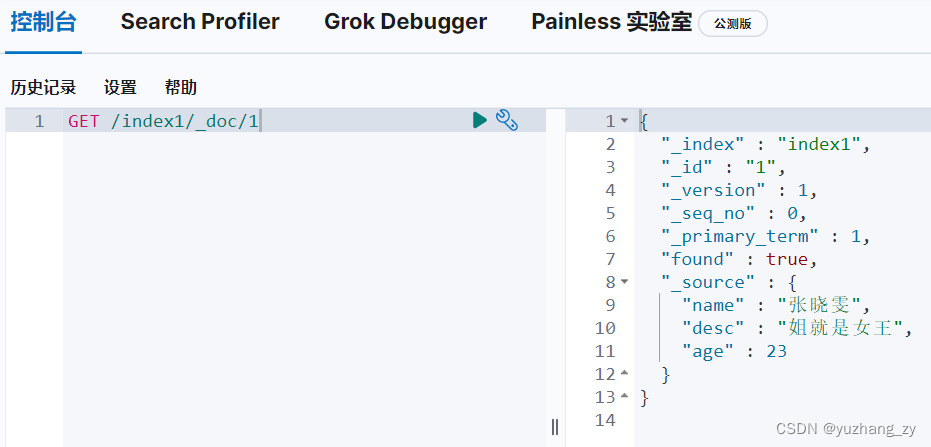
搜索:
1. 简单搜索:GET /index_name/,GET /index_name/_doc/<_id>
2. 复杂搜索:select(排序,分页,高亮,模糊查询,精准查询);















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









