








目录
3.1 Contrastive Learning as Dictionary Look-up
4.1 Linear Classification Protocol
- Title:Momentum Contrast for Unsupervised Visual Representation Learning
- Paper:https://arxiv.org/pdf/1911.05722.pdf
- Github:https://github.com/facebookresearch/moco
摘要
我们提出了 动量对比 (MoCo) 用于 无监督视觉表示学习。从对比学习作为字典查找 (look-up) 的角度来看,我们构建了一个 具有一个 队列 (queue) 和一个 移动平均编码器 (moving-averaged encoder) 的 动态字典。这使得动态 (on-the-fly) 建立一个大型且一致的字典能够促进对比无监督学习。MoCo 在 ImageNet 线性分类通用协议下提供了有竞争力的结果。更重要的是,MoCo 学习到的表示可以很好地迁移到下游任务中。MoCo 可在 PASCAL VOC、COCO 和其他数据集上的 7 个检测/分割任务中 优于 有监督的预训练竞争者,有时甚至远超。这表明,在许多视觉任务中,无监督和有监督表示学习之间的差距已在很大程度上被缩小。
一、引言
无监督表示学习在 NLP 中非常成功,如 GPT 和 BERT。但是有监督预训练在 CV 中仍占主导地位 (be dominant in),而无监督 CV 方法通常是落后的 (lag behind)。其原因可能在于它们 各自的信号空间的差异。语言 任务 具有 离散的信号空间 (words, sub-words 等),用于构建 tokenized 字典,该过程可以基于无监督学习。相比之下,CV 进一步关注字典构建,因为 (视觉的) 原始信号 处于一个 连续且高维的空间 中,且并非面向人类通信的结构 (例如,不像 words)。
最近的几项研究提出使用 与对比损失相关的方法 进行无监督视觉表示学习,并展示出了有前景的结果。尽管受到各种动机的驱动 (driven by various motivations),这些方法可以被认为是 构建动态字典。字典中的 key (tokens) 采样自数据 (如 images 或 patches),并由编码器网络表示。无监督学习训练编码器 以实施 字典查找 (look-up):一个经编码的 query 应与其匹配的 key 相似,而与其他 keys 不相似。学习被表述为 最小化对比损失。
从这个角度来看,假设构建字典的理想情况是:(i) 大型且 (ii) 在训练期间的演进/发展 (evolve) 具有一致性。直观地,一个更大的字典可以更好地采样潜在的 (underlying) 连续且高维的视觉空间,而字典中的 key 应由相同或相似的编码器来表示,以便它们与 query 的比较是一致的。然而,现有使用对比损失的方法会限制两个方面中一者 (稍后将在上下文中讨论)。
一个好的字典应同时具有以下两个特性
- 字典足够大型:字典越大则 key 越多,所能表示的视觉信息、视觉特征就越丰富 ,从而用 query 参与对比学习时,才越能学到图片的特征。反之,若字典很小,则模型很容易学习一些捷径来区分正、负样本 (过度拟合简单样本/特征),对大量真实数据的泛化很差。
- 编码的特征尽量保持一致性:字典里的 key 都应用相同/相似的编码器去编码得到,否则在模型查找 query 时,可以走一些捷径 —— 通过找到和 query 使用相同/相似的编码器的 key,而非真正与 query 含有相同/相似语义信息的 key。
对比学习方法在过去都至少被上述二者之一限制,而 MoCo 最大的贡献在于,使用队列以及动量编码器进行对比学习,解决该问题。
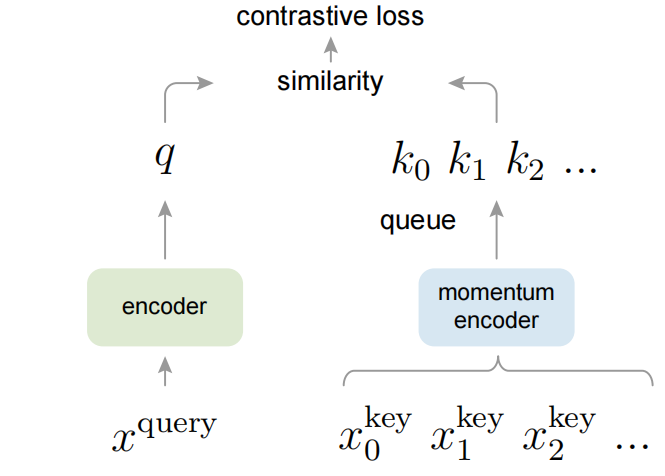
字典 keys {k0, k1, k2, …} 是由一组数据样本动态 (on-the-fly) 定义的。
keys 的字典被构建为一个队列,当前的 mini-batch 入队,最早的 mini-batch 出队,使之与 mini-batch 大小解耦。
keys 被一个缓慢更新 (slowly progressing) 的编码器编码,由 query 编码器的动量更新驱动。
这种方法为学习视觉表示提供了一个大型且一致的字典。
