






NeRV: Neural Representations for Videos
Abstract
We propose a novel neural representation for videos (NeRV) which encodes videos in neural networks. Unlike conventional representations that treat videos as frame sequences, we represent videos as neural networks taking frame index as input. Given a frame index, NeRV outputs the corresponding RGB image. Video encoding in NeRV is simply fitting a neural network to video frames and decoding process is a simple feedforward operation. As an image-wise implicit representation, NeRV output the whole image and shows great efficiency compared to pixelwise implicit representation, improving the encoding speed by 25× to 70×, the decoding speed by 38× to 132×, while achieving better video quality. With such a representation, we can treat videos as neural networks, simplifying several videorelated tasks. For example, conventional video compression methods are restricted by a long and complex pipeline, specifically designed for the task. In contrast, with NeRV, we can use any neural network compression method as a proxy for video compression, and achieve comparable performance to traditional frame-based video compression approaches (H.264, HEVC etc.). Besides compression, we demonstrate the generalization of NeRV for video denoising. The source code and pre-trained model can be found at “https://github.com/haochen-rye/NeRV.git”.
我们提出了一种新的视频神经表示方法(NeRV),它将视频编码到神经网络中。与传统的表示方法不同,我们将视频表示为以帧索引为输入的神经网络。给定一个帧索引,NeRV输出相应的RGB图像。神经网络中的视频编码只是将神经网络与视频帧相匹配,解码过程是一个简单的前馈操作。作为一种图像隐式表示,神经网络输出整个图像,与像素隐式表示相比效率更高,编码速度提高了25倍至70倍,解码速度提高了38倍至132倍,同时获得了更好的视频质量。有了这样的表示,我们可以将视频视为神经网络,从而简化几个与视频相关的任务。例如,传统的视频压缩方法受到专门为该任务设计的长而复杂的管道的限制。相比之下,使用神经网络,我们可以使用任何神经网络压缩方法作为视频压缩的代理,并实现与传统的基于帧的视频压缩方法(H.264、HEVC等)相当的性能。除了压缩,我们还展示了神经网络在视频去噪中的推广。可以在“https://github.com/haochen-rye/NeRV.git”上找到源代码和预先训练的模型。
1 Introduction
What is a video? Typically, a video captures a dynamic visual scene using a sequence of frames. A schematic interpretation of this is a curve in 2D space, where each point can be characterized with a (x, y) pair representing the spatial state. If we have a model for all (x, y) pairs, then, given any x, we can easily find the corresponding y state. Similarly, we can interpret a video as a recording of the visual world, where we can find a corresponding RGB state for every single timestamp. This leads to our main claim: can we represent a video as a function of time?
什么是视频?通常,视频使用一系列帧捕捉动态视觉场景。对这一点的图解解释是二维空间中的曲线,其中每个点都可以用代表空间状态的(x,y)对来表征。如果我们对所有(x,y)对都有一个模型,那么,给定任何x,我们可以很容易地找到相应的y态。类似地,我们可以将视频解释为视觉世界的记录,在这里我们可以找到每个时间戳对应的RGB状态。这就引出了我们的主要观点:我们能否将视频表示为时间的函数?
More formally, can we represent a video V as V = {vt}, where vt = fθ(t), a frame at timestamp t, is represented as a function f parameterized by θ. Given their remarkable representational capacity, we choose deep neural networks as the function in our work. Given these intuitions, we propose NeRV, a novel representation that represents videos as implicit functions and encodes them into neural networks. Specifically, with a fairly simple deep neural network design, NeRV can reconstruct the corresponding video frames with high quality, given the frame index. Once the video is encoded into a neural network, this network can be used as a proxy for video, where we can directly extract all video information from the representation. Therefore, unlike traditional video representations which treat videos as sequences of frames, shown in Figure 1(a), our proposed NeRV considers a video as a unified neural network with all information embedded within its architecture and parameters, shown in Figure 1(b).
更正式地说,我们可以将视频V表示为V={vt},其中vt=fθ(t),时间戳t处的帧,表示为θ参数化的函数f。考虑到它们卓越的代表能力,我们选择深层神经网络作为我们工作中的功能。基于这些直觉,我们提出了NeRV,这是一种新的表示方法,将视频表示为隐函数,并将其编码到神经网络中。具体来说,通过一个相当简单的深层神经网络设计,在给定帧索引的情况下,神经网络可以高质量地重建相应的视频帧。一旦视频被编码成神经网络,这个网络就可以作为视频的代理,我们可以直接从表示中提取所有视频信息。因此,与图1(a)所示的将视频视为帧序列的传统视频表示不同,我们提出的神经网络将视频视为一个统一的神经网络,其结构和参数中嵌入了所有信息,如图1(b)所示。
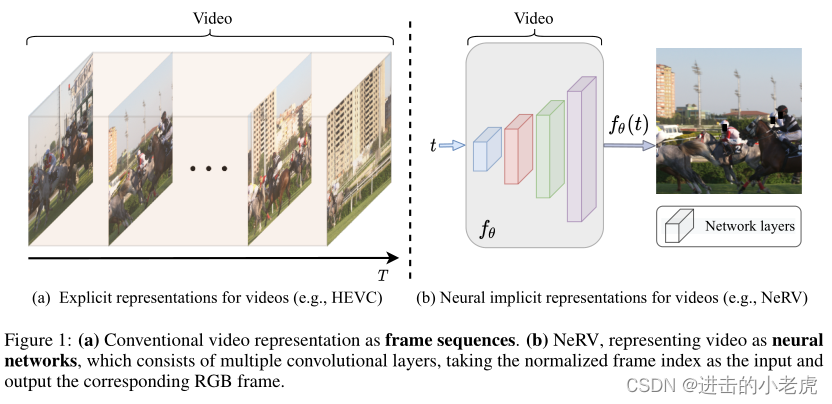
As an image-wise implicit representation, NeRV shares lots of similarities with pixel-wise implicit visual representations which takes spatial-temporal coordinates as inputs. The main differences between our work and image-wise implicit representation are the output space and architecture designs. Pixel-wise representations output the RGB value for each pixel, while NeRV outputs a whole image, demonstrated in Figure 2. Given a video with size of T×H×W , pixel-wise representations need to sample the video T∗H∗W times while NeRV only need to sample T times. Considering the huge pixel number, especially for high resolution videos, NeRV shows great advantage for both encoding time and decoding speed. Different output space also leads to different architecture designs, NeRV utilizes a MLP + ConvNets architecture to output an image while pixel-wise representation uses a simple MLP to output the RGB value of the pixel. Sampling efficiency of NeRV also simplify the optimization problem, which leads to better reconstruction quality compared to pixel-wise representations.
