







 本文介绍了如何使用Python进行数据处理和可视化,包括读取CSV文件、利用jieba进行分词、生成词云图以及地图热力图。代码中涉及的模块有pandas、jieba、matplotlib、seaborn和pyecharts,通过这些工具分析电影评论,展示评论来源城市的分布,并对评论内容生成词云图。同时,文章提供了背景图片、字体设置及自定义背景颜色的方法。
本文介绍了如何使用Python进行数据处理和可视化,包括读取CSV文件、利用jieba进行分词、生成词云图以及地图热力图。代码中涉及的模块有pandas、jieba、matplotlib、seaborn和pyecharts,通过这些工具分析电影评论,展示评论来源城市的分布,并对评论内容生成词云图。同时,文章提供了背景图片、字体设置及自定义背景颜色的方法。
距上一篇 获取影评的txt后,jieba生成云词。
嘻嘻,都是搬运工啦。我不管,整理过后,就是自己的了————都是站在巨人的肩膀上编码,有何不同
文章地址:python抓取猫眼电影评论,200多行代码,哈哈
示例:

字体 windows自带的一个隶书,你也可以自行修改。背景图也是自定义哦,记得一定是白色底的
云词背景图

文中所需模块没有的,自行安装。很简单 pip install xxx , 最新版就是了。注释自行删除
附上代码:
from pyecharts.charts.base import default
from wordcloud import WordCloud, STOPWORDS
import pandas as pd
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Geo
from pyecharts import options as opts
from pyecharts.globals import ChartType, SymbolType
from pyecharts.exceptions import NonexistentCoordinatesException
import sys, os, time, util, win_w_h
__dir__ = os.path.dirname(os.path.abspath(__file__))
# sys.path.append(__dir__)
# sys.path.append(os.path.abspath(os.path.join(__dir__, '../common')))
back_coloring_path = r'static\blove.jpg' # 设置背景图片路径
fonts_path = r'static\STXINGKA.TTF' # 为matplotlib设置中文字体路径没
root_path = util.JarProjectPath.project_root_path('py')
# 分析text,生成分布图html 和 云词图
@util.run_time
def analysis(filepath):
with open(filepath, encoding='UTF-8') as f:
data = pd.read_csv(f,sep=',',header=None,encoding='UTF-8',names=['date','nickname','city','rate','comment'])
# 获取文件的拼音,作为文件名。
n, f = os.path.basename(filepath).split('.')[:2]
filename = util.pinyin(n)
# 云词
jb(data, filename)
city = data.groupby(['city'])
rate_group = city['rate']
city_com = city['city'].agg(['count'])
city_com.reset_index(inplace=True)
data_map = [(city_com['city'][i], int(city_com['count'][i])) for i in range(0,city_com.shape[0])]
# print(data_map)
ddict = dict(data_map)
# # 去掉坐标不存在
if ddict.__contains__('普洱'):
