







音乐app推荐歌曲为什么符合你的口味?
1. 算法解析
核心思想非常简单、直白:
- 找到跟你口味偏好相似的用户,把他们爱听的歌曲推荐给你;
- 找出跟你喜爱的歌曲特征相似的歌曲,把这些歌曲推荐给你。
1.1基于相似用户做推荐
用“1”表示“喜爱”,用“0”笼统地表示“不发表意见”。
小明的和你的口味相近,共同喜爱的歌曲最多,有5首。
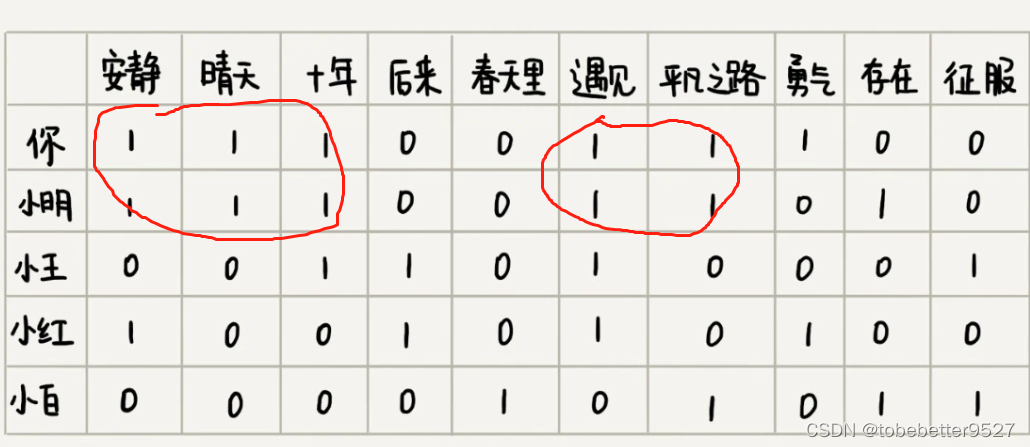
遍历用户,对比用户跟你喜爱歌曲的个数,设定一个阈值,超过这个阈值,就把这个用户喜爱,但你没听过的歌曲推荐给你。
如何判断用户喜爱歌曲的程度?通过用户的行为。

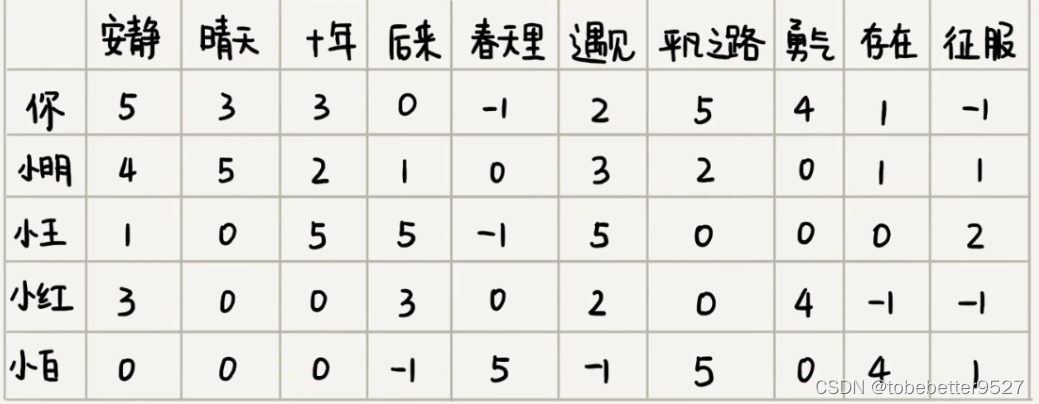
有上面的定义,你和小明喜爱的歌曲可能是这样的:
欧几里得距离
有喜爱程度表后,如何判断用户口味相似? 就是欧几里得距离(Euclidean distance)。
欧几里得距离是用来计算两个向量之间的距离的。这个概念中有两个关键词,向量和距离。
类比一维、二维、三维的表示方法,K维空间中的某个位置,可以写作( X 1 X_{1} X1, X 2 X_{2} X2, X 3 X_{3} X3,…, X K X_{K} XK)。这种表示方法就是向量(vector)。
计算公式:

你和小明的距离最小,说明口味最接近。

1.2 基于相似歌曲做推荐
如何判断两首歌曲是否相似呢?
对歌曲定义一些特征项,比如是伤感的还是愉快的,是摇滚还是民谣,是柔和的还是高亢的等等。类似基于相似用户的推荐方法,我们给每个歌曲的每个特征项打一个分数,这样每个歌曲就都对应一个特征项向量。我们可以基于这个特征项向量,来计算两个歌曲之间的欧几里得距离。欧几里得距离越小,表示两个歌曲的相似程度越大。
人工标注,不可行,工作量大,且主观性比较强。
如果喜欢听的人群都是差不多的,那侧面就可以反映出,这两首歌比较相似。如图所示,每个用户对歌曲有不同的喜爱程度,我们依旧通过上一个解决方案中定义得分的标准,来定义喜爱程度。
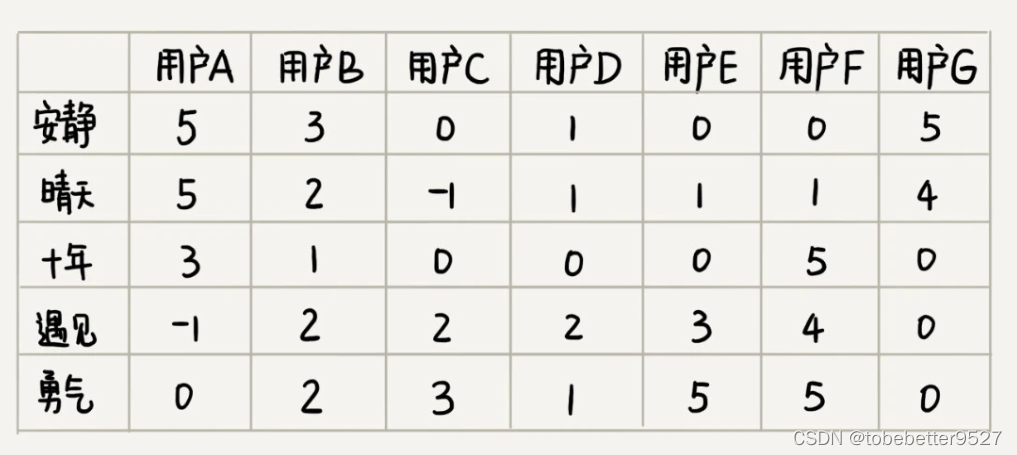
针对每个歌曲,我们将每个用户的打分作为向量,来计算欧几里得距离。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









