







本篇是学习编码理论时写的杂记,内容可能枯燥。
二维码笔记系列(原文地址):
- 『二维码学习笔记(一) | 二维码概述』
- 『二维码学习笔记(二) | 数据分析与数据编码』
- 『二维码学习笔记(三) | 纠错编码』
- 『二维码学习笔记(四) | 信息构建与模块放置』
- 『二维码学习笔记(五) | 数据掩码与版本信息』
唠唠闲话
二维码是一种存储二进制数据的矩阵条码,其使用 RS(Reed-Solomon) 编码进行纠错。RS 码是一种线性码(Linear code),其在现实生活中应用广泛,且存在高效的编解码算法。
本篇介绍编码原理,纠错算法以及拓展知识,跳转目录:
分组码
本节介绍分组码的定义例子,以及汉明距离等重要概念。
概述
在信息传输中,因传输通道噪音的干扰,接收端收到的信息与发送端发出的信息可能有误差。纠错码的引入,通过增加额外数据位,使传输的数据抵抗干扰的能力更加鲁棒(robust)。
在编码理论中,分组码(block code)是一大类重要的纠错码,它以块的形式对数据进行编码。分组码的抽象定义在概念上很有用,因为它允许编码理论家、数学家和计算机科学家以统一的方式研究所有分组码的局限性。这种局限性通常对编码界限进行研究,研究其与分组码不同参数的联系,例如信息率与检测纠正错误能力。
定义及例子
纠错码用于在受信道噪声影响的不可靠通信信道上可靠地传输数字数据。当发送者想要使用分组码传输长数据流时,发送者将流分成一些固定大小的片段,每个这样的片段称为消息(message)。分组码过程中,将每 message 单独编码成块(block)。然后,发送者将所有 block 传输给接收者,接收者又可以使用某种解码机制(希望)从可能损坏的接收 block 中恢复原始消息。整体传输的性能和成功取决于信道和分组码的参数。
定义,记号和例子:
-
设 Σ \Sigma Σ 为长度为 q q q 的字符集,记 Σ n \Sigma^n Σn 为 n 元字符构成的集合
-
将子集 C ⊆ Σ n C\subseteq\Sigma^n C⊆Σn 称为块长(block length)为 n n n 的分组码(注:编码=嵌入映射=子集)
-
C C C 的消息长度或维数定义为 k = l o g q ( ∣ C ∣ ) k=log_q(|C|) k=logq(∣C∣)(形式定义,可能非整数)
-
编码 C C C 的编码率或信息率(code rate/information rate) 定义为
R = k n = l o g q ( ∣ C ∣ ) n R=\frac{k}{n}=\frac{log_q(|C|)}{n} R=nk=nlogq(∣C∣)
注: R R R = 消息长度/编码块长度 -
C C C 的元素 x x x 称为码字(codeword)
-
设分组码 C C C 的距离为 d d d,将 C C C 简称为 ( n , k , d ) Σ (n, k, d)_{\Sigma} (n,k,d)Σ 分组码,距离的定义在下边给出
-
分组码可以看成嵌入映射 C ↪ Σ n C\hookrightarrow\Sigma^n C↪Σn,映射左侧为原始信息,右侧为加密后的信息
-
例1: { h i , a m , o k } \{hi,\ am,\ ok\} {hi, am, ok} 是以 Σ = { a , … , z } \Sigma=\{a,\dots,z\} Σ={a,…,z} 为字符集的,块长为 2, 维数为 l o g 26 3 log_{26}3 log263 的分组码
-
例2: { ( 1 , 1 , 1 ) , ( 0 , 0 , 0 ) } \{(1,1,1), (0,0,0)\} {(1,1,1),(0,0,0)} 是以 Σ = { 0 , 1 } \Sigma=\{0,1\} Σ={0,1} 为字符集的,块长 3 ,维数 1 的分组码,写成映射形式
Σ 1 → Σ 3 0 → ( 0 , 0 , 0 ) 1 → ( 1 , 1 , 1 ) \begin{align*} \Sigma^1&\rightarrow\Sigma^3\\ 0&\rightarrow(0, 0, 0)\\ 1&\rightarrow(1, 1, 1) \end{align*} Σ101→Σ3→(0,0,0)→(1,1,1) -
用大空间 Σ 3 \Sigma^3 Σ3 表示小空间 Σ 1 \Sigma^1 Σ1 的数据,能更好地处理错误信息,比如:
- 察觉错误(detect error):用
(
0
,
0
,
0
)
(0,0,0)
(0,0,0) 传输信息 0 时,若发生了至多 2 个错误,比如
( 0 , 0 , 0 ) → ( 0 , 1 , 1 ) (0,0,0)\rightarrow(0,1,1) (0,0,0)→(0,1,1)
接收端收到 ( 0 , 1 , 1 ) ∉ Σ 3 (0,1,1)\notin\Sigma^3 (0,1,1)∈/Σ3 时,能明显察觉到信息发生了错误 - 填补缺失(correct erasure):用
(
0
,
0
,
0
)
(0,0,0)
(0,0,0) 传输信息 0 时,若丢失了至多 2 个位置的数据(且丢失位置已知),比如
