










几种数据结构在数据索引应用的简单说明
Hello,大家好我是木鸟,在学习编程和面试的过程中是不是经常听到数据结构,什么二叉树、红黑树。。。,刚开始我一听到这些头有点大心想这是什么啊,前段时间看视频学习的时候看到这块内容,在这里做个总结,有不合理的地方希望大佬进行指正,谢谢。
二叉树
可以把它理解为数据分叉,上边一个枝,左右分两个叉,比枝小的在左边,比枝大的在右边;
二叉树的缺点:比方说1、2、3、4、5、6.。。。。等这样的数据,如果以二叉树的数据结构进行查找它并不能提高查询速度,因为它的下一个数据总是比上一个数据大,它的结构会往右斜着下去
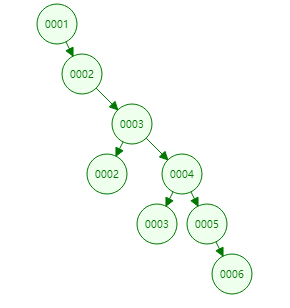
红黑树
可以把它理解为二叉树的升级,枝头为黑叔,分叉为红树,也是比枝小的数据在左边比枝大的在右边,但是红黑树与二叉树的区别是每次一个枝两个两个叉之后(会对数据做一个二叉平衡),再下一个数据它又会分出一个枝,相对于二叉树1、2、3、4、5、6这样的数据深度要小
缺点:数据量大时,深度也会很大,因为每个枝只有两个叉。

B-Tree
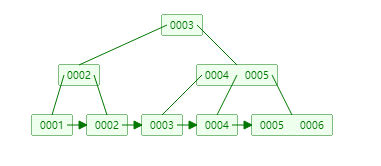
相对于二叉树、红黑树多了一个度的概念,设置一个度的值就是说明一行数据的个数达到这个度的值之后再来一个数据它会取中间一个值作为枝(每行的数据会自动从左到右递增),其他数据也是做小右大分叉,等下边一行数据达到度的值之后再进来一个数据,它又会取中间一个值放到上边一行,而且B-Tree存储的数据结构并不像二叉树红黑树那样只是对索引进行分裂,B-Tree它是以key-value的形式对数据进行分裂,key为索引值value为索引对应的数据,相对于红黑树、二叉树查找到索引值之后再去查找对应的数据查询速度更快,因为他是以key-value的形式直接将数据带出来了。
缺点:度的值不能设的太大因为他是以key-value的形式,每次都将索引值和数据查出来,如果太大的话一下从磁盘中将大量的数据读取出来会很慢。
(如图度为3)
B+Tree
MySQL常用的存储结构,他是B-Tree的变种,相对于B-Tree每行都是存储key-value的数据形式,B+Tree是非叶子节点不存储数据(value),只存储索引值(key),可以大大增加度的值,而叶子节点也就是分叉会是存储key-value的形式,而且他的叶子节点有顺序访问指针提高了区间查询。
缺点:会增加一些数据结构的冗余,因为只有叶子节点才会存储数据,所以它的枝干和叶子的key会有冗余但是影响不大。
(如图度为3)
HASH
为每个索引做一个Hash值,查找唯一值的时候很快但是不能进行范围查找。
缺点:范围查询不管用,只适用于唯一值查询。
推荐一个网站:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
这个网站可以很直白的观看各种数据结构的运作















 6041
6041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









