







数据集简介
介绍两种深度学习极其经典的数据集,每一个深耕深度学生的“玩家”都一定有所耳闻,但是我们往往深耕神经网络的算法原理,前向传播与反向传播,那么这些优秀的数据集是如何集成出来,又如何被读取的呢,知道菜的味道,却不闻饭香太不公平了吧,数据集制作也是一大学问,已经封脚,今天就来会会这被忽略的数据集

Mnist

出门右转
放个图,以免此块太空虚,简单来说就是一个“多人运动”,多人手写阿拉伯0~10的数据集,里面包含图片与标签,详情点击这里【Tensorflow 笔记 Ⅳ——mnist手写数字识别】瞧一波,不亏的,当然强中强,归官网,猛戳这里 THE MNIST DATABASE of handwritten digits
Fashion-Mnist
名如其集,肯定要比 Mnist Fashion 一些,多达几万件的衣服裤子,能不 Fashion 都难,具体的数据集描述与其他信息参见 Fashion-MNIST,这里多有摘抄。【哎越来越懒了,毕竟这种介绍的东西不是我们的心头菜┗|`O′|┛ 嗷~~】

Fashion-MNIST是一个替代MNIST手写数字集的图像数据集。 它是由Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自10种类别的共7万个不同商品的正面图片。Fashion-MNIST的大小、格式和训练集/测试集划分与原始的MNIST完全一致。60000/10000的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
这个数据集的样子大致如上图,embeding 动图在此

数据集制作需求来源
经典的MNIST数据集包含了大量的手写数字。十几年来,来自机器学习、机器视觉、人工智能、深度学习领域的研究员们把这个数据集作为衡量算法的基准之一。你会在很多的会议,期刊的论文中发现这个数据集的身影。实际上,MNIST数据集已经成为算法作者的必测的数据集之一。有人曾调侃道:“如果一个算法在MNIST不work, 那么它就根本没法用;而如果它在MNIST上work, 它在其他数据上也可能不work!”
Fashion-MNIST的目的是要成为MNIST数据集的一个直接替代品。作为算法作者,你不需要修改任何的代码,就可以直接使用这个数据集。Fashion-MNIST的图片大小,训练、测试样本数及类别数与经典MNIST完全相同。
写给专业的机器学习研究者
我们是认真的。取代MNIST数据集的原因由如下几个:
- MNIST太简单了。 很多深度学习算法在测试集上的准确率已经达到99.6%!不妨看看我们基于scikit-learn上对经典机器学习算法的评测 和这段代码: “Most pairs of MNIST digits can be distinguished pretty well by just one pixel”(翻译:大多数MNIST只需要一个像素就可以区分开!)
- MNIST被用烂了。 参考:“Ian Goodfellow wants people to move away from mnist”(翻译:Ian Goodfellow希望人们不要再用MNIST了。)
- MNIST数字识别的任务不代表现代机器学习。 参考:“François Cholle: Ideas on MNIST do not transfer to real CV” (翻译:在MNIST上看似有效的想法没法迁移到真正的机器视觉问题上。)
获取数据
很多的机器学习库已经内置了Fashion-MNIST数据或接口,方便你直接使用。
你可以使用以下链接下载这个数据集。Fashion-MNIST的数据集的存储方式和命名与经典MNIST数据集完全一致。
| 名称 | 描述 | 样本数量 | 文件大小 | 链接 | MD5校验和 |
|---|---|---|---|---|---|
train-images-idx3-ubyte.gz | 训练集的图像 | 60,000 | 26 MBytes | 下载 | 8d4fb7e6c68d591d4c3dfef9ec88bf0d |
train-labels-idx1-ubyte.gz | 训练集的类别标签 | 60,000 | 29 KBytes | 下载 | 25c81989df183df01b3e8a0aad5dffbe |
t10k-images-idx3-ubyte.gz | 测试集的图像 | 10,000 | 4.3 MBytes | 下载 | bef4ecab320f06d8554ea6380940ec79 |
t10k-labels-idx1-ubyte.gz | 测试集的类别标签 | 10,000 | 5.1 KBytes | 下载 | bb300cfdad3c16e7a12a480ee83cd310 |
或者,你可以直接克隆这个代码库。数据集就放在data/fashion下。这个代码库还包含了一些用于评测和可视化的脚本。
git clone git@github.com:zalandoresearch/fashion-mnist.git
类别标注
每个训练和测试样本都按照以下类别进行了标注:
| 标注编号 | 描述 |
|---|---|
| 0 | T-shirt/top(T恤) |
| 1 | Trouser(裤子) |
| 2 | Pullover(套衫) |
| 3 | Dress(裙子) |
| 4 | Coat(外套) |
| 5 | Sandal(凉鞋) |
| 6 | Shirt(汗衫) |
| 7 | Sneaker(运动鞋) |
| 8 | Bag(包) |
| 9 | Ankle boot(踝靴) |
读取原理
从上面给的 Mnist 官网地址进入,这里的信息都从官网地址所获取而来
Mnist 数据集与 Fashion-Mnist 数据集的命名规范,格式,压缩类型等等,基本除了大小不一样,内部存储的数据不同,其它基本是一样的,包括内存地址中一些关键数据的相对地址都是相同的,所以它们两个数据集的读取方式基本一致【简直完全一致好不好】,所以我们可以从 mnist 数据集读取原理来读取 fashion-mnist 数据集

