







摘要
流行音乐的钢琴改编深受许多人的喜爱。然而,自动生成流行音乐钢琴改编的任务仍然研究不足。这在一定程度上是由于缺乏同步的流行音乐与钢琴改编(Pop, Piano Cover)数据对,这使得应用最新的数据密集型深度学习方法变得具有挑战性。为了利用数据驱动方法的优势,我们使用自动化流程构建了大量配对且同步的流行音乐与钢琴改编(Pop, Piano Cover)数据。在本文中,我们提出了 Pop2Piano,一种基于 transformer 的网络,其输入为流行音乐的波形,输出为钢琴改编。据我们所知,这是第一个不依赖旋律与和弦提取模块、直接从流行音乐音频生成钢琴改编的模型。我们展示了使用我们构建的数据集训练的 Pop2Piano 模型,能够生成可信的钢琴改编作品。
关键词——钢琴改编、音乐编配、transformer、音乐同步
1. 引言
钢琴改编是指将现有歌曲中的所有音乐元素重新创作或编排为钢琴演奏形式的音乐作品。流行音乐的钢琴改编是被广泛喜爱的一种音乐形式。例如,人们在音乐教育中使用它,而钢琴改编创作者在 Youtube 等平台上拥有数百万的订阅者。
为了让人类创作钢琴改编,需要从原始音频中识别出所有的音乐元素,例如旋律、和弦或情绪,并将其重新诠释为符合音乐性的钢琴演奏。因此,即使对人类而言,制作钢琴改编也不是一件容易的事情,因为它是一个创意性的任务,并且需要具备音乐知识。
以往的研究集中于将流行音频编排为其他乐器[1, 2],使用多个外部模块提取显式的音乐信息,如旋律与和弦。然而,制作钢琴改编还涉及各种隐性的音乐特征,例如音乐的氛围和编曲者的风格。因此,我们认为,研究音频与钢琴改编之间的端到端转换也是有价值的。
与此同时,深度学习在建模高维度音乐音频数据方面展现出卓越的性能。然而,据我们所知,目前尚无直接使用流行音乐波形进行钢琴改编建模的深度学习研究。这可能是由于缺乏用于此类建模的大量同步配对数据所致。
在本研究中,我们引入了一种基于 transformer 的钢琴改编生成模型,名为 Pop2Piano,它从流行音乐的波形中生成钢琴演奏(MIDI)。我们的贡献总结如下:
- 我们提出了一种新颖的钢琴改编生成方法。为此,我们构建了一个包含 300 小时同步 Pop 与 Piano Cover 的数据集,命名为 Piano Cover Synchronized to Pop Audio(PSP),并介绍了用于构建该数据集的预处理系统。
- 我们设计了 Pop2Piano,这是一种 transformer 网络,其输入为音频而非旋律或和弦提取器,而是直接使用频谱图作为输入。该模型还通过 arranger token 控制改编风格。
- 我们上传了用于复现 PSP 数据集的数据清单与预处理代码,并在 Colab 上发布了可执行的 Pop2Piano 演示程序。
2. 相关工作
2.1 自动音乐转录