作为一种图像隐式表示,神经网络与以时空坐标为输入的像素隐式视觉表示有许多相似之处。我们的工作与图像隐式表达的主要区别在于输出空间和建筑设计。像素表示输出每个像素的RGB值,而NeRV输出整个图像,如图2所示。给定一个大小为T×H×W的视频,像素级表示需要对视频进行采样T∗H∗W次,而NeRV只需要采样T次。考虑到巨大的像素数,尤其是对于高分辨率视频,神经网络在编码时间和解码速度上都显示出巨大的优势。不同的输出空间也会导致不同的架构设计,NeRV使用MLP+ConvNets架构来输出图像,而像素级表示使用简单的MLP来输出像素的RGB值。神经网络的采样效率也简化了优化问题,与像素级表示相比,它可以获得更好的重建质量。
We also demonstrate the flexibility of NeRV by exploring several applications it affords. Most notably, we examine the suitability of NeRV for video compression. Traditional video compression frameworks are quite involved, such as specifying key frames and inter frames, estimating the residual information, block-size the video frames, applying discrete cosine transform on the resulting image blocks and so on. Such a long pipeline makes the decoding process very complex as well. In contrast, given a neural network that encodes a video in NeRV, we can simply cast the video compression task as a model compression problem, and trivially leverage any well-established or cutting edge model compression algorithm to achieve good compression ratios. Specifically, we explore a three-step model compression pipeline: model pruning, model quantization, and weight encoding, and show the contributions of each step for the compression task. We conduct extensive experiments on popular video compression datasets, such as UVG, and show the applicability of model compression techniques on NeRV for video compression. We briefly compare different video representations in Table 1 and NeRV shows great advantage in decoding speed.
我们还通过探索NeRV提供的几个应用程序,展示了NeRV的灵活性。最值得注意的是,我们研究了神经网络在视频压缩中的适用性。传统的视频压缩框架涉及很多方面,如指定关键帧和帧间信息、估计残差信息、视频帧的块大小、对生成的图像块应用离散余弦变换等。如此长的管道也使得解码过程非常复杂。相比之下,如果使用神经网络对视频进行编码,我们可以简单地将视频压缩任务转换为模型压缩问题,并轻松利用任何成熟的或前沿的模型压缩算法来实现良好的压缩比。具体来说,我们探索了一个三步模型压缩管道:模型修剪、模型量化和权重编码,并展示了每一步对压缩任务的贡献。我们在流行的视频压缩数据集(如UVG)上进行了大量实验,并展示了模型压缩技术在神经网络视频压缩中的适用性。我们在表1中简要比较了不同的视频表示,NeRV在解码速度上显示了巨大的优势。
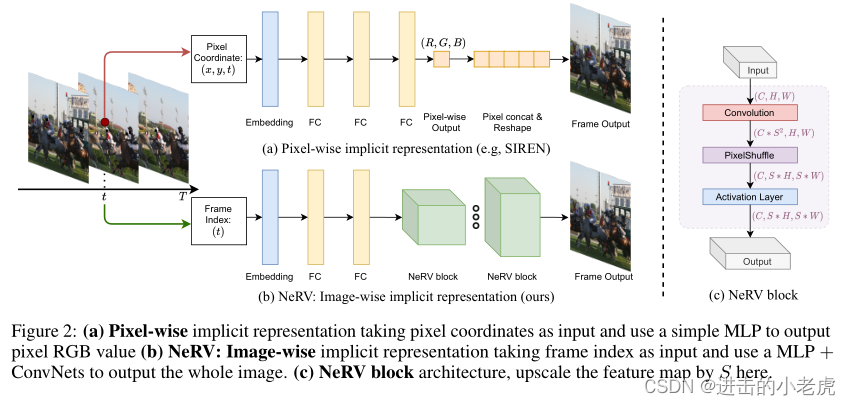
Besides video compression, we also explore other applications of the NeRV representation for the video denoising task. Since NeRV is a learnt implicit function, we can demonstrate its robustness to noise and perturbations. Given a noisy video as input, NeRV generates a high-quality denoised output, without any additional operation, and even outperforms conventional denoising methods.
除了视频压缩,我们还探索了神经网络表示在视频去噪任务中的其他应用。由于神经网络是一个学习的隐函数,我们可以证明它对噪声和扰动的鲁棒性。给定一个有噪声的视频作为输入,NeRV可以生成高质量的去噪输出,而无需任何额外操作,甚至比传统的去噪方法表现得更好。
The contribution of this paper can be summarized into four parts:
本文的贡献可以概括为四个部分:
We propose NeRV, a novel image-wise implicit representation for videos, representating a video as a neural network, converting video encoding to model fitting and video decoding as a simple feedforward operation.
我们提出了一种新的基于图像的视频隐式表示方法,将视频表示为神经网络,将视频编码转换为模型拟合,并将视频解码转换为简单的前馈操作。
Compared to pixel-wise implicit representation, NeRV output the whole image and shows great efficiency, improving the encoding speed by 25× to 70×, the decoding speed by 38× to 132×, while achieving better video quality.
与像素级隐式表示相比,神经网络输出整个图像,效率更高,编码速度提高了25倍至70倍,解码速度提高了38倍至132倍,同时获得了更好的视频质量。
NeRV allows us to convert the video compression problem to a model compression problem, allowing us to leverage standard model compression tools and reach comparable performance with conventional video compression methods, e.g.