ddict.pop('普洱')
if ddict.__contains__('海西'):
ddict.pop('海西')
if ddict.__contains__('黔南'):
ddict.pop('黔南')
if ddict.__contains__('延边'):
ddict.pop('延边')
if ddict.__contains__('陵水'):
ddict.pop('陵水')
# print(data_map, '------------', ddict, '------------', [(key, val) for key, val in ddict.items()])
# 地图划分
geo_heatmap_dynamic([(key, val) for key, val in ddict.items()], filename)
#评分分析
# rate = rate_group.value_counts()
# sns.set_style("darkgrid")
# bar_plot = sns.barplot(x=rate.index,y=(rate.values/sum(rate)),palette="muted")
# plt.xticks(rotation=90)
# plt.show()
# 通过jieba分词 生成云词图
def jb(data, filename=str(round(time.time() * 1000))):
#分词
comment = jieba.cut(str(data["comment"]),cut_all=False)
wl_space_split= " ".join(comment)
#导入背景图
backgroud_Image = plt.imread(back_coloring_path)
stopwords = STOPWORDS.copy()
# print(" STOPWORDS.copy()",help(STOPWORDS.copy()))
#可以自行加多个屏蔽词,也可直接下载停用词表格
stopwords.add("好看")
stopwords.add("喜欢")
# print(stopwords)
# print(wl_space_split)
#设置词云参数
#参数分别是指定字体/背景颜色/最大的词的大小,使用给定图作为背景形状
wc = WordCloud(width=1024,height=768,background_color='white',
mask = backgroud_Image,font_path=fonts_path,
stopwords=stopwords, max_font_size=200,
random_state=40)
#将分词后数据传入云图
wc.generate_from_text(wl_space_split)
# plt.imshow(wc)
# plt.axis('off')#不显示坐标轴
# plt.show()
#保存结果到本地
wc.to_file(f'{root_path}files/{filename}.jpg')
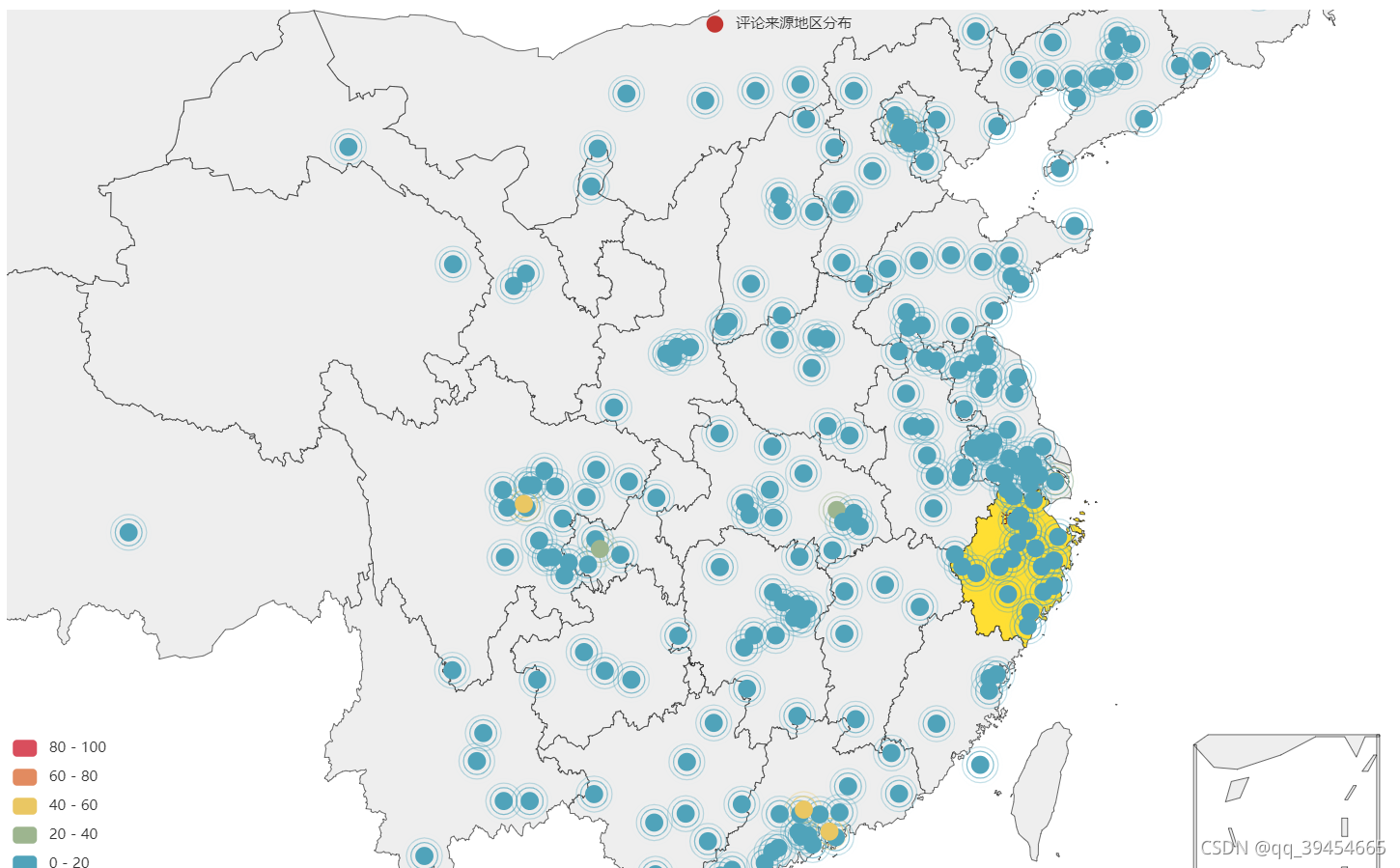
# 生成评论分布图
def geo_heatmap_dynamic(data, filename=str(round(time.time() * 1000))) -> Geo:
# test_data_ = [("测试点1", 116.512885, 39.847469), ("测试点2", 125.155373, 42.933308), ("测试点3", 87.416029, 43.477086)]
# count = [1000, 2000, 500]
# address_ = []
# json_data = {}
# for ss in range(len(test_data_)):
# json_data[test_data_[ss][0]] = [test_data_[ss][1], test_data_[ss][2]]
# address_.append(test_data_[ss][0])
# json_str = json.dumps(json_data, ensure_ascii=False, indent=4)
# with open('test_data.json', 'w', encoding='utf-8') as json_file:
# json_file.write(json_str)
wh = win_w_h.get_real_resolution_ratio(1.5)