我们提出了动量对比 (MoCo),作为一种构建大型且一致的字典的方法,用于具有对比损失的无监督学习 (图 1)。字典 被维护为一个 数据样本的队列:当前的 mini-batch 入队,最早的 mini-batch 出队。该队列 将字典大小与 mini-batch 大小解耦,从而 允许字典变得大型。此外,由于 字典 keys 来自于前面的几个 mini-batch,此处提出了一个 缓慢更新 (slowly progressing) 的 key 编码器,作为 query 编码器的基于动量的移动平均 (momentum-based moving average) 来实现,以 保持一致性。
MoCo 是一种构建对比学习的动态字典的机制,可用于各种 前置/代理任务 (pretext task)。本文 following 最广泛应用的简单前置任务 —— 实例判别 (instance discrimination):若 query 和 key 是源自同一图像的经编码的视图 (views),则二者相匹配。利用这个前置任务,MoCo 显示出在 ImageNet 中在线性分类普通协议下的具有竞争力的结果。
无监督学习的一个主要目的是 预训练可通过微调迁移到下游任务的表示 (即特征)。在 7 个与检测/分割相关的下游任务中,MoCo 无监督预训练可超过 ImageNet 有监督预训练,(甚至) 在某些情况下远超 (by nontrival margins)。在实验中,探索了在 ImageNet 或 10 亿个 Instagram 图像集上预先训练过的 MoCo,证明了 MoCo 可在更真实、十亿图像规模和相对未知的 (uncurated) 场景中很好地工作。这些结果表明,MoCo 在很大程度上在许多 CV 任务中缩小了无监督和有监督表示学习之间的差距,并且在一些应用中可作为 ImageNet 有监督预训练的替代方案。
- 详见文末总结
二、相关工作
无监督/自监督 (自监督学习是无监督学习的一种形式。在现有文献中,它们的区别是非正式的。本文中,我们在 “没有人类注释的标签监督” 的意义上,使用了更经典的术语 “无监督学习”) 学习方法通常涉及两个方面:前置任务和损失函数。“前置” 一词意味着被解决的任务并非真正的兴趣,而为了学习良好的数据表示的用于真正目的 (如 下游任务)。损失函数 通常可独立于前置任务被调查/研究。MoCo 侧重于损失函数方面。接下来将讨论有关这两个方面的相关研究。
损失函数。定义损失函数的一种常见方法是 衡量 模型的预测 和 一个固定的 target 之间的差异,例如通过 L1 或 L2 损失重建输入像素 (如 自动编码器),或通过交叉熵或 margin-based 的损失将输入分类为预定义的类别 (如 8 个位置、color bins)。如下面所述,其他的替代方案也是可能的。
对比损失 衡量了 表示空间中样本对的相似度。有别于将输入与固定的 target 进行匹配,在对比损失公式中,target 可在训练过程中动态 (on-the-fly) 变化,并且可根据网络计算的数据表示来定义。对比学习是最近几项关于无监督学习的工作的核心,稍后将在上下文中详细阐述它(3.1 节)。
对抗损失 衡量了 概率分布之间的差异。这是一种广泛成功的无监督数据生成技术。在 (Adversarial feature learning, Large scale adversarial representation learning) 中探讨了表示学习的对抗方法。生成对抗网络 (GAN) 和 噪声对比估计 (noise-contrastive estimation, NCE) 之间存在关系 (Generative adversarial nets)。
前置任务。人们提出了范围广泛的 前置/代理任务 (pretext task)。例子方面,包括在某些损坏下恢复输入,如 去噪自动编码器、上下文自动编码器,或跨通道自动编码器 (colorization)。一些前置任务通过构造伪标签,如 单张 “样例 (exemplar)” 图像的转换、patch 排序、跟踪或分割视频中的 objects,或聚类特征。
对比学习 vs 前置任务。各种前置任务都可基于某种形式的对比损失函数。实例判别 (Instance discrimination) 方法,与基于样例 (exemplar-based) 的任务和噪声对比估计相关。对比预测编码 (CPC) 中的前置任务是上下文自动编码的一种形式,而对比多视图 (multivies) 编码 (CMC) 中的前置任务与 colorization 有关。
三、方法
3.1 Contrastive Learning as Dictionary Look-up