原理获取
一共有四个文件
train-images-idx3-ubyte: training set images
train-labels-idx1-ubyte: training set labels
t10k-images-idx3-ubyte: test set images
t10k-labels-idx1-ubyte: test set labels
训练集 60000,测试集 10000
官网对这 4 个文件列举了 如下信息,目的就是说明如何读取这些数据
TRAINING SET LABEL FILE (train-labels-idx1-ubyte)
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| … | … | … | … |
| xxxx | unsigned byte | ?? | label |
TRAINING SET IMAGE FILE (train-images-idx3-ubyte)
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| … | … | … | … |
| xxxx | unsigned byte | ?? | pixel |
TEST SET LABEL FILE (t10k-labels-idx1-ubyte)
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 10000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| … | … | … | … |
| xxxx | unsigned byte | ?? | label |
TRAINING SET IMAGE FILE (train-images-idx3-ubyte)
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 10000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| … | … | … | … |
| xxxx | unsigned byte | ?? | pixel |
四个表格中的 [offset] 就是数据的偏移量,我们发现图像数据与标签数据的 magic number 分别是 0x00000801 与 0x00000803,译成十进制就是 2049 与 2051,并且在 [offset] 的数据可以发现,图像数据与标签数据存储的位置分别是 0016 与 0008【例如对于训练的图像数据 [offset]=0004 的位置存储为数据量即 60000 张图】,因此 2049,2051,8,16就成了读取数据的关键,在代码中我们将应用 2049 与 2051 作为读取判断的先决条件,从 8,16 的 [offset] 处读取数据
最后官网还有一段对魔法函数的说明:
| English | Chinese |
|---|---|
| The magic number is an integer (MSB first). The first 2 bytes are always 0. The third byte codes the type of the data: 0x08: unsigned byte 0x09: signed byte 0x0B: short (2 bytes) 0x0C: int (4 bytes) 0x0D: float (4 bytes) 0x0E: double (8 bytes) | magic number是整数(MSB在前)。前2个字节始终为0。 第三个字节编码数据的类型: 0x08:无符号字节 0x09:有符号字节 0x0B:short 类型(2个字节) 0x0C:整型 int(4个字节) 0x0D:浮点型 float(4个字节) 0x0E:双精度 double 型(8个字节) |
gzip使用
由于压缩格式为 .gz 格式,所以我们需要使用 gzip 来管理压缩包,因此我们需要解压文件,再从解压的文件中获取偏移量 [offset],魔法数字 magic number 来获取数据。gzip示例如下:
demo 内容为 how to use gzip,是一个去掉后缀的文本文件,当然加上后缀也无所谓
压缩
import gzip
with open('gzip_demo/demo', 'rb') as plain_file:
with gzip.open('gzip_demo/demo.gz', 'wb') as zip_file:
zip_file.writelines(plain_file)
解压
with gzip.open('gzip_demo/demo.gz') as g:
print('读取 gz 文件:', g.read().decode('utf-8'))
字节存储顺序
字节存放顺序分为大尾存储(big endian)与小尾存储(little endian),定义如下:
| 大尾存储 | 小尾存储 |
|---|---|
| 数据的高字节存放在低地址就是大尾 | 数据的高字节存放在高地址的就是小尾 |
| 大尾存放时: 偏移地址 存放内容 0x0000 0x12 0x0001 0x34 | 小尾存放: 偏移地址 存放内容 0x0000 0x34 0x0001 0x12 |
在 numpy 中由此函数 numpy.dtype.newbyteorder 可以管理存储顺序,官网说明参见这里【English Version,中文版本】
•'S'-将数据类型从当前端切换到另一端
•'<','L'-小尾数
•“>”,“B”-大尾数法
•'=','N'-本机顺序
•'','I'-忽略(不更改字节顺序)
从上面四个 gz 文件的表格可知 [offset] 越小,存储的 [type] 越大,所以采用大尾存放机制,所以在文件读取代码中,我们将采取 np.dtype(np.uint32).newbyteorder('>') 进行控制
源码开干
文件列表说明
在父目录 dataset_download 文件夹下存在如下两个文件加,里面分别存放 mnist 数据集 与 fashion-mnist 数据集

