







哈夫曼编码,是一种可变字长编码(VLC)的高效算法。该算法是Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码。
相比定长编码来说,这种编码实现的压缩率(衡量压缩算法效率的重要指标)非常高,也就是说,哈夫曼编码比定长编码占用更少的存储空间。
假设我们要对某个字母表创建一套二进制前缀码,那么我们一般都会讲字母表中的字符与二进制的叶子联系起来,树中所有的左向边都为0,右向边都为1.可以通过记录根到字符叶子的简单路径上的标记来获得一个字符的代码字。这样任何一棵这样的树都可以生成一套前缀码。但是我们都知道即使在英文单词中,每个字母出现的概率都是不同的,如果仅仅是放到二叉树中,对于一些高频字符很可能需要更长的代码串来表示,这是非常不友好的。
一个方法就是通过根据字符出现的概率,尽可能将短位串分配给高频字符,长位串分配给低频字符。这里就用到了贪婪思想。
思路:
1. 初始化n个单节点的数,表上字母表中的字符,并将其概率记录,用来表示权重。
2. 找出两颗权重最小的树(对于权重都相同的树,任选其一),将它们作为新树中的左右子树,并将权值之和记录到新的树根中。迭代这一步操作,直到剩下一棵单独的树。
以下面的例子来描述哈夫曼树的构造过程:
| 字符 | A | B | C | D | _ |
| 出现概率 | 0.35 | 0.1 | 0.2 | 0.2 | 0.15 |
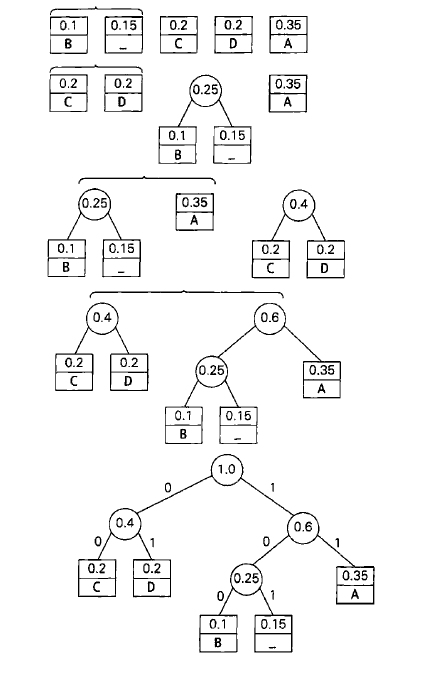
由上面的过程我们得到了下面的代码字:
| 字符 | A | B | C | D | _ |
| 出现概率 | 0.35 | 0.1 | 0.2 | 0.2 | 0.15 |
| 代码字 | 11 | 100 | 00 | 01 | 101 |
Input:
5
A B C D _
35 10 20 20 15
Output:
A : 11
B : 100
C : 00
D : 01
_ : 101
完整代码如下:
import java.util.Scanner;
public class Main {
//建立数的节点类
static class Node{
int weight;//频数
int parent;
int leftChild;
int rightChild;
public Node(int weight, int parent, int leftChild, int rightChild){
this.weight = weight;
this.parent = parent;
this.leftChild = leftChild;
this.rightChild = rightChild;
}
void setWeight(int weight){
this.weight = weight;
}
void setParent(int parent){
this.parent = parent;
}
void setLeftChild(int leftChild){
this.leftChild = leftChild;
}
void setRightChild(int rightChild){
this.rightChild = rightChild;
}
int getWeight(){
return weight;
}
int getParent(){
return parent;
}
int getLeftChild(){
return leftChild;
}
int getRightChild(){
return rightChild;
}
}
//新建哈夫曼编码
static class NodeCode {
String character;
String code;
NodeCode(String character, String code) {
this.character = character;
this.code = code;
}
NodeCode(String code) {
this.code = code;
}
void setCharacter(String character) {
this.character = character;
}
void setCode(String code) {
this.code = code;
}
String getCharacter() {
return character;
}
String getCode() {
return code;
}
}
//初始化一个哈弗曼树
public static void initHuffmanTree(Node[] huffmanTree, int m){
for(int i = 0; i < m; i++){
huffmanTree[i] = new Node(0, -1, -1, -1);
}
}
//初始化编码
public static void initHuffmanCode(NodeCode[] huffmanCode, int n){
for(int i = 0; i < n; i++){
huffmanCode[i] = new NodeCode("","");
}
}
//获取huffmanCode的符号
public static void getHuffmanCode(NodeCode[] huffmanCode, int n){
Scanner input = new Scanner(System.in);
for(int i = 0; i < n; i++){
String temp = input.next();
huffmanCode[i] = new NodeCode(temp,"");
}
}
//获取频率
public static void getHuffmanWeight(Node[] huffmanTree , int n){
Scanner input = new Scanner(System.in);
for(int i = 0; i < n;i ++){
int temp = input.nextInt();
huffmanTree[i] = new Node(temp, -1, -1, -1);
}
}
//选取两个较小的结点
public static int[] selectMin(Node[] huffmanTree ,int n) {
int min[] = new int[2];
class TempNode {
int newWeight;//存储权