对比学习及其近期发展,可被视为是 为字典查找 (look-up) 任务训练一个编码器,如下所述。
考虑一个经编码的 query ,和 一组经编码的样本
—— 字典的 keys。假设字典中有一个 与
相匹配的 key (记为
)。对比损失是一个函数,当
与 positive key
相似 且与所有其他 keys 不同 (被视为
的 negative keys) 时,损失函数值较低。利用 点积 衡量相似度,本文考虑了一种对比损失函数的形式,称为 InfoNCE。
![]()
其中, 是每个 (Unsupervised feature learning via non-parametric instance discrimination) 的温度超参数。当
时,InfoNCE 变为标签 CE 损失。InfoNCE 的总和包含了一个正样本
和
个负样本 (即字典/队列里所有 keys)。直观地,InfoNCE 损失是一个
路的 softmax 分类器的对数损失,该分类器努力将
归类为
。对比损失函数也可基于其他形式,如 margin-based 的损失和 NCE 损失的变体。
InfoNCE Loss
- 公式 (1) 的分子表示 query 和正样本 key 计算,分母表示 query 和 K+1 个负样本 key 计算累加和。
- 直接计算的复杂度很大,因为 MoCo 使用 instance discrimination 作为前置任务,那么 IN-1K 的 128 万张图片即可视为有 128 万个类别,相应地要设置 128 万分类的 Softmax,从而直接计算和训练是非常困难的。
- NCE loss (Noise Contrastive Estimation Loss):将多分类改造为二分类 —— 数据类别 data sample (正类) 和噪声类别 noisy sample (负类),从而解决了巨量类别问题。
- Estimation:意为近似。为降低计算复杂度,不是在每次迭代时遍历整个 IN-1K 的约 128 万个负样本,而是只从中选一些负样本来参与 Loss 计算 (即选队列字典中的 65536 个负样本),从而相当于一种近似。这也正是 MoCo 所强调的 —— 好的字典应足够大型,因为越大型的字典越能够提供越好的近似。
- InfoNCE Loss 作为 NCE loss 的一个简单变体,认为如果只把问题视为二分类,可能对模型学习不是很友好,毕竟大量的噪声样本很有可能不属于一个类别,所以还是视为了多分类问题。
- 公式 (1) 的
其实相当于 logit,也可类比为 Softmax 中的
。
作为温度超参数,用于控制分布的形状 。
对比损失 作为一个无监督的目标函数来 训练表示 query 和 keys 的编码器网络。通常,query ,其中
是一个 (query) 编码器网络,
是一个 query 样本 (同理有
)。它们的实例化 (instantiations) 取决于具体的前置任务。输入的 query
和 key
可以是 图像、patches、包含一系列上下文的 patches 等。使用的 query 编码器网络
和 key 编码器网络
可以是 完全相同/共享的 (如 Inva Spread 架构相同参数共享)、部分相同/共享的、或完全不同的 (如 CMC,多视角多编码器)。
3.2 Momentum Contrast
从上述角度来看,对比学习是一种 在图像等高维连续输入上构建离散字典 的一种方法。字典是动态的,因为 keys 是随机采样的,且 key 编码器在训练过程中演进 (evolves)。我们的假设是,好的特征可以通过一个包含大量负样本的大型字典来学习,而字典 keys 的编码器尽管还在演进,但仍尽可能地保持一致。基于这个动机,我们将呈现出下面所描述的动量对比。
字典作为队列。我们方法的核心是将字典作为一个数据样本的队列。这允许我们重用最靠近前面的 mini-batches 中的经编码的 keys。队列的引入可将字典大小与 mini-batch 大小解耦。我们的字典大小可以比一个典型的 mini-batch 大小大得多,并且可灵活独立地设为一个超参数。
字典中的样本逐渐被替换。当前的 mini-batch 将入队字典,队列中最老的 mini-batch 将被移除出队。字典总是表示所有数据的一个采样子集 (类似基于所有数据的滑动窗口),而维护此字典的额外计算是可管理的。此外,删除最老的 mini-batch 可能是有益的,因为其中的 经编码的 keys 是最过时的,因此与最新的 keys 最不一致。