( 0 , 0 , 0 ) → ( ∗ , 0 , ∗ ) (0,0,0)\rightarrow(*,0,*) (0,0,0)→(∗,0,∗)
接收端通过余下数据仍能还原初始数据 - 纠错能力(correct error):假设传输
(
0
,
0
,
0
)
(0,0,0)
(0,0,0) 时,有至多 1 个位置的数据错误,比如
( 0 , 0 , 0 ) → ( 0 , 1 , 0 ) (0,0,0)\rightarrow(0,1,0) (0,0,0)→(0,1,0)
由于错误位置至多一个,初始数据只可能是 ( 0 , 0 , 0 ) (0,0,0) (0,0,0)
- 显然,编码的纠错能力是有上限的,假设数据 ( 0 , 0 , 0 ) (0,0,0) (0,0,0) 传送时发生 2 个位置的错误,比如变成 ( 0 , 1 , 1 ) (0,1,1) (0,1,1),接收端并不能确定原数据是 ( 0 , 0 , 0 ) (0,0,0) (0,0,0) 还是 ( 1 , 1 , 1 ) (1,1,1) (1,1,1)。类似地,检测错误和填补缺失的能力也是有限的,假设传送时发生 3 个位置的错误,这种错误显然不能被检测出来。
汉明距离
汉明距离衡量编码处理错误能力的关键指标,下边给出具体定义,总不妨设字符集 Σ \Sigma Σ 包含数字 0
-
设码字 c = ( c 1 , ⋯ , c n ) ∈ Σ n c=(c_1,\cdots,c_n)\in\Sigma^n c=(c1,⋯,cn)∈Σn,定义权重(weight) w t ( c ) = # { i ∣ c i ≠ 0 } wt(c) = \#\{i|c_i\neq 0\} wt(c)=#{i∣ci=0} 为 c c c 的非零成分的数目。
-
对 c , c ′ ∈ Σ n c,c'\in\Sigma^n c,c′∈Σn,定义 c c c 和 c ′ c' c′ 的汉明距离(Hamming distance) 为
Δ ( c , c ′ ) = # { i ∣ c i ≠ c i ′ } \Delta(c,c') = \#\{i|c_i\neq c_i'\} Δ(c,c′)=#{i∣ci=ci′}
注:容易验证 Σ n \Sigma^n Σn 关于 Δ \Delta Δ 作成度量空间 -
编码 C C C 的(最小)距离定义为
δ ( C ) = min { Δ ( c , c ′ ) ∣ c ≠ c ′ ∈ C } \delta(C) = \min\{\Delta(c,c')\ |\ c\neq c'\in C\} δ(C)=min{Δ(c,c′) ∣ c=c′∈C}
注:距离 d = δ ( C ) d=\delta(C) d=δ(C) 描述了码字 c c c 转变为另一码字 c ′ c' c′ 的最少修改数 -
(定理)容易证明,分组码 ( n , k , d ) Σ (n,k,d)_{\Sigma} (n,k,d)Σ 的错误处理能力为:
- 编码 C C C 能检测至多 e ≤ d − 1 e\leq d-1 e≤d−1 个错误
- 编码 C C C 能填补至多 e ≤ d − 1 e\leq d-1 e≤d−1 个缺失
- 编码 C C C 能纠正至多 e ≤ ⌊ d − 1 2 ⌋ e\leq \lfloor\frac{d-1}{2}\rfloor e≤⌊2d−1⌋ 个错误,即 2 e ≤ d − 1 2e\leq d-1 2e≤d−1
-
用图像理解第三条性质:根据定义,以码字为圆心,半径 e ≤ ⌊ d − 1 2 ⌋ e\leq \lfloor\frac{d-1}{2}\rfloor e≤⌊2d−1⌋ 的“小球”互不相交,当错误数目 e ≤ ⌊ d − 1 2 ⌋ e\leq \lfloor\frac{d-1}{2}\rfloor e≤⌊2d−1⌋ 时,错误数据仍在小球范围内,因此能被纠正
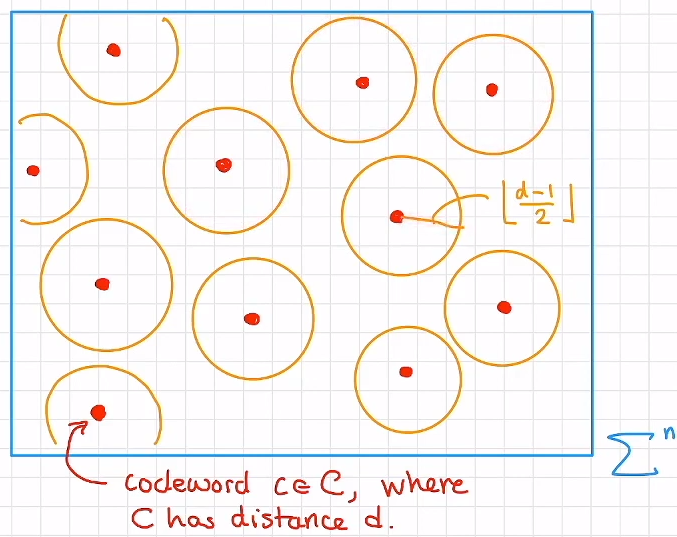
衡量指标
编码在设计上有几个重要目标,或者说衡量指标:
- 处理错误的能力,比如检测错误,纠正错误
- 尽量小的冗余信息(minimize overhead)
- 计算效率,比如编码,解码和纠错等操作的执行效率
在分组码 ( n , k , d ) Σ (n,k,d)_{\Sigma} (n,k,d)Σ 中,错误处理能力用距离 d d d 或相对距离 d ′ d' d′ 描述,冗余信息用编码率/信息率 R R R 表述。
一般地,编码距离 d d d 越大,错误处理能力越强,但相应地,冗余信息将越多,这导致了信息率 R R R 的减小。因此,协调错误处理能力 d d d 与信息率 R R R 是编码领域的重要问题,然而,如何制定最佳权衡策略(best trade-off)还是个开问题。
尽管如此,有不少研究在某些方面给出了解答,例如下边要介绍的汉明界。
有时也用相对距离 d ′ = d n d'=\frac{d}{n} d′=nd 来衡量编码的纠错能力。
汉明界
在编码理论领域,汉明界(Hamming Bound) 是对分组码参数的限制,它对编码空间的利用率提出了重要限制。汉明界也被称为球包装界或体积界,这可以从推导过程看出来。