NeRV允许我们将视频压缩问题转化为模型压缩问题,允许我们利用标准模型压缩工具,并达到与传统视频压缩方法相当的性能。
As a general representation for videos, NeRV also shows promising results in other tasks, e.g., video denoising. Without any special denoisng design, NeRV outperforms traditional hand-crafted denoising algorithms (medium filter etc.) and ConvNets-based denoisng methods.
作为视频的一般表示,神经网络在其他任务中也显示出了良好的效果,例如视频去噪。在没有任何特殊的去噪设计的情况下,NeRV优于传统的手工去噪算法(中值滤波等)和基于ConvNets的去噪方法。
2 Related Work
Implicit Neural Representation. Implicit neural representation is a novel way to parameterize a variety of signals. The key idea is to represent an object as a function approximated via a neural network, which maps the coordinate to its corresponding value (e.g., pixel coordinate for an image and RGB value of the pixel). It has been widely applied in many 3D vision tasks, such as 3D shapes, 3D scenes, and appearance of the 3D structure. Comparing to explicit 3D representations, such as voxel, point cloud, and mesh, the continuous implicit neural representation can compactly encode high-resolution signals in a memory-efficient way. Most recently, demonstrated the feasibility of using implicit neural representation for image compression tasks. Although it is not yet competitive with the state-of-the-art compression methods, it shows promising and attractive proprieties. In previous methods, MLPs are often used to approximate the implicit neural representations, which take the spatial or spatio-temporal coordinate as the input and output the signals at that single point (e.g., RGB value, volume density). In contrast, our NeRV representation, trains a purposefully designed neural network composed of MLPs and convolution layers, and takes the frame index as input and directly outputs all the RGB values of that frame.
隐神经表示。内隐神经表示是一种对各种信号进行参数化的新方法。其关键思想是将对象表示为通过神经网络逼近的函数,该函数将坐标映射到相应的值(例如,图像的像素坐标和像素的RGB值)。它被广泛应用于许多三维视觉任务,如三维形状、三维场景、三维结构的外观。与体素、点云、网格等显式3D表示相比,连续隐式神经表示可以以一种高效存储的方式对高分辨率信号进行压缩编码。最近,证明了使用隐式神经表示进行图像压缩任务的可行性。虽然它还不能与最先进的压缩方法竞争,但它显示出了有前途和有吸引力的特性。在以往的方法中,常常使用MLPs来逼近隐式神经表示,将空间或时空坐标作为该单点(如RGB值、体积密度)的输入和输出信号。相比之下,我们的NeRV表示训练了一个由MLPs和卷积层组成的有目的设计的神经网络,并以帧索引作为输入,直接输出该帧的所有RGB值。
Video Compression. As a fundamental task of computer vision and image processing, visual data compression has been studied for several decades. Before the resurgence of deep networks, handcrafted image compression techniques, like JPEG and JPEG2000 , were widely used. Building upon them, many traditional video compression algorithms, such as MPEG, H.264, and HEVC, have achieved great success. These methods are generally based on transform coding like Discrete Cosine Transform (DCT) or wavelet transform, which are well-engineered and tuned to be fast and efficient. More recently, deep learning-based visual compression approaches have been gaining popularity. For video compression, the most common practice is to utilize neural networks for certain components while using the traditional video compression pipeline. For example, proposed an effective image compression approach and generalized it into video compression by adding interpolation loop modules. Similarly, converted the video compression problem into an image interpolation problem and proposed an interpolation network, resulting in competitive compression quality. Furthermore, generalized optical flow to scale-space flow to better model uncertainty in compression. Later, employed a temporal hierarchical structure, and trained neural networks for most components including key frame compression, motion estimation, motions compression, and residual compression. However, all of these works still follow the overall pipeline of traditional compression, arguably limiting their capabilities.
视频压缩。视觉数据压缩作为计算机视觉和图像处理的一项基本任务,已经研究了几十年。在深度网络复兴之前,手工制作的图像压缩技术,如JPEG和JPEG2000,被广泛使用。在此基础上,许多传统的视频压缩算法,如MPEG、H.264、HEVC等都取得了巨大的成功。这些方法通常是基于变换编码,如离散余弦变换(DCT)或小波变换,这些都是经过精心设计和调整,以实现快速和高效。最近,基于深度学习的视觉压缩方法越来越受欢迎。对于视频压缩,最常见的做法是在使用传统视频压缩管道的同时,对某些组件使用神经网络。例如,提出了一种有效的图像压缩方法,并通过加入插值环路模块将其推广到视频压缩中。同样,将视频压缩问题转化为图像插值问题,并提出插值网络,导致压缩质量竞争。进一步,将光流推广到尺度空间流,以更好地模拟压缩中的不确定性。之后,采用时间层次结构,训练神经网络的大多数组件,包括关键帧压缩,运动估计,运动压缩和剩余压缩。然而,所有这些工作仍然遵循传统压缩的整体管道,可以说限制了它们的能力。
Model Compression. The goal of model compression is to simplify an original model by reducing the number of parameters while maintaining its accuracy. Current research on model compression research can be divided into four groups: parameter pruning and quantization; low-rank factorization; transferred and compact convolutional filters; and knowledge distillation. Our proposed NeRV enables us to reformulate the video compression problem into model compression, and utilize standard model compression techniques. Specifically, we use model pruning and quantization to reduce the model size without significantly deteriorating the performance.
压缩模型。模型压缩的目的是通过减少参数的数量来简化原始模型,同时保持模型的准确性。目前模型压缩的研究主要分为四类:参数剪枝和量化;低秩分解;转移和紧卷积滤波器;和知识蒸馏。我们提出的NeRV使我们能够将视频压缩问题重新表述为模型压缩,并利用标准模型压缩技术。具体地说,我们使用模型剪枝和量化来减少模型的大小,而不会显著地影响性能。
3 Neural Representations for Videos
We first present the NeRV representation in Section 3.1, including the input embedding, the network architecture, and the loss objective. Then, we present model compression techniques on NeRV in Section 3.2 for video compression.
