







MySQL高级操作
视图
- 视图我们可以粗略的理解为将查询后的内容保存成一个变量。调用这个变量我们就能获得查询的数据。
- 当我们查看表(
show tables;)的时候,会看到当前所有的视图,为了方便我们区分表和视图的区别,建议在视图命名时头部添加v_
创建视图
创建语法 :create view 视图名称 as select语句;
注意:和普通表相同的是视图中的表头也不能出现重复字段!我们在将两表链接存储时很容易出现表头重复的问题
假设我们现在有以下两张表。
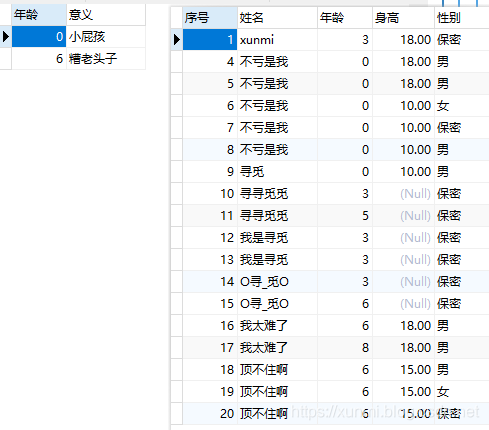
我对上述两表进行create view v_测试_年龄 as select * from 寻觅的测试表 as 测试 left join 寻觅的年龄连接表 as 年龄 on 测试.年龄=年龄.年龄;这句操作;
我们会收到报错ERROR 1060 (42S21): Duplicate column name '年龄',这时候我们可以将select后的*进行改变
create view v_测试_年龄 as select 测试.*,年龄.意义 from 寻觅的测试表 as 测试 left join 寻觅的年龄连接表 as 年龄 on 测试.年龄=年龄.年龄;如此就不会出现重复的表头,可以成功创建视图
查看视图
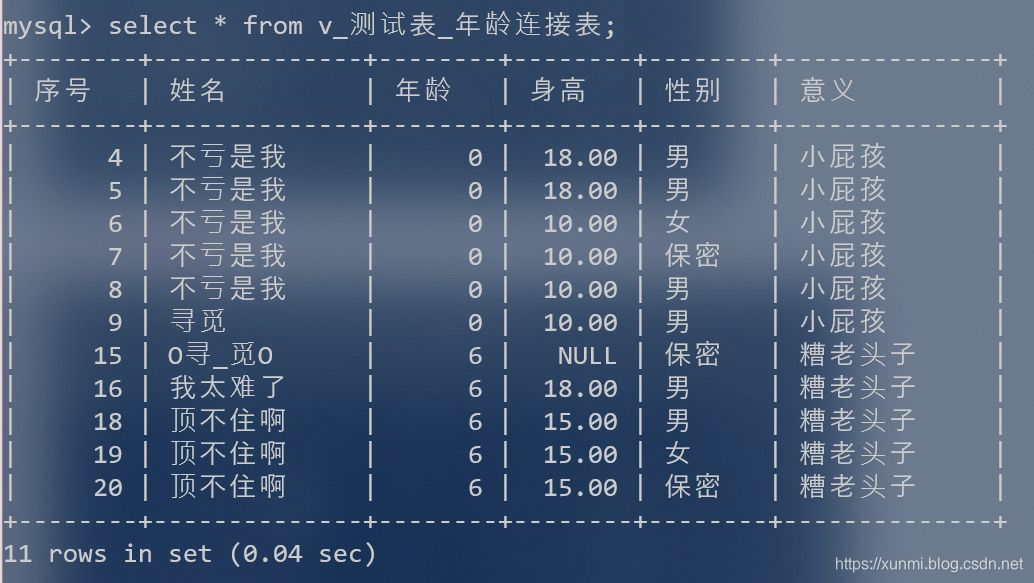