-
设 x ∈ Σ n x\in\Sigma^n x∈Σn,如下定义 B Σ n ( x , e ) B_{\Sigma^n}(x, e) BΣn(x,e) ,并称为 x x x 的以 e e e 为半径的 Hamming Ball。
B Σ n ( x , e ) = { y ∈ Σ n ∣ Δ ( x , y ) ≤ e } B_{\Sigma^n}(x, e) = \{y\in\Sigma^n\ |\ \Delta(x,y)\leq e\} BΣn(x,e)={y∈Σn ∣ Δ(x,y)≤e} -
将汉明球 B Σ n ( x , e ) B_{\Sigma^n}(x, e) BΣn(x,e) 包含的 Σ n \Sigma^n Σn 元素个数称为球的体积(Volume) ,记为
V o l q ( e , n ) = ∣ B Σ n ( x , e ) ∣ , w h e r e q = ∣ Σ ∣ Vol_q(e,n)=|B_{\Sigma^n}(x, e)|,\ where\ q=|\Sigma| Volq(e,n)=∣BΣn(x,e)∣, where q=∣Σ∣
由于对称性,球体积与 x x x 的选取无关,因而体积定义中不含参数 x x x -
推导易得下边公式
V o l q ( e , n ) = ∑ i = 0 e ( n i ) ( q − 1 ) i Vol_q(e,n) = \sum_{i=0}^e\begin{pmatrix}n\\ i\end{pmatrix}(q-1)^i Volq(e,n)=i=0∑e(ni)(q−1)i
其中加项 ( n i ) ( q − 1 ) i \begin{pmatrix}n\\ i\end{pmatrix}(q-1)^i (ni)(q−1)i 代表与 x x x 的汉明距离为 i i i 的 Σ n \Sigma^n Σn 中的元素数目。换言之,这些元素可通过 x x x 修改 i 个位置数据得到。 -
设 d d d 为 C C C 的距离,同前边示意图易知,汉明球 B Σ n ( x , ⌊ d − 1 2 ⌋ ) , x ∈ C B_{\Sigma^n}(x,\lfloor\frac{d-1}{2}\rfloor),x\in C BΣn(x,⌊2d−1⌋),x∈C 之间两两不交,继而有
∣ C ∣ ⋅ V o l q ( ⌊ d − 1 2 ⌋ , n ) ≤ ∣ Σ n ∣ ≤ q n |C|\cdot Vol_q(\lfloor\frac{d-1}{2}\rfloor,n) \leq |\Sigma^n| \leq q^n ∣C∣⋅Volq(⌊2d−1⌋,n)≤∣Σn∣≤qn
取等当且仅当这些汉明球覆盖了整个空间;整理可得
log q ( ∣ C ∣ ) + log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) ≤ n ⇒ k + log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) ≤ n ⇒ k n + log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) n ≤ 1 ⇒ R ≤ 1 − log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) n \begin{align*} &\log_q(|C|) + \log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))\leq n\\ \Rightarrow &\ k+\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))\leq n\\ \Rightarrow &\ \frac{k}{n}+\frac{\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))}{n}\leq 1\\ \Rightarrow &\ R \leq 1-\frac{\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))}{n} \end{align*} ⇒⇒⇒logq(∣C∣)+logq(Volq(⌊2d−1⌋,n))≤n k+logq(Volq(⌊2d−1⌋,n))≤n nk+nlogq(Volq(⌊2d−1⌋,n))≤1 R≤1−nlogq(Volq(⌊2d−1⌋,n))
上式表明,当编码块长 n n n,字符集长 q q q 以及编码距离 d d d 确定时,信息率 R R R 存在不等式右侧给出的上界,这一上界便称为汉明界 -
汉明界在某些角度上回答了编码距离与信息率的关系,假设编码块长 n n n 和字符集 Σ \Sigma Σ 确定,汉明界表明:当编码距离 d d d 确定时,信息率 R R R 不会超过某个数值。而取到边界当且仅当所构造编码的半径为 ⌊ d − 1 2 ⌋ \lfloor\frac{d-1}{2}\rfloor ⌊2d−1⌋ 的汉明球覆盖了整个空间。达到汉明界的编码被称为完美编码(perfect code) 或汉明码(Hamming code)