我们首先在3.1节介绍了NeRV表示,包括输入嵌入、网络架构和损失目标。然后,我们在第3.2节介绍了NeRV上的视频压缩模型压缩技术。
3.1 NeRV Architecture
In NeRV, each video V = { vt } is represented by a function fθ:R→R^(H×W ×3), where the input is a frame index t and the output is the corresponding RGB image vt ∈ R^(H×W×3). The encoding function is parameterized with a deep neural network θ, vt = fθ(t). Therefore, video encoding is done by fitting a neural network fθ to a given video, such that it can map each input timestamp to the corresponding RGB frame.
在NeRV中,每个视频V = {vt}用函数fθ:R→R^(H×W ×3)表示,其中输入为帧索引t,输出为对应的RGB图像vt∈R^(H×W×3)。利用深度神经网络θ, vt = fθ(t)对编码函数进行参数化。因此,视频编码是通过拟合神经网络fθ到给定的视频,这样它可以将每个输入时间戳映射到相应的RGB帧。
Input Embedding. Although deep neural networks can be used as universal function approximators, directly training the network fθ with input timestamp t results in poor results, which is also observed. By mapping the inputs to a high embedding space, the neural network can better fit data with high-frequency variations. Specifically, in NeRV, we use Positional Encoding as our embedding function.
输入嵌入。虽然深度神经网络可以作为通用函数逼近器,但直接用输入时间戳 t 训练网络 fθ 的结果很差,这也是可以观察到的。通过将输入映射到高嵌入空间,神经网络可以更好地拟合高频变化的数据。具体来说,在NeRV中,我们使用位置编码作为我们的嵌入函数。
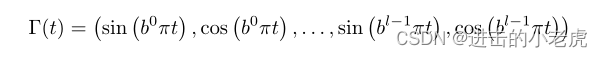
where b and l are hyper-parameters of the networks. Given an input timestamp t, normalized between (0,1], the output of embedding function Γ(·) is then fed to the following neural network.
其中b和l为网络的超参数。给定一个输入时间戳t,在(0,1)之间归一化,然后将嵌入函数Γ(·)的输出输入到以下神经网络。
Network Architecture. NeRV architecture is illustrated in Figure 2(b). NeRV takes the time embedding as input and outputs the corresponding RGB Frame. Leveraging MLPs to directly output all pixel values of the frames can lead to huge parameters, especially when the images resolutions are large. Therefore, we stack multiple NeRV blocks following the MLP layers so that pixels at different locations can share convolutional kernels, leading to an efficient and effective network. Inspired by the super-resolution networks, we design the NeRV block, illustrated in Figure 2©, adopting PixelShuffle technique for upscaling method. Convolution and activation layers are also inserted to enhance the expressibilty. The detailed architecture can be found in the supplementary material.
网络体系结构。NeRV架构如图2(b)所示。NeRV将嵌入的时间作为输入,并输出相应的RGB帧。利用MLPs直接输出帧的所有像素值可能会导致巨大的参数,特别是当图像分辨率很大时。因此,我们按照MLP层堆叠多个NeRV块,使不同位置的像素可以共享卷积核,从而形成一个高效有效的网络。受超分辨率网络的启发,我们设计了NeRV块,如图2©所示,采用PixelShuffle技术进行升级。还插入了卷积层和激活层,以增强可表达性。详细的架构可以在补充材料中找到。
Loss Objective. For NeRV, we adopt combination of L1 and SSIM loss as our loss function for network optimization, which calculates the loss over all pixel locations of the predicted image and the ground-truth image as following
损失函数。对于NeRV,我们采用L1和SSIM损耗的组合作为网络优化的损耗函数,计算出预测图像和ground-truth图像在所有像素位置上的损耗如下
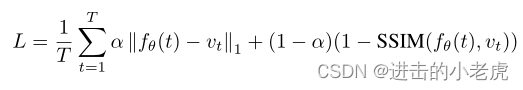
where T is the frame number, fθ(t) ∈ R^(H×W×3) the NeRV prediction, vt ∈R^(H×W×3) the frame ground truth, α is hyper-parameter to balance the weight for each loss component.
其中T是帧数,fθ(T)∈ R^(H×W×3)是NeRV预测,vt∈ R^(H×W×3)是帧地面真值,α是超参数,以平衡每个损耗分量的权重。

3.2 Model Compression
In this section, we briefly revisit model compression techniques used for video compression with NeRV. Our model compression composes of four standard sequential steps: video overfit, model pruning, weight quantization, and weight encoding as shown in Figure 3.
在本节中,我们将简要回顾NeRV视频压缩中使用的模型压缩技术。我们的模型压缩由四个标准的顺序步骤组成:视频过拟合、模型剪枝、权重量化和权重编码,如图3所示。
Model Pruning. Given a neural network fit on a video, we use global unstructured pruning to reduce the model size first. Based on the magnitude of weight values, we set weights below a threshold as zero,
模型修剪。给定一个神经网络拟合到一个视频上,我们首先使用全局非结构化剪枝来减小模型大小。根据权重值的大小,我们将低于阈值的权重设置为零,
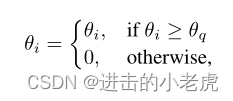
where θq is the q percentile value for all parameters in θ. As a normal practice, we fine-tune the model to regain the representation, after the pruning operation.
θq是θ中所有参数的q百分位数。作为一种正常的做法,我们微调模型,以恢复表示后,剪枝操作。
Model Quantization. After model pruning, we apply model quantization to all network parameters. Note that different from many recent works that utilize quantization during training, NeRV is only quantized post-hoc (after the training process). Given a parameter tensor µ
量化模型。在模型剪枝之后,我们对所有的网络参数进行模型量化。请注意,与最近许多在训练过程中利用量化的工作不同,NeRV只在事后(训练过程之后)量化。给定一个参数张量µ
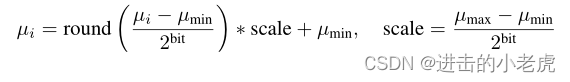
where ‘round’ is rounding value to the closest integer, ‘bit’ the bit length for quantized model, µmax and µmin the max and min value for the parameter tensor µ, ‘scale’ the scaling factor. Through Equation 4, each parameter can be mapped to a ‘bit’ length value. The overhead to store ‘scale’ and µmin can be ignored given the large parameter number of µ, e.g., they account for only 0.005% in a small 3 × 3 Conv with 64 input channels and 64 output channels (37k parameters in total).
