







摘要
语言模型的预训练已经带来了显著的性能提升,但不同方法之间的仔细比较仍然具有挑战性。训练过程计算量大,通常使用不同规模的私有数据集进行训练。此外,正如我们将展示的,超参数选择对最终结果具有显著影响。我们对 BERT 预训练(Devlin 等,2019)进行了一项复现研究,系统地衡量了多个关键超参数和训练数据规模的影响。研究发现,BERT 训练不足,并且在适当优化后可以匹敌或超越其后发布的所有模型。我们的最佳模型在 GLUE、RACE 和 SQuAD 上达到了最新的最优性能。这些结果强调了之前被忽视的设计选择的重要性,并引发了对近期报告的改进来源的质疑。我们公开了我们的模型和代码。
1 引言
自训练方法,如 ELMo(Peters 等,2018)、GPT(Radford 等,2018)、BERT(Devlin 等,2019)、XLM(Lample 和 Conneau,2019)和 XLNet(Yang 等,2019)等,已带来了显著的性能提升。然而,确定这些方法中哪些因素最为关键仍然是一个挑战。训练计算成本高,这限制了可进行的超参数调整数量,并且训练通常使用不同规模的私有数据,进一步限制了我们评估建模改进影响的能力。
本研究对 BERT 预训练(Devlin 等,2019)进行复现,并仔细评估了超参数调整和训练集规模的影响。我们发现,BERT 训练不足,并提出了一种改进的 BERT 训练方法,我们称之为 RoBERTa。RoBERTa 的训练方法能够匹敌或超越所有后续提出的模型。我们的改进包括:
- 训练更长时间,使用更大的批次,并覆盖更多数据;
- 移除“下一句预测”(Next Sentence Prediction, NSP)目标;
- 训练时使用更长的输入序列;
- 训练过程中动态改变掩码模式(masking pattern)。
此外,我们收集了一个全新的大规模数据集 CC-NEWS,其规模可与其他私有数据集相媲美,以更好地控制训练数据规模对模型的影响。
在相同的训练数据规模下,我们的改进训练方案使 BERT 在 GLUE 和 SQuAD 上的表现优于原始 BERT 结果。进一步延长训练时间并增加训练数据后,我们的模型在 GLUE 公共排行榜上取得了88.5的分数,与 Yang 等(2019)报告的 88.4 相当。我们的模型在GLUE 任务中的 9 个子任务中有 4 个(MNLI、QNLI、RTE 和 STS-B)达到了最新的最优性能,并且在 SQuAD 和 RACE 任务上也达到了最先进水平。
总体而言,我们重新验证了 BERT 的掩码语言模型(Masked Language Model, MLM)目标的有效性,并证明其训练方式在正确的设计选择下,依然能与最近提出的其他预训练方法(如 XLNet 的扰动自回归语言建模)竞争。
主要贡献:
- 揭示 BERT 训练中的关键设计选择**,提出改进方案,使其在下游任务上表现更优;
- 引入新的 CC-NEWS 数据集,并确认使用更多数据进行预训练可以进一步提高模型在下游任务中的表现;
- 改进的训练方法证明,在正确的设计下,掩码语言模型(MLM)预训练依然具备竞争力,可与所有近期发布的方法匹敌。
2 背景
本节简要介绍BERT 预训练方法(Devlin 等,2019),并探讨我们将在后续实验部分分析的训练选择。