动量更新。使用队列可使字典变得大型,但它也使通过反向传播更新 key 编码器变得困难 (梯度应传播到队列中的所有样本)。一个朴素的解决方案是从 query 编码器 复制 key 编码器
而 忽略 这个 梯度。但这种解决方案在实验中产生的结果很差 (4.1 节)。我们假设,这种失败是由 快速变化的编码器降低了 key 表示的一致性 导致的。我们提出 动量更新 来解决该问题。
形式上,将 的参数表示为
,
的参数表示为
,通过下式更新
:
![]()
此处 是一个动量系数。只有 query 编码器参数
才会通过反向传播进行更新,而当前的 key 编码器参数
是基于先前的
和当前的
实现间接动量更新。在公式 (2) 中的动量更新使
比
演进得更 smoothly。因此,尽管 队列中的 keys 由不同的编码器编码 (在不同的 mini-batches),但这些 编码器间的差异可以很小。在实验中,一个相对较大的动量 (如
,我们的默认值) 比一个较小值 (如
) 要好得多,这表明 一个缓慢演进的 key 编码器是利用队列的核心。

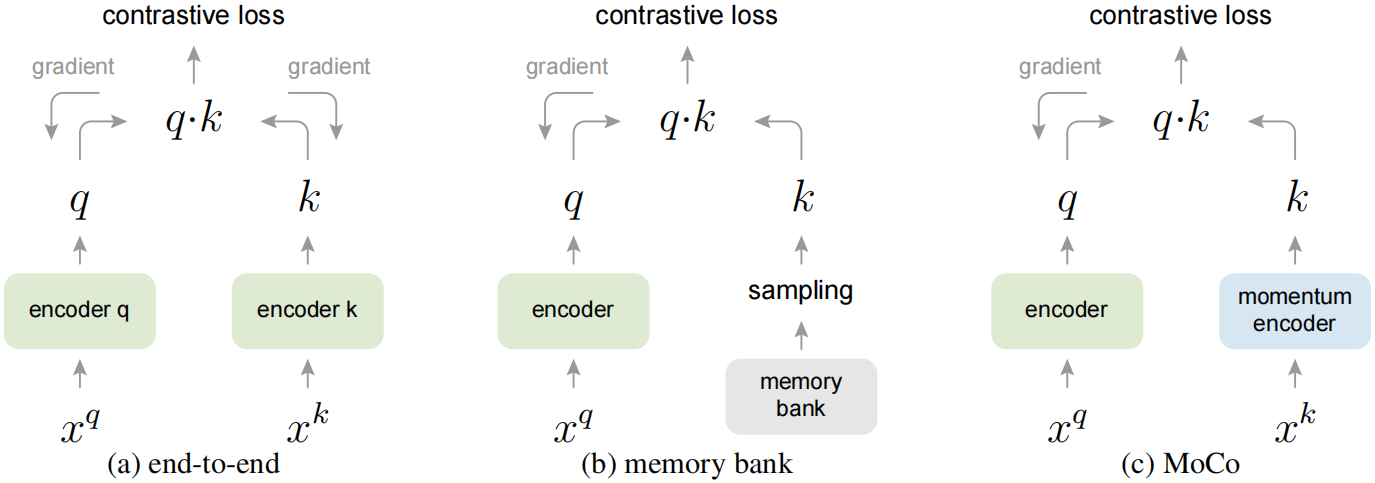
此处将举例说明一对 query 和 key。这 3 种机制在如何维护 keys 和如何更新 key 编码器方面有所不同。
(a): 用于计算 query 和 key 表示的编码器通过反向传播进行端到端更新 (这两个编码器可以不同)
(b): key 表示从内存库 (memory bank) 中采样
(c): MoCo 通过一个动量更新的编码器动态地编码新 keys,并维护一个 keys 的队列 (详见图 1)
与先前机制的关系。MoCo 是使用对比损失的通用机制。我们将其与图 2 中两种现有的通用机制进行了比较。它们在字典的大小和一致性上表现出不同的属性。
通过反向传播进行的端到端更新 是一种自然的机制 (图 2a)。它使用 当前 mini-batch 中的所有样本作为字典,因此 keys 被一致地编码 (由相同的一组编码器参数编码)。但字典大小与 mini-batch 大小相耦合 (couple with),会受到 GPU 内存大小的限制。它也受到了大 mini-batch 优化的挑战。最近的一些方法是基于 由局部位置 (local positions) 驱动的前置任务,其中通过多个位置 (multiple positions) 可以使字典大小更大。但是这些前置任务可能需要特殊的网络设计,如 patchifying 输入 或 customizing 感受野大小,这可能会使这些网络向下游任务的迁移复杂化。
(a) SimCLR / Inva Spread 的端到端学习
- 缺点:字典大小和 mini_batch 大小一致,但大 batch 难设置、难优化、难收敛,故效果有限。
- 优点:梯度反向传播使得编码器可以实时更新,从而令字典中的 key 具有很高的特征一致性。
- SimCLR 最终去 batch_size=8192 训练 (谷歌 TPU memory 很大),可以支持模型做对比学习。
另一种机制是 内存库 (memory bank) 方法 (图 2b)。内存库由数据集中所有样本的表示组成 (离线提取所有 keys 表示)。每个 mini-batch 的字典都随机抽样自内存库而没有反向传播,因此它可以支持一个大型的字典。然而,当最后一次看到样本 (的表示) 时,内存库中样本的表示被更新,因此采样到的 keys 本质上是关于在整个过去 epoch 的多个不同 steps 的编码器,因此不够一致。在 (Unsupervised feature learning via non-parametric instance discrimination) 中的内存库采用了动量更新。其动量更新是在同一个样本的表示上,而非编码器。该动量更新与我们的方法无关,因为 MoCo 并没有追踪每个样本。此外,MoCo 的内存效率更高,并且可以在数十亿的规模数据上训练,这对于内存库来说是难以处理的。
(b) Memory Bank / InstDisc 模型
- memory bank 中,query 的编码器是梯度更新的,但是字典中的 key 没有单独对应的可学习编码器。
- memory bank 预存了整个数据集的嵌入特征,训练时只需要从中采样一些 keys 子集作为字典,然后正常计算 query 和 key 的 loss,通过梯度反向传播更新编码器。
- 编码器更新后,重新编码采样到的 keys 子集得到新的嵌入特征来替换原值,从而完成一个 step 的 memory bank 更新,依此类推.