-
举个例子,考虑二进制字符集 Σ = { 0 , 1 } \Sigma=\{0,1\} Σ={0,1},设编码的块长为 n = 7 n=7 n=7,距离为 d = 3 d=3 d=3,维数为 k k k,计算汉明界
R = k n ≤ 1 − log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) n = 1 − log 2 ( V o l 2 ( 1 , 7 ) ) 7 , V o l 2 ( 1 , 7 ) = 1 + 7 = 1 − log 2 ( 8 ) 7 = 4 7 \begin{align*} R = \frac{k}{n}&\leq 1-\frac{\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))}{n}\\ &= 1-\frac{\log_2(Vol_2(1,7))}{7},\ Vol_2(1,7) = 1+7\\ &= 1-\frac{\log_2(8)}{7} = \frac{4}{7} \end{align*} R=nk≤1−nlogq(Volq(⌊2d−1⌋,n))=1−7log2(Vol2(1,7)), Vol2(1,7)=1+7=1−7log2(8)=74
根据汉明界,编码维数 k ≤ 4 k\leq 4 k≤4,如下编码可以取到等号
C : Σ 4 → Σ 7 ( x 1 x 2 x 3 x 4 ) ↦ ( 1 1 1 1 0 1 1 1 1 0 1 1 1 1 0 1 ) ( x 1 x 2 x 3 x 4 ) = ( x 1 x 2 x 3 x 4 x 2 + x 3 + x 4 x 1 + x 3 + x 4 x 1 + x 2 + x 4 ) \begin{align*} C:\Sigma^4&\rightarrow \Sigma^7\\ \begin{pmatrix}x_1\\ x_2\\ x_3\\ x_4\end{pmatrix}& \mapsto\begin{pmatrix} 1& & & \\ & 1& & \\ & &1 & \\ & & &1 \\ 0& 1& 1 &1 \\ 1& 0 &1 &1 \\ 1& 1 & 0 &1 \\ \end{pmatrix} \begin{pmatrix}x_1\\ x_2\\ x_3\\ x_4\end{pmatrix} = \begin{pmatrix}x_1\\ x_2\\ x_3\\ x_4\\ x_2+x_3+x_4 \\ x_1+x_3+x_4 \\ x_1+x_2+x_4\end{pmatrix} \end{align*} C:Σ4⎝ ⎛x1x2x3x4⎠ ⎞→Σ7↦⎝ ⎛1011110111101111⎠ ⎞⎝ ⎛x1x2x3x4⎠ ⎞=⎝ ⎛x1x2x3x4x2+x3+x4x1+x3+x4x1+x2+x4⎠ ⎞
例中,编码用线性变换定义,这种编码方式称为线性码,Reed Solomon 编码便是一类特殊的线性码。
线性码
线性码是一种纠错码,任何码字的线性组合也是一个码字。线性码传统上分为分组码和卷积码,以下仅讨论分组码。
下设 F = F q \mathbb{F} = \mathbb{F}_q F=Fq 为 q q q 个元素构成的有限域。
基本概念
-
(定义) 编码空间 F n \mathbb{F}^n Fn 的真子空间 C = F k C=\mathbb{F}^k C=Fk 称为 F \mathbb{F} F 上的维数为 k k k,块长为 n n n 的线性码(Linear Code)。将矩阵 G ∈ F n × k G\in\mathbb{F}^{n\times k} G∈Fn×k 称为 C C C 的生成元矩阵(Generator Matrix),若
C = c o l u m n s p a n ( G ) = { G ⋅ x ∣ x ∈ F k } C=column\ span(G)=\{G\cdot x\ |\ x\in\mathbb{F}^k\} C=column span(G)={G⋅x ∣ x∈Fk}
借助生成矩阵 G G G,线性码 C C C 可写为映射形式
C : F k → F n X ↦ G X , w h e r e X = ( x 1 x 2 ⋮ x k ) \begin{align*} C:\mathbb{F}^k&\rightarrow\mathbb{F}^n\\ X&\mapsto GX,\ where\ X=\begin{pmatrix} x_1\\ x_2\\\vdots\\ x_k \end{pmatrix} \end{align*} C:FkX→Fn↦GX, where X=⎝ ⎛x1x2⋮xk⎠ ⎞ -
生成元矩阵不唯一:任意可逆矩阵左乘生成元矩阵,仍得到生成元矩阵。特别地,通过调整 F n \mathbb{F}^n Fn 的索引,总能左乘得到上分块为单位阵的生成元矩阵:
C : F k → F n X ↦ ( I G ′ ) X = ( X G ′ X ) \begin{align*} C:\mathbb{F}^k&\rightarrow\mathbb{F}^n\\ X &\mapsto \begin{pmatrix}I\\ G'\end{pmatrix} X=\begin{pmatrix} X\\G'X \end{pmatrix} \end{align*} C:FkX→Fn↦(IG′)X=(XG′X)容易发现,初始信息 X X X 嵌在编码后的信息中。我们将满足这一性质的编码称为系统码(Systematic Code)
-
称 H ∈ F ( n − k ) × n H\in\mathbb{F}^{(n-k)\times n} H∈F(n−k)×n 为线性码 C C C 的奇偶检验矩阵(Parity Check Matrix),若
ker ( H ) = { x ∈ F n ∣ H x = 0 } = { G y ∈ F n ∣ y ∈ F k } = i m ( G ) \begin{align*} \ker(H) &= \{x\in\mathbb{F}^n|Hx=0\}\\ &= \{Gy\in\mathbb{F}^n| y\in\mathbb{F}^k\}=im(G) \end{align*} ker(H)={x∈Fn∣Hx=0}={Gy∈Fn∣y∈Fk}=im(G)由线性代数知识,易见 r a n k ( H ) = n − k , r a n k ( G ) = k rank(H)=n-k, rank(G)=k rank(H)=n−k,rank(G)=k,即矩阵 G G G 为列满秩,矩阵 H H H 为行满秩
-
设 ( C , G , H ) (C,G,H) (C,G,H) 为一组线性码,则 ( C ⊥ , H t , G t ) (C^\perp, H^t, G^t) (C⊥,Ht,Gt) 也为一组线性码,称为 C C C 的对偶码(Dual Code),其中
C ⊥ = { x ∈ F n ∣ ⟨ x , y ⟩ = x t y = 0 , ∀ y ∈ C } C^{\perp} = \{x\in\mathbb{F}^n|\lang x,y\rang=x^ty=0,\forall\ y\in C\} C⊥={x∈Fn∣⟨x,y⟩=xty=0,∀ y∈C}
注:编码可以理解为信息空间到表示空间的单射,线性码则是通过列满秩矩阵给出这个单射。
编码距离
相比分组码,线性码的编码距离可以用矩阵 G G G 或 H H H 计算。
-
以下命题等价
- 编码 C C C 的汉明距离为 d d d
-
G
G
G 列空间非零向量最小权重,即
min { w t ( x ) ∣ x ∈ c o l u m n s p a n o f ( G ) } \min\{wt(x) | x\in column\ span\ of(G)\} min{wt(x)∣x∈column span of(G)} - H H H 的任意 d − 1 d-1 d−1 个列向量线性无关,且存在长为 d d d 的线性相关列向量组;换言之, H H H 的线性相关列向量组的最小长度为 d d d
- G G G 的任意 n − d + 1 n-d+1 n−d+1 个行向量构成的向量组中,存在 k k k 个线性无关向量;换言之, G G G 的任意 n − d + 1 n-d+1 n−d+1 行构成的矩阵列满秩
-
我们依次证明这几个命题
-
( 1 ) ⇔ ( 2 ) (1)\Leftrightarrow (2) (1)⇔(2)
根据线性性:
d = δ ( c , c ′ ) = δ ( c − c ′ , 0 ) = w t ( c − c ′ ) = w t ( c ′ ′ ) , c ′ ′ ∈ C d=\delta(c,c')=\delta(c-c', 0) = wt(c-c')=wt(c''),c''\in C d=δ(c,c′)=δ(c−c′,0)=wt(c−c′)=wt(c′′),c′′∈C -
( 2 ) ⇔ ( 3 ) (2)\Leftrightarrow(3) (2)⇔(3)
先将 H H H 列分块化,并由 ker ( H ) = C \ker(H)=C ker(H)=C 知
H = ( H 1 ⋯ H n ) x = ( x 1 , ⋯ , x n ) t ∈ C ⇔ H x = O ⇔ ∑ i = 1 n x i H i = O \begin{align*} H = \begin{pmatrix} H_1&\cdots&H_n \end{pmatrix}\\ x=(x_1,\cdots,x_n)^t\in C &\Leftrightarrow Hx = O\\ &\Leftrightarrow \sum_{i=1}^nx_iH_i=O \end{align*} H=(H1⋯Hn)x=(x1,⋯,xn)t∈C⇔Hx=O⇔i=1∑nxiHi=O
x ∈ C x\in C x∈C 的 r r r 个非零元数目对应得到 H H H 中 r r r 个线性相关的列向量 -
( 1 ) ⇔ ( 4 ) (1)\Leftrightarrow(4) (1)⇔(4)