自动音乐转录(Automatic Music Transcription,AMT)是从乐器音频波形中估计音符信息的任务。在钢琴 AMT 领域,一些研究使用 CNN 和 RNN 架构来提取特征并建模音符的起始、结束及帧信息[3, 4, 5]。也有研究使用 transformer 模型和频谱图来生成 MIDI[6, 7]。多乐器 AMT 的目标是从多种乐器混合的音频中分别估计每种乐器的音符信息。Cerberus[8] 和 MT3[7] 是这类研究的两个例子,分别采用了 RNN 和 transformer 模型。
这些研究在使用大量同步的乐器-音频数据集(如 MAESTRO[9] 和 Slakh2100[10])时取得了有前景的结果。为了训练钢琴改编生成模型,我们构建了一个包含 300 小时同步钢琴改编的数据集。尽管 AMT 与钢琴改编生成在将音频转换为音符方面存在相似性,但它们之间也有区别:钢琴改编生成并没有唯一的正确答案。例如,原始歌曲中的单声部人声可以通过不同方式表达,如配声或加倍;和声也可能根据原曲氛围或编曲者风格表现为不同的伴奏纹理。
2.2 音乐变换
音乐变换是一个活跃的研究领域,其目标是对音乐数据进行操作。其中一种常见的方法是音乐风格迁移(music style transfer),即在保留原始音乐特征的同时,将一段音乐从一种风格转换为另一种风格[11, 12, 13]。在许多研究中,音乐风格并没有统一的定义,因此在本研究中,我们使用“风格”一词来描述在为一首流行歌曲创作钢琴改编时,不同编曲者之间在音乐诠释和创作过程上的差异。已有一些研究以此意义探讨音乐风格迁移[12, 14]。
另一种常见方法是音乐简化(music reduction),即将一段音乐重新编排,使其能够由较少的乐器或单个演奏者演奏,同时保留其音乐内容[15, 16]。基于音频的乐器改编研究可被视为将音乐简化为单一乐器的过程。已有的工作通常使用外部模块从音频中提取旋律和和弦。例如,Song2Guitar[1] 通过提取旋律、和弦和节拍模块,从流行音乐音频生成吉他改编谱;然后通过统计建模指法概率生成吉他谱。类似地,在 Takamori 等人[2]的研究中,使用外部模块提取旋律、和弦和副歌,并通过基于规则的方法生成钢琴谱。相比之下,我们的研究 Pop2Piano 仅使用节拍提取器,直接从流行音乐音频生成钢琴音符。
3. 数据集
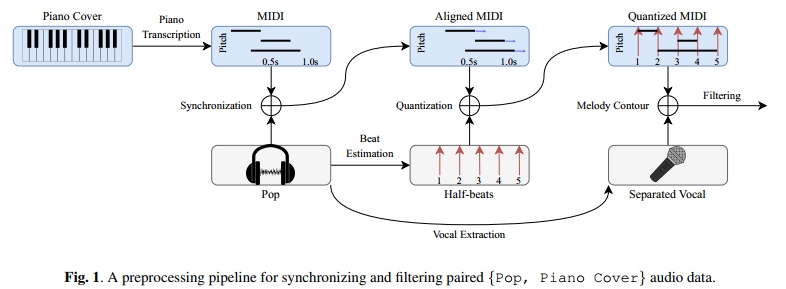
在建模原始波形对的过程中,主要的瓶颈在于其长距离依赖,因为学习音乐的高维语义在计算上具有挑战性。一个替代方法是训练成对的短波形片段。然而,这种方法要求成对数据是同步的,否则就有可能在划分后的片段数据中不包含正确的标签。由于收集到的数据对并不同步,我们开发了一个预处理流水线来获得同步的 {Pop, Piano Cover} 数据,如图1所示。
3.1 预处理
3.1.1 同步配对音乐
