








欢迎大家评论留言发表自己的观点,大数据还需要掌握哪些知识或者技术。
基础概念
大数据的本质
一、数据的存储:分布式文件系统(分布式存储)
二、数据的计算:分部署计算
基础知识
学习大数据需要具备Java知识基础及Linux知识基础
学习路线
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 -> Hive、Pig
数据采集引擎 -> Sqoop、Flume
第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HA
Oozie:工作流引擎
(3)Spark的学习
第一阶段:Scala编程语言
第二阶段:Spark Core -> 基于内存、数据的计算
第三阶段:Spark SQL -> 类似于mysql 的sql语句
第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂
(4)Apache Storm 类似:Spark Streaming ->进行流式计算
NoSQL:Redis基于内存的数据库
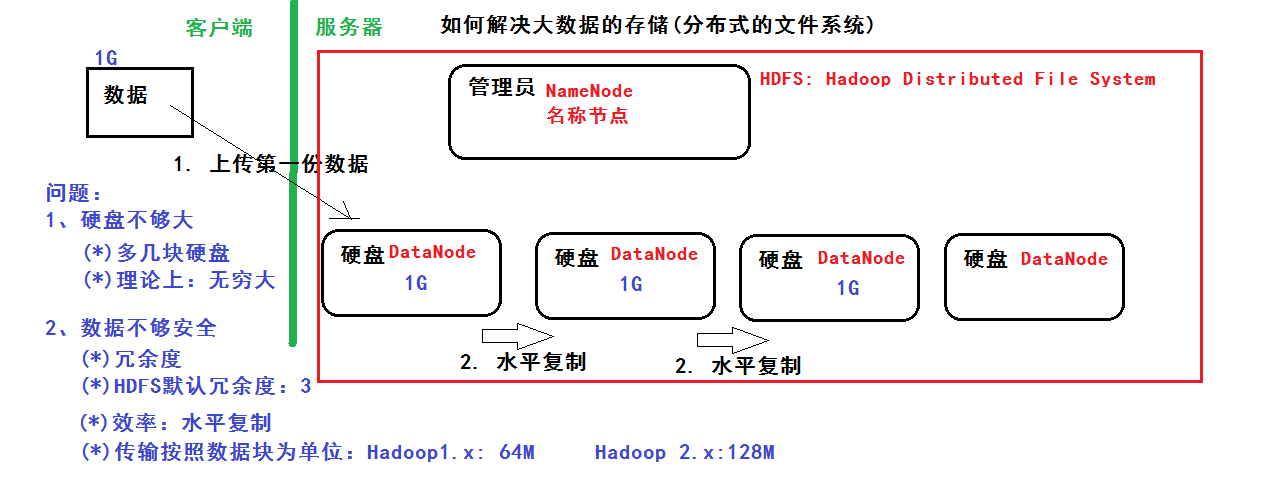
HDFS
分布式文件系统 解决以下问题:
• 硬盘不够大:多几块硬盘,理论上可以无限大
• 数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128M
• 管理员:NameNode 硬盘:DataNode
MapReduce
基础编程模型:把一个大任务拆分成小任务,再进行汇总
• MR任务:Job = Map + Reduce
Map的输出是Reduce的输入、MR的输入和输出都是在HDFS
MapReduce数据流程分析:
• Map的输出是Reduce的输入,Reduce的输入是Map的集合
HBase
什么是BigTable?: 把所有的数据保存到一张表中,采用冗余 ---> 好处:提高效率
• 因为有了bigtable的思想:NoSQL:HBase数据库
• HBase基于Hadoop的HDFS的
• 描述HBase的表结构
核心思想是:利用空间换效率
大数据工程涉及大量数据的设计,部署,获取以及维护(保存)。大数据工程师需要去设计和部署这样一个系统,使相关数据能面向不同的消费者及内部应用。
1. 而大数据分析的工作则是利用大数据工程师设计的系统所提供的大量数据。大数据分析包括趋势、图样分析以及开发不同的分类、预测预报系统。
2.因此,简而言之,大数据分析是对数据的高级计算。而大数据工程则是进行系统设计、部署以及计算运行平台的顶层构建。
3.如何成为一名大数据工程师
我们知道大数据领域充斥着多种技术。因此,你学习与你的大数据工作角色相关的技术非常重要。这与任何常规领域有点不同,如数据科学和机器学习中,你可以从某些地方开始并努力完成这一领域内的所有工作。
4.资源,想要大数据学习资料可以加入我们大数据开发学习群
学习一个新的东西肯定是需要需要学习资料,没有资料从何学习呢。零基础.进阶.项目实战欢迎加入319819749















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