根据定义: C C C 的编码距离为 d d d 等价于 ∀ y ∈ C \forall y\in C ∀y∈C, y y y 的任意 d − 1 d-1 d−1 项出错不会得到另一个码字;等价于方程组 G x = y Gx=y Gx=y 中,将 G , y G,y G,y 的任意 d − 1 d-1 d−1 个行向量丢弃得到的方程 G ′ x = y ′ G'x=y' G′x=y′,其只有唯一解 x x x;等价于 G G G 去掉任意 d − 1 d-1 d−1 行,得到的矩阵列满秩
-
-
一般地,选取列向量 x ∈ C x\in C x∈C 得距离上界 d ≤ w t ( x ) d\leq wt(x) d≤wt(x),选取 H H H 的 r r r 个线性相关向量得到距离下界 d ≥ r d\geq r d≥r,比如前边例子
G = ( 1 1 1 1 0 1 1 1 1 0 1 1 1 1 0 1 ) , H = ( 0 1 1 1 1 0 0 1 0 1 1 0 1 0 1 1 0 1 0 0 1 ) G = \begin{pmatrix} 1& & & \\ & 1& & \\ & &1 & \\ & & &1 \\ 0& 1& 1 &1 \\ 1& 0 &1 &1 \\ 1& 1 & 0 &1 \\ \end{pmatrix},H=\begin{pmatrix} 0&1&1&1&1&0&0\\ 1&0&1&1&0&1&0\\ 1&1&0&1&0&0&1 \end{pmatrix} G=⎝ ⎛1011110111101111⎠ ⎞,H=⎝ ⎛011101110111100010001⎠ ⎞由 G G G 的第一列非零数得 d ≤ 3 d\leq 3 d≤3,由 H H H 前三列向量线性相关性 d ≥ 3 d\geq 3 d≥3,于是 d = 3 d=3 d=3
信息率
前边提到衡量编码的三个重要指标:处理错误能力,尽量小的冗余信息,以及计算效率。关于错误处理能力,我们用编码距离 d d d 来衡量,对于线性码还可以借助生成元矩阵 G G G 和奇偶检验矩阵 H H H 做相关计算;对于冗余信息,Hamming Bound 给出了某些方面的回答,本节将对信息率的边界做更深入的探讨。
本节侧重介绍辛格尔顿界,其与 Reed Solomon 纠错直接关联,其他作为拓展兴趣只做科普性地介绍,不讨论证明。
辛格尔顿界
在编码理论中,辛格尔顿界(Singleton Bound) 以 Richard Collom Singleton 命名,其表明
(
n
,
k
,
d
)
q
(n,k,d)_q
(n,k,d)q 分组码中,信息长满足
k
≤
n
−
d
+
1
k\leq n-d+1
k≤n−d+1,继而
R
≤
1
−
d
−
1
n
R\leq 1-\frac{d-1}{n}
R≤1−nd−1
这个定理的证明非常简单,考虑复合映射
φ
\varphi
φ 为单射
φ
:
Σ
k
→
Σ
n
→
Σ
n
−
d
+
1
c
↦
(
c
1
,
⋯
,
c
n
)
↦
(
c
d
,
⋯
,
c
n
)
\begin{align*} \varphi:\Sigma^k&\rightarrow\Sigma^n\rightarrow\Sigma^{n-d+1}\\ c&\mapsto(c_1,\cdots, c_{n})\mapsto(c_{d},\cdots,c_n) \end{align*}
φ:Σkc→Σn→Σn−d+1↦(c1,⋯,cn)↦(cd,⋯,cn)
φ
\varphi
φ 必为单射,由于
c
c
c 与
c
′
c'
c′ 至多前 d-1 个位置不同,即
φ
(
c
)
=
φ
(
c
′
)
⇒
(
c
d
,
⋯
,
c
n
)
=
(
c
d
′
,
⋯
,
c
n
′
)
⇒
Δ
(
c
,
c
′
)
≤
d
−
1
⇒
c
=
c
′
\begin{align*} \varphi(c)=\varphi(c')&\Rightarrow(c_{d},\cdots,c_n)=(c_{d}',\cdots,c_n')\\ &\Rightarrow \Delta(c,c')\leq d-1\\ &\Rightarrow c=c' \end{align*}
φ(c)=φ(c′)⇒(cd,⋯,cn)=(cd′,⋯,cn′)⇒Δ(c,c′)≤d−1⇒c=c′
由 φ \varphi φ 为单射,比较集合立得 k ≤ n − d + 1 k\leq n-d+1 k≤n−d+1。
对于线性码,从上一节编码距离的刻画(4) 立知, n − d + 1 ≥ k n-d+1\geq k n−d+1≥k。
GV 界
在编码理论中,GV Bound(Gilbert–Varshamov Bound) 是由 Edgar Gilbert 和 Rom Varshamov 分别独立提出的,关于编码(未必线性)参数的边界,Varshamov 通过使用线性码的概率方法证明了这一界限。有关该证明的更多信息请参阅这里。
定理 (Gilbert–Varshamov) 设 q q q 为素数幂次, d ≤ n d\leq n d≤n,则存在线性码 C C C 使得