2.1 设定
BERT 的输入是两个片段(即一系列标记)的拼接,分别表示为 x 1 , … , … , x N 和 y 1 , … , M y 1 , … , y M x1,…,\ldots , x_N 和 y1,…,My_1, \dots , y_M x1,…,…,xN和y1,…,My1,…,yM。这些片段通常由多个自然句子组成。这两个片段以单个输入序列的形式提供给 BERT,并使用特殊标记进行分隔: [ C L S ] , x 1 , . . . , x N , [ S E P ] , y 1 , . . . , y M , [ E O S ] [CLS], x_1, ..., x_N, [SEP], y_1, ..., y_M, [EOS] [CLS],x1,...,xN,[SEP],y1,...,yM,[EOS]。其中,MM 和 NN 需要满足 M + N < T M + N < T M+N<TM + N < T M+N<TM+N<T,其中 TT是控制训练时最大序列长度的参数。
模型首先在大规模无标注文本语料库上进行预训练,然后在有标注的终端任务数据上进行微调。
2.2 结构
BERT 采用了目前广泛使用的 Transformer 结构(Vaswani 等,2017),这里不再详细介绍。我们使用具有 LL 层的 Transformer 结构,每个块包含 AA个自注意力(self-attention)头,并且隐藏层维度为 HH。
2.3 训练目标
在预训练过程中,BERT 采用了两个训练目标:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。
掩码语言模型(MLM)
在输入序列中,随机选择部分标记并用特殊标记[MASK] 替换。MLM 目标是对这些被掩码的标记进行预测,并使用交叉熵损失进行优化。BERT 以均匀采样的方式选择 15% 的输入标记作为可能的替换对象。在这些被选中的标记中:
- 80% 被替换为 [MASK];
- 10%维持原样,不做修改;
- 10% 替换为从词汇表中随机选择的标记。
在最初的实现中,随机掩码和替换操作仅在训练开始时执行一次,并在整个训练过程中保持不变。但在实际操作中,数据会被重复使用,因此对于每个训练句子,掩码模式并不总是相同(详见 4.1 节)。
下一句预测(NSP)
NSP 任务是一个二分类任务,用于预测两个片段是否在原始文本中相邻。
- 正样本:从文本语料库中选取连续的句子对;
- 负样本:从不同的文档中配对片段;
- 正负样本的采样概率相等。
NSP 目标的设计旨在提升 BERT 在下游任务(例如自然语言推理(Natural Language Inference, NLI))上的表现,这类任务需要推理句子对之间的关系(Bowman 等,2015)。
2.4 优化方法
BERT采用Adam优化器(Kingma和Ba,2015)进行训练,参数设置如下: β 1 = 0.9 \beta_1 = 0.9 β1=0.9, β 2 = 0.999 \beta_2 = 0.999 β2=0.999, ϵ = 1 e − 6 \epsilon = 1\mathrm{e}{-6} ϵ=1e−6,并应用 L 2 L_2 L2权重衰减(衰减系数为0.01)。学习率在前10,000步训练中线性预热至峰值1e-4,之后线性衰减。所有层和注意力权重均采用0.1的dropout率,激活函数为GELU(Hendrycks和Gimpel,2016)。模型预训练总步数 S = 1 , 000 , 000 S = 1,000,000 S=1,000,000,每批次包含 B = 256 B = 256 B=256条序列,每条序列最大长度 T = 512 T = 512 T=512个词元。