视图查看的方式和表完全相同,我们甚至可以用查表的方式查询有哪些视图。show table;这时候前缀v_的作用就体现出来了

同样使用 select * from 视图名;就能看见视图内的内容比如select * from v_测试表_年龄连接表;
删除视图
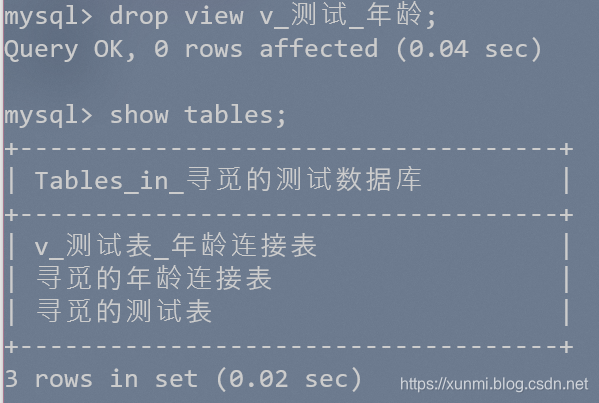
删除视图:drop view 视图名
例:drop view v_测试_年龄;
视图的修改
视图主要作用是方便查看,虽然没有彻底限制视图不能修改,并不推荐修改,而且视图修改时限制颇多。
如下视图是无法修改的:
- select子句中包含distinct
- select子句中包含组函数
- select语句中包含group by子句
- select语句中包含order by子句
- where子句中包含相关子查询
- from子句中包含多个表
- 如果视图中有计算列,则不能更新
- 如果基表中有某个具有非空约束的列未出现在视图定义中,则不能做insert操作
视图的意义
- 提高了重用性,就像一个函数
- 对数据库重构,却不影响程序的运行
- 提高了安全性能,可以对不同的用户
- 让数据更加清晰
事务
事务在订单和银行系统中会有大量使用场景。你可以将事务看出几个同生共死的兄弟,这些兄弟们时时刻刻都会共进退,一个无法通过则全员都不通过。
假设你准备使用支付宝购买一顿15块钱的午饭,扫码后支付宝会做如下几件事:
- 查询你的账户余额>支付金额
