






个人学习记录。
一、基础篇
1. 基本架构:一个键值数据库包含什么?
- 访问框架
- 操作模块
- 索引模块
- 存储模块
(Redis除上述四块外有高可用集群模块和高可扩展模块)
2. 数据结构:快速的Redis有哪些慢操作?
- 键和值之间的存储是什么数据结构?
- 使用了哈希表,称之为全局哈希表。
- 哈希表是一个数组,数组的每一个元素是一个哈希桶。
- (可能变慢)出现哈希冲突则使用拉链法解决(链表)。
- 为了避免rehash变慢,Redis采用了渐进式rehash。
- Redis基础数据类型和底层数据结构
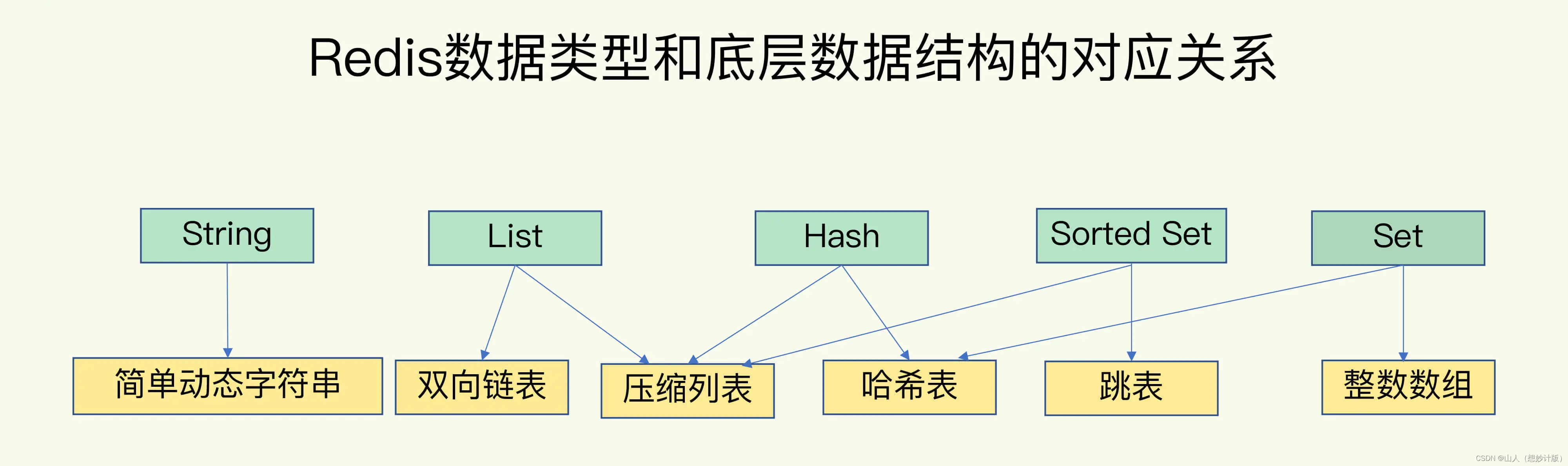
- 整数数组和压缩列表在查找的时间复杂度上不占优势,为何Redis还使用它们作为底层数据结构呢?
- 内存利用率高,整数数组和压缩列表的数据结构很紧凑,例如链表还需额外存储指针。
- 数组是连续内存,对CPU高速缓存更友好。所以当数据量很少时不会降低访问速度。但当数据量超过阈值时,为了降低查询的时间复杂度会转变为哈希表或跳表。
3. 高性能IO模型:为什么单线程Redis能那么快?
- Redis是单线程的吗?
- 一般是指网络I/O和键值对读写是单线程完成的。
- 其他功能是额外的线程执行的,比如持久化、异步删除、集群同步等。
- Redis 6.0中引入了多线程模型,网络I/O部分改为多线程。(TODO)
- 为什么用单线程?
- 多线程开销:上下文切换、等待获取共享资源等。
- 单线程为什么这么快?
- 采用I/O多路复用机制。
二、实践篇
11. 万金油的String为什么不好用了?
- String类型存储开销大。
- SDS结构体中除了buf(实际数据)外,还有len(已用长度 4字节)和alloc(实际分配长度 4字节)。
- Redis统一使用RedisObject记录元数据,并指向实际数据。
- 元数据(8字节)
- 指针(8字节):指向了SDS。
- 压缩列表(ZipList)可以节省内存。
- 实践:如何使用集合类型来存储单值的键值对?
- 基于Hash的二次编码
- 以存储String举例,可以将字符串分组,比如10位数字,取前7位为Hash的Key,后三位为Field,对应value不变。
- 需要注意设置hash-max-ziplist-entries和hash-max-ziplist-value,也就是用压缩列表存Hash时的最多元素个数和最大元素长度。如果超出了底层会变为哈希表。
- 基于Hash的二次编码
12. 有一亿个keys要统计,应该用哪种集合?
- 聚合统计
- Set集合的交集、并集、差集。
- 计算复杂度较高,数据量大的情况下会阻塞Redis。可以在主从集群中选择一个从节点负责聚合计算。
- 排序统计
- Sorted Set
- 场景:最新列表、排行榜
- 二值状态统计
- 使用bitmap节省内存。(SETBIT、GETBIT、BITCOUNT)
- 场景:签到打卡、1亿个用户中连续10天打卡的人数。
- 基数统计
- 统计一个集合中不重复的元素个数。
- Set内存空间占用很大。
- HyperLogLog当集合元素数量非常多时,计算基数所需的空间是固定的且比较小。但HyperLogLog是基于概率实现的,有一定误差。
- 场景:统计UV,一个用户多次访问只计数1次。















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









