







摘要
预训练表示对于许多自然语言处理(NLP)和感知任务正变得至关重要。尽管NLP中的表示学习已经转向无需人工标注的原始文本训练,但视觉和视觉-语言表示仍然严重依赖于经过精心策划的训练数据集,这些数据集成本高昂或需要专业知识。在视觉应用中,表示主要通过使用具有显式类别标签的数据集(如ImageNet或OpenImages)进行学习。对于视觉-语言任务,流行的数据集如Conceptual Captions、MSCOCO或CLIP都涉及复杂的数据收集(和清理)过程。这种高成本的策划过程限制了数据集的规模,从而阻碍了训练模型的扩展。在本文中,我们利用一个包含超过十亿个图像-替代文本对的噪声数据集,这些数据在Conceptual Captions数据集中无需昂贵的过滤或后处理步骤即可获得。一个简单的双编码器架构通过对比损失学习对齐图像和文本对的视觉与语言表示。我们证明了数据集的规模可以弥补其噪声,并且即使采用如此简单的学习方案,也能实现最先进的表示。我们的视觉表示在迁移到分类任务(如ImageNet和VTAB)时表现出色。对齐的视觉和语言表示支持零样本图像分类,并在Flickr30K和MSCOCO图像-文本检索基准测试中取得了新的最先进结果,即使与更复杂的交叉注意力模型相比也是如此。这些表示还支持复杂文本和文本+图像查询的跨模态搜索。
1. 引言
在现有文献中,视觉和视觉-语言表示学习大多使用不同的训练数据源分别进行研究。在视觉领域,通过在大规模监督数据(如ImageNet、OpenImages和JFT-300M)上进行预训练,已被证明对通过迁移学习提高下游任务性能至关重要。这些预训练数据集的策划需要大量的数据收集、采样和人工标注工作,因此难以扩展。
预训练也已成为视觉-语言建模的事实标准方法。然而,视觉-语言预训练数据集(如Conceptual Captions、Visual Genome Dense Captions和ImageBERT)需要更繁重的人工标注、语义解析、清理和平衡工作。因此,这些数据集的规模通常仅在约1000万个样本的范围内。这至少比视觉领域的对应数据集小一个数量级,也比用于NLP预训练的大规模互联网文本语料库小得多。
在本研究中,我们利用一个包含超过十亿个噪声图像-替代文本对的数据集来扩展视觉和视觉-语言表示学习。我们遵循Conceptual Captions数据集中的流程,获得了一个大规模的噪声数据集。但与Conceptual Captions提出的复杂过滤和后处理步骤不同,我们仅应用了基于频率的简单过滤。最终的数据集虽然噪声较多,但其规模比Conceptual Captions数据集大两个数量级。我们展示了在这个超大规模数据集上预训练的视觉和视觉-语言表示在广泛任务中表现出色。
为了训练我们的模型,我们使用了一种目标函数,通过简单的双编码器架构在共享的潜在嵌入空间中对齐视觉和语言表示。类似的目标已被应用于视觉-语义嵌入(VSE)学习。我们将模型命名为ALIGN:大规模图像和噪声文本嵌入。图像和文本编码器通过对比损失(公式化为归一化softmax)进行学习,该损失将匹配的图像-文本对的嵌入推近,同时将不匹配的图像-文本对的嵌入推开。这是自监督和监督表示学习中最有效的损失函数之一。将配对的文本视为图像的细粒度标签,我们的图像-文本对比损失类似于传统的基于标签的分类目标;关键区别在于文本编码器生成“标签”权重。图1左上部分总结了我们在ALIGN中使用的方法。
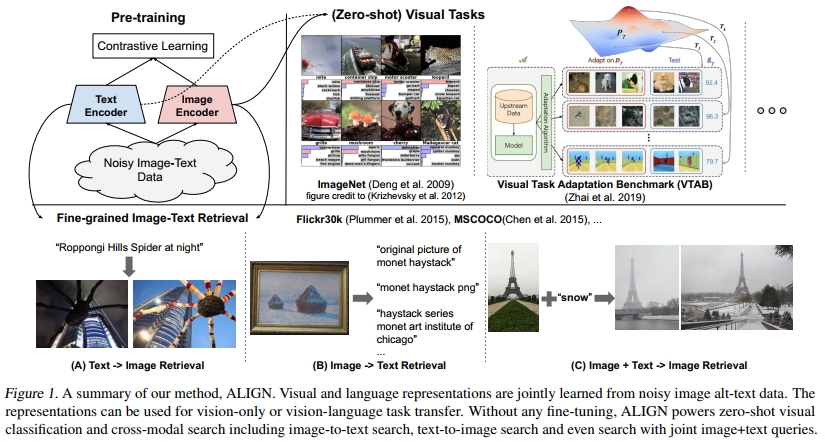
对齐的图像和文本表示天然适合跨模态匹配/检索任务,并在相应的基准测试中取得了最先进(SOTA)的结果。例如,在Flickr30K和MSCOCO数据集上,ALIGN在大多数零样本和微调的R@1指标上比之前的SOTA方法高出7%以上。此外,这种跨模态匹配天然支持零样本图像分类,只需将类别名称输入文本编码器即可实现,在ImageNet上取得了76.4%的top-1准确率,且未使用任何训练样本。图像表示本身在各种下游视觉任务中也表现出色。例如,ALIGN在ImageNet上取得了88.64%的top-1准确率。图1底部展示了由ALIGN构建的真实检索系统中的跨模态检索示例。