- 将你的账户余额扣除
- 将商家账户中增加相应的金额。
如果商家没有收到相应的金额,这这些金额会原路返回到你的账户中
事务四大特性(ACID)
原子性(Atomicity)
一个事务必须将视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败滚回,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
一致性(consistency)
数据库总是从一个一致性的状态转换到另一个一致性的状态。
隔离性(isolation)
一个事务所做的修改在最终提交以前,对其他事务是不可见的。
持久性(durability)
一旦事务提交,则其所做的修改会永久保存到数据库。
启动事务
并不是所有数据库的存储引擎都支持事务,在MySQL5.7之前默认的存储引擎就是不支持事务的,我们这里使用的是innodb,此引擎在MySQL5.7以及之后的数据库中为默认引擎。
开启
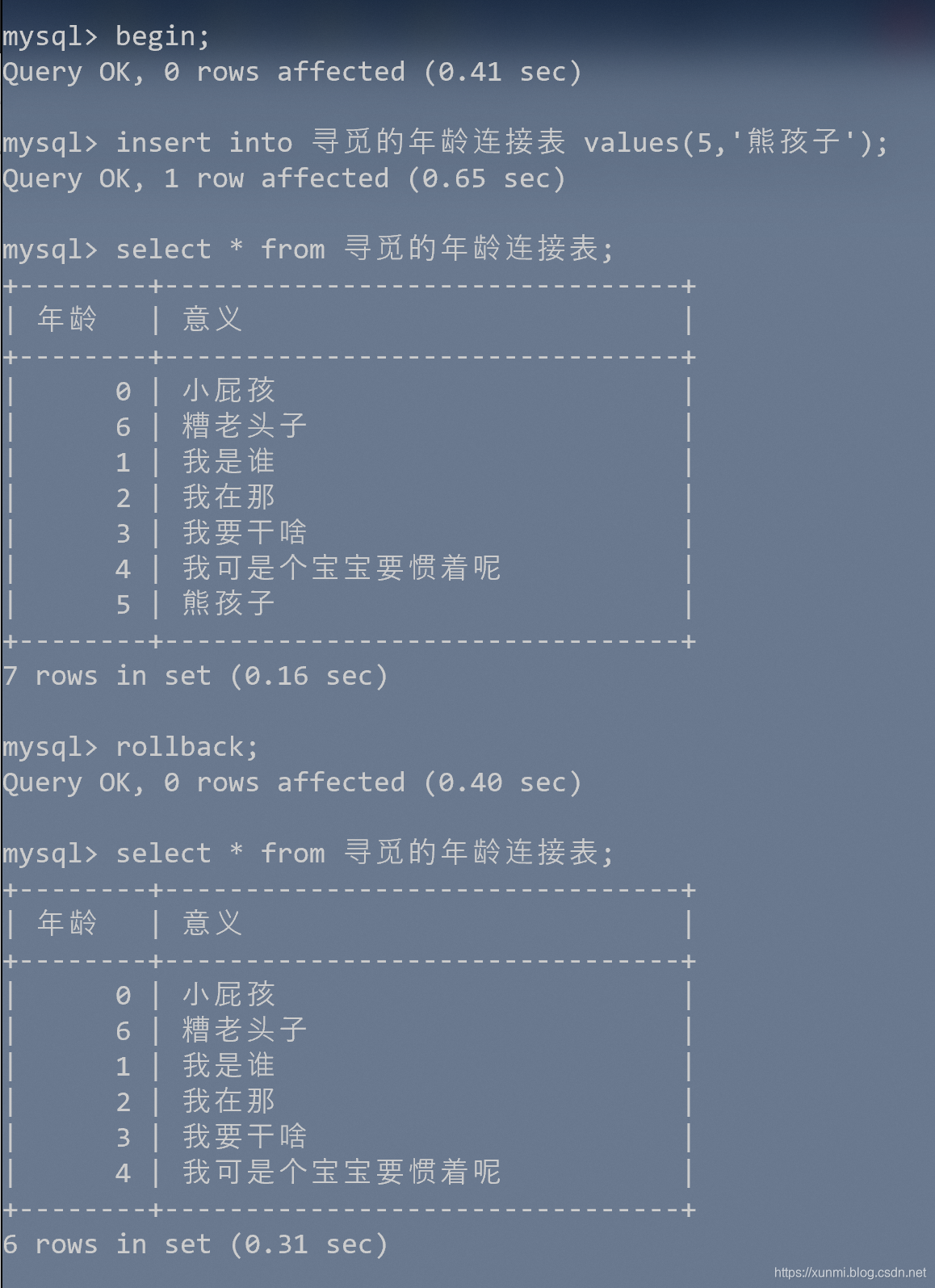
begin;或start transaction;
我们开启事务后,执行了几句添加语句,添加成功后,我们发现在本地去查询数据已经存在了,但是直接查询服务器发现数据并不存在
insert into 寻觅的年龄连接表 values(1,'我是谁');
insert into 寻觅的年龄连接表 values(2,'我在那');
