







前言
原文地址:SCIBENCH: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
SciBench 是 ICML2024 的一篇论文,之前在整理 NeurIPS 数学研讨会-论文粗读 时关注过这个工作。近期在整类似的基准数据集,来 follow 借鉴这里的行文思路。
内容概括
文章提出了一个基准 SciBench,解决 LLMs 解决科学问题的局限性,提出一个更具挑战性的基准,并分析影响模型能力的十项基本技能。
创新点:
- 创新基准的提出
- 通过消融实验,解释模型当前存在的问题
- 分析影响模型能力的十类问题
SciBench 文章结构
摘要
-
动机:大多数 LLM 基准都集中于高中科目的问题,并且仅限于初等代数运算。为了系统地检查解决复杂科学问题所需的推理能力,我们引入了适用于 LLMs 扩展基准套件 SciBench 。
-
工作概括:SciBench 包含一个精心构造的数据集,其中包含数学、化学和物理领域的一系列大学级别的科学问题。
-
实验结果:基于该数据集,我们对具有各种提示策略的代表性开源和私有 LLM 进行了深入的基准测试研究。结果显示,目前 LLMs 成绩还不够理想,总体最好成绩仅为 43.22%。
-
实验结论:此外,通过详细的用户研究,我们将 LLMs 所犯的错误分为十类问题求解能力。我们的分析表明,没有任何一种提示策略能够显着优于其他策略,并且对于某些解决问题技能有所提高的策略可能会导致其他技能的下降。
-
展望:我们预计 SciBench 将促进LLMs推理能力的进一步发展,从而最终为科学研究和发现做出贡献。
引言
引言是对摘要的扩写。首先,展开论文的动机:
- LLM 当前的发展:LLM 在数学推理等任务表现优异
- 这里潜在的问题和局限性:不能充分评估 LLMs 解决科学问题的推理能力的深度
- 基于这些问题,已有哪些工作以及仍存在的问题:已有工作的包括 COT,外部工具等

- 为了弥补这些问题,提出 SciBench:与现有基准不同,所有问题都是开放式、自由回答的问题,需要多步推理能力、对科学概念的理解、特定领域知识的检索(例如方程和定理)以及复杂的数值能力。
然后概括实验内容:评估包括广泛的代表性开源 和 私有 LLMs。
最后,是实验结论:
- 在人工注释者的帮助下,总结出成功解决科学问题所需的十项基本技能。
- CoT 虽然显着提升了计算能力,但在其他方面效果较差
- 使用外部工具的提示可能会损害其他基本技能
- 小样本学习并不能普遍提高科学解决问题的能力
相关工作
现有的基准,通过图片概括差异:
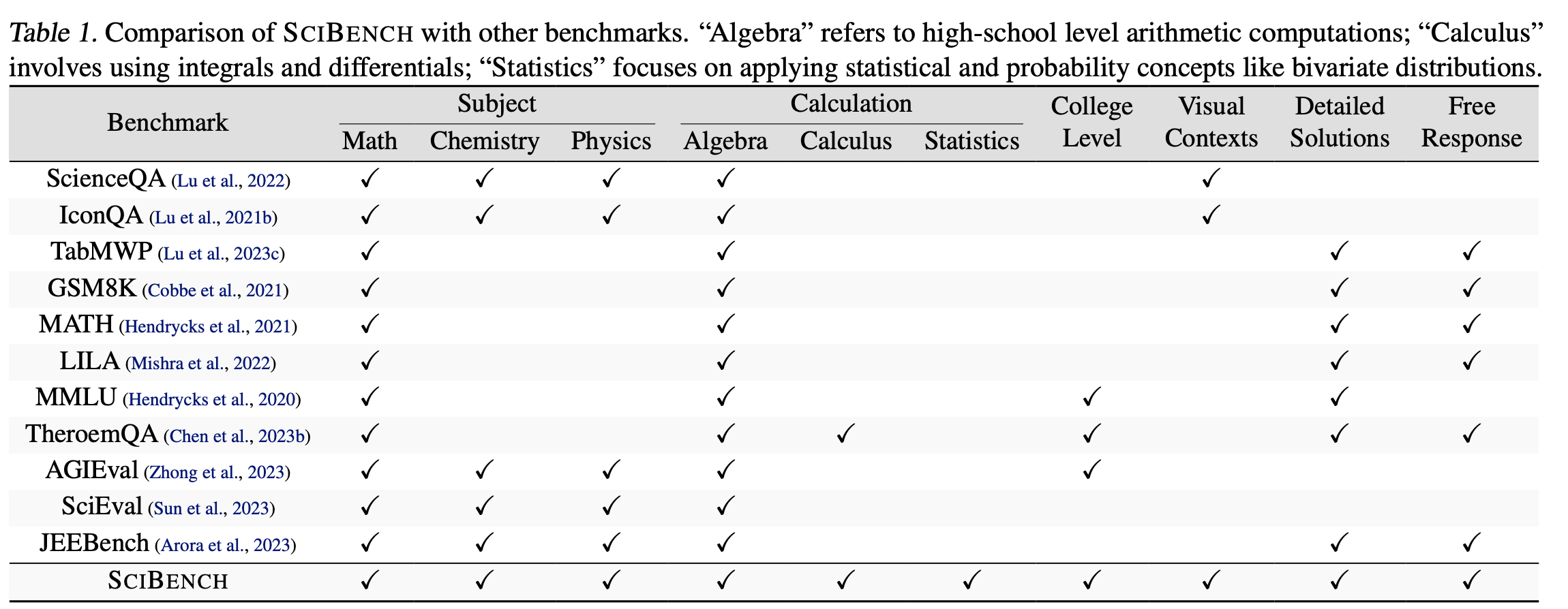
数据集介绍
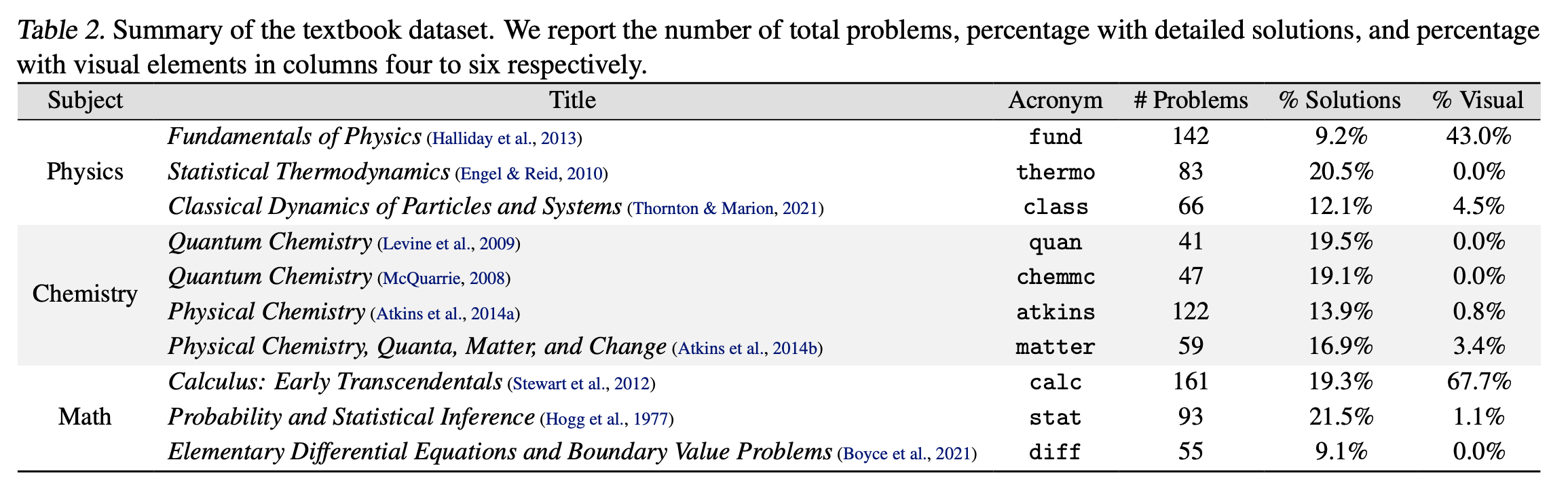
数据集构建过程,包括数据选择标准,数据成分,以及数据预处理方式。
实验设计
- 实验设置:对比的方法策略,以及实施细节
- 结果分析:结合图表,总结结论
- 附加实验:补充实验结论
提示策略分析
这节专门讨论文章摘要提到的,十项基本技能,也是文章的主要结论。对前边的实验结果,进一步解释升华。上一节侧重对现象的描述,这节则进一步分析原因。
结论
这部分和摘要内容类似。
最后,附录放了些数据集具体的来源,few shot 示例,提示词的细节,复现细节(方便复现)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