- C C C 的块长为 n n n,字符集数目为 q q q, 汉明边界为 d d d
-
C
C
C 的信息率
R
=
k
n
R=\frac{k}{n}
R=nk 满足下边性质
R ≥ 1 − l o g q ( V o l q ( d − 1 , n ) ) − 1 n \begin{align*} R\geq 1- \frac{log_q(Vol_q(d-1, n))-1}{n} \end{align*} R≥1−nlogq(Volq(d−1,n))−1
定理证明过程并不复杂,但使用了分析概率的方法,属于非构造性证明,感性趣看这个视频。
渐进分析(Asymptotics)
GV Bound 给出了
R
R
R 的下界,结合 Hamming Bound 得到
1
−
l
o
g
q
(
V
o
l
q
(
d
−
1
,
n
)
)
−
1
n
≤
R
≤
1
−
log
q
(
V
o
l
q
(
⌊
d
−
1
2
⌋
,
n
)
)
n
1- \frac{log_q(Vol_q(d-1, n))-1}{n} \leq \ R \leq 1-\frac{\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))}{n}
1−nlogq(Volq(d−1,n))−1≤ R≤1−nlogq(Volq(⌊2d−1⌋,n))
这个不等式中,信息率 R R R 与参数 d , n , q d,n,q d,n,q 均有关,且形式复杂,不利于理解 R R R 的性质。为此,我们使用渐进分析的方式,通过取极限去除某些参数,以研究 R R R 最本质的性质。
信息率与距离
-
设 C = { C i } i = 1 ∞ \mathfrak{C}=\{C_i\}_{i=1}^\infin C={Ci}i=1∞ 为编码构成的序列,其中 C i C_i Ci 为 ( n i , k i , d i ) q i (n_i,k_i,d_i)_{q_i} (ni,ki,di)qi 分组码,定义序列 C \mathfrak{C} C 的信息率为
R ( C ) : = lim i → ∞ k i n i R(\mathfrak{C}) :=\lim_{i\rightarrow\infty}\frac{k_i}{n_i} R(C):=i→∞limniki
定义 C \mathfrak{C} C 的相对距离(简称距离) δ ( C ) \delta(C) δ(C) 为
δ ( C ) : = lim i → ∞ d i n i \delta(\mathfrak{C}) :=\lim_{i\rightarrow\infty}\frac{d_i}{n_i} δ(C):=i→∞limnidi -
前边讨论汉明界时,举了 ( 7 , 4 , 3 ) 2 (7,4,3)_2 (7,4,3)2-汉明码的例子,类似地,容易构造编码序列 C = { C i } i = 1 ∞ \mathfrak{C}=\{C_i\}_{i=1}^\infty C={Ci}i=1∞,其中 C i C_i Ci 为 ( 2 i − 1 , 2 i − i − 1 , 3 ) 2 (2^i-1, 2^i-i-1, 3)_2 (2i−1,2i−i−1,3)2 汉明码,此时
R ( C ) = lim i → ∞ 2 i − i − 1 2 i − 1 = 1 δ ( C ) = lim i → ∞ 3 n i = 0 \begin{align*} R(\mathfrak{C}) &= \lim_{i\rightarrow\infty}\frac{2^i-i-1}{2^i-1}=1\\ \delta(\mathfrak{C}) &=\lim_{i\rightarrow\infty}\frac{3}{n_i}=0 \end{align*} R(C)δ(C)=i→∞lim2i−12i−i−1=1=i→∞limni3=0
C C C 的信息率趋近于 1 1 1,但距离趋近于 0,即纠错能力趋于没有。 -
我们希望在 δ ( C ) \delta(\mathfrak{C}) δ(C) 和 R ( C ) R(\mathfrak{C}) R(C) 中找到最佳的协调方式,特别地,将满足 δ ( C ) ≠ 0 ≠ R ( C ) \delta(\mathfrak{C})\neq 0\neq R(\mathfrak{C}) δ(C)=0=R(C) 的编码序列称为渐进好的(Asymptotically Good)
边界分析
-
GV Bound 和 Hamming Bound 公式中的体积球 V o l Vol Vol 不利于讨论,为此先定义 q-ary 熵函数(q-ary entropy function),用于化简公式
H q : [ 0 , 1 ] → [ 0 , 1 ] x ↦ x l o g q ( q − 1 ) − x l o g q ( x ) − ( 1 − x ) l o g q ( 1 − x ) \begin{align*} H_q:[0,1]&\rightarrow[0,1]\\ x&\mapsto xlog_q(q-1)-xlog_q(x)-(1-x)log_q(1-x) \end{align*} Hq:[0,1]x→[0,1]↦xlogq(q−1)−xlogq(x)−(1−x)logq(1−x)- 当 x → 0 x\rightarrow 0 x→0 时,上式趋 0