- ImageNet 虽有 128 万张图片 —— 128 万个 keys,但特征维度 dim = 128,用 memory bank 存下来只需 600M,尚且可行。但是对于亿级图片规模的数据,预提取和存储所有特征则要几十至几百 G 的 memory,故 memory bank 的扩展性不如 MoCo。
memory bank 的特征一致性很差
- query 编码器的更新很频繁 (batch-wise),导致 key 的嵌入特征提取自不同时刻的编码器,特征一致性很差。
- memory bank 预存了整个数据集的嵌入特征,使得模型要训练一个 epoch (所有 steps / iters) 才能把整个 memory bank 更新一遍。当下一个 epoch 训练开始时,第一个 step / iter 选中的 keys 的嵌入特征可能分别来自上一个 epoch 中不同时刻的编码器,导致 query和 key 的嵌入特征差异很大。
- memory bank 通过另一个 loss (proximal optimization) 平滑训练过程,也提到了动量更新 (样本的表示/特征,而非编码器)。
第 4 节对这三种机制进行了实证比较 (empiricaly compares)。
3.3 Pretext Task
对比学习可以驱动各种前置任务。本文的重点不是设计一个新的前置任务,而是主要 following (Unsupervised feature learning via non-parametric instance discrimination) 中的实例判别任务并使用一个简单的前置任务,这与一些最近的工作有关。
按照 (Unsupervised feature learning via non-parametric instance discrimination),如果一个 query 和一个 key 来自同一图像,则我们将它们视为正对,否则将它们视为负样本对。我们使用随机数据增强广 获取同一图像的两个随机 “视图 (views)” 以构成一个正对。而 query 和 key 分别由它们的编码器 和
进行编码。该编码器可以是任何 CNN。

算法 1 为这个前置任务提供了 MoCo 的伪代码。对于当前的 mini-batch,我们编码 query 及其对应的 keys,它们构成了正样本对。负样本则来自队列。
f_k.params = f_q.params # key 编码器的参数初始化基于 query 编码器
for x in loader: # 取出一个 mini-batch 的图像序列 x,包含 N = 256 张图片,但没有标签
x_q = aug(x) # 用作 query 的图(数据增广得到)
x_k = aug(x) # 用作 key 的图 (数据增广得到),与 x_q 构成正样本对
q = f_q.forward(x_q) # 提取 query 特征,q.shape = N×C,c 为 embed dim
k = f_k.forward(x_k) # 提取 key 特征,k.shape = N×C,c 为 embed dim
k = k.detach() # 不使用梯度更新 key 编码器 f_k 的参数,确保提取的特征的一致性
# bmm 是分批矩阵乘法; 字典大小 K = 65536
l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # l_pos.shape = N×1,q * k+ (query 与当前正样本的相似度)
l_neg = mm(q.view(N,C), queue.view(C,K)) # l_neg.shape = N×K,q * k_ (query 与上一 mini-batch 或 queue 的所有负样本的相似度)
logits = cat([l_pos, l_neg], dim=1) # 拼接正负样本相似度,logits.shape = N×(1+K) = 256×(1+65536) -> 相当于 65537 分类
labels = zeros(N) # 按照以上实现方式,所有正样本永远在 logits 的 index = 0 的位置上
# InfoNCE Loss,促进 query 与正样本 key 的相似度越来越高、与负样本 keys 的相似度越来越低
loss = CrossEntropyLoss(logits/t, labels)
loss.backward() # 计算梯度反向传播
update(f_q.params) # query 编码器 f_q 使用梯度立即更新
f_k.params = m*f_k.params+(1-m)*f_q.params # key 编码器 f_k 缓慢地动量更新
enqueue(queue, k) # 当前 mini-batch 的样本特征入队,作为下一个 mini-batch 中 query 的负样本
dequeue(queue) # 最早进入 queue 的 mini-batch 出队 技术细节。我们采用 ResNet 作为编码器,其最后一个全连接层 (在全局平均池化之后) 具有固定维数的输出 (128-D)。输出向量由 L2-范数归一化。此即为 query 或 key 的表示。公式 (1) 中的温度系数 设为 0.07。数据增广设置遵循 (Unsupervised feature learning via non-parametric instance discrimination):从经随机 resized 的图像中裁剪出 224×224 的像素,然后随机颜色抖动 (color jittering)、随机水平翻转和 随机灰度转换,所有这些都可以在 PyTorch 的 torchvision 包中获得。以下展示了数据增广示例代码:
# https://github.com/facebookresearch/moco/blob/main/main_moco.py
if args.aug_plus:
# MoCo v2's aug: similar to SimCLR https://arxiv.org/abs/2002.05709
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.)),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1) # not strengthened
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([moco.loader.GaussianBlur([.1, 2.])], p=0.5),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
]
else:
# MoCo v1's aug: the same as InstDisc https://arxiv.org/abs/1805.01978
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.)),
transforms.RandomGrayscale(p=0.2),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
] Shuffling BN。编码器 和
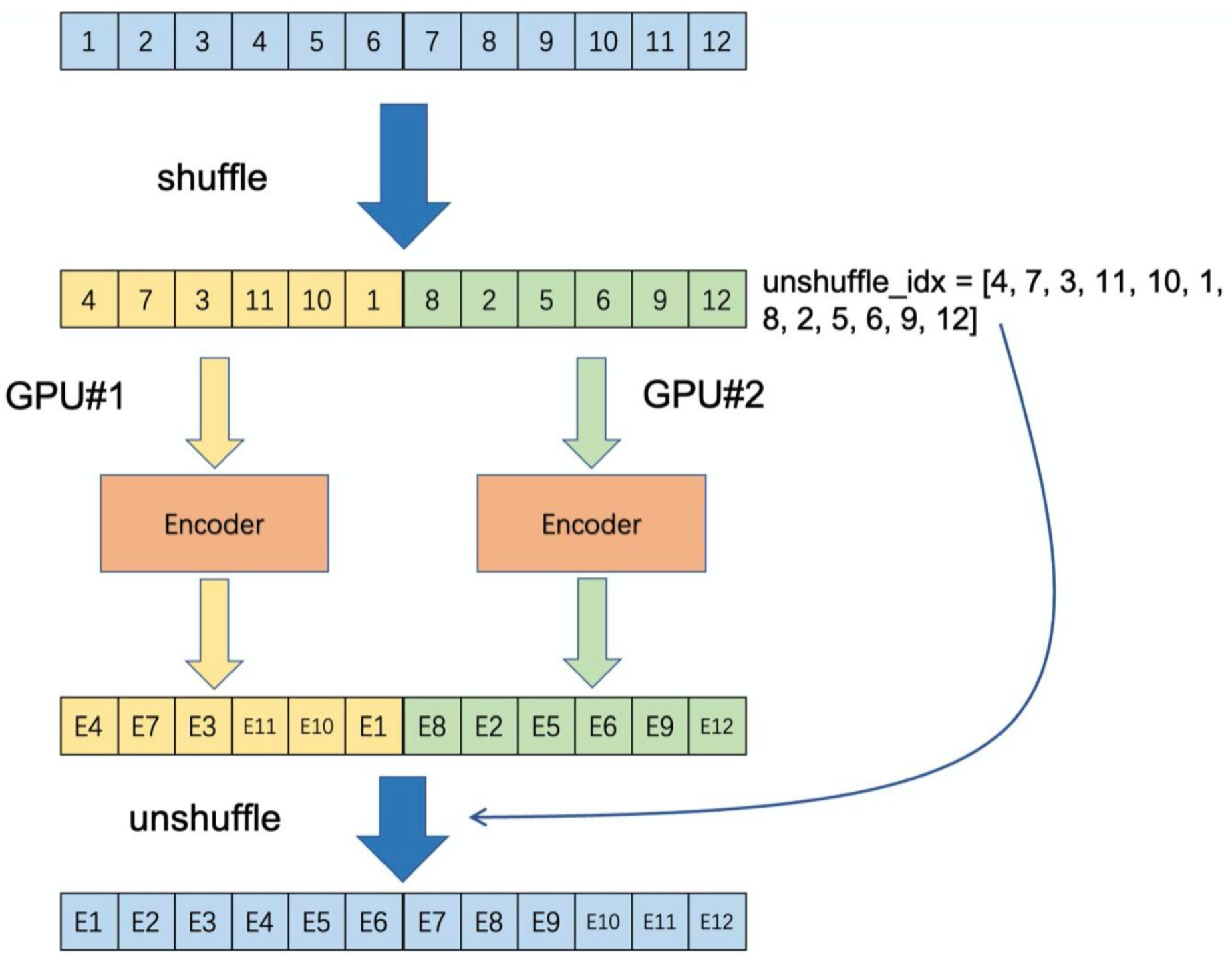
都有 BN,如同标准 ResNet。实验中发现 使用 BN 会抑制模型学习良好的表示,就像在 (Data-efficient image recognition with contrastive predictive coding) 中所报道的那样 (它避免使用 BN)。模型似乎 “欺骗 (cheat)” 前置任务,且容易找到低损失的解决方案。这可能是因为 样本间的 intra-batch 通信 (由 BN 引起的) 泄漏了信息。(前人认为 BN 使样本间数据不期望的发生交互,从而使模型倾向于找到与原训练目标不符的 low-loss 优化方式,故避免使用 BN)
我们通过 shuffling BN 来解决该问题。我们使用多 GPU 训练,并为每个 GPU 独立地对样本执行 BN (正如在普通实践中所做的那样)。对于 key 编码器 ,在将其分布到各 GPU 之间前,shuffle 当前 mini-batch 中的样本顺序 (并在编码后 shuffle back);query 编码器
的 mini-batch 的样本顺序不变。这 确保了用于计算 query 及其 positive key 的 batch 统计信息 来自两个不同的子集。这有效地解决了作弊 (cheating) 问题,并允许训练受益于 BN。(由于每个 batch 内的样本之间计算 mean 和 std 导致信息泄露,产生退化解。MoCo 通过多 GPU 训练,分开计算 BN,并且 shuffle 不同 GPU 上产生的 BN 信息来解决问题)
本文在我们的方法和对应的端到端消融中都使用了 shuffling BN (图 2a)。它与作为竞争者的内存库无关 (图2b),内存库不受此问题的影响,因为 positive keys 来自过去不同的 mini-batches。
四、实验
我们研究基于以下数据集的无监督训练:
ImageNet-1M (IN-1M):ImageNet 训练集基于 1000 个类别,有 ∼128 万张图像 (其实是 ImageNet-1K;我们计算图像数量 1M 而非类别 1K,因为无监督学习不用类别)。该数据集在类别分布上很平衡,其中的图像通常包含 objects 的标志性视图 (iconic view)。
Instagram-1B (IG-1B):根据 (Exploring the limits of weakly supervised pretraining),这是一个来自 Instagram 的具有 ∼10亿 (940M) 公共图像的数据集。这些图片具有与 ImageNet 类别相关的∼1500 种散列标记 (hashtags)。与 IN-1M 相比,该数据集相对未被规整 (uncurated),并且具有真实世界数据的长尾、不平衡的分布。此数据集同时包含标志性 (iconic) objects 和场景级 (scene-level) 图像。
训练。使用 SGD 优化器,权重衰减为 0.0001,动量为 0.9。对于 IN-1M,在 8 个 GPU 中使用 256 的 mini-batch (算法 1 中的 ),初始学习率为 0.03。在 120 和 160 个 epoch 时学习率乘 0.1,共训练 200 个 epochs,耗费 ∼53 小时训练 ResNet-50。对于 IG-1B,在 64 个 GPU 中使用 1024 的 mini-batch,学习率为 0.12,每 62.5k 次迭代 (64M 张图像) 学习率指数衰减 0.9×。训练 125 万 (1.25M) 次迭代 (IG-1B 的 ∼1.4 个 epoch),耗费 ∼6 天训练 ResNet-50。
# https://github.com/facebookresearch/moco/blob/main/main_moco.py
parser.add_argument('--epochs', default=200, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N',
help='mini-batch size (default: 256), this is the total '
'batch size of all GPUs on the current node when '
'using Data Parallel or Distributed Data Parallel')
