






 本文介绍了使用Python自动化登录校园网的两种方法:一种是通过Selenium的webdriver模拟浏览器操作,另一种是利用Requests模块抓包分析后发送HTTP请求。文中详细讲解了每种方法的实现步骤,包括XPath定位元素、发送登录请求及处理登录后的网络连接。这两种方法各有利弊,Selenium直观但速度慢,Requests速度快但调试复杂。
本文介绍了使用Python自动化登录校园网的两种方法:一种是通过Selenium的webdriver模拟浏览器操作,另一种是利用Requests模块抓包分析后发送HTTP请求。文中详细讲解了每种方法的实现步骤,包括XPath定位元素、发送登录请求及处理登录后的网络连接。这两种方法各有利弊,Selenium直观但速度慢,Requests速度快但调试复杂。
本文首发于:本人博客 【python】自动登录中科大校园网
最近在做一个项目,其中就需要自动联网的功能。不过由于不可能把手机一直留在宿舍开热点,就只能连接wifi了。学校里有ustcnet(校园网)和eduroam两种wifi,其中前者是连接后通过浏览器上登录账号并开通网络后才可以使用的,而eduroam是通过用户名和密码来进行连接的(应用IEEE 802.1x协议进行接入,基于RADIUS协议进行接入认证,具体笔者也不清楚),和普通的使用ssid和密码接入wifi的过程有着天壤之别,所以笔者选择了连接校园网来实现所需功能。
前文提到了登录校园网需要通过浏览器进行操作,其实本质上就是和服务器端进行http协议通信,发送用户名和密码让服务端给你的IP提供一个access,这样就可以访问网络了。
在参考了多篇前辈编写的校园网自动登录脚本后[1],[2],[3],其实现方法大致可以总结如下:
1. 利用selenium模块中的webdriver类模拟一个浏览器,然后在浏览器中模拟点击,以通过网页原生的方式向服务端发送连接请求
2. 通过抓包获取网页向服务端发送的连接请求数据格式,并利用requests模块向服务端发送连接请求
一、webdriver方式
这种方法主要摘自[1],并没有太多的改动,原文的讲解很详细,推荐去看原作者。下面给出实现代码。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import subprocess
def spider():
driver = webdriver.Chrome()
driver.get('http://wlt.ustc.edu.cn') #这里输入你的校园网登录网址
time.sleep(1)
input_tag = driver.find_element(By.XPATH, "//input[@name='name' and @class='sform']") #通过xpath确定账号框位置
input_tag.send_keys("your_account") #输入账号
input_tag2 = driver.find_element(By.XPATH, "//input[@name='password' and @class='sform']") #通过xpath确定密码框位置