# print(wh, wh[0], wh[1])
try:
ops = opts.InitOpts(width = f'{wh[0]}px', height = f'{wh[1]}px')
c = (
Geo(init_opts= ops)
.add_schema(maptype="china", itemstyle_opts=opts.ItemStyleOpts(color="#eeeeee", border_color="#111"),)
# .add_coordinate_json(json_file='test_data.json') # 加入自定义的点
.add(
"评论来源地区分布",
# [list(z) for z in zip(province_name, province_count)],
# [('广州', 100), ("乌鲁木齐", 66), ("济南", 99), ("武汉", 88)],
data,
# HEATMAP MAP GEO
type_=ChartType.EFFECT_SCATTER,
symbol_size = 15 #标记大小
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True, max_ = 100), # is_piecewise=True 表示切分legend范围
title_opts=opts.TitleOpts(title="")
)
)
c.render(path=os.path.join(__dir__, f'../files/{filename}.html'))
except NonexistentCoordinatesException as e:
print(e)
sys.exit(1)
# return c
if __name__ =='__main__':
filepath = r'files\我的青春有个你.txt'
analysis(filepath)
# print(util.pinyin('我爱你'))
print(1)
#analysis(movie_id)
#print(mv.get('videoName', default='找不到字段'))
# print(os.path.join(__dir__, f'../files/geo/geo{str(round(time.time() * 1000))}.html'))
# c = geo_heatmap_dynamic()
# c.render(path=os.path.join(__dir__, f'../files/geo/geo{str(round(time.time() * 1000))}.html'))
# 上面的一些公共参数:
# symbol_size = 15 :表示标记大小为15。
# .set_series_opts(label_opts=opts.LabelOpts(is_show=False)):用于设置是否显示标签。
# .set_global_opts(visualmap_opts=opts.VisualMapOpts(is_piecewise=True, max_ = 1000), title_opts=opts.TitleOpts(title=""):is_piecewise=True表示切分legend,max_表示legend的最大值,title设置左上角标题。
# type_=ChartType.HEATMAP 等用于设置地图类型。
哦哦,对了,还有一个中文转拼音 文件名的,先安装模块哦。
import pypinyin
# 不带声调的(style=pypinyin.NORMAL)
def pinyin(word):
s = ''
for i in pypinyin.pinyin(word, style=pypinyin.NORMAL):
s += ''.join(i)
return s

















 4590
4590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