2.5 训练数据
BERT的训练数据来源于BookCorpus(Zhu等,2015)和英文维基百科的混合语料,未压缩文本总量为16GB。
3 实验设置
本节详述我们对BERT复现研究的实验配置。
3.1 实现细节
我们在FAIRSEQ框架(Ott等,2019)中重新实现了BERT。除峰值学习率和预热步数需针对不同场景单独调优外,其余优化超参数(如第2节所述)均遵循原始BERT设定。实验发现:
- 训练过程对Adam优化器的 ϵ \epsilon ϵ项极为敏感,调整该参数可提升性能或稳定性;
- 大批量训练时,设定 β 2 = 0.98 \beta_2=0.98 β2=0.98有助于增强稳定性。
我们采用最大长度 T = 512 T=512 T=512词元的序列进行预训练。与Devlin等(2019)不同,我们:
- 不随机注入短序列;
- 不在前90%训练步数中使用缩短序列;
- 全程使用完整长度序列训练。
训练基于DGX-1服务器,配备8块32GB Nvidia V100 GPU(通过InfiniBand互联),采用混合精度浮点运算(Micikevicius等,2018)。
3.2 训练数据
BERT式预训练高度依赖大规模文本。Baevski等(2019)证明增加数据量能提升下游任务表现。虽然部分扩展数据集(如Radford等2019;Yang等2019;Zellers等2019)未公开,我们仍尽可能收集多领域数据,确保实验数据规模与质量可比。
使用的五大英语语料库(总计超160GB未压缩文本)包括:
- BOOKCORPUS+英文维基百科:原始BERT训练数据(16GB)
- CC-NEWS:从CommonCrawl新闻数据集英语部分爬取(2016年9月至2019年2月间的6300万篇新闻,过滤后76GB)
- OPENWEBTEXT:Radford等(2019)WebText语料的开源复现(Reddit高赞帖文链接提取内容,38GB)
- STORIES:经Winograd模式筛选的CommonCrawl故事类文本(31GB)
3.3 评估方法
沿用既有研究,我们在三大基准测试中评估预训练模型:
GLUE
通用语言理解评估基准(Wang等2019b)包含9个自然语言理解数据集,任务分为单句分类或句对分类。我们:
- 在第4节复现研究中,报告单任务微调后的开发集结果(未使用多任务训练或模型集成);
- 在第5节补充公开排行榜的测试集结果(需任务特定改进,详见5.1节)。
SQuAD
斯坦福问答数据集要求从给定段落中提取答案。评估两个版本:
- V1.1:段落必含答案,采用BERT原始跨度预测法;
- V2.0:增加二分类器判断问题是否可答,训练时联合优化分类与跨度损失。
RACE
中国英语考试阅读理解数据集(Lai等2017)含2.8万篇章和近10万问题,特点包括:
- 上下文长度显著长于其他数据集;
- 多数问题需推理作答;