首先,我们使用钢琴转录模型[5]将钢琴改编音频转换为 MIDI。第二步,我们将钢琴 MIDI 与流行音乐音频进行粗对齐。我们使用 SynctoolBox[17] 获得一条对齐路径,然后通过线性插值调整 MIDI 的音符时间。这一步实现了钢琴改编与流行音频之间的基本同步。第三步,将音符时间量化为八分音符单位。在使用 Essentia 从流行音频中提取节拍后,将 MIDI 中每个音符的起始和结束时间量化到最接近的八分音符节拍。如果量化后的音符起始和结束时间相同,则将结束时间向后移动一个节拍。通过将音符的时间单位从连续时间(秒)转换为量化时间(节拍),可以降低数据的熵。
3.1.2 过滤低质量样本
在某些情况下,数据对由于诸如音乐进度差异或与原曲调性不同等原因不适合作为训练样本。为了过滤这些情况,所有旋律色度准确率(Melody Chroma Accuracy, MCA)[18] 小于等于 0.15 或音频时长差异超过 20% 的样本都会被剔除。旋律色度准确率是通过比较音频中提取的主旋律音高轮廓与 MIDI 顶部旋律声部之间计算得出的。
我们使用 Spleeter[19] 分离人声信号。接着,为了提取流行音乐的旋律轮廓,我们使用 Librosa[20] 中的 pYIN[21] 计算人声的 f0 序列。采样率设为 44100,hop length 为 1024。
3.2 与流行音乐同步的钢琴改编数据(PSP)
我们从 YouTube 上收集了 5989 首由 21 位编曲者创作的钢琴改编作品及其对应的流行歌曲。然后我们对 {Pop, Piano Cover} 数据进行同步和过滤。最终保留了 4989 条数据(307 小时),构成训练集 PSP。需要注意的是,PSP 中的每一条钢琴改编数据都是唯一的,但原始流行歌曲则不然。这将有助于模型根据编曲者条件分别学习钢琴改编的风格以及输入音频的声学特征。
4. 模型
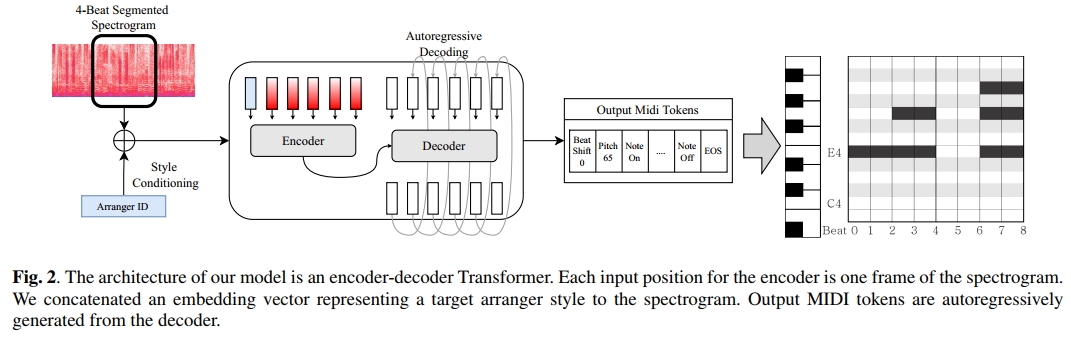
4.1 输入与输出
Pop2Piano 使用流行音乐音频的 log-Mel 频谱作为 encoder 的输入。采样率为 22050,窗口大小为 4096,hop size 为 1024。此外,表示目标钢琴改编编曲者的 arranger token 会被嵌入,并附加在频谱的第一帧之前。
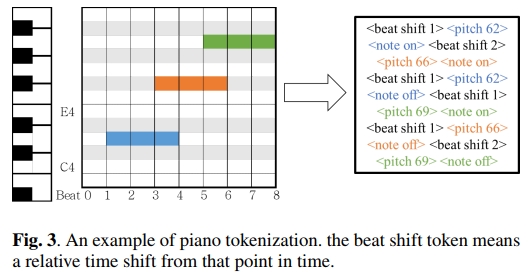
decoder 的每一步输出从以下类型的 token 中选择:
Note Pitch [128 values] 表示一个 MIDI 音高事件。但实际上只使用对应于钢琴键的 88 个音高。
Note On/Off [2 values] 决定前一个 Note Pitch 事件是被解释为 note-on 还是 note-off。
Beat Shift [100 values] 表示在以八分音符为单位量化的片段内的相对时间偏移。该偏移将作用于所有后续的与音符相关的事件,直到下一个 Beat Shift 事件为止。我们定义的词表中包含最长 50 个节拍的 Beat Shifts,但由于每个片段的时间都会重置,实际中我们只使用大约 10 个此类事件。
EOS, PAD [2 values] 表示序列的结束和序列的填充。