input_tag2.send_keys("your_password") #输入密码
input_tag2.send_keys(Keys.ENTER) #敲一下回车
time.sleep(1)
input_tag3 = driver.find_element(By.XPATH, "//input[@name='go' and @type='submit']") #找到开通网络按钮
input_tag3.send_keys(Keys.ENTER) #敲一下回车
time.sleep(1) # 1秒后自动关闭浏览器
# 测试网络是否连通
def Ping():
backinfo = subprocess.call('ping www.zhihu.com -n 1', shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if backinfo:
print('网络未连接')
return 1
else:
print("有网")
return 2
if __name__ == '__main__':
spider()
print("连接网络中·····")
connection = Ping()
if connection == 2 :
print("ping")
elif connection == 1:
spider()
exit()对此方法中的值得注意的点进行以下总结:
1. 原文中利用的是`driver.find_element_by_xpath()` 函数,这种方法已经被弃用,此处使用`driver.find_element(By.XPATH, "xpath_str")`进行xpath寻找。
2. 具体用xpath匹配什么需要依不同的校园网而定,一般有交互的控件都带有input的标签,所以f12打开元素审查,搜索'input'或者搜索控件的内容就可以找到控件的name、class、style等信息,再利用这些信息进行xpath匹配即可。
3. 不要ping校内网站,即使没有登录校园网,也是可以浏览校内网站的。
二、requests方式
校内网登录的方式一般有GET和POST两种方式[3],使用GET方式只需要把账号密码放在url的参数中即可,此处不赘言,而POST方式更为常见,此处主要讨论这种方法。
这种方法主要通过抓包获取网页向服务端发送的数据格式,然后再利用requests发送http包。
1. 抓包
打开浏览器无痕模式(这点很重要,不然你会发现你发送的第一个包就有cookie),在浏览器中打开校园网网站,f12打开开发者工具,点击上方的network

然后再输入你的账号和密码之后,点击登录,留意刚刚抓到的包,点击它查看具体数据。
2. 登录账户
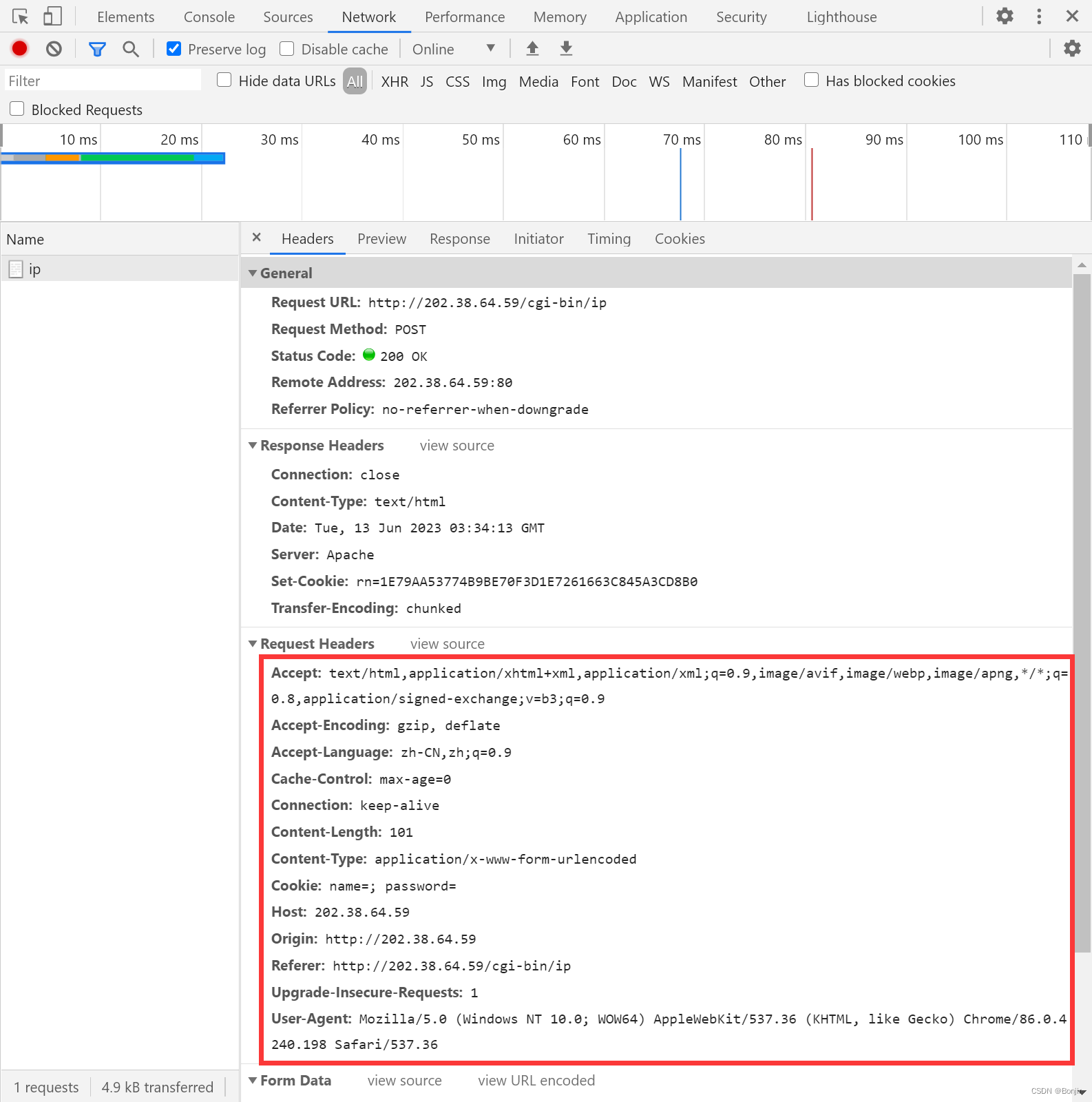
把上面红框内的部分复制下来,把冒号前面和冒号后面分别用引号圈起来。
post_header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
...