- 每篇文本对应多道四选一题目。
4 训练过程分析
本节通过量化实验探究BERT预训练成功的关键因素(模型架构保持固定)。我们以BERTBASE配置(L=12层,H=768隐藏维度,A=12注意力头,1.1亿参数)为基准展开研究。
4.1 静态掩码 vs 动态掩码
如第2节所述,BERT通过随机掩码和预测词元进行训练。原始BERT实现采用静态掩码:
- 在数据预处理阶段一次性生成掩码模式;
- 为避免每轮epoch重复使用相同掩码,训练数据被复制10份(每序列对应10种不同掩码);
- 在40轮训练中,每个序列会以相同掩码出现4次。
我们对比了动态掩码策略——每次向模型输入序列时实时生成新掩码模式。当预训练步数增加或数据集规模扩大时,动态掩码的优势尤为显著。
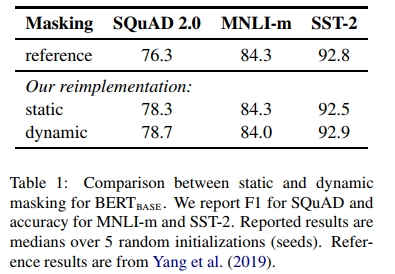
表1结果对比了Devlin等人(2019)发布的BERTBASE结果与我们的两种复现方案(静态掩码和动态掩码)。我们发现采用静态掩码的复现结果与原始BERT模型表现相当,而动态掩码则与静态掩码效果相近或略优。基于这些结果以及动态掩码在效率上的优势,后续实验均采用动态掩码策略。
4.2 模型输入格式与下一句预测
原始BERT预训练过程中,模型接收两个拼接的文档片段作为输入:这些片段有50%概率(p=0.5)来自同一文档的连续部分,50%概率来自不同文档。除掩码语言建模目标外,模型还通过辅助的下一句预测(NSP)损失函数来学习判断这两个片段是否源自同一文档。
NSP损失曾被假设为原始BERT训练的关键因素。Devlin等人(2019)发现移除NSP会损害模型性能,特别是在QNLI、MNLI和SQuAD 1.1任务上表现显著下降。但近期研究(Lample和Conneau,2019;Yang等人,2019;Joshi等人,2019)对NSP的必要性提出了质疑。
为深入理解这一分歧,我们比较了以下替代训练格式:
• 片段对+NSP:遵循BERT原始输入格式(Devlin等人,2019),保留NSP损失。每个输入包含一对片段(每段可含多个自然句子),但组合长度不超过512 tokens。
• 句子对+NSP:每个输入包含一对自然句子(可能来自同一文档的连续部分或不同文档)。由于这类输入远短于512 tokens,我们通过增大批次规模来保持总token量与片段对+NSP相当,同时保留NSP损失。
• 全句子模式:每个输入由连续采样的完整句子组成(可跨文档边界),总长度不超过512 tokens。当某文档采样结束时,从下一文档继续采样并添加分隔符。此模式移除NSP损失。
• 文档句子模式:构造方式类似全句子模式,但禁止跨文档采样。当文档末尾的输入不足512 tokens时,动态增加批次规模以保持总token量相当。此模式同样移除NSP损失。
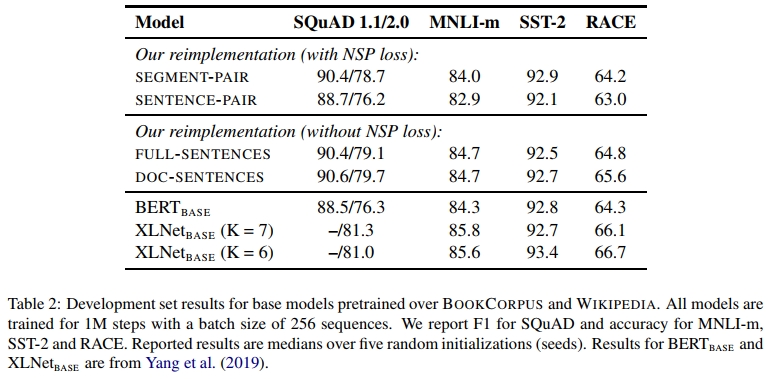
表2结果显示四种设置的对比:
- 句子对vs片段对:保留NSP时,使用单句子会损害下游任务性能(可能因模型难以学习长程依赖);
- 移除NSP的影响:采用文档内文本块(DOC-SENTENCES)训练时,性能超越原始BERTBASE,且移除NSP损失能使下游任务表现持平或微升——这与Devlin等人(2019)的结论相反,可能因其仅移除损失项却保留片段对输入格式;