insert into 寻觅的年龄连接表 values(3,'我要干啥');

提交
commit;
当我执行提交后,我们会发现数据同时出现在了我们的数据库中。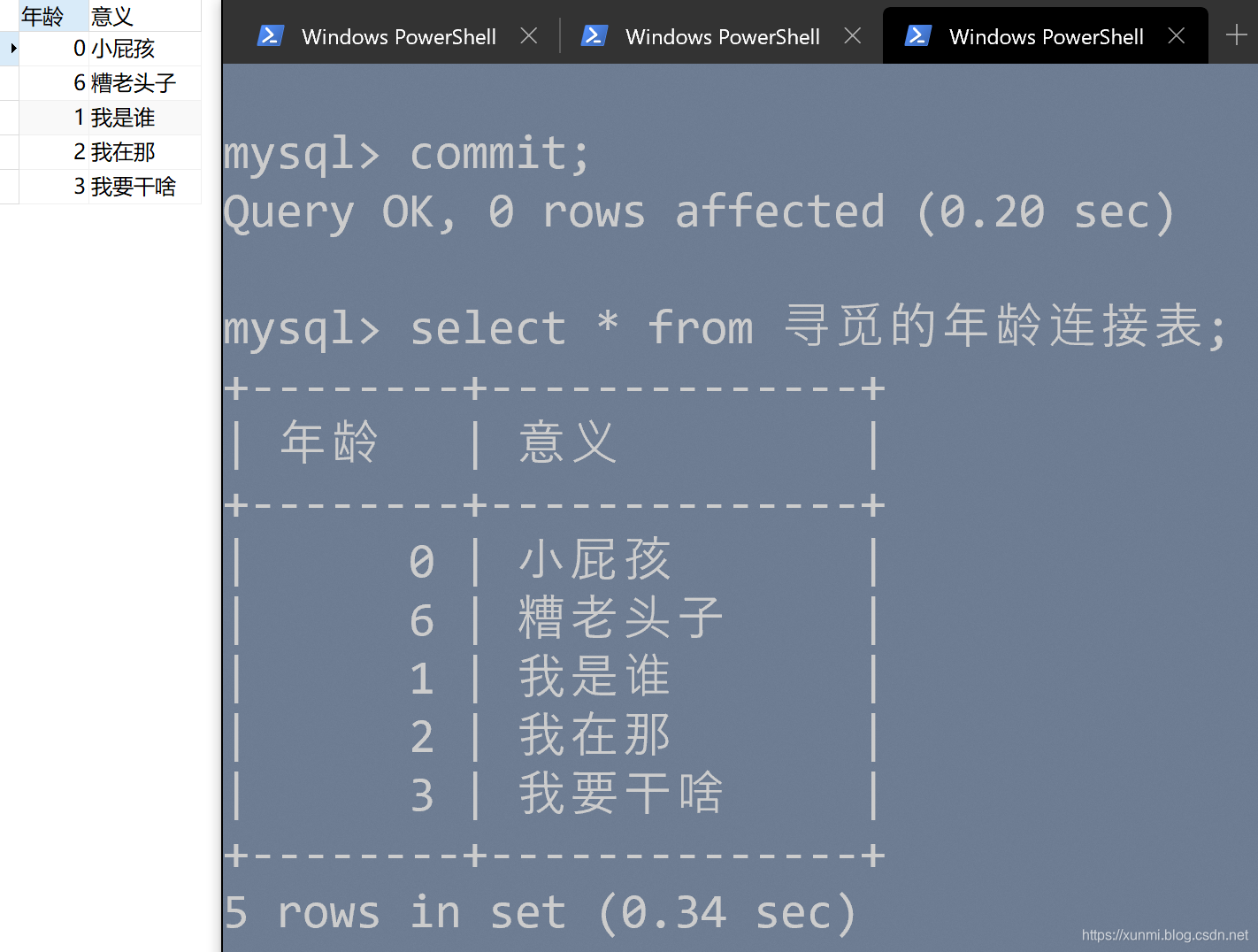
回滚
rollback
取消所有尚未提交的操作,但并不影响已经提交的操作。
索引
索引在生活中并不少见,书的目录我们就可以看作为索引,数据库的索引也可以看出数据库的目录,方便我们能更快的查找到我们需要的内容。
索引是什么
索引也是存在数据库中的一张特殊的表,当我们调用索引相关字段时数据库会自动去索引表中找到我们需要数据所对应的游标,这里的游标就相当于目录的页码。
索引的原理
索引常用B+树模型建立,也会有使用哈希表建立。在这里我们就来介绍一下B+树的存储方式
每个B+树的结点中都存储了两个数据和三个子节点而这个数据又为从小到大排列

使用索引
查看索引
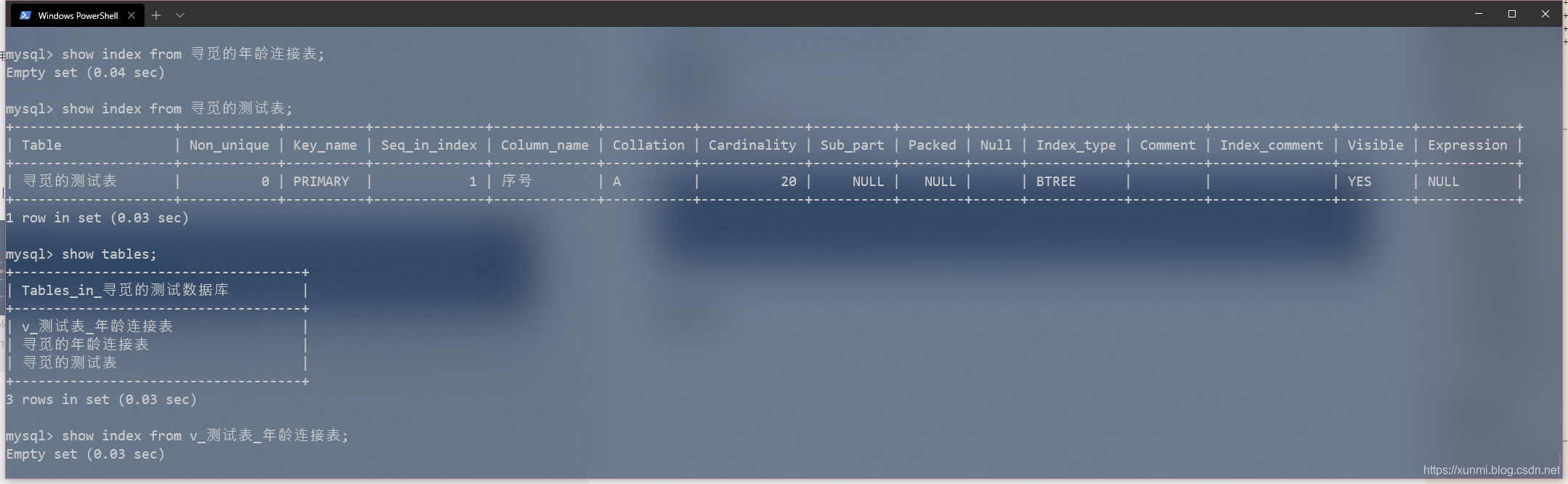
show index from 表名;
在这里两个表中我都从未定义过索引,但测试表中却有着一条索引信息,这条信息是因为我在创建测试表时添加了主键,主键会自动生成索引信息,根据下图我们还能发现,生成的视图并不会继承我们的索引信息。
创建索引
create index 索引名称 on 表名(字段名称(长度));
实例:
- 启用运行时间记录
set profiling=1; - 在数据表中查找一条数据
select * from 寻觅的索引表 where 数据='我是第999'; - 查看查询消耗时间
show profiles; - 创建索引
create index 索引_数据 on 寻觅的索引表(数据(30)); - 再次查找之前那条数据
select * from 寻觅的索引表 where 数据='我是第999'; - 查看查询消耗时间
show profiles;

我们会发现添加索引后,查询速度得到提升和优化。
删除索引
drop index 索引名称 on 表名;
例如 : drop index 索引_数据 on 寻觅的索引表;

何时使用索引适合
适合建立索引的情况
- 主键自动建立索引
- 频繁作为查询条件的字段应该建立索引
- 查询中与其他表关联的字段,外键关系建立索引
- 在高并发的情况下创建复合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度 (建立索引的顺序跟排序的顺序保持一致)
不适合建立索引的情况
- 频繁更新的字段不适合建立索引
- where条件里面用不到的字段不创建索引
- 表记录太少,当表中数据量超过三百万条数据,可以考虑建立索引
- 数据重复且平均的表字段,比如性别,国籍















 2115
2115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











