







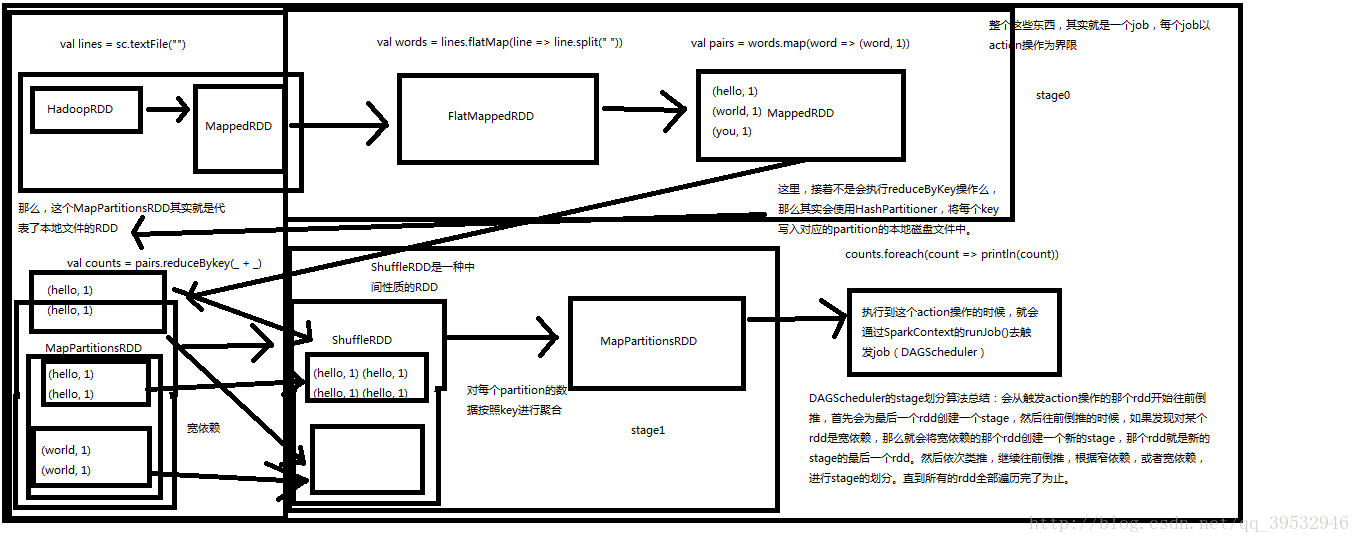
stage划分算法:必须对stage划分算法很清晰,知道自己的Application被划分了几个job,每个job被划分了几个stage,每个stage有哪些代码,只能在线上报错的信息上更快的发现问题或者性能调优。
//DAGscheduler的job调度的核心入口
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
//使用触发job的最后一个RDD创建finalStage
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
//将stage添加到DAGSchedule缓存中
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
//使用finalStage创建一个Job(最后的stage就是finalStage)
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
//将job加入到内存缓存中
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
//使用submitStage提交finalStage
//这个方法的调用,其实会导致第一个stage的提交,其余的stage都储存在栈里。
submitStage(finalStage)
//提交等待的stage
submitWaitingStages()
}
//提交stage的方法
//这里其实就是stage划分算法的入口
//但是stage划分算法是submitStage()和getMissingParentStages()方法共同组成的。
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
//调用getMissingParentStages()获取父stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
//递归调用submitStage()方法,去提交父stage,知道最后没有父stage了。
//此时会提交stage0,其余的stage都在waitingStages里面了。
//这里的递归相当于stage算法的精髓
for (parent <- missing) {
submitStage(parent)
}
// 并且将当前stage放入waitingStages队列中
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
//获取某个Stage的父Stage
//如果发现最后一个RDD的所有依赖都是窄依赖,就不会创建新的RDD。
//但是如果这个RDD宽依赖了某个RDD,那么将会创建一个新的stage。
//并且将新的stage立即返回。
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// 定义了一个栈
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
//如果是宽依赖的话。
//其实对于每一个有shuffle操作的算子,底层都对应了三个RDD(MapPartitionsRDD,shuffleRDD,MapPartitionsRDD)
//shuffleRdd的map端的会划分到新的RDD
case shufDep: ShuffleDependency[_, _, _] =>
//使用宽依赖的RDD创建一个stage,并且会将isshufflemap设置为true
//默认最后一个stage不是shufflemap Stage
//但是fianalstage之前的stage都是shuffleMap stage
val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
//如果是窄依赖,就将RDD放入栈中
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
//首先,向栈中推入了stage的最后一个RDD
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
//对stage的最后一个RDD,调用Visit()方法
visit(waitingForVisit.pop())
}
missing.toList
}
//提交stage,为stage创建一批task,task数量与partition数量相同
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// 获取partition数量
stage.pendingPartitions.clear()
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
initialized.
if (stage.internalAccumulators.isEmpty || stage.numPartitions == partitionsToCompute.size) {
stage.resetInternalAccumulators()
}
val properties = jobIdToActiveJob(jobId).properties
//将stage加入runningStages队列
runningStages += stage
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
val job = s.activeJob.get
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
var taskBinary: Broadcast[Array[Byte]] = null
try {
case stage: ShuffleMapStage =>
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
case stage: ResultStage =>
closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
//为stage创建指定数量的task
val tasks: Seq[Task[_]] = try {
stage match {
//除了final Stage不是shuffle Stage。
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
//给每一个partition创建一个task
//给每个task最佳位置
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
//给shuffle Stage创建ShuffleStageTask
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.internalAccumulators)
}
//不是S户发放了 Stage就是finalStage。那么创建ResultStage
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
//给每一个partition创建一个task
//给每个task最佳位置(就是从stage的最后位置开始找,哪个RDD的Partition被Cache了,或被checkPoint了,那么task的最佳位置就是RDD被Cache或者被CheckPoint的位置)
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, stage.internalAccumulators)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
}
}stage划分算法总结:
- 从finalstage倒推
- 通过宽依赖进行stage划分
- 通过递归,优先提交父stage















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