2. 相关工作
用于分类或检索的高质量视觉表示通常在大规模标注数据集上进行预训练(Mahajan等,2018;Kolesnikov等,2020;Dosovitskiy等,2021;Juan等,2020)。最近,自监督学习(Chen等,2020b;Tian等,2020;He等,2020;Misra & Maaten,2020;Li等,2021;Grill等,2020;Caron等,2020)和半监督学习(Yalniz等,2019;Xie等,2020;Pham等,2020)作为替代范式被研究。然而,目前通过这些方法训练的模型在下游任务中的迁移能力有限(Zoph等,2020)。
利用图像和自然语言描述是学习视觉表示的另一个方向。Joulin等(2015);Li等(2017);Desai & Johnson(2020);Sariyildiz等(2020);Zhang等(2020)表明,通过从图像预测描述可以学习到良好的视觉表示,这启发了我们的工作。然而,这些工作仅限于小规模数据集(如Flickr和COCO Captions),并且生成的模型无法生成跨模态检索等任务所需的视觉-语言表示。
在视觉-语言表示学习领域,视觉-语义嵌入(VSE)(Frome等,2013;Faghri等,2018)及其改进版本(如利用目标检测器、密集特征图或多注意力层)(Socher等,2014;Karpathy等,2014;Kiros等;Nam等,2017;Li等,2019;Messina等,2020;Chen等,2020a)被提出。最近,更先进的模型通过跨模态注意力层(Liu等,2019a;Lu等,2019;Chen等,2020c;Huang等,2020b)在图像-文本匹配任务中表现出色。然而,它们的速度慢了几个数量级,因此在现实世界的图像-文本检索系统中不实用。相比之下,我们的模型继承了最简单的VSE形式,但在图像-文本匹配基准测试中仍然优于所有之前的交叉注意力模型。
与我们的工作密切相关的是CLIP(Radford等,2021),它提出了在类似的对比学习设置中通过自然语言监督学习视觉表示。除了使用不同的视觉和语言编码器架构外,关键区别在于训练数据:ALIGN遵循原始替代文本数据中图像-文本对的自然分布,而CLIP通过从英文维基百科构建高频视觉概念白名单来收集数据集。我们证明了无需专家知识策划的数据集也可以学习到强大的视觉和视觉-语言表示。
3. 大规模噪声图像-文本数据集
我们工作的重点是扩展视觉和视觉-语言表示学习。为此,我们采用了一个比现有数据集大得多的数据集。具体来说,我们遵循Conceptual Captions数据集(Sharma等,2018)的构建方法,获取了一个原始英文替代文本数据(图像和替代文本对)的版本。Conceptual Captions数据集通过大量过滤和后处理进行了清理。在这里,为了扩展规模,我们通过放宽原始工作中的大部分清理步骤,以质量换取规模。相反,我们仅应用了基于频率的最小过滤,具体如下。结果是一个更大(18亿个图像-文本对)但噪声更多的数据集。图2展示了数据集中的一些示例图像-文本对。

基于图像的过滤
遵循Sharma等人(2018)的方法,我们删除了色情图像,并仅保留较短边大于200像素且宽高比小于3的图像。与超过1000条替代文本相关联的图像被丢弃。为了确保我们不在测试图像上进行训练,我们还删除了所有下游评估数据集(如ILSVRC-2012、Flickr30K和MSCOCO)中测试图像的重复或近似重复项。更多细节请参见附录A。
基于文本的过滤
我们排除了被超过10张图像共享的替代文本。这些替代文本通常与图像内容无关(例如“1920x1080”、“alt img”和“cristina”)。我们还丢弃了包含任何稀有词汇(不在原始数据集中最常见的1亿个单字和双字范围内)的替代文本,以及那些过短(少于3个单字)或过长(超过20个单字)的替代文本。这样可以去除噪声文本,例如“image tid 25&id mggqpuweqdpd&cache 0&lan code 0”,或过于通用而无用的文本。
4. 预训练与任务迁移
##4.1 在噪声图像-文本对上进行预训练