- 当 x → 1 x\rightarrow 1 x→1 时,上式趋 l o g q ( q − 1 ) log_q(q-1) logq(q−1)
- 当 q → ∞ q\rightarrow \infty q→∞ 时, H q ( x ) → x H_q(x)\rightarrow x Hq(x)→x
- 图像整体开口朝下
-
设 q ≥ 2 ∈ Z , 0 ≤ p ≤ 1 − 1 q q\geq 2 \in\mathbb{Z},\ 0\leq p\leq 1-\frac{1}{q} q≥2∈Z, 0≤p≤1−q1,则(略去证明)
q n ⋅ H q ( p ) − o ( n ) ≤ V o l q ( p n , n ) ≤ q n ⋅ H q ( p ) \begin{align*} q^{n\cdot H_q(p)-o(n)}\leq Vol_q(pn, n)\leq q^{n\cdot H_q(p)} \end{align*} qn⋅Hq(p)−o(n)≤Volq(pn,n)≤qn⋅Hq(p) -
根据 Hamming Bound,对任意编码序列 C \mathfrak{C} C,有
R ≤ 1 − 1 n log q ( V o l q ( ⌊ d − 1 2 ⌋ , n ) ) ≤ n → ∞ 1 − H q ( δ ( C ) 2 ) \begin{align*} R &\leq 1-\frac{1}{n}\log_q(Vol_q(\lfloor\frac{d-1}{2}\rfloor,n))\\ &\underset{n\rightarrow \infty}{\leq}1-H_q(\frac{\delta(\mathfrak{C})}2) \end{align*} R≤1−n1logq(Volq(⌊2d−1⌋,n))n→∞≤1−Hq(2δ(C))
根据 GV Bound,存在编码序列 C \mathfrak{C} C,使得
R ≥ 1 − 1 n ( l o g q ( V o l q ( d − 1 , n ) ) − 1 ) ≥ 1 − 1 n ( n ⋅ H q ( d − 1 n ) − o ( n ) − 1 ) ≥ n → ∞ 1 − H q ( δ ( C ) ) \begin{align*} R&\geq 1- \frac{1}{n}(log_q(Vol_q(d-1, n))-1)\\ &\geq 1-\frac{1}{n}(n\cdot H_q(\frac{d-1}{n})-o(n)-1)\\ &\underset{n\rightarrow \infty}{\geq}1-H_q(\delta(\mathfrak{C}))\\ \end{align*} R≥1−n1(logq(Volq(d−1,n))−1)≥1−n1(n⋅Hq(nd−1)−o(n)−1)n→∞≥1−Hq(δ(C)) -
综上,有
1 − H q ( δ ( C ) ) ≤ R ( C ) ≤ 1 − H q ( δ ( C ) 2 ) 1-H_q(\delta(\mathfrak{C}))\leq R(\mathfrak{C})\leq 1-H_q(\frac{\delta(\mathfrak{C})}2) 1−Hq(δ(C))≤R(C)≤1−Hq(2δ(C))
我们将这两个边界分别称为编码序列 C \mathfrak{C} C 的渐进 GV Bound 和渐进 Hamming Bound。当 q = 2 q=2 q=2 时,图像表现为
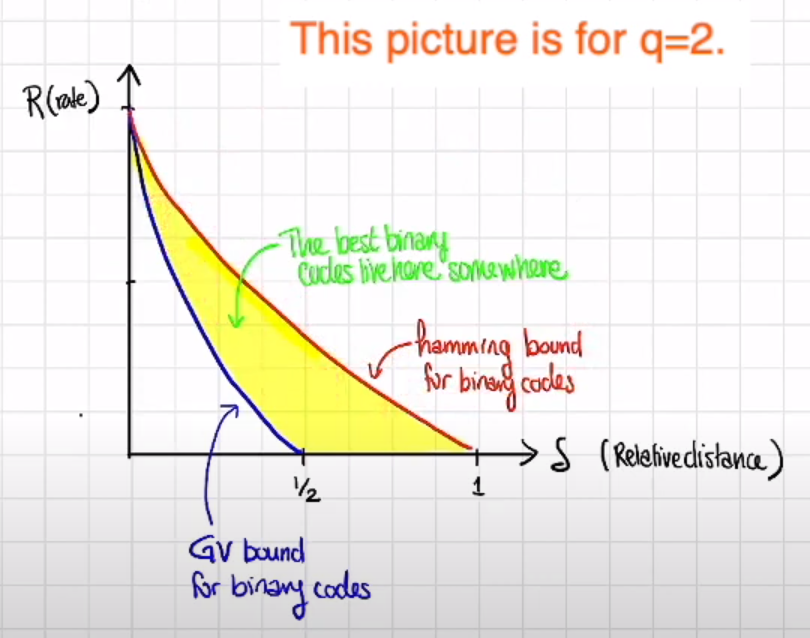
-
延伸
-
Q1:是否存在编码序列,满足渐进 GV Bound,即落在黄色区域
- 当 q ≥ 49 q\geq 49 q≥49 时,问题成立
- 当 q = 2 q=2 q=2 时,这还是个开问题
-
能否构造编码序列,满足渐进 GV Bound,同样地,这个问题也仅在 q q q 足够大时存在
-
渐进 GV Bound 给出蓝线以下的存在性,继而说明了存在“渐近好的”编码序列
-
关于边界分析,还有 Plotkin Bound 等,将图像进一步细化,这些都描述了比率 R ( C ) R(\mathfrak{C}) R(C) 与距离 δ ( C ) \delta(\mathfrak{C}) δ(C) 之间的关系

-
特别注意,本节讨论对编码序列的渐进分析,从图像上看 Singleton Bound 始终在 Plotkin Bound 上方,但这是在 q q q 固定下取极限得到的图像;落实到具体编码时,Singleton Bound 是可以取到的,比如 RS 码。
-
CSDN 对博客长度有字数限制,剩下内容放在下篇讨论。


















 2420
2420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