- 跨文档对比:单文档序列(DOC-SENTENCES)略优于多文档混合(FULL-SENTENCES),但因前者导致批次规模动态变化,后续实验为便于对比采用全句子模式。
4.3 大批量训练
神经机器翻译领域已证实:适当提高学习率时,大批量训练可加速优化并提升最终性能(Ott等,2018)。近期研究也表明BERT适合大批量训练(You等,2019)。
原始BERTBASE采用256序列/批次的规模训练100万步。通过梯度累积计算等效方案:
- 2K序列/批次 ⇨ 12.5万步
- 8K序列/批次 ⇨ 3.1万步
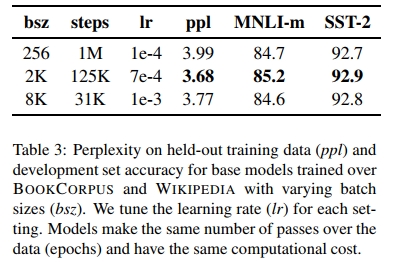
表3显示:增大批次规模时,掩码语言建模的困惑度与下游任务准确率同步提升。大批量还更利于分布式数据并行训练,故后续实验采用8K序列/批次的配置。
4.4 文本编码
字节对编码(BPE)(Sennrich等,2016)作为字符级与词级表示的混合体,能有效处理自然语言语料中的大规模词汇表。BPE不依赖完整单词,而是基于对训练语料统计分析得到的子词单元。
传统BPE词汇表规模通常为1万-10万子词单元。但在处理多样化语料时,Unicode字符可能占据词汇表大部分空间。Radford等(2019)提出创新方案:以字节(而非Unicode字符)作为基础子词单元,仅需5万子词单元即可无损编码所有文本。原始BERT(Devlin等,2019)采用3万规模的字符级BPE词汇表,且需启发式分词预处理。
我们实验发现:
- 采用Radford等(2019)的字节级BPE(5万子词单元)仅导致部分任务性能微降
- 该方案使BERTBASE和BERTLARGE分别增加约1500万/2000万参数
- 通用编码优势超越轻微性能损失,故后续实验采用此方案
5 RoBERTa模型
在前文章节中,我们提出了改进BERT预训练流程的若干方法以提升最终任务性能。现将这些改进方案整合并评估其综合效果,将该配置命名为RoBERTa(鲁棒优化的BERT方法)。具体而言,RoBERTa采用以下配置:
- 动态掩码(4.1节)
- 无NSP损失的全句子模式(4.2节)
- 大批次训练(4.3节)
- 更大规模的字节级BPE编码(4.4节)
此外,我们还探究了先前工作中未被充分重视的两个关键因素:
- 预训练数据量
- 数据训练遍历次数
例如,新近提出的XLNet架构(Yang等,2019)使用的预训练数据量达到原始BERT(Devlin等,2019)的近10倍。其训练批次大小扩大8倍,优化步数减半,因此预训练阶段处理的序列总量是BERT的4倍。
为厘清这些因素与其他建模选择(如预训练目标函数)的相对重要性,我们首先基于BERTLARGE架构(L=24层,H=1024隐藏维,A=16注意力头,3.55亿参数)训练RoBERTa。使用与Devlin等(2019)相当的BOOKCORPUS+维基百科数据集进行10万步预训练,在1024块V100 GPU上耗时约1天完成。
实验结果
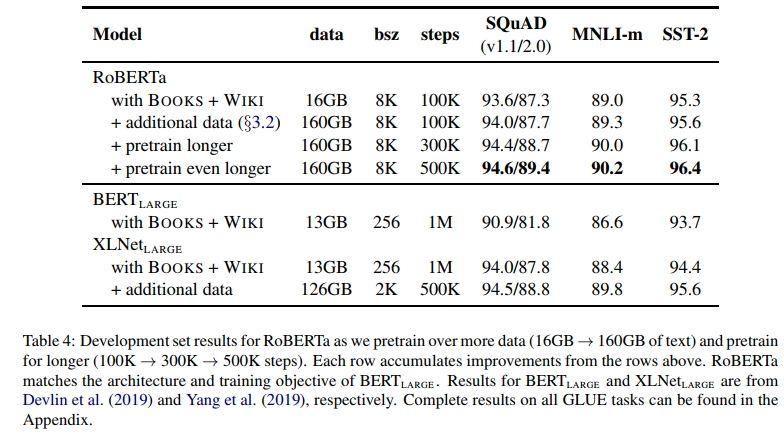
表4展示了我们的实验结果:
-
数据量控制实验
在相同训练数据条件下,RoBERTa相比原始报告的BERTLARGE结果有显著提升,这验证了第4节所探讨的设计选择的重要性。 -