我们使用双编码器架构对ALIGN进行预训练。该模型由一对图像编码器和文本编码器组成,顶部使用余弦相似度组合函数。我们使用带有全局池化的EfficientNet(不训练分类头中的1x1卷积层)作为图像编码器,使用带有[CLS]标记嵌入的BERT作为文本嵌入编码器(我们从训练数据集中生成了10万个词片词汇表)。在BERT编码器顶部添加了一个具有线性激活的全连接层,以匹配图像塔的维度。图像编码器和文本编码器均从头开始训练。
图像和文本编码器通过归一化softmax损失(Zhai & Wu, 2019)进行优化。在训练中,我们将匹配的图像-文本对视为正样本,将训练批次中随机形成的所有其他图像-文本对视为负样本。
我们最小化两种损失的总和:一种是图像到文本分类损失,另一种是文本到图像分类损失。
L
i
2
t
=
−
1
N
∑
i
N
log
exp
(
x
i
⊤
y
i
/
σ
)
∑
j
=
1
N
exp
(
x
i
⊤
y
j
/
σ
)
(
1
)
L_{i2t} = - \frac { 1 } { N } \sum _ { i } ^ { N } \log \frac { \exp ( x _ { i } ^ { \top } y _ { i } / \sigma ) } { \sum _ { j = 1 } ^ { N } \exp ( x _ { i } ^ { \top } y _ { j } / \sigma ) } \qquad \quad ( 1 )
Li2t=−N1i∑Nlog∑j=1Nexp(xi⊤yj/σ)exp(xi⊤yi/σ)(1)
L t 2 i = − 1 N ∑ i N log exp ( y i ⊤ x i / σ ) ∑ j = 1 N exp ( y i ⊤ x j / σ ) ( 2 ) L _ { t 2 i } = - \frac { 1 } { N } \sum _ { i } ^ { N } \log \frac { \exp ( y _ { i } ^ { \top } x _ { i } / \sigma ) } { \sum _ { j = 1 } ^ { N } \exp ( y _ { i } ^ { \top } x _ { j } / \sigma ) } \qquad \quad ( 2 ) Lt2i=−N1i∑Nlog∑j=1Nexp(yi⊤xj/σ)exp(yi⊤xi/σ)(2)
在这里,( x_i ) 和 ( y_j ) 分别是第 ( i ) 对图像和第 ( j ) 对文本的归一化嵌入。( N ) 是批次大小,( \sigma ) 是用于缩放 logits 的温度参数。为了使批次内负样本更有效,我们将所有计算核心的嵌入连接起来以形成一个更大的批次。温度参数至关重要,因为图像和文本嵌入都经过 L2 归一化。我们通过实验发现,温度参数可以与其他参数一起有效地学习,而无需手动调整。
4.2 迁移到图像-文本匹配与检索
我们在图像到文本和文本到图像的检索任务上评估 ALIGN 模型,包括微调和不微调的情况。考虑了两个基准数据集:Flickr30K(Plummer 等,2015)和 MSCOCO(Chen 等,2015)。我们还在 Crisscrossed Captions(CxC)(Parekh 等,2021)上评估 ALIGN,这是 MSCOCO 的扩展版本,包含对描述-描述、图像-图像和图像-描述对的额外人类语义相似性判断。通过扩展的标注,CxC 支持四种模态内和模态间检索任务(图像到文本、文本到图像、文本到文本和图像到图像检索)以及三种语义相似性任务(语义文本相似性 STS、语义图像相似性 SIS 和语义图像-文本相似性 SITS)。由于训练集与原始 MSCOCO 相同,我们可以直接在 CxC 标注上评估微调后的 ALIGN 模型。
4.3 迁移到视觉分类
我们首先将 ALIGN 的零样本迁移应用于 ImageNet ILSVRC-2012 基准(Deng 等,2009)及其变体,包括 ImageNet-R(Hendrycks 等,2020)(非自然图像,如艺术、卡通、素描)、ImageNet-A(Hendrycks 等,2021)(对机器学习模型更具挑战性的图像)和 ImageNet-V2(Recht 等,2019)。所有这些变体都遵循相同的 ImageNet 类别集(或其子集),而 ImageNet-R 和 ImageNet-A 中的图像采样分布与 ImageNet 截然不同。