"Content-Length": str(len(urlencode(post_data))),
"Content-Type": "application/x-www-form-urlencoded",
...
}在构建好request_header字典之后,注意到其中有一项content-length,这项就是表单的长度。在request_header的下面可以发现form_data(也可能是其他形式的请求数据,因不同校园网而定),把这部分也复制下来制成字典。
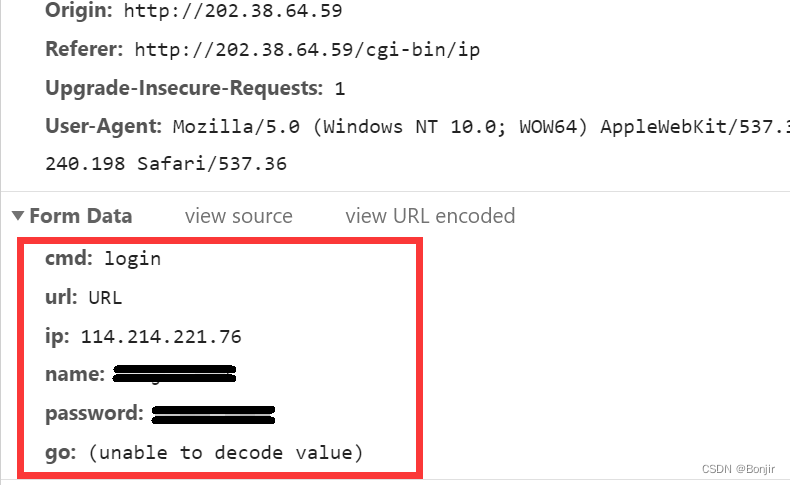
不过需要注意的是,这里面有一部分不可以直接复制,就是`go:(unable to decode value)`这项,需要点击view URL encoded,把对应位置的URL编码字符串转换成GBK编码,即可放入请求数据的字典中去。具体的转换方式是把 ‘+’ 改成 ‘ ’ , ‘%’ 去掉,剩余部分是GBK编码的汉字,利用编码转换网站 将GBK编码转换成汉字,然后再encode(“GBK”)即可。

go_login = "登录账户"
post_data = {
...
"go": go_login.encode("GBK")
}然后在浏览器开发工具的general部分找到requested URL,将此url设为`post_addr`,在利用`rq = requests.post(post_addr, headers=post_header, data=post_data)`即可发送数据。注意此处有必要把request的返回值记录下来,因为response包里有cookie,进行后续的操作需要用到。
3. 开通网络
有些校园网可能登陆之后就自动连接了网络,不过笔者的校园网需要再额外多一个开通网络的步骤。
点击开通网络,抓包发现这个数据包是GET类型,继续像之前把数据复制下来做成字典。可以看到这里的请求数据包里有一项cookie,值为上面登录账户过程中response里的set-cookie值。
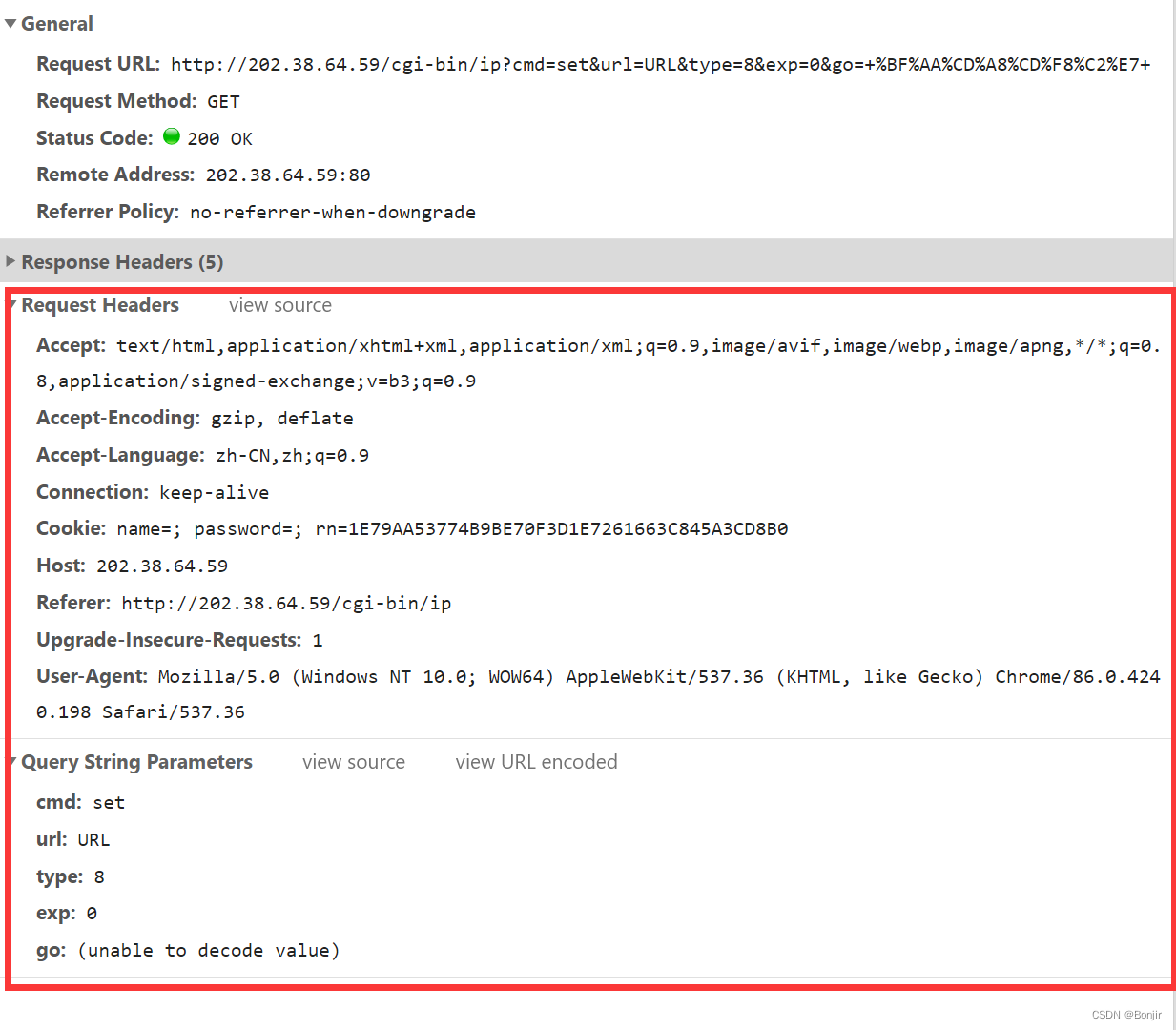
下面给出完整实现代码。
import socket
import requests
import subprocess
import re
import json
from urllib.parse import urlencode
from urllib.parse import parse_qs, urlparse
def get_host_ip():
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(("10.255.255.255", 1))
ip = s.getsockname()[0]
finally:
s.close()
return ip
user_ip = get_host_ip()
print("局域网ip为{}".format(user_ip))
user_name = "your username"
user_password = "your password"
def LogIn():
login_url = "http://202.38.64.59/cgi-bin/ip"
go_login = str("登录账户".encode("GBK"))
go_login = go_login[2:-1]
login_data = {
"cmd": "login",
"url": "URL",
"ip": user_ip,
"name": user_name,
"password": user_password,