int place;//存储该结点所在的位置
TempNode(int newWeight, int place){
this.newWeight = newWeight;
this.place = place;
}
void setNewWeight(int newWeight){
this.newWeight = newWeight;
}
void setPlace(int place){
this.place = place;
}
int getNewWeight(){
return newWeight;
}
int getPlace(){
return place;
}
}
TempNode[] tempTree = new TempNode[n];
//将huffmanTree中没有双亲的结点存储到tempTree中
int i=0,j=0;
for(i = 0; i < n; i++) {
if(huffmanTree[i].getParent() == -1 && huffmanTree[i].getWeight()!=0) {
tempTree[j] = new TempNode(huffmanTree[i].getWeight(),i);
j++;
}
}
int m1,m2;
m1 = m2 = 0;
for(i = 0; i < j; i++) {
if(tempTree[i].getNewWeight() < tempTree[m1].getNewWeight())//此处不让取到相等,是因为结点中有相同权值的时候,m1取最前的
m1 = i;
}
for(i = 0; i < j; i++) {
if(m1 == m2)
m2++;//当m1在第一个位置的时候,m2向后移一位
if(tempTree[i].getNewWeight() <= tempTree[m2].getNewWeight() && i != m1)//此处取到相等,是让在结点中有相同的权值的时候,
//m2取最后的那个。
m2 = i;
}
min[0] = tempTree[m1].getPlace();
min[1] = tempTree[m2].getPlace();
return min;
}
//创建哈弗曼树
public static void createHaffmanTree(Node[] huffmanTree,int n){
if(n <= 1)
System.out.println("Parameter Error!");
int m = 2 * n - 1;
//initHuffmanTree(huffmanTree,m);
for(int i = n; i < m; i++) {
int[] min = selectMin(huffmanTree, i);
int min1 = min[0];
int min2 = min[1];
huffmanTree[min1].setParent(i);
huffmanTree[min2].setParent(i);
huffmanTree[i].setLeftChild(min1);
huffmanTree[i].setRightChild(min2);
huffmanTree[i].setWeight(huffmanTree[min1].getWeight() + huffmanTree[min2].getWeight());
}
}
//创建哈夫曼编码
public static void createHaffmanCode(Node[] huffmanTree,NodeCode[] huffmanCode,int n){
Scanner input = new Scanner(System.in);
char[] code = new char[10];
int start;
int c;
int parent;
int temp;
code[n-1] = '0';
for(int i = 0; i < n; i++)
{
StringBuffer stringBuffer = new StringBuffer();
start = n-1;
c = i;
while((parent=huffmanTree[c].getParent()) >= 0)
{
start--;
code[start] = ((huffmanTree[parent].getLeftChild() == c) ? '0' : '1');
c = parent;
}
for(;start < n-1; start++){
stringBuffer.append(code[start]);
}
huffmanCode[i].setCode(stringBuffer.toString());
}
}
//输出
public static void ouputHaffmanCode(NodeCode[] huffmanCode,int n){
for(int i = 0; i < n; i++){
System.out.println(huffmanCode[i].getCharacter() + " : " + huffmanCode[i].getCode());
}
}
//主函数
public static void main(String[] args){
Scanner input = new Scanner(System.in);
int n;
int m;
n = input.nextInt();
m = 2*n-1;
Node[] huffmanTree = new Node[m];
NodeCode[] huffmanCode = new NodeCode[n];
//初始化
initHuffmanTree(huffmanTree, m);
initHuffmanCode(huffmanCode, n);
//获取符号
getHuffmanCode(huffmanCode, n);
//获取概率
getHuffmanWeight(huffmanTree, n);
//创建哈夫曼树
createHaffmanTree(huffmanTree, n);
//创建哈夫曼编码
createHaffmanCode(huffmanTree, huffmanCode, n);
//输出
ouputHaffmanCode(huffmanCode, n);
}
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