我们还将图像编码器迁移到下游视觉分类任务中。为此,我们使用 ImageNet 以及一些较小的细粒度分类数据集,如 Oxford Flowers-102(Nilsback & Zisserman,2008)、Oxford-IIIT Pets(Parkhi 等,2012)、Stanford Cars(Krause 等,2013)和 Food101(Bossard 等,2014)。对于 ImageNet,我们报告了两种设置的结果:仅训练顶层分类层(冻结 ALIGN 图像编码器)和完全微调。对于细粒度分类基准,仅报告完全微调的结果。遵循 Kolesnikov 等(2020),我们还在视觉任务适应基准(VTAB)(Zhai 等,2019)上评估模型的鲁棒性,该基准包含 19 个多样化的视觉分类任务(涵盖自然、专业和结构化图像分类任务的子组),每个任务有 1000 个训练样本。
5. 实验与结果
我们从零开始训练 ALIGN 模型,使用开源的 EfficientNet 实现作为图像编码器,BERT 作为文本编码器。除非在消融研究中,否则我们使用图像编码器为 EfficientNet-L2、文本编码器为 BERT-Large 的 ALIGN 结果。无论使用哪种 EfficientNet 变体,图像编码器均在 289×289 像素分辨率下训练。我们首先将输入图像调整为 346×346 分辨率,然后在训练中执行随机裁剪(附加随机水平翻转),在评估中执行中心裁剪。对于 BERT,我们使用最多 64 个词片的序列,因为输入文本不超过 20 个单字。softmax 温度参数初始化为 1.0(该参数在图像到文本损失和文本到图像损失之间共享),并在 softmax 损失中使用 0.1 的标签平滑参数。我们使用 LAMB 优化器(You 等,2020),权重衰减率为 1e-5。学习率在 10k 步内从零线性预热到 1e-3,然后在 1.2M 步(约 12 个 epoch)内线性衰减到零。我们在 1024 个 Cloud TPUv3 核心上训练模型,每个核心有 16 个正样本对,因此总有效批次大小为 16384。
5.1 图像-文本匹配与检索
我们在 Flickr30K 和 MSCOCO 跨模态检索基准上评估 ALIGN,包括零样本和完全微调设置。我们遵循 Karpathy & Fei-Fei(2015)和大多数现有工作来获取训练/测试集划分。具体来说,对于 Flickr30K,我们在标准的 1K 测试集上评估,并在 30k 训练集上微调。对于 MSCOCO,我们在 5K 测试集上评估,并在 82K 训练集加上 30K 额外验证图像(不在 5K 验证集或 5K 测试集中)上微调。 在微调期间,使用相同的损失函数。但当批次大小与训练样本总数相当时,可能会出现假负样本。因此,我们将全局批次大小从 16384 减少到 2048。我们还将初始学习率降低到 1e-5,并在 Flickr30K 和 MSCOCO 上分别训练 3K 和 6K 步(线性衰减)。所有其他超参数与预训练保持一致。
表 1 显示,与之前的工作相比,ALIGN 在 Flickr30K 和 MSCOCO 基准的所有指标上均取得了 SOTA 结果。在零样本设置中,ALIGN 在图像检索任务中比之前的 SOTA(CLIP,Radford 等,2021)提高了 7% 以上。通过微调,ALIGN 大幅优于所有现有方法,包括那些采用更复杂跨模态注意力层的方法,如 ImageBERT(Qi 等,2020)、UNITER(Chen 等,2020c)、ERNIE-ViL(Yu 等,2020)、VILLA(Gan 等,2020)和 Oscar(Li 等,2020)。
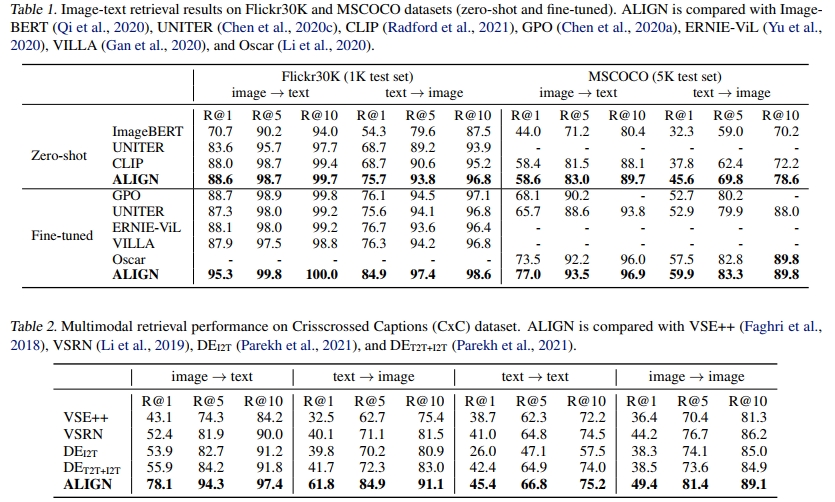
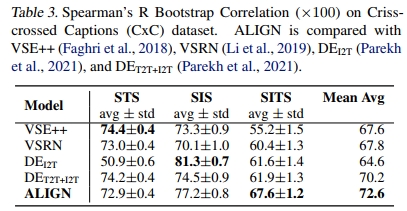