这个词典的设计灵感来源于基于 Transformer 的 AMT 研究 [6, 7]。关于这些 token 的详细解释示例如图 3 所示。对于每个输入,模型会自回归地生成输出,直到 decoder 中生成 EOS token 为止。为了生成任意长度的流行音乐音频的钢琴改编,在推理阶段,音频会按每 4 个节拍依次裁剪作为模型输入,随后生成的 token(除了 EOS)会被拼接起来。之后,将生成 token 的相对节拍转换为绝对时间,转换所用的绝对时间信息来自于原始歌曲中提取的节拍,最后这些信息会被转换为标准 MIDI 文件。
4.2. Architecture
Pop2Piano 的模型架构是用于 MT3 [7] 的 T5-small [22]。它是一个具有 encoder-decoder 结构的 Transformer 网络。可学习参数的数量约为 5900 万。与 MT3 [7] 不同的是,使用的是原始 T5 中的相对位置嵌入,而不是绝对位置嵌入。此外,还使用了一个可学习的嵌入层来嵌入编曲者的风格。图 2 展示了这些过程的概览。
5. 实验
在本实验中,我们检验使用 PSP 训练的 Pop2Piano(Pop2PianoPSP)是否能够生成合理的钢琴改编,并验证其是否遵循特定编曲者的风格。
5.1. Training Setup
我们使用长度为随机 4 个节拍的音频片段对模型进行训练。对整个 PSP 数据集重复这一过程 2000 次。假设平均音乐的 bpm 为 120,我们可以估算出使用 PSP 数据集训练的音频总时长约为 5500 小时。该网络使用 AdaFactor [23] 进行优化,学习率为 0.001。
5.2. 生成结果
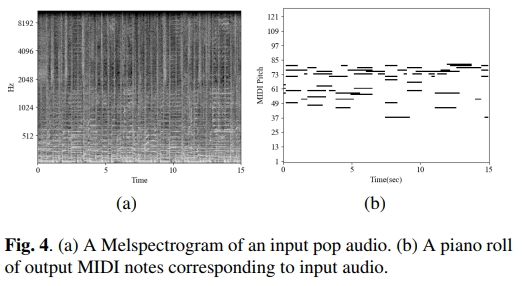
图4展示了使用任意流行音乐作为输入生成的钢琴封面示例。生成的样本可以通过链接进行试听。原始歌曲是一个复杂的音频信号,混合了各种声音,如人声、贝斯和打击乐。然而,可以看到生成的钢琴封面展示了原始歌曲的人声旋律线作为堆叠的音符,并且还包括了一种合理的伴奏,跟随原始歌曲的和声。此外,使用Pop2Piano生成的各种钢琴封面样本可以在演示页面上与原始歌曲一起试听。
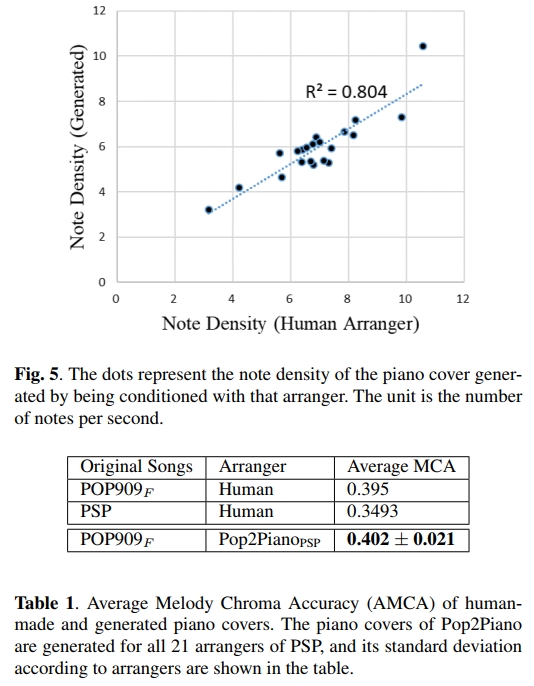
此外,我们还希望确认生成的钢琴封面不仅合理地跟随了原始歌曲的旋律,还能以我们指定的编曲风格进行演绎。然而,封面风格非常隐性,因此很难进行定量评估。受到编曲者之间音符密度差异的启发,我们通过测量Pop2PianoPSP生成的钢琴封面的音符密度,间接验证它是否以目标编曲者的风格生成钢琴封面。结果如图5所示,生成的钢琴封面在音符密度上高度符合目标编曲者的风格,线性相关度为 R 2 = 0.804 R² = 0.804 R2=0.804。