模块导入
import tensorflow as tf
import gzip
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
import os
tf.__version__
'1.15.2'
gzip 使用
with open('gzip_demo/demo', 'rb') as plain_file:
with gzip.open('gzip_demo/demo.gz', 'wb') as zip_file:
zip_file.writelines(plain_file)
with gzip.open('gzip_demo/demo.gz') as g:
print('读取 gz 文件:', g.read().decode('utf-8'))
读取 gz 文件: how to use gzip
数据读取方式一
官网读取方式
mnist = input_data.read_data_sets('./dataset_download/mnist/', one_hot=False)
print('train images shape:', mnist.train.images.shape,
'\ntrain labels shape:', mnist.train.labels.shape)
plt.imshow(mnist.train.images[0].reshape(28, 28), cmap='binary')
plt.title(str(mnist.train.labels[0]))
plt.show()
Extracting ./dataset_download/mnist/train-images-idx3-ubyte.gz
Extracting ./dataset_download/mnist/train-labels-idx1-ubyte.gz
Extracting ./dataset_download/mnist/t10k-images-idx3-ubyte.gz
Extracting ./dataset_download/mnist/t10k-labels-idx1-ubyte.gz
train images shape: (55000, 784)
train labels shape: (55000,)

可以利用 fake_data=True 来 返回空列表数据
mnist = input_data.read_data_sets('./dataset_download/mnist/', fake_data=True, one_hot=False)
print('train images:', mnist.train.images,
'\ntrain labels:', mnist.train.labels,
'\nvalidation images:', mnist.validation.images,
'\nvalidation labels:', mnist.validation.labels,
'\ntest images:', mnist.test.images,
'\ntest labels:', mnist.test.labels)
train images: []
train labels: []
validation images: []
validation labels: []
test images: []
test labels: []
数据获取方式二
定义大尾(big endian)存放方式
def read32(bytestream):
dt = np.dtype(np.uint32).newbyteorder('>')
return np.frombuffer(bytestream.read(4), dtype=dt)[0]
将 magic number=2051 作为图像文件在读取时的判断条件,读取的数据通过 data = np.frombuffer(buf, dtype=np.uint8) 转换成 numpy 数组,这是只有一个维度的数据,通过 data = data.reshape(num_images, rows, cols, 1) 获取 28×28 形式的数据
def extract_images(f):
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = read32(bytestream)
if magic != 2051:
raise ValueError('Invalid magic number %d in MNIST image file: %s' %
(magic, f.name))
num_images = read32(bytestream)
rows = read32(bytestream)
cols = read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = np.frombuffer(buf, dtype=np.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
one_hot 编码
dense_to_one_hot() 是官网使用的独热编码函数,one_hot() 则是重新定义的独热编码函数
def dense_to_one_hot(labels_dense, num_classes):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
from sklearn.preprocessing import OneHotEncoder
def one_hot(labels):
encoder = OneHotEncoder(sparse=False)
one_hot = [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]]
encoder.fit(one_hot)
labels_reshape = labels.reshape(-1, 1)
labels_onehot = encoder.transform(labels_reshape)
return labels_onehot
将 magic number=2049 作为标签文件在读取时的判断条件
这里在 if not_hot: 判定中使用 one_hot() 函数代替 dense_to_one_hot()
def extract_labels(f, one_hot=False):
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = read32(bytestream)
if magic != 2049:
raise ValueError('Invalid magic number %d in MNIST label file: %s' %
(magic, f.name))
num_items = read32(bytestream)
buf = bytestream.read(num_items)
labels = np.frombuffer(buf, dtype=np.uint8)
if one_hot:
return one_hot(labels)
return labels
读取单个图像文件与单个标签文件
也可以不导入 gfile 包,将下面的 with 结构如下调换也能运转
with open(local_file, 'rb') as f:
train_images = extract_images(f)
from tensorflow.python.framework import dtypes
from tensorflow.python.platform import gfile
def read_data_sets(one_hot=False,
dtype=dtypes.float32,
reshape=True,
seed=None):
local_image_file = 'dataset_download/mnist/train-images-idx3-ubyte.gz'
with gfile.Open(local_image_file, 'rb') as f:
train_images = extract_images(f)
local_label_file = 'dataset_download/mnist/train-labels-idx1-ubyte.gz'
with gfile.Open(local_label_file, 'rb') as f:
train_labels = extract_labels(f)
return train_images, train_labels
train_images, train_labels = read_data_sets()
Extracting dataset_download/mnist/train-images-idx3-ubyte.gz
Extracting dataset_download/mnist/train-labels-idx1-ubyte.gz
plt.imshow(train_images[0].reshape(28, 28), cmap='gray')
plt.title(train_labels[0], fontsize=20)
plt.axis('off')
plt.show()
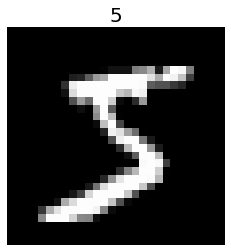
train_labels_onehot = one_hot(train_labels)
train_labels_onehot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])
train_labels_dense_to_one_hot = dense_to_one_hot(train_labels, 10)
train_labels_dense_to_one_hot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])
获取整个Mnist训练集、测试集与验证集
def get_dataset(one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000,
seed=None):
train_image_file = 'dataset_download/mnist/train-images-idx3-ubyte.gz'
with gfile.Open(train_image_file, 'rb') as f:
train_images = extract_images(f)
train_label_file = 'dataset_download/mnist/train-labels-idx1-ubyte.gz'
with gfile.Open(train_label_file, 'rb') as f:
train_labels = extract_labels(f)
test_image_file = 'dataset_download/mnist/t10k-images-idx3-ubyte.gz'
with gfile.Open(test_image_file, 'rb') as f:
test_images = extract_images(f)
test_label_file = 'dataset_download/mnist/t10k-labels-idx1-ubyte.gz'
with gfile.Open(test_label_file, 'rb') as f:
test_labels = extract_labels(f)
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
return (train_images, train_labels), (test_images, test_labels), (validation_images, validation_labels)
(train_images, train_labels), (test_images, test_labels), (validation_images, validation_labels) = get_dataset()
Extracting dataset_download/mnist/train-images-idx3-ubyte.gz
Extracting dataset_download/mnist/train-labels-idx1-ubyte.gz
Extracting dataset_download/mnist/t10k-images-idx3-ubyte.gz
Extracting dataset_download/mnist/t10k-labels-idx1-ubyte.gz
fig = plt.figure(figsize=(20, 5))
image_list = [train_images[0].reshape(28, 28),
test_images[0].reshape(28, 28),
validation_images[0].reshape(28, 28)]
label_list = [str(train_labels[0]),
str(test_labels[0]),
str(validation_labels[0])]
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.imshow(image_list[i], cmap='gray')
plt.title(label_list[i], fontsize=20)
plt.axis('off')
plt.show()