多数据集联合训练
将3.2节所述的三个新增数据集与原始数据结合(总计160GB文本),保持10万步训练不变。实验结果显示所有下游任务性能均得到进一步提升,证实了预训练数据规模与多样性的关键作用。 -
延长训练步数实验
将预训练步数从10万逐步增加至30万,最终到50万步。结果表明:
- 下游任务性能持续显著提升
- 30万步和50万步模型在多数任务上超越XLNetLARGE
- 即使最长训练模型也未出现过拟合,表明进一步训练仍可能带来增益
后续评估方案
本文后续将基于最优配置的RoBERTa模型(使用3.2节全部五个数据集训练50万步)在三大基准测试上进行评估:
- GLUE
- SQuAD
- RACE
5.1 GLUE 结果
在 GLUE 任务中,我们考虑两种微调设置。
在第一种设置(单任务,验证集)中,我们对 RoBERTa 进行单独微调,使其适应 GLUE 中的各个任务,仅使用对应任务的训练数据。针对每个任务,我们执行有限的超参数搜索,具体如下:
- 批量大小选取自 {16, 32};
- 学习率选取自 1 e − 5 , 2 e − 5 , 3 e − 5 {1e-5, 2e-5, 3e-5} 1e−5,2e−5,3e−5;
- 训练前 6%的步长采用线性预热,之后进行线性衰减至 0;
- 微调 10 轮,并根据验证集上的评估指标进行提前停止。
其余超参数保持与预训练时一致。在此设置下,我们在 5 次不同的随机初始化上计算每个任务的中位数开发集结果,并且不进行模型集成。
在第二种设置(集成,测试集)中,我们通过 GLUE 排行榜对比 RoBERTa 与其他方法的表现。虽然许多 GLUE 排行榜的提交依赖于多任务微调,但我们的提交仅基于单任务微调。在RTE、STS 和 MRPC 任务上,我们发现从 MNLI 的单任务微调模型出发比直接使用 RoBERTa 预训练模型效果更好。此外,我们在附录中描述了略微扩展的超参数搜索范围,并在每个任务上集成 5 到 7 个模型进行测试集评估。
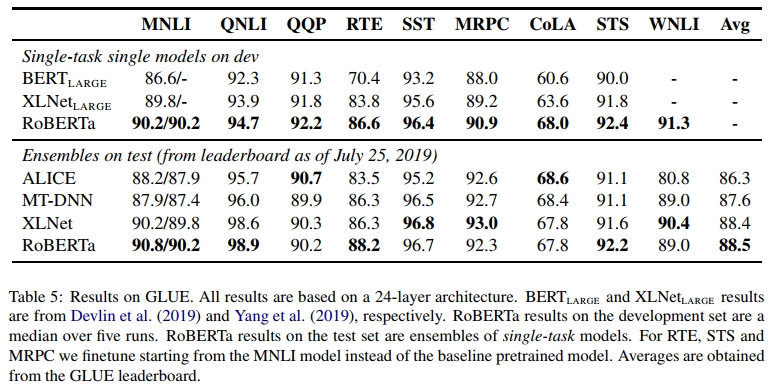
任务特定的修改 GLUE 任务中有两个任务需要特定的微调方法,以在排行榜上获得具有竞争力的结果。
QNLI:最近的 GLUE 排行榜提交采用了一种成对排序(pairwise ranking)的形式来处理 QNLI 任务,其中候选答案从训练集中挖掘出来并相互比较,每个(问题,候选答案)对被分类为正例(Liu et al., 2019b,a; Yang et al., 2019)。这种方法大大简化了任务,但无法与 BERT(Devlin et al., 2019)直接比较。借鉴最近的研究,我们在测试集提交中采用了排序方法,但为了与 BERT 直接对比,我们在开发集上使用纯分类方法进行评估。
WNLI:我们发现提供的 NLI 格式数据很难处理。因此,我们使用 SuperGLUE(Wang et al., 2019a)中重新格式化的 WNLI 数据,该数据指明了查询代词和指代的跨度。我们使用 Kocijan et al.(2019)提出的边际排序损失(margin ranking loss)对 RoBERTa 进行微调。对于给定的输入句子,我们使用 spaCy(Honnibal and Montani, 2017)从句子中提取额外的候选名词短语,并微调模型,使其对正确指代短语的评分高于任何生成的错误候选短语。这种方法的一个不幸后果是,我们只能使用正例训练数据,这导致无法使用超过一半的提供训练样本。