表 2 报告了 ALIGN 在 Crisscrossed Captions(CxC)检索任务中的表现。ALIGN 再次在所有指标上取得了 SOTA 结果,尤其是在图像到文本(+22.2% R@1)和文本到图像(+20.1% R@1)任务上大幅领先。表 3 显示,ALIGN 在 SITS 任务上也优于之前的 SOTA,提高了 5.7%。一个有趣的观察是,尽管在跨模态任务上表现优异,ALIGN 在模态内任务上的表现并不突出。例如,与图像到文本和文本到图像任务相比,文本到文本和图像到图像检索任务(尤其是前者)的改进较小。在 STS 和 SIS 任务上的表现也略逊于 VSE++ 和 DEI2T。我们怀疑这是因为 ALIGN 的训练目标专注于跨模态(图像-文本)匹配,而不是模态内匹配。Parekh 等(2021)建议多任务学习可以产生更平衡的表示。我们将此留待未来研究。
5.2 零样本视觉分类
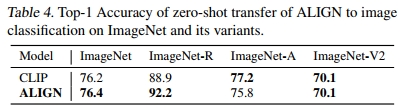
如果我们将类别名称的文本直接输入文本编码器,ALIGN 能够通过图像-文本检索将图像分类到候选类别中。表 4 比较了 ALIGN 和 CLIP 在 ImageNet 及其变体上的表现。与 CLIP 类似,ALIGN 在不同图像分布的分类任务中表现出很强的鲁棒性。为了进行公平比较,我们使用了与 CLIP 相同的提示集成方法。每个类别名称通过 CLIP 定义的一组提示模板进行扩展,例如“一张 {类别名称} 的照片”。类别嵌入通过计算所有模板嵌入的平均值并进行 L2 归一化得到。我们发现,这种集成方法在 ImageNet 的 top-1 准确率上带来了 2.9% 的提升。
5.3 仅使用图像编码器的视觉分类
在 ImageNet 基准测试中,我们首先冻结学习到的视觉特征,仅训练分类头。随后,我们对所有层进行微调。我们使用基本的数据增强方法,包括随机裁剪(与 Szegedy 等(2015)相同)和水平翻转。在评估中,我们应用比例为 0.875 的单一中心裁剪。遵循 Touvron 等(2019)的方法,我们使用训练和评估之间的比例为 0.8,以缓解随机裁剪引入的分辨率差异。具体来说,在冻结视觉特征时,训练/评估分辨率为 289/360;而在微调所有变量时,训练/评估分辨率为 475/600。
在这两个训练阶段中,我们使用全局批次大小为 1024,SGD 优化器动量为 0.9,学习率每 30 个 epoch 衰减一次,衰减比例为 0.2(总共 100 个 epoch)。权重衰减设置为零。在冻结视觉特征时,我们使用初始学习率为 0.1。在微调所有层时,我们使用初始学习率为 0.01,并且主干网络的学习率比分类头小 10 倍。
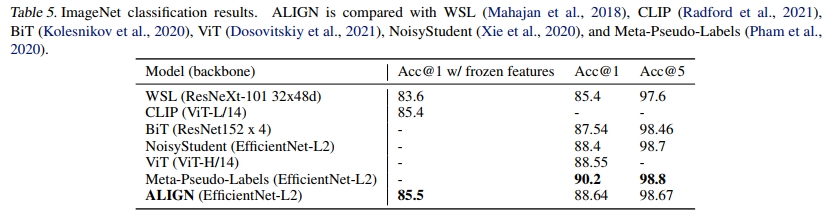
表 5 比较了 ALIGN 与之前的方法在 ImageNet 基准测试中的表现。在冻结特征的情况下,ALIGN 略微优于 CLIP,并取得了 85.5% 的 top-1 准确率的 SOTA 结果。经过微调后,ALIGN 的准确率高于 BiT 和 ViT 模型,仅略逊于需要 ImageNet 训练与大规模未标记数据之间深度交互的 Meta Pseudo Labels。与同样使用 EfficientNet-L2 的 NoisyStudent 和 Meta-Pseudo-Labels 相比,ALIGN 通过使用较小的测试分辨率(600 而不是 800)节省了 44% 的 FLOPS。
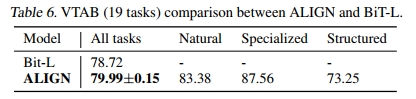
在 VTAB 评估中,我们遵循(Zhai 等,2019)附录 I 中的超参数搜索方法,每个任务进行 50 次试验。每个任务在 800 张图像上进行训练,并使用 200 张图像的验证集选择超参数。搜索完成后,使用选定的超参数在每个任务的 1000 张图像(训练集和验证集的组合)上进行训练。表 6 报告了三次微调运行的平均准确率(包括每个子组的细分结果)及其标准偏差,结果显示 ALIGN 在应用类似的超参数选择方法时优于 BiT-L(Kolesnikov 等,2020)。
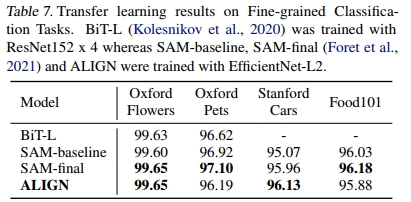