"go": go_login
}
login_header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Content-Length": str(len(urlencode_simple(login_data))),
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "name=; password=",
"Host": "202.38.64.59",
"Origin": "http://202.38.64.59",
"Referer": "http://202.38.64.59/cgi-bin/ip",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
# rq = requests.post(login_url, headers=login_header, data=json.dumps(login_data))
rq = requests.post(login_url, headers=login_header, data=login_data)
if "Set-Cookie" in rq.headers:
cookie_rn = rq.headers["Set-Cookie"]
else :
print("No cookie in headers! Headers:\n{}\nText:\n{}".format(rq.headers, rq.text))
# print("No cookie in headers! Headers:\n{}\nText:\n{}".format(rq.headers, rq.text.encode("utf-8")))
cookie_rn = ""
return rq.status_code, cookie_rn
def Connect(cookie_rn):
connect_url = r"http://202.38.64.59/cgi-bin/ip?cmd=set&url=URL&type=8&exp=0&go=+%BF%AA%CD%A8%CD%F8%C2%E7+"
connect_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'name=; password=; {rn}'.format(rn = cookie_rn),
'Host': '202.38.64.59',
'Referer': 'http://202.38.64.59/cgi-bin/ip',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
go_submit = " 开通网络 "
query_string_params = {
'cmd': 'set',
'url': 'URL',
'type': '8',
'exp': '0',
"go": go_submit.encode("GBK")
}
# print("go_submit: {}".format(go_submit.encode("GBK")))
rq = requests.get(connect_url, headers=connect_headers, data=query_string_params)
return rq.status_code
def LogOut(cookie_rn):
try:
cookie_rn = cookie_rn
except :
raise ValueError("Please Login() before Logout()!")