我们通过计算第3.1.2节中描述的MCA(旋律色度准确度)来评估生成的钢琴封面的质量。有趣的是,我们的结果显示,生成的钢琴封面的MCA值与人工创作的POP909数据集[24]相似,即使是在没有显式旋律的情况下进行训练。POP909是一个包含909首中文流行歌曲的钢琴MIDI数据集,包含旋律、桥段和伴奏的单独轨道。然而,在我们的实验中,为了保持一致性,我们将所有轨道合并,并像处理PSP数据集一样,通过我们的预处理管道同步fPop, Piano Coverg数据对。经过过滤后,剩余817首曲目,我们在本文中将其称为POP909F。MCA值如表1所示。需要注意的是,更高的MCA值并不一定意味着更好的钢琴封面,因此,评估生成的钢琴封面的质量仍然是一个值得进一步研究的课题。
5.3. 主观评估
我们通过评估生成的钢琴封面的自然度来衡量其主观质量。由于目前没有公开的相关研究,我们将使用用POP909训练的Pop2Piano网络(Pop2PianoPOP909)作为基准模型。与该模型的比较可以帮助我们了解PSP数据集对Pop2Piano模型性能的影响。
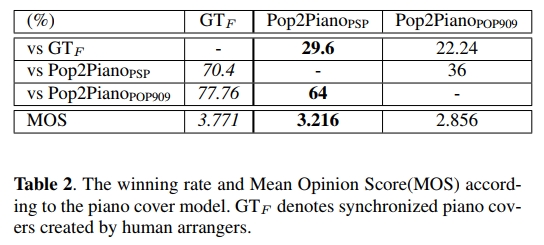
我们进行了一项用户研究,共有25名参与者,其中没有专业音乐人。参与者不知道每个钢琴封面是由哪个模型生成的。我们从25首未包含在训练数据集中的歌曲的副歌部分选择了10秒钟的片段。对于每首歌曲,使用人类编曲者制作的钢琴封面作为GT(真实标签)。然而,由于GT也需要与原始歌曲同步,因此应用了同步管道,处理后的数据被称为GTF。参与者在听完原始歌曲和钢琴封面后,评估给定的钢琴封面在安排原始歌曲时的自然程度,评分范围为1-5分。
在听觉评估中,70%的参与者更喜欢Pop2PianoPSP生成的钢琴封面,而不是Pop2PianoPOP909。在Pop2PianoPSP与Pop2PianoPOP909之间的MOS分析中,使用配对单侧Wilcoxon检验,我们在99%的置信区间下拒绝了H0(0:222;inf),p值为 3.34 e − 05 3.34e−05 3.34e−05。见表2。
5.4. 局限性
我们认识到我们的模型还可以进行一些改进。例如,Pop2Piano仅使用四拍长度的音频作为输入上下文。因此,在生成超过四拍的钢琴封面时,旋律轮廓或伴奏纹理等特征的连贯性较差。此外,基于八分音符节拍的时间量化方法使得模型无法生成具有其他节奏的钢琴封面,如三连音、十六分音符和颤音。
6. 结论
我们提出了Pop2Piano,这是一个新颖的研究,旨在直接从音频生成流行钢琴封面,而不使用基于Transformer网络的旋律或和弦提取模块。我们收集了PSP数据集,共计300小时的配对“Pop,Piano Cover”数据集,用于训练模型。我们设计了一条同步数据的管道,使其适合用于训练神经网络。我们开源了所需的数据列表和代码,以便复制PSP数据集。我们展示并评估了Pop2PianoPSP能够生成逼真的流行钢琴封面,并且能够模仿特定编曲者的风格。
论文名称:
POP2PIANO : POP AUDIO-BASED PIANO COVER GENERATION
论文地址:
https://arxiv.org/pdf/2211.00895



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