为了在较小的细粒度分类基准上进行评估,我们为所有任务采用了一种简单的微调策略。我们使用与 ImageNet 微调中相同的数据增强和优化器。类似地,我们首先训练分类头,然后微调所有层,但冻结批量归一化统计量。训练/评估分辨率固定为 289/360。我们使用批次大小为 256,权重衰减为 1e-5。初始学习率分别设置为 1e-2 和 1e-3,并在 20k 步内采用余弦学习率衰减。表 7 将 ALIGN 与 BiT-L(Kolesnikov 等,2020)和 SAM(Foret 等,2021)进行了比较,后两者在所有任务中应用了相同的微调超参数。对于这些小任务,微调中的细节非常重要。因此,我们列出了(Foret 等,2021)中未使用 SAM 优化的基线结果,以便进行更公平的比较。我们的结果(三次运行的平均值)与未调整优化算法的 SOTA 结果相当。
6. 消融实验
在消融实验中,我们主要在 MSCOCO 零样本检索和 ImageNet K近邻(KNN)任务上比较模型性能。我们发现这两个指标具有代表性,并且与上述部分中报告的其他指标相关性良好。除非特别说明,消融实验中未调整的超参数均与基线模型保持一致。
6.1 模型架构
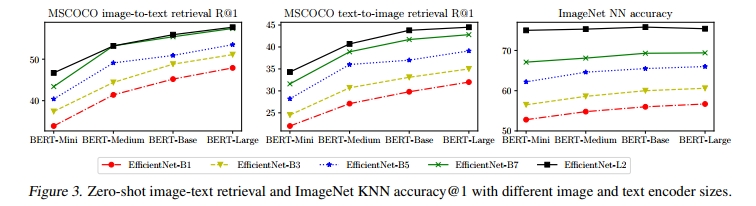
我们首先研究了使用不同图像和文本骨干网络的 ALIGN 模型性能。我们训练了从 EfficientNet-B1 到 L2 的图像编码器,以及从 BERT-Mini 到 BERT-Large 的文本编码器。为了匹配 B7(640)的输出维度,我们在 B1、B3、B5 和 L2 的全局池化特征顶部添加了一个额外的全连接层(线性激活)。类似地,所有文本编码器也添加了一个线性层。为了节省运行时间,我们在消融实验中将训练步数减少到 1M。
图 3 展示了使用不同图像和文本骨干网络组合的 MSCOCO 零样本检索和 ImageNet KNN 结果。随着骨干网络的增大,模型质量显著提升,但 ImageNet KNN 指标在使用 EfficientNet-B7 和 EfficientNet-L2 时,从 BERT-Base 到 BERT-Large 开始趋于饱和。正如预期的那样,对于视觉任务,提升图像编码器容量更为重要(例如,即使使用 BERT-Mini 文本塔,L2 的性能也优于使用 BERT-Large 的 B7)。而在图像-文本检索任务中,图像和文本编码器的容量同等重要。基于图 3 中展示的良好扩展性,我们仅在微调时使用 EfficientNet-L2 + BERT-Large 的模型,如第 5 节所述。
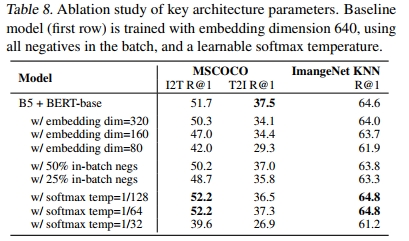
接下来,我们研究了关键架构超参数,包括嵌入维度、批次中随机负样本的数量以及 softmax 温度。表 8 将多个模型变体与基线模型(第一行)进行了比较,基线模型的训练设置如下:EfficientNet-B5 图像编码器、BERT-Base 文本编码器、嵌入维度 640、使用批次中所有负样本,以及可学习的 softmax 温度。
表 8 的第 2-4 行显示,随着嵌入维度的增加,模型性能有所提升。因此,我们让嵌入维度随着更大的 EfficientNet 骨干网络扩展(L2 使用 1376)。第 5 和第 6 行显示,在 softmax 损失中使用较少的批次内负样本(50% 和 25%)会降低性能。第 7-9 行研究了 softmax 损失中温度参数的影响。与学习温度参数的基线模型(收敛至约 1/64)相比,某些手动选择的固定温度可能略优。然而,我们选择使用可学习的温度,因为其性能具有竞争力且使学习过程更简单。我们还注意到,温度通常在前 100k 步迅速下降到收敛值的 1.2 倍左右,然后在训练结束前缓慢收敛。
6.2 预训练数据集
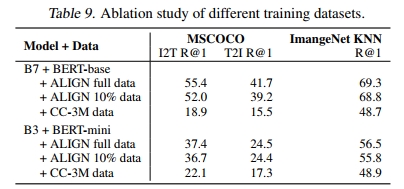
了解模型在不同规模数据集上的表现也很重要。为此,我们在三个不同的数据集上训练了两个模型:EfficientNet-B7 + BERT-base 和 EfficientNet-B3 + BERT-mini。这三个数据集分别是:完整的 ALIGN 训练数据、随机采样的 10% ALIGN 训练数据,以及 Conceptual Captions(CC-3M,约 300 万张图像)。由于 CC-3M 数据集较小,我们将训练步数减少到默认值的 1/10。所有模型均从头开始训练。