其中,round为舍入到最接近的整数,bit为量化模型的比特长度,µmax和µmin为参数张量的最大和最小值,scale为缩放因子。通过公式4,每个参数可以映射到一个“位”长度值。存储“scale”和存储µmin的开销可以忽略,因为参数数量很大,例如在64个输入通道和64个输出通道的小的3 × 3 Conv(总共37k个参数)中,它们仅占0.005%。
Entropy Encoding. Finally, we use entropy encoding to further compress the model size. By taking advantage of character frequency, entropy encoding can represent the data with a more efficient codec. Specifically, ploy Huffman Coding after model quantization. Since Huffman Coding is lossless, it is guaranteed that a decent compression can be achieved without any impact on the reconstruction quality. Empirically, this further reduces the model size by around 10%.
熵编码。最后,我们使用熵编码进一步压缩模型大小。通过利用字符频率,熵编码可以以一种更高效的编解码器来表示数据。具体地说,在模型量化后运用霍夫曼编码。由于Huffman编码是无损的,它可以保证在不影响重构质量的情况下实现良好的压缩。根据经验,这进一步减少了大约10%的模型大小。
4 Experiments
4.1 Datasets and Implementation Details
We perform experiments on “Big Buck Bunny” sequence from scikit-video to compare our NeRV with pixel-wise implicit representations, which has 132 frames of 720×1080 resolution. To compare with state-of-the-arts methods on video compression task, we do experiments on the widely used UVG, consisting of 7 videos and 3900 frames with 1920×1080 in total.
我们对scikit-video中的“大巴克兔子”序列进行实验,以比较我们的NeRV与像素级隐式表示,它有132帧的分辨率为720×1080。为了与最先进的视频压缩方法进行比较,我们在广泛使用的UVG上进行了实验,UVG由7个视频和3900帧组成,总共1920×1080。
In our experiments, we train the network using Adam optimizer with learning rate of 5e-4. For ablation study on UVG, we use cosine annealing learning rate schedule, batchsize of 1, training epochs of 150, and warmup epochs of 30 unless otherwise denoted. When compare with state-of-the-arts, we run the model for 1500 epochs, with batchsize of 6. For experiments on “Big Buck Bunny”, we train NeRV for 1200 epochs unless otherwise denoted. For fine-tune process after pruning, we use 50 epochs for both UVG and “Big Buck Bunny”.
在我们的实验中,我们使用学习率为5e-4的Adam优化器来训练网络。对于UVG的消融研究,我们使用余弦退火学习速率计划,批大小为1,训练期为150,预热期为30,除非另有说明。当与先进技术相比较时,我们运行了1500个时代的模型,批量为6个。对于“大巴克兔”的实验,我们训练NeRV 1200个epoch,除非另有说明。对于修剪后的微调过程,我们对UVG和“Big Buck Bunny”都使用了50个epoch。
For NeRV architecture, there are 5 NeRV blocks, with up-scale factor 5, 3, 2, 2, 2 respectively for 1080p videos, and 5, 2, 2, 2, 2 respectively for 720p videos. By changing the hidden dimension of MLP and channel dimension of NeRV blocks, we can build NeRV model with different sizes. For input embedding in Equation 1, we use b = 1.25 and l = 80 as our default setting. For loss objective in Equation 2, α is set to 0.7. We evaluate the video quality with two metrics: PSNR and MS-SSIM. Bits-per-pixel (BPP) is adopted to indicate the compression ratio. We implement our model in PyTorch and train it in full precision (FP32). All experiments are run with NVIDIA RTX2080ti. Please refer to the supplementary material for more experimental details, results, and visualizations.
NeRV架构有5个NeRV块,1080p视频的上标因子分别为5、3、2、2、2,720p视频的上标因子分别为5、2、2、2、2。通过改变MLP的隐藏维数和NeRV块的通道维数,可以建立不同大小的NeRV模型。对于方程1中的输入嵌入,我们使用b = 1.25和l = 80作为默认设置。对于公式2中的损失目标,α设为0.7。我们用两个指标来评估视频质量:PSNR和MS-SSIM。采用bit -per-pixel (BPP)表示压缩比。我们在PyTorch中实现我们的模型,并对其进行全精度训练(FP32)。所有实验都使用NVIDIA RTX2080ti运行。请参阅补充材料,以获得更多的实验细节、结果和可视化。
4.2 Main Results
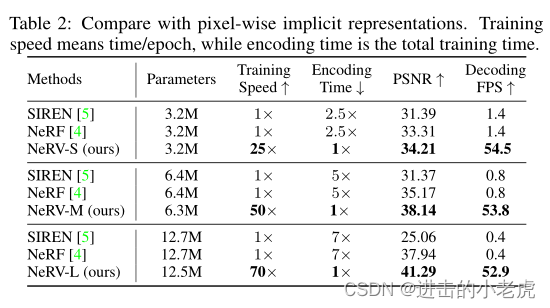
We compare NeRV with pixel-wise implicit representations on ’Big Buck Bunny’ video. We take SIREN [5] and NeRF as the baseline, where SIREN takes the original pixel coordinates as input and uses sine activations, while NeRF adds one positional embedding layer to encode the pixel coordinates and uses ReLU activations. Both SIREN and FFN use a 3-layer perceptron and we change the hidden dimension to build model of different sizes. For fair comparison, we train SIREN and FFN for 120 epochs to make encoding time comparable. And we change the filter width to build NeRV model of comparable sizes, named as NeRV-S, NeRV-M, and NeRV-L. In Table 2, NeRV outperforms them greatly in both encoding speed, decoding quality, and decoding speed. Note that NeRV can improve the training speed by 25× to 70×, and speedup the decoding FPS by 38× to 132×. We also conduct experiments with different training epochs in Table 3, which clearly shows that longer training time can lead to much better overfit results of the video and we notice that the final performances have not saturated as long as it trains for more epochs.
