






 本文详细介绍了MybatisPlus中的流式查询原理,如何在项目中启用和使用它,以及在处理大数据量时的优势。通过实例演示了如何在实际项目中利用流式查询功能,以降低内存压力并提高系统性能。
本文详细介绍了MybatisPlus中的流式查询原理,如何在项目中启用和使用它,以及在处理大数据量时的优势。通过实例演示了如何在实际项目中利用流式查询功能,以降低内存压力并提高系统性能。
引言
在大数据量处理的场景中,如何高效地进行数据库查询并节省内存资源是开发者们面临的重要挑战。MybatisPlus作为一款深受开发者喜爱的Mybatis增强工具,提供了诸多实用功能以简化开发工作,其中的流式查询便是应对大数据量处理的利器之一。本文将深入探讨MybatisPlus流式查询的原理,并通过实例演示其具体使用方法,助您轻松应对海量数据处理任务。
一、流式查询原理
流式查询,顾名思义,是指在查询过程中,数据库以数据流的形式逐条返回结果,而不是一次性加载全部数据到内存中。这种方式尤其适用于数据量庞大、内存资源有限的场景,能够显著降低内存压力,提高系统的响应速度和稳定性。在MybatisPlus中,流式查询通过com.baomidou.mybatisplus.extension.plugins.pagination.Dialect接口实现,该接口定义了与不同数据库方言对应的分页查询SQL生成方法。当启用流式查询时,MybatisPlus会根据配置的数据库类型生成相应的流式查询SQL,每次仅加载少量数据到内存,从而实现大数据量的高效处理。
二、启用流式查询
在使用MybatisPlus进行流式查询之前,需要确保以下几点:
1. 添加依赖
确保项目中已引入MybatisPlus相关依赖。
以Maven为例:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>最新版本</version>
</dependency>
2. 配置数据库连接
在Spring Boot的配置文件(如application.yml)中配置正确的数据库连接信息。
spring:
datasource:
url: jdbc:mysql://localhost:3306/your_database?useSSL=false&serverTimezone=UTC
username: your_username
password: your_password
driver-class-name: com.mysql.cj.jdbc.Driver3. 设置流式查询参数
在执行查询时,通过设置QueryWrapper或LambdaQueryWrapper的stream()方法开启流式查询参数如图:

三、实战示例
接下来,我们将通过一个完整的示例,展示如何在实际项目中运用MybatisPlus的流式查询处理大数据。
1. 定义实体类
假设我们有一个商户订单MerchantOrderInfoPO实体类,包含ID、订单号、商户号等属性 如图:

2. 创建Mapper接口
创建MerchantOrderInfoMapper接口,继承com.baomidou.mybatisplus.core.mapper.BaseMapper,并添加自定义查询方法:getSelectMerchantOrderInfoDataList 如图:
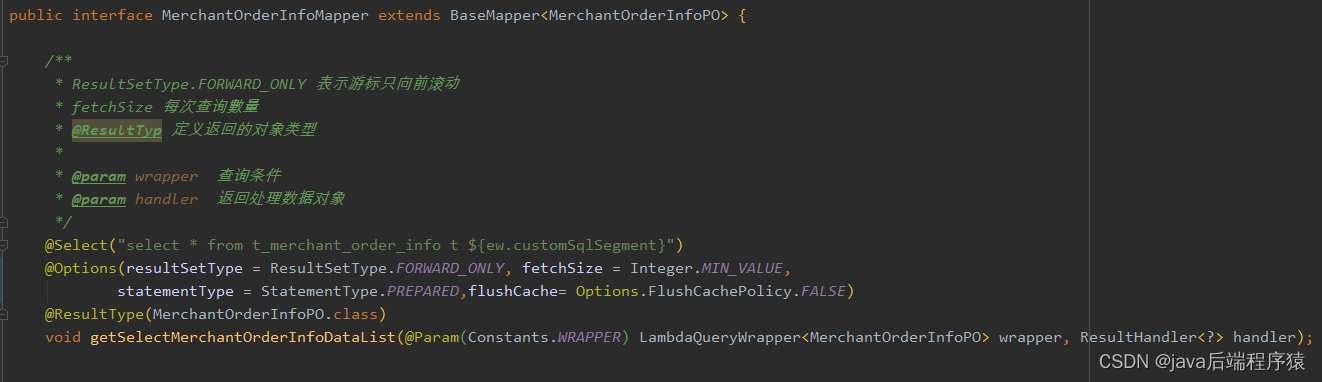
3. 实现流式查询
在Service层或业务逻辑处理的地方,使用流式查询来获取所有订单数据:
@Override
public R getSelectMerchantOrderInfoDataList(MerchantOrderInfoSearchParam param) {
merchantOrderInfoService.getSelectMerchantOrderInfoDataList(param, new
ResultHandler<Object>() {
@Override
public void handleResult(ResultContext<?> resultContext) {
// 对每一条订单数据进行处理...
// 写上你的业务代码
}
});
}
return R.success("成功!");
}
结语
MybatisPlus的流式查询功能为开发者在处理大数据量场景时提供了强大且高效的解决方案。通过合理设置流式查询参数,既能保证系统的内存利用率,又能确保数据处理的高效进行。掌握并善用流式查询,无疑将为您的项目开发增添一份有力保障。
拓展实际应用
流式查询应用在导出功能上有明显的性能提升,在做导出功能时,只需要在Service层将处理好的导出数据添加到list集合中,然后及时清理集合中的数据,防止出现新的oom问题,如图:
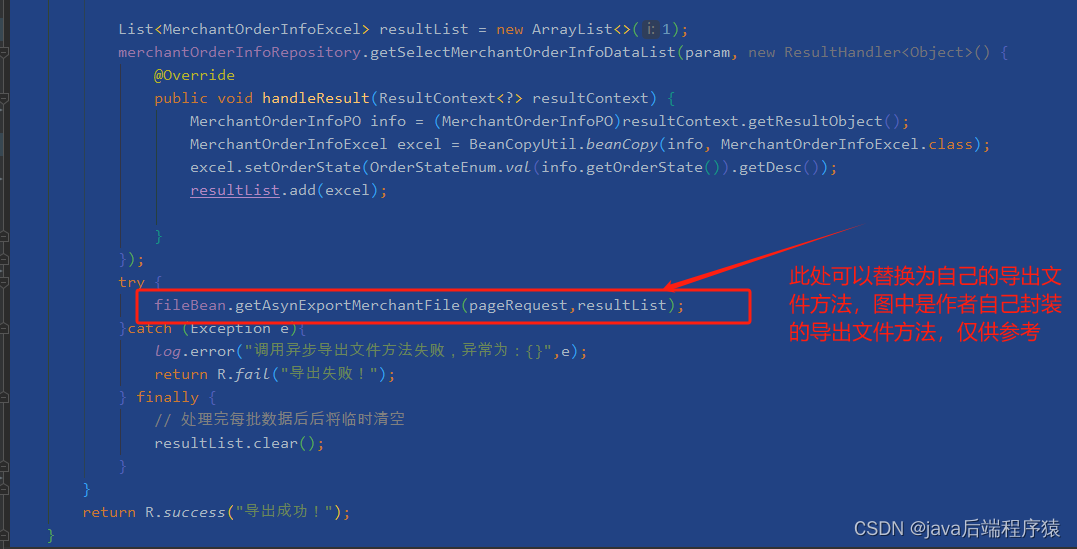
个人经验。不喜勿喷,欢迎大家一起交流使用心得!
















 6257
6257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











