







PEGASUS:基于抽取间隙句的预训练模型用于抽象摘要生成
摘要
近期的工作表明,在大规模文本语料库上使用自监督目标对Transformer模型进行预训练,并在包括文本摘要在内的下游自然语言处理任务上进行微调,取得了巨大成功。然而,专门为抽象文本摘要设计的预训练目标尚未得到充分探索。此外,跨多个领域的系统性评估也较为缺乏。在本研究中,我们提出了一种新的自监督目标,在大规模文本语料库上预训练基于Transformer的编码器-解码器模型。在PEGASUS中,输入文档中的重要句子被移除或掩码,并从剩余句子中生成一个输出序列,类似于抽取式摘要。我们在涵盖新闻、科学、故事、说明、电子邮件、专利和立法法案等12个下游摘要任务上评估了最佳的PEGASUS模型。实验结果表明,通过ROUGE分数衡量,该模型在所有12个下游数据集上均达到了最先进的性能。我们的模型在低资源摘要任务中也表现出令人惊讶的性能,仅用1000个样本就在6个数据集上超越了之前的最先进结果。最后,我们通过人工评估验证了实验结果,并证明我们的模型在多个数据集上的摘要表现达到了人类水平。
1 引言
文本摘要的目标是从输入文档中生成准确且简洁的摘要。与仅从输入中复制信息片段的抽取式摘要不同,抽象式摘要可能会生成新的词汇。一个好的抽象式摘要应涵盖输入中的主要信息,并在语言上流畅自然。
在抽象式摘要中,序列到序列(Sutskever et al., 2014)已成为主流框架,使用基于RNN(Chung et al., 2014; Hochreiter & Schmidhuber, 1997)和最近基于Transformer(Vaswani et al., 2017)的编码器-解码器架构。大多数关于神经抽象式摘要的研究依赖于大规模、高质量的监督文档-摘要对数据集(Hermann et al., 2015),并取得了显著成果(Rush et al., 2015; Nallapati et al., 2016; See et al., 2017)。近年来,人们越来越关注收集新的摘要数据集,这些数据集具有更多抽象式摘要(Narayan et al., 2018)、更长的文档(Cohan et al., 2018; Sharma et al., 2019)、多文档输入(Fabbri et al., 2019)以及来自多样化领域(Grusky et al., 2018; Koupaee & Wang, 2018; Kim et al., 2019; Kornilova & Eidelman, 2019; Zhang & Tetreault, 2019)。然而,针对这些广泛设置的模型系统性评估工作较少。
与此同时,使用自监督目标在大规模文本语料库上预训练的Transformer模型(Radford et al., 2018a; Devlin et al., 2019)显著提升了许多自然语言处理任务的性能(Wang et al., 2018; Rajpurkar et al., 2016)。最近的研究利用此类预训练方法扩展了Transformer基序列到序列模型的成功(Dong et al., 2019; Song et al., 2019; Rothe et al., 2019; Lewis et al., 2019; Raffel et al., 2019),包括抽象式摘要任务。
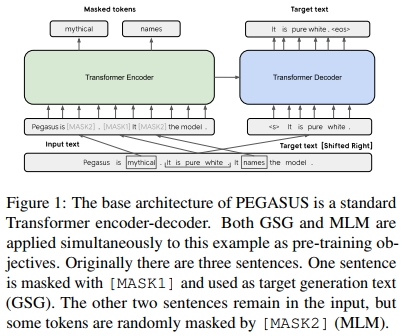
在本研究中,我们专门研究了针对抽象式文本摘要的预训练目标,并在12个下游数据集上进行了评估,涵盖新闻(Hermann et al., 2015; Narayan et al., 2018; Grusky et al., 2018; Rush et al., 2015; Fabbri et al., 2019)、科学(Cohan et al., 2018)、短篇故事(Kim et al., 2019)、说明(Koupaee & Wang, 2018)、电子邮件(Zhang & Tetreault, 2019)、专利(Sharma et al., 2019)和立法法案(Kornilova & Eidelman, 2019)。我们发现,从文档中掩码整个句子并从剩余部分生成这些间隔句子作为预训练目标在下游摘要任务中表现良好。特别是,选择假定重要的句子优于选择开头或随机选择的句子。我们假设这一目标适合抽象式摘要,因为它与下游任务高度相似,鼓励对整篇文档的理解和类似摘要的生成。我们将这种自监督目标称为间隔句子生成(Gap Sentences Generation, GSG)。使用GSG在大规模文档语料库(网页和新闻文章)上预训练Transformer编码器-解码器,形成了我们的方法——基于抽取间隔句的预训练用于抽象摘要生成的序列到序列模型(PEGASUS)。
我们使用包含5.68亿参数的最佳模型在最近引入的C4语料库(Raffel et al., 2019)上进行训练,在12个摘要任务上达到或超越了当前的最先进水平。我们进一步通过一个新收集的新闻类文章语料库(称为HugeNews)推动了最先进水平,包括竞争激烈的XSum和CNN/DailyMail摘要数据集。
大规模文档-摘要数据集较为稀缺,且在实际应用中,研究数据集与真实用例之间存在不匹配,因为收集摘要的成本较高;最常见的场景是低资源摘要。我们模拟了这一场景,并展示了我们的模型在使用少量监督对进行微调时能够快速适应,仅用1000个样本就在6个数据集上取得了最先进的结果。
从定性角度来看,我们观察到最佳模型生成的高质量输出,并通过人工评估验证了这一点。我们发现,PEGASUS生成的摘要在我们评估的数据集(XSum、CNN/DailyMail和Reddit TIFU)上至少与参考摘要相当,即使在低监督水平下也是如此。
总结我们的贡献:
- 我们提出了一种新的自监督预训练目标——间隔句子生成,并研究了选择这些句子的策略。
- 我们在广泛的下游摘要任务上评估了所提出的预训练目标,并通过仔细的消融实验选择了最佳模型设置,训练了一个包含5.68亿参数的PEGASUS模型,在所有12个下游数据集上达到或超越了最先进水平。
- 我们展示了如何通过微调PEGASUS模型在广泛领域中实现良好的抽象摘要性能,并在仅使用1000个样本的情况下超越了许多任务的最先进结果。
- 我们通过人工评估验证了实验设计,并展示了在XSum、CNN/DailyMail和Reddit TIFU上达到人类水平的摘要性能。
2 相关工作
Dai & Le (2015); Ramachandran et al. (2017) 使用领域内数据的语言模型和自编码器预训练来改进RNN序列模型的性能。然而,结合更大规模的外部文本语料库(如维基百科、书籍或网页)和基于Transformer的序列模型,显著提升了在自然语言理解和文本生成任务上的性能(Radford et al., 2018a; Devlin et al., 2019; Rothe et al., 2019; Yang et al., 2019; Joshi et al., 2019; Song et al., 2019; Dong et al., 2019; Lewis et al., 2019)。与我们的方法最相似的是基于某些掩码输入预训练目标的Transformer编码器-解码器模型。
MASS(Song et al., 2019) 提出了掩码序列到序列生成,根据句子的剩余部分重建句子片段。随机选择一个句子片段。
UniLM(Dong et al., 2019) 提出了联合训练三种语言建模任务:单向(从左到右和从右到左)、双向(词级掩码,带下一句预测)和序列到序列(词级掩码)预测。
T5(Raffel et al., 2019) 将文本到文本框架推广到多种自然语言处理任务,并展示了扩大模型规模(至110亿参数)和预训练语料库的优势,引入了C4——一个从Common Crawl中提取的大规模文本语料库,我们在部分模型中也使用了它。T5通过随机掩码不同比例和长度的文本片段进行预训练。
BART(Lewis et al., 2019) 引入了去噪自编码器来预训练序列到序列模型。BART通过任意噪声函数破坏文本,并学习重建原始文本。对于生成任务,噪声函数是文本填充,使用单个掩码标记来掩码随机采样的文本片段。
与MASS、UniLM、BART和T5不同,PEGASUS掩码多个完整句子,而不是较小的连续文本片段。在我们的最终目标中,我们基于重要性确定性地选择句子,而不是随机选择。与T5类似,PEGASUS不重建完整的输入序列,仅生成掩码句子作为单个输出序列。在本研究中,我们完全专注于下游摘要(生成)任务,未评估自然语言理解分类任务。
在低资源摘要设置方面,已有一些工作使用CNN/DailyMail数据集。Radford et al. (2018b) 表明,在Web文本上预训练的大型Transformer语言模型可以通过提示“TL;DR”生成摘要,在CNN/DailyMail上达到8.27的ROUGE-2分数。Khandelwal et al. (2019) 在维基百科上预训练了一个Transformer语言模型,并使用3000个样本进行微调,达到了13.1的ROUGE-2分数。
3 预训练目标
在本研究中,我们提出了一种新的预训练目标——间隔句子生成(Gap Sentences Generation, GSG)。为了进行比较,我们还单独评估了BERT的掩码语言模型目标,并将其与GSG结合进行评估。
3.1 间隔句子生成(GSG)
我们假设使用与下游任务更相似的预训练目标可以带来更好且更快的微调性能。鉴于我们的目标是用于抽象式摘要,我们提出的预训练目标涉及从输入文档生成类似摘要的文本。为了利用大规模文本语料库进行预训练,我们在缺乏抽象摘要的情况下设计了一种序列到序列的自监督目标。一种简单的方法是将其预训练为抽取式摘要生成器;然而,这种方法只会训练模型复制句子,因此不适合抽象式摘要。
受最近在掩码单词和连续片段方面取得的成功启发(Joshi et al., 2019; Raffel et al., 2019),我们从文档中选择并掩码整个句子,并将这些间隔句子连接成一个伪摘要。每个选中的间隔句子的位置被替换为掩码标记[MASK1],以通知模型。间隔句子比例(Gap Sentences Ratio, GSR)指的是选中的间隔句子数量与文档中句子总数的比例,类似于其他工作中的掩码率。
为了更接近摘要的形式,我们选择那些对文档来说显得重要或核心的句子。由此产生的目标既具有掩码的实证优势,又预见了下游任务的形式。
我们考虑了三种主要策略,用于从包含n个句子的文档 D = { x i } n D=\{x_i\}_n D={ xi}n中无重复地选择m个间隔句子:
- 随机(Random):均匀随机选择m个句子。
- 开头(Lead):选择前m个句子。
- 重要性(Principal):根据重要性选择得分最高的前 m m m个句子。作为重要性的代理,我们计算句子与文档其余部分之间的ROUGE1-F1分数(Lin, 2004),即 s i = r o u g e ( x i , D ∖ { x i } ) , ∀ i s_i = rouge(x_i, D \setminus \{x_i\}), \forall i si=rouge(xi,D∖{ xi}),∀i。在这种形式下,句子是独立评分的(Ind),并选择得分最高的 m m m个句子。我们还考虑了如Nallapati等人(2017)所提出的顺序选择(Seq)方法,通过贪心算法最大化已选句子 S ∪
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