获取整个 Fashion-Mnist 训练集、测试集与验证集
def get_dataset(one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000,
seed=None):
train_image_file = 'dataset_download/fashion_mnist/train-images-idx3-ubyte.gz'
with gfile.Open(train_image_file, 'rb') as f:
train_images = extract_images(f)
train_label_file = 'dataset_download/fashion_mnist/train-labels-idx1-ubyte.gz'
with gfile.Open(train_label_file, 'rb') as f:
train_labels = extract_labels(f)
test_image_file = 'dataset_download/fashion_mnist/t10k-images-idx3-ubyte.gz'
with gfile.Open(test_image_file, 'rb') as f:
test_images = extract_images(f)
test_label_file = 'dataset_download/fashion_mnist/t10k-labels-idx1-ubyte.gz'
with gfile.Open(test_label_file, 'rb') as f:
test_labels = extract_labels(f)
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
return (train_images, train_labels), (test_images, test_labels), (validation_images, validation_labels)
(train_images, train_labels), (test_images, test_labels), (validation_images, validation_labels) = get_dataset()
Extracting dataset_download/fashion_mnist/train-images-idx3-ubyte.gz
Extracting dataset_download/fashion_mnist/train-labels-idx1-ubyte.gz
Extracting dataset_download/fashion_mnist/t10k-images-idx3-ubyte.gz
Extracting dataset_download/fashion_mnist/t10k-labels-idx1-ubyte.gz
| 标注编号 | 描述 |
|---|---|
| 0 | T-shirt/top(T恤) |
| 1 | Trouser(裤子) |
| 2 | Pullover(套衫) |
| 3 | Dress(裙子) |
| 4 | Coat(外套) |
| 5 | Sandal(凉鞋) |
| 6 | Shirt(汗衫) |
| 7 | Sneaker(运动鞋) |
| 8 | Bag(包) |
| 9 | Ankle boot(踝靴) |
class_dict = {0:'T-shirt', 1:'Trouser', 2:'Pullover', 3:'Dress', 4:'Coat',
5:'Sandal', 6:'Shirt', 7:'Sneaker', 8:'Bag', 9:'Ankle boot'}
fig = plt.figure(figsize=(20, 5))
image_list = [train_images[0].reshape(28, 28),
test_images[0].reshape(28, 28),
validation_images[0].reshape(28, 28)]
label_list = [train_labels[0],
test_labels[0],
validation_labels[0]]
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.imshow(image_list[i], cmap='gray')
plt.title(class_dict[label_list[i]], fontsize=20)
plt.axis('off')
plt.show()