如表 9 所示,大规模训练数据集对于扩展模型规模并实现更好的性能至关重要。例如,使用 ALIGN 数据训练的模型明显优于使用 CC-3M 数据训练的模型。在 CC-3M 上,B7 + BERT-base 开始过拟合,表现甚至不如 B3 + BERT-mini。相反,需要更大的模型来充分利用更大的数据集——较小的 B3 + BERT-mini 在 10% ALIGN 数据上几乎达到饱和,而使用更大的 B7 + BERT-base 时,完整 ALIGN 数据带来了明显的性能提升。
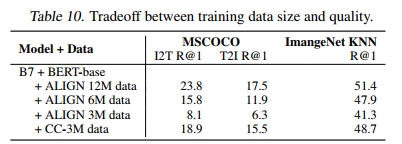
为了更好地理解数据规模的扩展如何抵消噪声增加的影响,我们进一步随机采样了 300 万、600 万和 1200 万条 ALIGN 训练数据,并将它们与经过清理的 CC-3M 数据在 B7 + BERT-base 模型上进行比较。表 10 显示,尽管相同规模(300 万)的 ALIGN 数据表现远不如 CC 数据,但在 600 万和 1200 万条 ALIGN 数据上训练的模型质量迅速提升。尽管存在噪声,ALIGN 数据仅需 4 倍规模即可超越 Conceptual Captions 的表现。
7. 学习嵌入的分析
我们构建了一个简单的图像检索系统,以研究 ALIGN 训练的嵌入行为。为了演示,我们使用了一个包含 1.6 亿张 CC-BY 许可图像的索引,这些图像与我们的训练集无关。图 4 展示了一些在训练数据中不存在的文本查询的 top 1 文本到图像检索结果。ALIGN 能够根据场景的详细描述、细粒度或实例级概念(如地标和艺术品)检索到精确的图像。这些示例表明,我们的 ALIGN 模型能够对齐具有相似语义的图像和文本,并且能够推广到新的复杂概念。

此前,word2vec(Mikolov 等,2013a;b)表明,通过训练词向量来预测句子和段落中的相邻词,词向量之间会出现线性关系。我们展示了在 ALIGN 中,图像和文本嵌入之间也会出现线性关系。我们使用图像+文本的组合查询进行图像检索。具体来说,给定一个查询图像和一个文本字符串,我们将它们的 ALIGN 嵌入相加,并用它来检索相关图像。图 5 展示了多种图像+文本查询的结果。这些示例不仅展示了 ALIGN 嵌入在视觉和语言领域的高度组合性,还展示了“多模态查询搜索”这一新范式的可行性,而这种搜索仅使用文本查询或图像查询是难以实现的。例如,现在可以寻找“澳大利亚”或“马达加斯加”版本的熊猫,或者将一双黑色鞋子变成“米色”的同款鞋子。最后,如图 5 的最后三行所示,通过在嵌入空间中进行减法操作,可以从场景中移除对象或属性。

8. 多语言 ALIGN 模型
ALIGN 的一个优势在于,模型是在经过简单过滤的噪声网络图像文本数据上训练的,且没有任何过滤器是针对特定语言的。鉴于此,我们进一步放宽了 Conceptual Captions 数据处理流程的语言限制,将数据集扩展到多语言(涵盖 100 多种语言),并将其规模与英语数据集(18 亿图像-文本对)相匹配。使用这些数据训练了一个多语言模型 ALIGNmling。我们创建了一个新的多语言词片词汇表,包含 25 万个词,以覆盖所有语言。模型训练完全遵循英语配置。
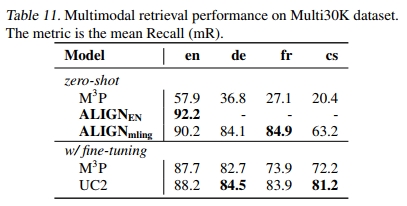
我们在 Multi30k 上测试了多语言模型,这是一个多语言图像文本检索数据集,将 Flickr30K(Plummer 等,2015)扩展到德语(de)(Elliott 等,2016)、法语(fr)(Elliott 等,2017)和捷克语(cs)(Barrault 等,2018)。该数据集包含 31,783 张图像,每张图像有 5 条英语和德语描述,以及 1 条法语和捷克语描述。训练集/开发集/测试集的划分定义见 Young 等(2014)。我们评估了 ALIGN 的零样本模型性能,并将其与 M3P(Huang 等,2020a)和 UC2(Zhou 等,2021)进行了比较。评估指标是平均召回率(mR),它计算图像到文本检索和文本到图像检索任务中 Recall@1、Recall@5 和 Recall@10 的平均得分。