我们将NeRV与《大巴克兔》视频中的像素级隐式表示相比较。我们以SIREN[5]和NeRF为基线,其中SIREN以原始像素坐标为输入,使用正弦激活,而NeRF增加了一个位置嵌入层对像素坐标进行编码,使用ReLU激活。SIREN和FFN都使用了3层感知器,我们改变隐藏维度来构建不同大小的模型。为了进行公平比较,我们对SIREN和FFN进行了120个epoch的训练,以使编码时间具有可比性。我们改变滤波器的宽度,建立类似大小的NeRV模型,命名为NeRV-S, NeRV-M, and NeRV-L。在表2中,NeRV在编码速度、解码质量和解码速度方面都大大优于它们。需要注意的是,NeRV可以将训练速度提高25 ~ 70×,解码FPS速度提高38× ~ 132×。我们还在表3中对不同的训练时段进行了实验,实验清楚地表明,训练时间越长,视频的过拟合效果就越好,我们注意到,只要训练的时段越多,最终的表现就没有饱和。
4.3 Video Compression
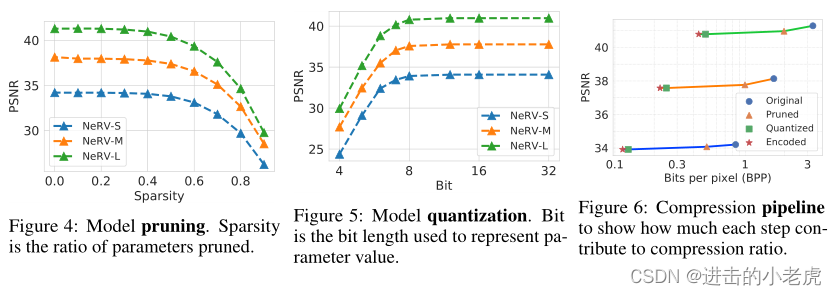
Compression ablation. We first conduct ablation study on video “Big Buck Bunny”. Figure 4 shows the results of different pruning ratios, where model of 40% sparsity still reach comparable performance with the full model. As for model quantization step in Figure 5, a 8-bit model still remains the video quality compared to the original one (32-bit). Figure 6 shows the full compression pipeline with NeRV. The compression performance is quite robust to NeRV models of different sizes, and each step shows consistent contribution to our final results. Please note that we only explore these three common compression techniques here, and we believe that other well-established and cutting edge model compression algorithm can be applied to further improve the final performances of video compression task, which is left for future research.
压缩消融。我们首先在视频“大巴克兔”上进行消融研究。图4显示了不同修剪率下的结果,稀疏度为40%的模型仍然可以达到与完整模型相当的性能。在图5的模型量化步骤中,8位模型相对于原模型(32位)仍然保持视频质量。图6显示了NeRV的完整压缩管道。压缩性能对于不同大小的NeRV模型是相当稳健的,每一步都显示出对我们最终结果的一致贡献。请注意,我们这里只探讨这三种常见的压缩技术,我们相信其他成熟的、前沿的模型压缩算法可以进一步提高视频压缩任务的最终性能,这有待于今后的研究。
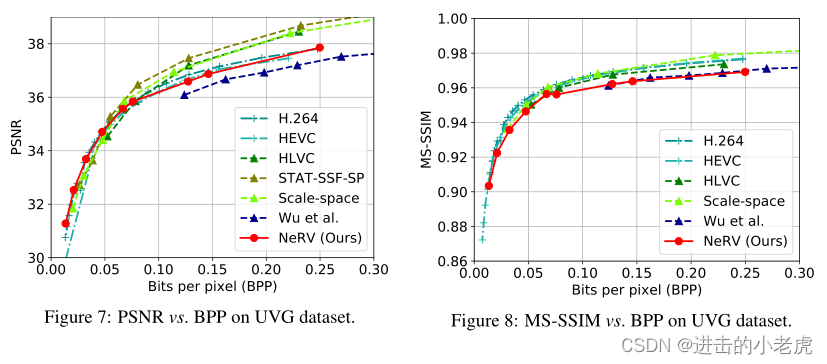
Compare with state-of-the-arts methods. We then compare with state-of-the-arts methods on UVG dataset. First, we concatenate 7 videos into one single video along the time dimension and train NeRV on all the frames from different videos, which we found to be more beneficial than training a single model for each video. After training the network, we apply model pruning, quantization, and weight encoding as described in Section3.2. Figure 7 and Figure 8 show the rate-distortion curves. We compare with H.264, HEVC, STA T-SSF-SP, HL VC, Scale-space, and Wu et al. H.264 and HEVC are performed with medium preset mode. As the first image-wise neural representation, NeRV generally achieves comparable performance with traditional video compression techniques and other learning-based video compression approaches. It is worth noting that when BPP is small, NeRV can match the performance of the state-of-the-art method, showing its great potential in high-rate video compression. When BPP becomes large, the performance gap is mostly because of the lack of full training due to GPU resources limitations. As shown in Table 3, the decoding video quality keeps increasing when the training epochs are longer. Figure 9 shows visualizations for decoding frames. At similar memory budget, NeRV shows image details with better quality.
