









目录
上一篇:【机器学习(二)】K近邻算法:原理、kd树构造和查找、案例分析、代码(机器学习库、自己实现)
引言
在机器学习和深度学习中,经常会用到信息熵(entropy)这个概念,可以理解为熵表示的是随机变量不确定度的衡量。例如概率0.5比概率0.3的不确定度要高。
原理
信息熵
设X是一个取值有限的离散随机变量,其概率分布为:,则随机变量X的熵定义为
通常log取2或者e,得到的熵的单位分别称作比特或纳特。从这就可以知道,熵依赖X的分布,和X的取值无关,所以也可以把X的熵记做:
当随机变量只有两个取值的时候,例如0,1,那么X的分布为:
那么X的熵为:
的变化曲线如下:
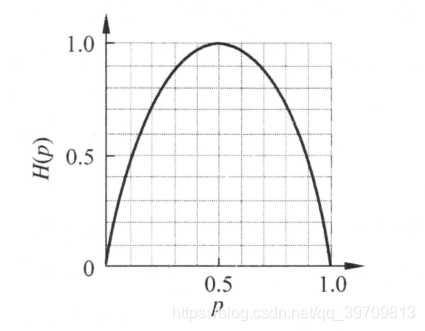
从上图中可以看出,当p=0或者1的时候,熵为0,这个时候不确定度最低,因为p=0或1已经决定x属于什么了。
同理,当p=0.5的时候不确定度最高,此时很难分清x到底是什么。
条件熵
设随机变量(X,Y)的联合概率分布为:
条件熵表示在已知随机变量X的条件下,Y的不确定度,因此
这里
当熵和条件熵是有训练数据估计而来的,那么对应的熵和条件熵称为经验熵和经验条件熵。
信息增益
信息增益是表示数据集中某个特征X的信息使类Y的信息的不确定性减少的程度,即特征X让类Y不确定度降低。
特征A对训练数据集D的信息的信息增益,定义为集合D的熵
与特征A给定条件下D的条件熵
之差
其中和
之差成为互信息
信息增益算法流程
数据集为D;样本容量为,即样本个数。
K为分类个数,表示属于类别
的样本个数,
。
特征A取值有,根据A的取值,把D划分成n个子集
,
是
的样本个数,
。
子集中属于
的样本的集合为
,
是
的样本个数。
输入:训练数据集D和特征A
输出:特征A对数据集D的信息增益
- 计算数据D的经验熵
- 计算特征A对数据集D的经验条件熵
- 计算信息增益
信息增益比
有时候以信息增益来划分训练数据集的特征,会存在偏向于选择取值较多的特征问题,使用信息增益比可以对这一个问题进行校正,成文一种更加权衡的选择标准。
特征A对训练数据D的信息增益比定义为信息增益
与训练数据D关于特征A的值的熵之比:
,其中
,n是特征A取值的个数。
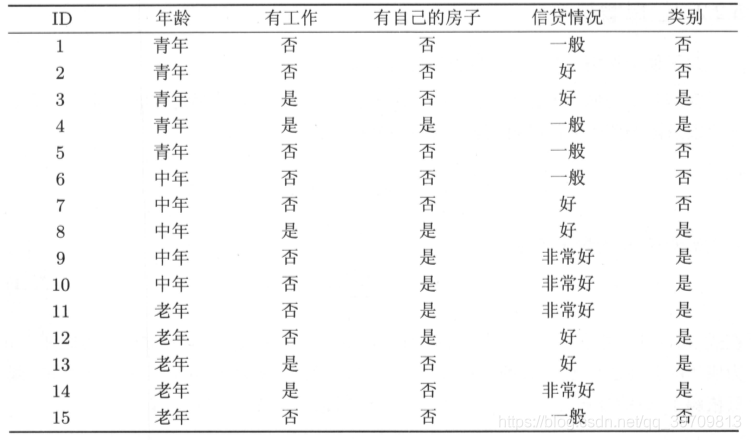
案例
表中是贷款申请表,最后的类别代表是否给予贷款的分类,求训练集信息熵、信息增益和信息增益比。
信息熵求解
从类别中可以知道,是有9个,否有6个,所以信息熵为0.971:
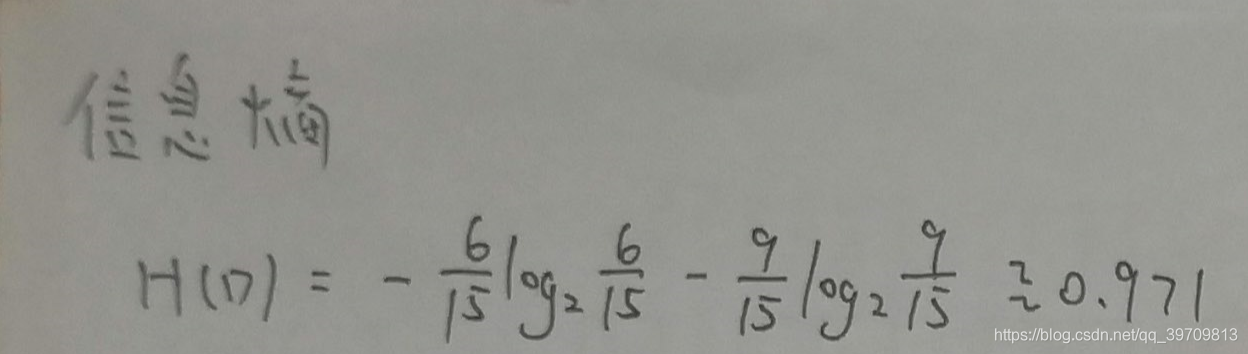
信息增益求解
这里需要对每个特征分别单独求解,例如信贷特征,有三类。一般、好和非常好分别是:5,6,4。
在一般中,是有1个,否有4个;
在好中,是有4个,否有2个;
在非常好中,是有4个,否有0个。所以计算如下:

信息增益比求解
上面已经计算过信息增益了,因此只需计算特征熵即可,计算如下:

结果分析
如果以信息增益为特征选择标准,可以知道房子的权重最大,因此优先选择房子作为首要特征,信贷特征其次。
信息增益比则是对信息增益进行了校正,从结果中可以知道,房子特征依旧是首要特征,但是工资特征其次,而不是信息增益中的信贷。
案例的代码实现
没有使用机器学习库实现:
import numpy as np
import pandas as pd
from math import log
def create_data():
datasets = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],
]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
# 返回数据集和每个维度的名称
return datasets, labels
# 熵
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print('特征({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
print(train_data)
print('特征信息增益为:', info_gain_train(np.array(datasets)))
结果如下:(值计算了信息增益)
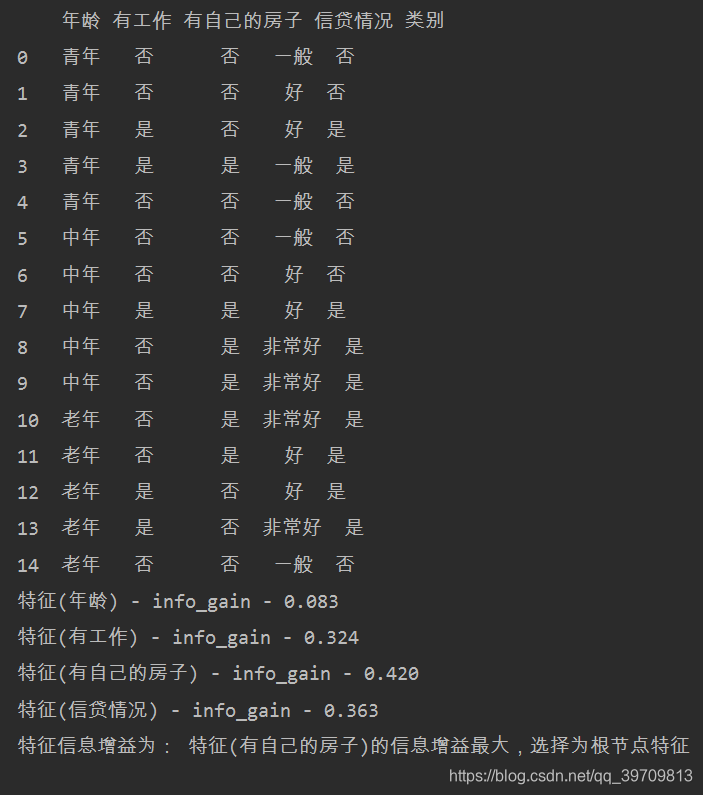
程序运算结果与手动计算结果一致。
下一篇:【机器学习(四)】决策树、ID3算法、C4.5算法、CART算法:原理,案例和代码
---------------------------------------------------------------------------------------------------------------------------------------
更新2020-6-17,将信息增益图中错误的地方改正,对代码进行简化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