表 11 显示,ALIGNmling 的零样本性能在所有语言上均大幅优于 M3P,其中在法语(fr)上的绝对 mR 提升最大,达到 +57.8。ALIGNmling 的零样本性能甚至与微调(使用训练集)的 M3P 和 UC2 相当,除了捷克语(cs)。在英语(en)上,ALIGNmling 的表现略逊于仅在英语数据上训练的 ALIGNEN。
9. 结论
我们提出了一种简单的方法,利用大规模噪声图像-文本数据来扩展视觉和视觉-语言表示学习。我们的方法避免了繁重的数据整理和标注工作,仅需进行基于频率的最小清理。在该数据集上,我们使用对比损失训练了一个简单的双编码器模型。生成的模型名为 ALIGN,能够进行跨模态检索,并显著优于最先进的 VSE 和跨注意力视觉-语言模型。在纯视觉下游任务中,ALIGN 也优于或与使用大规模标注数据训练的最先进模型相当。
10. 社会影响与未来工作
尽管从方法论的角度来看,这项工作通过简单的数据收集方法展示了有希望的结果,但在实际使用模型之前,还需要对数据和生成的模型进行额外分析。例如,应考虑替代文本中可能存在的有害文本数据是否会加剧这些危害。在公平性方面,可能需要进行数据平衡工作,以防止网络数据中的刻板印象被强化。应对敏感的宗教或文化物品进行额外的测试和训练,以了解并减轻可能错误标注数据的影响。
还需要进一步分析,以确保人类和相关文化物品(如服装、食品和艺术)的人口统计分布不会导致模型性能偏差。如果此类模型将用于生产环境,则需要进行分析和平衡。
最后,应禁止将此类模型用于监视或其他恶意目的的意外滥用。
附录 A:从训练数据中移除近似重复的测试图像
为了检测近似重复的图像,我们首先按照(Wang 等,2014)的方法训练一个高质量图像嵌入模型,并使用(Juan 等,2020)中的大规模标注数据集。然后,基于嵌入模型的所有训练图像,通过 k-means 生成 4K 个聚类。对于每个查询图像(来自 ALIGN 数据集)和索引图像(来自下游任务的测试集),我们根据嵌入距离找到它们的 top-10 最近聚类。然后将每张图像分配到 10 个 3 元组桶中(从 10 个聚类中任意选择 3 个的所有可能组合)。对于落入同一桶的任何查询-索引图像对,如果它们的嵌入余弦相似度大于 0.975,我们将其标记为近似重复。该阈值是在一个大规模数据集上训练的,该数据集由人工评分数据和随机增强生成的合成数据构建。
附录 B:在 SimLex-999 上的评估
图像-文本联合训练也可能有助于自然语言理解,如 Kiros 等(2018)所示。例如,仅使用语言数据很难学习反义词。为了测试 ALIGN 模型的这一能力,我们还在 SimLex-999(Hill 等,2015)上评估了 ALIGN 模型的词表示。SimLex-999 是一个比较 999 对词相似性的任务。我们按照 Kiros 等(2018)的方法,报告了 9 个子任务的结果,每个子任务包含一个词对子集:全部、形容词、名词、动词、具体性四分位数(1-4)和困难词对。
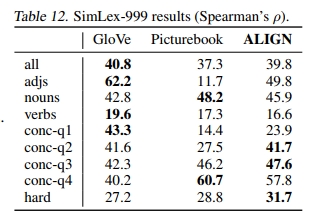
结果列于表 12 中,并与 Picturebook(Kiros 等,2018)和 GloVe(Pennington 等,2014)嵌入进行了比较。总体而言,学习到的 ALIGN 嵌入表现优于 Picturebook,但略逊于 GloVe 嵌入。有趣的是,ALIGN 词嵌入与 Picturebook 嵌入有相似的趋势,在名词和大多数具体类别上表现更好,但在形容词和较少具体类别上表现不如 GloVe 嵌入。ALIGN 词嵌入在困难类别上表现最佳,这些类别的相似性难以与相关性区分开来。这一观察结果验证了 Kiros 等(2018)的假设,即基于图像的词嵌入比基于文本分布的方法更不容易混淆相似性与相关性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