与最先进的方法比较。然后,我们在UVG数据集上与最先进的方法进行比较。首先,我们沿着时间维度将7个视频拼接成一个单一的视频,并在不同视频的所有帧上训练NeRV,我们发现这比为每个视频训练一个单一的模型更有益。训练完网络后,我们应用模型剪接、量化和权重编码,如第3.2节所述。图7和图8显示了速率失真曲线。我们与H.264、HEVC、STA T-SSF-SP、HL VC、Scale-space和Wu等进行了比较。H.264和HEVC采用中等预设模式。作为第一个基于图像的神经表示,NeRV通常可以达到与传统视频压缩技术和其他基于学习的视频压缩方法相当的性能。值得注意的是,当BPP较小时,NeRV的性能可以与最先进的方法相媲美,显示出其在高速视频压缩方面的巨大潜力。当BPP变大时,性能差距主要是由于GPU资源的限制,没有充分的训练。从表3可以看出,随着训练周期的增加,解码视频质量不断提高。图9显示了解码帧的可视化。在相同的内存预算下,NeRV显示的图像细节质量更好。

Decoding time. We compare with other methods for decoding time under a similar memory budget. Note that HEVC is run on CPU, while all other learning-based methods are run on a single GPU, including our NeRV. We speedup NeRV by running it in half precision (FP16). Due to the simple decoding process (feedforward operation), NeRV shows great advantage, even for carefully-optimized H.264. And lots of speepup can be expected by running quantizaed model on special hardware. All the other video compression methods have two types of frames: key and interval frames. Key frame can be reconstructed by its encoded feature only while the interval frame reconstruction is also based on the reconstructed key frames. Since most video frames are interval frames, their decoding needs to be done in a sequential manner after the reconstruction of the respective key frames. On the contrary, our NeRV can output frames at any random time index independently, thus making parallel decoding much simpler. This can be viewed as a distinct advantage over other methods.
解码时间。在相似的内存预算下,我们与其他方法比较了解码时间。注意HEVC是在CPU上运行的,而所有其他基于学习的方法都运行在单个GPU上,包括我们的NeRV。我们通过半精度运行来加速NeRV (FP16)。由于解码过程简单(前馈操作),即使在经过精心优化的H.264中,NeRV也显示出了巨大的优势。通过在特殊硬件上运行量化模型,可以获得较高的速度。所有其他视频压缩方法都有两种类型的帧:关键帧和间隔帧。关键帧只能根据其编码特征进行重构,而间隔帧重构也是基于重构后的关键帧。由于大多数视频帧都是间隔帧,解码需要在重构出相应的关键帧后,按顺序进行。相反,我们的NeRV可以独立输出任意随机时间指数的帧,从而使并行解码更加简单。这可以被视为与其他方法相比的明显优势。
4.4 Video Denoising
We apply several common noise patterns on the original video and train the model on the perturbed ones. During training, no masks or noise locations are provided to the model, i.e., the target of the model is the noisy frames while the model has no extra signal of whether the input is noisy or not. Surprisingly, our model tries to avoid the influence of the noise and regularizes them implicitly with little harm to the compression task simultaneously, which can serve well for most partially distorted videos in practice.
我们在原始视频中应用几种常见的噪声模式,并在受扰动的图像上训练模型。在训练过程中,没有给模型提供掩模或噪声位置,即模型的目标是有噪声的帧,模型没有额外的信号来判断输入是否有噪声。令人惊讶的是,我们的模型试图避免噪声的影响,并隐式正则化它们,同时对压缩任务的危害很小,这可以很好地服务于实践中的大多数部分失真视频。
The results are compared with some standard denoising methods including Gaussian, uniform, and median filtering. These can be viewed as denoising upper bound for any additional compression process. As listed in Table 5, the PSNR of NeRV output is usually much higher than the noisy frames although it’s trained on the noisy target in a fully supervised manner, and has reached an acceptable level for general denoising purpose. Specifically, median filtering has the best performance among the traditional denoising techniques, while NeRV outperforms it in most cases or is at least comparable without any extra denoising design in both architecture design and training strategy.
结果与一些标准的去噪方法,包括高斯、均匀和中值滤波进行了比较。这些可以看作是对任何附加压缩过程的去噪上限。如表5所示,虽然以完全监督的方式对噪声目标进行训练,但NeRV输出的PSNR通常远高于噪声帧,并达到了一般去噪的可接受水平。具体来说,中值滤波在传统去噪技术中表现最好,而NeRV在大多数情况下都优于中值滤波,或者至少在没有任何额外的去噪设计的架构设计和训练策略中可以与之媲美。
We also compare NeRV with another neural-network-based denoising method, Deep Image Prior (DIP). Although its main target is image denoising, NeRV outperforms it in both qualitative and quantitative metrics, demonstrated in Figure 10. The main difference between them is that denoising of DIP only comes form architecture prior, while the denoising ability of NeRV comes from both architecture prior and data prior. DIP emphasizes that its image prior is only captured by the network structure of Convolution operations because it only feeds on a single image. But the training data of NeRV contain many video frames, sharing lots of visual contents and consistences. As a result, image prior is captured by both the network structure and the training data statistics for NeRV. DIP relies significantly on a good early stopping strategy to prevent it from overfitting to the noise. Without the noise prior, it has to be used with fixed iterations settings, which is not easy to generalize to any random kind of noises as mentioned above. By contrast, NeRV is able to handle this naturally by keeping training because the full set of consecutive video frames provides a strong regularization on image content over noise.
我们还比较了NeRV和另一种基于神经网络的去噪方法,深度图像先验(DIP)。虽然它的主要目标是图像去噪,但NeRV在定性和定量指标上都优于它,如图10所示。两者的主要区别是DIP的去噪只来自于架构先验,而NeRV的去噪能力同时来自于架构先验和数据先验。DIP强调,它的图像先验只被卷积运算的网络结构捕获,因为它只提供单一的图像。而神经网络的训练数据包含较多的视频帧,具有较多的视觉内容和一致性。通过神经网络的网络结构和训练数据统计,获得了图像的先验信息。DIP很大程度上依赖于一个良好的早期停止策略,以防止它与噪声过拟合。没有噪声先验,它必须使用固定的迭代设置,这是不容易推广到任何随机类型的噪声如上所述。相比之下,NeRV能够通过持续训练自然地处理这一问题,因为完整的连续视频帧集在噪声之上提供了对图像内容的强正则化。

4.5 Ablation Studies
Finally, we provide ablation studies on the UVG dataset. PSNR and MS-SSIM are adopted for evaluation of the reconstructed videos.