数据获取方式三
本次直接将所有数据串在一起,为后期做 GAN 与 CGAN 做数据读取处理用,直接在函数内部将文件夹定位到 dataset_download,在定义解压函数中,并未使用 magic number 获取数据的方式,而是使用 head_size 即 [offset] 0008 与 0016 的方式获取
def extract_data(filename, num_data, head_size, data_size):
with gzip.open(filename) as bytestream:
bytestream.read(head_size)
buf = bytestream.read(data_size * num_data)
data = np.frombuffer(buf, dtype=np.uint8).astype(np.float)
return data
获取 mnist 图像数据,与上面相同,获取的数据只有一个维度,我们需要将其 reshape 成 28×28 的形式
dataset_name = 'mnist'
data_dir = os.path.join("./dataset_download", dataset_name)
train_images_data = extract_data(data_dir + '/train-images-idx3-ubyte.gz', 60000, 16, 28 * 28)
print('train_images_data shape:', train_images_data.shape)
train_images_data shape: (47040000,)
train_images = train_images_data.reshape(-1, 28, 28, 1)
print('train_images shape:', train_images.shape)
train_images shape: (60000, 28, 28, 1)
解析下方 load_data() 创建 one_hot 的方法,以 10 个类别为例,先创建一个暂存的零矩阵,在遍历修改零矩阵的值
a = np.array([5, 4, 8, 6, 3, 2, 4, 7, 8, 1])
a_one_hot = np.zeros((len(a), 10), dtype=float)
for i, label in enumerate(a):
a_one_hot[i, label] = 1.0
print('a:\n', a,
'\na_one_hot:', a_one_hot)
a:
[5 4 8 6 3 2 4 7 8 1]
a_one_hot: [[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
def load_data(dataset_name, onehot=False):
data_dir = os.path.join("./dataset_download", dataset_name)
data = extract_data(data_dir + '/train-images-idx3-ubyte.gz', 60000, 16, 28 * 28)
train_images = data.reshape((-1, 28, 28, 1))
data = extract_data(data_dir + '/train-labels-idx1-ubyte.gz', 60000, 8, 1)
train_labels = data.reshape((-1))
data = extract_data(data_dir + '/t10k-images-idx3-ubyte.gz', 10000, 16, 28 * 28)
test_images = data.reshape((-1, 28, 28, 1))
data = extract_data(data_dir + '/t10k-labels-idx1-ubyte.gz', 10000, 8, 1)
test_labels = data.reshape((-1))
train_images = np.asarray(train_images)
test_labels = np.asarray(test_labels)
X = np.concatenate((train_images, test_images), axis=0)
y = np.concatenate((train_labels, test_labels), axis=0).astype(np.int)
seed = 547
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(y)
if onehot== True:
y_vec = np.zeros((len(y), 10), dtype=np.float)
for i, label in enumerate(y):
y_vec[i, y[i]] = 1.0
return X, y_vec
return X, y
读取整个 Mnist 数据集
images, labels = load_data('mnist')
plt.imshow(images[520].reshape(28, 28), cmap='gray')
plt.title(str(labels[520]), fontsize=20)
plt.axis('off')
plt.show()
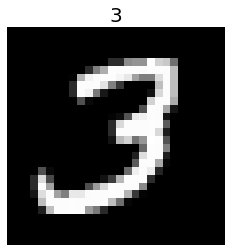
读取整个 Fashion-Mnist 数据集
class_dict = {0:'T-shirt', 1:'Trouser', 2:'Pullover', 3:'Dress', 4:'Coat',
5:'Sandal', 6:'Shirt', 7:'Sneaker', 8:'Bag', 9:'Ankle boot'}
images, labels = load_data('fashion_mnist')
plt.imshow(images[1314].reshape(28, 28), cmap='gray')
plt.title(class_dict[labels[1314]], fontsize=20)
plt.axis('off')
plt.show()
















 2380
2380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