结果 我们在表 5 中展示了实验结果。
在第一种设置(单任务,验证集)中,RoBERTa 在 GLUE 的 9 个任务的开发集上均达到了最先进(state-of-the-art)的结果。至关重要的是,RoBERTa 使用与 BERTLARGE 相同的掩码语言建模(MLM)预训练目标和相同的架构,但始终优于 BERTLARGE 和 XLNetLARGE。这引发了一个问题,即相较于模型架构和预训练目标,数据集规模和训练时长等常规因素是否更加重要,这正是我们在本研究中探讨的内容。
在第二种设置(集成,测试集)中,我们将 RoBERTa 提交到 GLUE 排行榜,并在 9 个任务中的 4 个上取得最先进的结果,同时达到了迄今为止最高的平均分。这尤其令人兴奋,因为 RoBERTa 不依赖于多任务微调,而大多数其他排名靠前的提交方案都依赖多任务微调。我们预计未来的研究可以通过更复杂的多任务微调进一步提升这些结果。
5.2 SQuAD 结果
对于 SQuAD,我们采用了比以往研究更简单的方法。特别是,BERT(Devlin et al., 2019)和 XLNet(Yang et al., 2019)都使用了额外的问答(QA)数据集来扩充训练数据,而我们仅使用提供的 SQuAD 训练数据对 RoBERTa 进行微调。Yang et al.(2019)还采用了自定义的分层学习率调度(layer-wise learning rate schedule)来微调 XLNet,而我们对所有层使用相同的学习率。
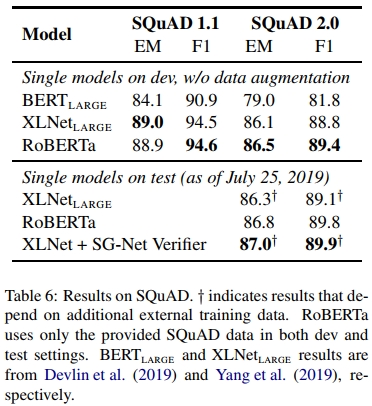
对于 SQuAD v1.1,我们遵循与 Devlin 等人(2019)相同的微调流程。对于 SQuAD v2.0,我们额外分类某个问题是否可回答;我们通过对分类损失和 span 预测损失求和来联合训练该分类器与 span 预测器。
结果 我们在表 6 中展示了实验结果。在 SQuAD v1.1 开发集上,RoBERTa 达到了与 XLNet 相同的最先进水平。在 SQuAD v2.0 开发集上,RoBERTa 刷新了最先进的结果,相较于 XLNet,EM 分数提高了 0.4,F1 分数提高了 0.6。
我们还将 RoBERTa 提交至 SQuAD 2.0 公开排行榜,并评估其相对于其他系统的表现。大多数排名靠前的系统都基于 BERT(Devlin 等人,2019)或 XLNet(Yang 等人,2019),它们都依赖额外的外部训练数据。而我们的提交未使用任何额外数据。我们的单模型 RoBERTa 在所有单模型提交中仅次于一个系统,并且在不依赖数据增强的系统中排名最高。
5.3 RACE 结果
在 RACE 任务中,系统会被提供一段文本、一道相关的问题,以及四个候选答案。系统需要判断这四个候选答案中哪个是正确的。
我们针对该任务调整了 RoBERTa,使其将每个候选答案与相应的问题和文本拼接在一起。然后,我们对这四个拼接后的序列进行编码,并将得到的 [CLS] 表示输入全连接层,该层用于预测正确答案。对于超过 128 个 token 的问题-答案对,我们进行截断;如果仍然超长,我们再截断文本部分,使得总长度最多为 512 个 token。