最后,我们提供了在UVG数据集上的消融研究。采用PSNR和MS-SSIM对重建视频进行评价。
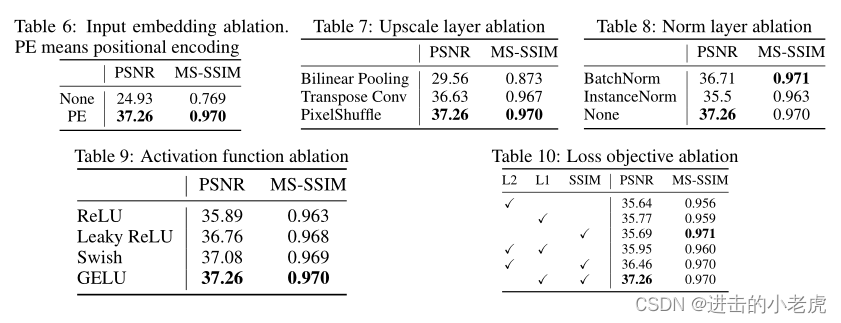
Input embedding. In Table 6, PE means positional encoding as in Equation 1, which greatly improves the baseline, None means taking the frame index as input directly. Similar findings can be found in [4], without any input embedding, the model can not learn high-frequency information, resulting in much lower performance.
输入嵌入。在表6中,PE表示如公式1所示的位置编码,极大地改善了基线,None表示直接以帧索引作为输入。在[4]中也有类似的发现,没有任何的输入嵌入,模型无法学习高频信息,导致性能大大降低。
Upscale layer . In Table 7, we show results of three different upscale methods. i.e., Bilinear Pooling, Transpose Convolution, and PixelShuffle [46]. With similar model sizes, PixelShuffle shows best results. Please note that although Transpose convolution [60] reach comparable results, it greatly slowdown the training speed compared to the PixelShuffle.
高档层。在表7中,我们展示了三种不同的高档方法的结果。即双线性池,转置卷积,PixelShuffle[46]。在相似的模型尺寸下,PixelShuffle显示出最好的结果。请注意,虽然转置卷积[60]达到了可比的结果,但与PixelShuffle相比,它大大降低了训练速度。
Normalization layer . In Table 8, we apply common normalization layers in NeRV block. The default setup, without normalization layer, reaches the best performance and runs slightly faster. We hypothesize that the normalization layer reduces the over-fitting capability of the neural network, which is contradictory to our training objective.
归一化层。在表8中,我们在NeRV块中应用了通用的规范化层。默认设置(没有标准化层)可以达到最佳性能,运行速度也稍微快一些。我们假设归一化层降低了神经网络的过拟合能力,这与我们的训练目标是矛盾的。
Activation layer . Table 9 shows results for common activation layers. The GELU [61] activation function achieve the highest performances, which is adopted as our default design.
激活层。表9显示了通用激活层的结果。GELU[61]激活函数的性能最高,我们采用它作为默认设计。
Loss objective. We show loss objective ablation in Table 10. We shows performance results of different combinations of L2, L1, and SSIM loss. Although adopting SSIM alone can produce the highest MS-SSIM score, but the combination of L1 loss and SSIM loss can achieve the best trade-off between the PSNR performance and MS-SSIM score.
损失的目标。表10显示客观消融损失。我们展示了L2、L1和SSIM损耗不同组合的性能结果。虽然单独采用SSIM可以得到最高的MS-SSIM分数,但是L1损耗和SSIM损耗的结合可以达到PSNR性能和MS-SSIM分数之间的最佳权衡。
5 Discussion
Conclusion. In this work, we present a novel neural representation for videos, NeRV, which encodes videos into neural networks. Our key sight is that by directly training a neural network with video frame index and output corresponding RGB image, we can use the weights of the model to represent the videos, which is totally different from conventional representations that treat videos as consecutive frame sequences. With such a representation, we show that by simply applying general model compression techniques, NeRV can match the performances of traditional video compression approaches for the video compression task, without the need to design a long and complex pipeline. We also show that NeRV can outperform standard denoising methods. We hope that this paper can inspire further research works to design novel class of methods for video representations.
结论。在这项工作中,我们提出了一种新的视频神经表示,NeRV,它将视频编码为神经网络。我们的重点是通过视频帧索引直接训练神经网络,输出相应的RGB图像,我们可以使用模型的权值来表示视频,这与传统的将视频视为连续的帧序列的表示完全不同。通过这样的表示,我们表明,通过简单地应用一般的模型压缩技术,NeRV可以在视频压缩任务中媲美传统视频压缩方法的性能,而不需要设计一个长而复杂的管道。我们还表明,NeRV可以优于标准的去噪方法。我们希望本文能对进一步的研究工作有所启发,从而设计出一类新的视频表示方法。
Limitations and Future Work. There are some limitations with the proposed NeRV. First, to achieve the comparable PSNR and MS-SSIM performances, the training time of our proposed approach is longer than the encoding time of traditional video compression methods. Second, the architecture design of NeRV is still not optimal yet, we believe more exploration on the neural architecture design can achieve higher performances. Finally, more advanced and cutting the edge model compression methods can be applied to NeRV and obtain higher compression ratios.
局限性和未来的工作。拟议的NeRV有一些限制。首先,为了达到相似的PSNR和MS-SSIM性能,我们提出的方法的训练时间比传统视频压缩方法的编码时间更长。其次,神经网络的结构设计还不是最优的,我们相信对神经网络结构设计进行更多的探索可以获得更高的性能。最后,更先进和前沿的模型压缩方法可以应用于神经网络,获得更高的压缩比。
Acknowledgement. This project was partially funded by the DARPA SAIL-ON (W911NF2020009) program, an independent grant from Facebook AI, and Amazon Research Award to AS.
确认。该项目由美国国防部高级研究计划局(DARPA)的SAIL-ON (W911NF2020009)项目提供部分资金,该项目是Facebook人工智能的一项独立拨款,亚马逊研究奖也颁发给了AS。















 3266
3266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









