






今天上午接到了个需求,要求对输入框输入的内容进行关键字提取,我接到需求的一瞬间也是蒙的,因为在印象里这都是自然语言干的事,于是我上网搜了搜发现确实有很多集成好的包,我大概找了几种(HanLP,Jieba,Ansj,IK-Analyzer)分别测试了下,经过测试发现IK-Analyzer这款最简单好用,虽然网上都说Jieba目前是中文分词最好的,话不多说上代码:
1、先引入maven依赖,版本你们自己挑选
<dependency>
<groupId>cn.shenyanchao.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>9.0.0</version>
</dependency>
2、基础代码实现:
public static void main(String[] args) {
String text = "我明天要和小伙伴们一起去阿拉德大陆的西海岸旅游";
try {
Set<String> keywords = extractKeywords(text);
System.out.println("关键字:" + keywords);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* description 提取关键字
*
* @author yanzy
* @version 1.0
* @date 2024/5/7 17:12
*/
private static Set<String> extractKeywords(String text) throws Exception {
Set<String> keywords = new HashSet<>();
StringReader reader = new StringReader(text);
IKSegmenter segmenter = new IKSegmenter(reader, true); // true表示使用智能模式
Lexeme lexeme;
while ((lexeme = segmenter.next()) != null) {
String word = lexeme.getLexemeText(); // 获取分词结果
// 根据词性和长度筛选关键字
if (isValidKeyword(word, lexeme.getLexemeType())) {
keywords.add(word);
}
}
return keywords;
}
/**
* description 根据自定义条件判断是否为有效关键字
*
* @author yanzy
* @version 1.0
* @date 2024/5/7 17:12
*/
private static boolean isValidKeyword(String word, int lexemeType) {
// 这里可以根据你的需求调整筛选规则
// 一般来说,名词、专有名词、形容词等类型的词可以作为关键词
// 根据词长和词性来筛选关键词
// 例如:提取名词(类型4)、专有名词(类型10)以及形容词(类型2),长度大于1的词
return (lexemeType == Lexeme.TYPE_CNWORD || lexemeType == Lexeme.TYPE_ARABIC) && word.length() > 1;
}
3、运行结果,可以看到有一些词是我们想要的,一些是不需要的,想要的词也不是连在一起的,被分成了多个,并且缺胳膊断腿
关键字:[西海岸, 拉德, 大陆, 明天, 小伙伴, 要和, 一起, 旅游]
4、为此我搜索了半天,终于找到解决办法, IK-Analyzer是支持扩展词典的,具体操作如下:
①、准备自定义词典文件:首先,准备一个文本文件,将你想要添加的自定义词汇逐行写入该文件,每行一个词汇,可以附加词频和词性等信息,以提高分词的准确性。
②、加载自定义词典文件:在 IK Analyzer 的配置文件中加载自定义词典文件(配置文件我贴在下面了),这样,分词器在分词时会将自定义词汇考虑在内。
③、xml文件一定要和扩展词典在同一级下,否则加载不到。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer扩展词典</comment>
<!-- 配置自定义词典 -->
<entry key="ext_dict">custom_dict.txt;</entry>
<!-- 配置停用词典 -->
<entry key="ext_stopwords">custom_dict.txt;</entry>
</properties>
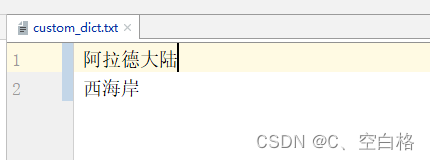
下面是扩展词典里我自定义的词汇:
5、这时我们在运行程序,看看结果:
关键字:[ 明天, 要和 ,小伙伴, 阿拉德大陆, 西海岸,一起, 旅游]
6、可以看到这次提取出来的就是我们想要的关键字了,那些多余的自己剔除掉就好了,如果你有很多需要自定义的词汇,可以在项目启动时全部初始化到扩展词典中,扩展词典支持txt和dic格式,按需使用即可。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