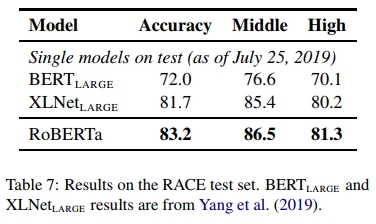
RACE 测试集的结果展示在表 7 中。RoBERTa 在初中和高中数据集上均达到了最先进的结果。
6 相关工作
不同的预训练方法采用了不同的训练目标,包括语言建模(Dai 和 Le,2015;Peters 等人,2018;Howard 和 Ruder,2018)、机器翻译(McCann 等人,2017)以及掩码语言建模(Devlin 等人,2019;Lample 和 Conneau,2019)。
许多最近的论文都采用了一种基础策略,即为每个下游任务微调模型(Howard 和 Ruder,2018;Radford 等人,2018),并使用某种变体的掩码语言建模目标进行预训练。然而,较新的方法通过多任务微调(Dong 等人,2019)、整合实体嵌入(Sun 等人,2019)、span 预测(Joshi 等人,2019)以及多种自回归预训练方法(Song 等人,2019;Chan 等人,2019;Yang 等人,2019)来提升性能。此外,通常通过在更多数据上训练更大的模型,也可以提升性能(Devlin 等人,2019;Baevski 等人,2019;Yang 等人,2019;Radford 等人,2019)。
我们的目标是复现、简化并更好地调整 BERT 的训练,以此作为参考点,以更好地理解所有这些方法的相对性能。
7 结论
我们在预训练 BERT 模型时,仔细评估了多种设计决策。我们发现,通过更长时间的训练、使用更大的批量、更大规模的数据、移除下一句预测(NSP)目标、训练更长的序列,以及动态改变应用于训练数据的掩码模式,可以显著提高模型性能。
我们提出的改进预训练方法 RoBERTa,在 GLUE、RACE 和 SQuAD 任务上均取得了最先进的结果,同时在 GLUE 任务上不依赖多任务微调,在 SQuAD 任务上不使用额外数据。这些结果表明,以往被忽视的设计决策对性能至关重要,并且 BERT 的预训练目标仍然能够与最新提出的替代方法竞争。
此外,我们使用了一个新数据集 CC-NEWS,并开源了我们的模型和用于预训练及微调的代码,网址为:
https://github.com/pytorch/fairseq
附录:《RoBERTa: 一种经过稳健优化的 BERT 预训练方法》
A GLUE 的完整结果
在表 8 中,我们展示了 RoBERTa 在 GLUE 任务上的完整开发集结果。我们分别列出了遵循 BERTLARGE 配置的 LARGE 版本,以及遵循 BERTBASE 配置的 BASE 版本的结果。
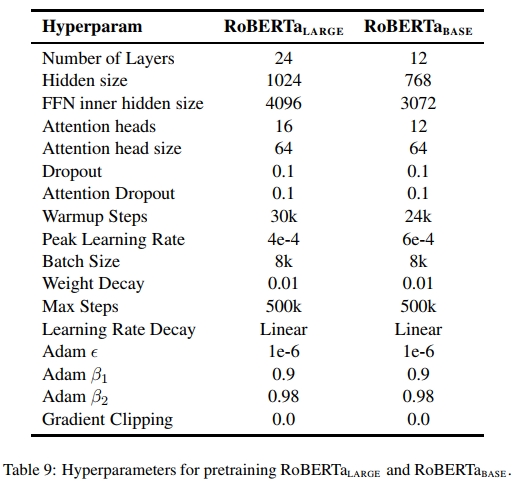
B 预训练超参数
表 9 描述了 RoBERTaLARGE 和 RoBERTaBASE 的预训练超参数。
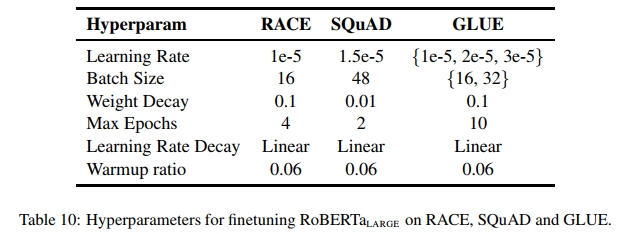
C 微调超参数
表 10 给出了 RACE、SQuAD 和 GLUE 的微调超参数。我们根据每个任务 5 个随机种子的中位数选择最佳超参数值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











