







使用scrapy框架下载图片
先介绍一下os模块:
import os即可
-
使用os.path.dirname (__ file__) 可以查看当前文件所在的目录,以如下目录为例:
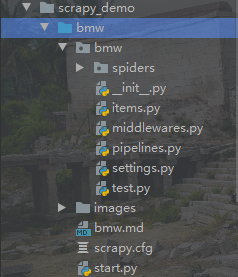
使用os.path.dirname(__ file__)得到的是第二个bmw(即蓝色框下面的那个)目录,假如我们想要在第一个bmw下面创建一个images文件夹,应该怎么做呢?
所以我们使用os.path.dirname(os.path.dirname(file))语句,如此得到的就是第二个bmw所在的目录了(也就是第一个bmw下)。 -
os.path.join语句可以将目录和想要创建的文件夹组成一个新的目录,如:os.path.join(os.path.dirname(os.path.dirname(file)), ‘images’)
这句话的作用就是将以后的文件保存在第一个bmw下的images文件夹中。
Images Pipeline

要想使用这个东西,先在item中设置两个item,分别是:
image_urls = scrapy.Field()
images = scrapy.Field()
然后再settings中设置:
ITEM_PIPELINES = {
# 'bmw.pipelines.BmwPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
注意,此时pipelines中的class BmwPipeline(默认创建的)不会再被执行
存储路径:
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
使用 Images Pipeline对汽车之家进行爬取
对原始程序进行上述配置之后,确实可以下载图片,但缺点是无法根据每张图片所属的标签进行分类下载。比如说,某张图片是属于"车厢座椅"标签的,但这个程序没有办法单独创建一个"车厢座椅"文件夹进行下载。
下面解决这个问题:
要想改变存储的路径,就要看看路径是在哪里确定下来的,这个类是ImagesPipeline,在里面发现了file_path这个方法,它确定了图片的路径,因此重写ImagesPipeline(位于scrapy.pipelines.images.ImagesPipeline)也许可以,进去后查看:
- file_path
def file_path(self, request, response=None, info=None):
## start of deprecation warning block (can be removed in the future)
def _warn():
from scrapy.exceptions import ScrapyDeprecationWarning
import warnings
warnings.warn('ImagesPipeline.image_key(url) and file_key(url) methods are deprecated, '
'please use file_path(request, response=None, info=None) instead',
category=ScrapyDeprecationWarning, stacklevel=1)
# check if called from image_key or file_key with url as first argument
if not isinstance(request, Request):
_warn()
url = request
else:
url = request.url
# detect if file_key() or image_key() methods have been overridden
if not hasattr(self.file_key, '_base'):
_warn()
return self.file_key(url)
elif not hasattr(self.image_key, '_base'):
_warn()
return self.image_key(url)
## end of deprecation warning block
image_guid = hashlib.sha1(to_bytes(url)).hexdigest() # change to request.url after deprecation
return 'full/%s.jpg' % (image_guid)
可以看到,最后返回的是’full/%s.jpg’ % (image_guid),即full文件夹下的文件名字。因此我们可以重写这个方法,那就得搞一个新的类,让其继承ImagesPipeline,进而重写一些方法,来让图片下载到对应的文件夹中。
但只有item知道每张图片属于哪个标签,而只重写file_path无法拿到item,因此想办法将item和file_path联系起来。
于是看到下面的方法:
- get_media_requests
def get_media_requests(self, item, info):
return [Request(x) for x in item.get(self.images_urls_field, [])]
我们再重写这个方法,新构建的类如下:
class BMWImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
request_objs = super(BMWImagesPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
path = super(BMWImagesPipeline, self).file_path(request, response=None, info=None)
category = request.item.get('category')
images_store = settings.IMAGES_STORE
category_path = os.path.join(images_store, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
image_name = path.replace("full/", "")
image_path = os.path.join(category_path, image_name)
return image_path
通过重写get_media_requests,将item和每个request联系起来,然后再重写file_path通过requset.item将category提取出来就能达到目的。
从settings中导入IMAGES_STORE,获得images文件夹的位置,然后通过前面说过的os.path.join方法将images文件夹和每个请求的category组成新的目录(如:images/车身外观),然后通过if语句判断是否存在图片所属的文件夹,如果不存在则创建。最后通过replace将之前的full文件夹去掉只剩图片名,再通过os.path.join将图片名和其所属的文件夹组合在一起。
遇见的问题
在重写get_media_requests时,用了一个for循环给每个request执行了 request_obj.item = item,我通过dir(request)查看了request的属性和方法,发现并没有item这个条目,于是产生疑问,为啥没有这个属性还能加上呢?
后来我写了如下代码:
class Father:
def __init__(self, a, b):
self.x = a
self.y = b
def show(self, q):
print(dir(self))
f = Father(1, 2)
f.show(5)
f.item = 3
f.show(5)
输出结果:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'show', 'x', 'y']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'item', 'show', 'x', 'y']
可以看到,虽然类里面没有item这个条目,但可以在类外人为的添加,不知道重写get_media_requests方法时用到的技巧是不是这个道理,验证如下:
def get_media_requests(self, item, info):
request_objs = super(BMWImagesPipeline, self).get_media_requests(item, info)
print(dir(request_objs[1]))
for request_obj in request_objs:
request_obj.item = item
print(dir(request_objs[1]))
return request_objs
在执行循环之前和之后分别输出request的属性和方法,输出结果如下:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__', '_body', '_encoding', '_get_body', '_get_url', '_meta', '_set_body', '_set_url', '_url', 'body', 'callback', 'cookies', 'copy', 'dont_filter', 'encoding', 'errback', 'flags', 'headers', 'meta', 'method', 'priority', 'replace', 'url']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__', '_body', '_encoding', '_get_body', '_get_url', '_meta', '_set_body', '_set_url', '_url', 'body', 'callback', 'cookies', 'copy', 'dont_filter', 'encoding', 'errback', 'flags', 'headers', 'item', 'meta', 'method', 'priority', 'replace', 'url']
确实如此,看来还是自己对python了解的太浅了,不过以后碰见类似的需求倒是可以应用一下。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