parser.add_argument('--lr', '--learning-rate', default=0.03, type=float,
metavar='LR', help='initial learning rate', dest='lr')
parser.add_argument('--schedule', default=[120, 160], nargs='*', type=int,
help='learning rate schedule (when to drop lr by 10x)')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum of SGD solver')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')# moco specific configs:
parser.add_argument('--moco-dim', default=128, type=int,
help='feature dimension (default: 128)') # embedding size = 128
parser.add_argument('--moco-k', default=65536, type=int,
help='queue size; number of negative keys (default: 65536)') # len(queue) = 65536
parser.add_argument('--moco-m', default=0.999, type=float,
help='moco momentum of updating key encoder (default: 0.999)') # m = 0.999
parser.add_argument('--moco-t', default=0.07, type=float,
help='softmax temperature (default: 0.07)') # τ = 0.07# https://github.com/facebookresearch/moco/blob/main/main_moco.py
def adjust_learning_rate(optimizer, epoch, args):
"""Decay the learning rate based on schedule"""
lr = args.lr
if args.cos: # cosine lr schedule
lr *= 0.5 * (1. + math.cos(math.pi * epoch / args.epochs))
else: # stepwise lr schedule
for milestone in args.schedule: # default=[120, 160]
lr *= 0.1 if epoch >= milestone else 1. # 在 120 和 160 个 epoch 时学习率乘 0.1
for param_group in optimizer.param_groups:
param_group['lr'] = lr # 更新各 group 的优化器参数4.1 Linear Classification Protocol
我们首先验证了我们的方法 —— 通过对经冻结特征的线性分类,遵循一个普遍的协议。在本小节中,我们对 IN-1M 进行无监督预训练。然后冻结特征,训练一个有监督线性分类器 (FC + Softmax)。我们在一个 ResNet 的全局平均池化 (GAP) 特征上训练 100 个 epochs 该分类器。我们报告了 ImageNet 验证集上的 1-crop,top-1 分类准确率。
# https://github.com/facebookresearch/moco/blob/main/main_lincls.py
def main_worker(gpu, ngpus_per_node, args):
# ...
# create model
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
# freeze all layers but the last fc
for name, param in model.named_parameters():
if name not in ['fc.weight', 'fc.bias']:
param.requires_grad = False # stop computing gradients to freeze layers
# init the fc layer
model.fc.weight.data.normal_(mean=0.0, std=0.01)
model.fc.bias.data.zero_()
# ...
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
# optimize only the linear classifier
parameters = list(filter(lambda p: p.requires_grad, model.parameters()))
assert len(parameters) == 2 # fc.weight, fc.bias
optimizer = torch.optim.SGD(parameters,
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
def sanity_check(state_dict, pretrained_weights):
"""
Linear classifier should not change any weights other than the linear layer.
