







 本文介绍如何爬取bilibili的完结番剧数据,利用B站提供的API接口获取视频信息,提取所需数据并保存为CSV文件。之后,详细说明了使用Python多线程进行数据抓取,并通过邮件服务将结果发送到指定邮箱的实现过程,包括163邮箱的客户端授权密码设置和通过SMTP发送邮件的步骤。
本文介绍如何爬取bilibili的完结番剧数据,利用B站提供的API接口获取视频信息,提取所需数据并保存为CSV文件。之后,详细说明了使用Python多线程进行数据抓取,并通过邮件服务将结果发送到指定邮箱的实现过程,包括163邮箱的客户端授权密码设置和通过SMTP发送邮件的步骤。
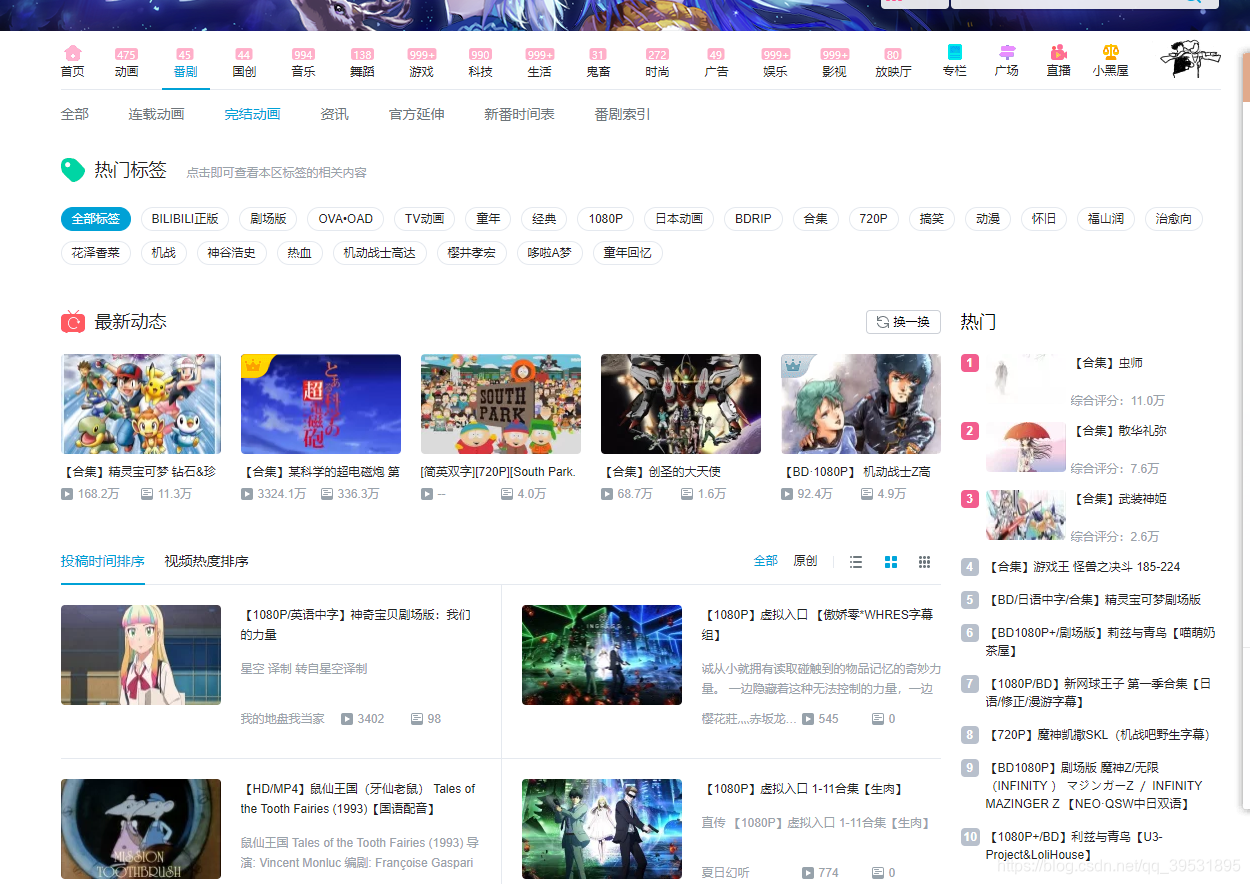
这是b站的完结番剧界面,它属于b站-番剧分区-完结动画区,今天来爬取b站的完结番剧,来了解他们的播放量和硬币数等。
爬取方法:
B站是一个对于爬虫是一个很友好的网站,它对于爬虫有专门的接口
https://github.com/uupers/BiliSpider/wiki
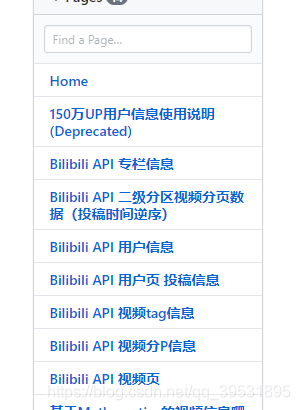
这个网址中有b站各个区域的接口,由于我们爬取的是b站二级分区数据,所以我们可以在这个网页右侧的[Bilibili API 二级分区视频分页数据(投稿时间逆序)]链接中,我们可以看到b站视频数据接口的信息。它是一个json文件。

我们需要用到的就是这部分信息,我们就转而获取视频接口信息的json文件,提取出想要的文件来保存在csv文件中。
我们总的思路是获取视频信息的json文件->提取json数据->保存数据为csv
在爬取过程中,很多网站都有自己的接口,我们可以去寻找接口来让爬取过程变得简单。
具体实现:
这个就是我们所需要获取的json文件的地址了
def get_url():
url = 'http://api.bilibili.com/x/web-interface/newlist?rid=32&pn='
for i in range(1, 328):
urls.append(url + str(i) + '&ps=50')得到json文件中的信息
def get_message(url):
print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