logout_url = "http://202.38.64.59/cgi-bin/ip?cmd=logout"
logout_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'name=; password=; {rn}'.format(rn = cookie_rn),
'Host': '202.38.64.59',
'Referer': 'http://202.38.64.59/cgi-bin/ip?cmd=set&url=URL&type=8&exp=0&go=+%BF%AA%CD%A8%CD%F8%C2%E7+',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
logout_data = {"cmd": "logout"}
rq = requests.get(logout_url, headers = logout_headers, data = logout_data)
if rq.status_code != 200:
print("In _logout(): \n logout failed with status code {sc}, \n headers:\n{hd} \n text:\n{tx}".\
format(sc = rq.status_code, hd = rq.headers, tx = rq.text))
ret = rq.status_code
rq.close()
return ret
def Ping():
backinfo = subprocess.call("ping www.bilibili.com -n 1", shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if backinfo:
print("网络未连接")
return 0
else:
print("网络已连接")
return 1
def urlencode_simple(query: dict):
url = ""
for key in query:
keycpy = str(key)
value = str(query[key])
if type(query[key]) == bytes:
value = value[2:-1]
keycpy = keycpy.replace('@', '%40')
keycpy = keycpy.replace(r'\x', '%')
keycpy = keycpy.replace(r' ', '+')
value = value.replace('@', '%40')
value = value.replace(r'\x', '%')
value = value.replace(r' ', '+')
url += "{}={}&".format(keycpy, value)
url = url[0:-1]
return url
if __name__ == "__main__":
# z = requests.get(login_url)
# print("Response: {}".format(z.status_code))
connection = Ping() #检测网络是否连通
print("连接网络中·····")
status_code, cookie_rn = LogIn()
if status_code != 200:
print("LogIn Error with status code: {}".format(status_code))
exit()
else:
print("Login Response code: {}".format(status_code))
status_code = Connect(cookie_rn)
if status_code != 200:
print("Connect Error with status code: {}".format(status_code))
exit()
else:
print("Connect Response code: {}".format(status_code))
connection = Ping() #检测网络是否连通
status_code = LogOut(cookie_rn)
if status_code != 200:
print("LogOut Error with status code: {}".format(status_code))
exit()
else:
print("LogOut Response code: {}".format(status_code))
connection = Ping() #检测网络是否连通
exit()笔者踩的一个比较大的坑就是每次发送GET/POST包的远端地址不要搞错了,需要是抓包获得的request URL,如果这个搞错了很可能会返回错误码405。
这样基本就完成了python自动登入校园网的实现。总结一下,第一种方式是利用webdriver类模拟浏览器进行爬虫操作,优点是实现简单,调试直观,代码简短,不过缺点是速度慢、不好把控(如果sleep时间少了会导致服务器没加载完),而且外观比较丑陋、不能静默实现爬虫;第二种方式是利用requests发送http包进行爬虫操作,优点是速度快、可以后台进行、让笔者了解了更多HTTP和网络知识、同时因为不用模拟浏览器,也就不局限于操作系统,http包的发送可以在单片机上进行,缺点是调试困难没有头绪,代码繁杂,堪称BUG妙妙屋。
以上就是此次项目的实现以及讲解,希望能给各位读者带来帮助~
主要参考:
[1] 基于python的校园网自动登录脚本!_zhihu.com_@Python小萌新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