This sanity check asserts nothing wrong happens (e.g., BN stats updated).
"""
print("=> loading '{}' for sanity check".format(pretrained_weights))
checkpoint = torch.load(pretrained_weights, map_location="cpu")
state_dict_pre = checkpoint['state_dict']
for k in list(state_dict.keys()):
# only ignore fc layer
if 'fc.weight' in k or 'fc.bias' in k:
continue
# name in pretrained model
k_pre = 'module.encoder_q.' + k[len('module.'):] \
if k.startswith('module.') else 'module.encoder_q.' + k
assert ((state_dict[k].cpu() == state_dict_pre[k_pre]).all()), \
'{} is changed in linear classifier training.'.format(k)
print("=> sanity check passed.")对于该分类器,实施网格搜索,发现最优初始学习率为 30 且权值衰减为 0。这些超参数在本小节中介绍的所有消融项中始终表现良好。这些超参数值意味着特征分布 (例如,规模 (magnitudes)) 可能与 ImageNet 有监督训练有本质上的差异,我们将在 4.2 节中重新讨论该问题。
更多实验分析见原文。
总结 ☆
- 虽然对比学习无需标签,但模型仍需知道图片中哪些相似、哪些不相似才可以训练,于是需要人为设计各种巧妙的代理任务来实现该目的。
- 如同一图像的不同裁剪和数据增广的结果,虽有差异但仍被视为具有相似的语义信息,从而作为匹配的 正样本对,此时原图即为 基准点/锚点 (anchor),衍生的新图即为 正样本;与其他图像产生的样本即均为 负样本对。
- 从某种程度上,数据集中每一图像 (及其产生的样本) 可以视为 一个单独的类别,故对 IM-1K 而言,类别数不是 1000 而是 128 万。
- 划分正、负样本后,即可通过编码器编码所有正、负样本以提取嵌入特征。
- 由于所有正、负样本均是基于 anchor 而言的,故 anchor 通常单独配置 一个 编码器 (如本文的 query 编码器),其他的正、负样本配置 另一个 编码器 (如本文的 key 编码器)。
- 当然,query 编码器 和 key 编码器可以 完全相同、部分相同 或 完全不同。但不同的编码器之间必须相似,以确保编码得到的特征具有一致性和比较的意义。
- 获取到 anchor 和正、负样本的嵌入特征后,只需衡量它们的相似度,并 缩小 anchor 与正样本对的嵌入特征距离,拉大 anchor 与负样本的嵌入特征距离。
- 确定代理任务并知道如何定义正、负样本后,就要用 目标函数 来告诉模型如何学习,如常见的对比学习目标函数 NCE Loss 等。
- 事实上,对比学习最大的特性就是方法 灵活,可以设置各种不同的代理任务。只要找到或设计一种合理的方式来 定义正、负样本,就能走完剩下的一些较标准化的流程,从而实施对比学习。
实现
# https://github.com/facebookresearch/moco/blob/main/moco/builder.py
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
import torch
import torch.nn as nn
class MoCo(nn.Module):
"""
Build a MoCo model with: a query encoder, a key encoder, and a queue
https://arxiv.org/abs/1911.05722
"""
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
"""
dim: feature dimension (default: 128)
K: queue size; number of negative keys (default: 65536)
m: moco momentum of updating key encoder (default: 0.999)
T: softmax temperature (default: 0.07)
"""
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc)
self.encoder_k.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc)
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
@torch.no_grad()
def _momentum_update_key_encoder(self):
"""
Momentum update of the key encoder
"""
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
@torch.no_grad()
def _dequeue_and_enqueue(self, keys):
# gather keys before updating queue
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # for simplicity
# replace the keys at ptr (dequeue and enqueue)
self.queue[:, ptr:ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K # move pointer
self.queue_ptr[0] = ptr
@torch.no_grad()
def _batch_shuffle_ddp(self, x):
"""
Batch shuffle, for making use of BatchNorm.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# random shuffle index
idx_shuffle = torch.randperm(batch_size_all).cuda()
# broadcast to all gpus
torch.distributed.broadcast(idx_shuffle, src=0)
# index for restoring
idx_unshuffle = torch.argsort(idx_shuffle)
# shuffled index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_shuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this], idx_unshuffle
@torch.no_grad()
def _batch_unshuffle_ddp(self, x, idx_unshuffle):
"""
Undo batch shuffle.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# restored index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_unshuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this]
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum('nc,nc->n', [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum('nc,ck->nk', [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
# utils
@torch.no_grad()
def concat_all_gather(tensor):
"""
Performs all_gather operation on the provided tensors.
*** Warning ***: torch.distributed.all_gather has no gradient.
"""
tensors_gather = [torch.ones_like(tensor)
for _ in range(torch.distributed.get_world_size())]
torch.distributed.all_gather(tensors_gather, tensor, async_op=False)
output = torch.cat(tensors_gather, dim=0)
return output


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









