






平时我们打电话的时候,有很多朋友喜欢把对方的声音录音下来:有的是因为纪念;有的是因为要保留证据......
而事实上,这些录音不仅可以保存声音,还可以被转换成文字形式。这样一来,无论是回顾还是查找信息,都会变得更加便捷。
那如果你还不了解通话录音怎么转换成文字的话,不妨就来看看今天的教程分享合集吧~

方法一:借助“录音转文字助手”
转写速度:4.8/5
转写准确度:4.8/5
识别语言:英语、中文(普通话、粤语等方言)、西班牙语、法语等
- 使用感受:
它快速、准确,让大家在会议中不再手忙脚乱。转换后的文字还可以编辑,让大家也能够轻松修正那些小差错。
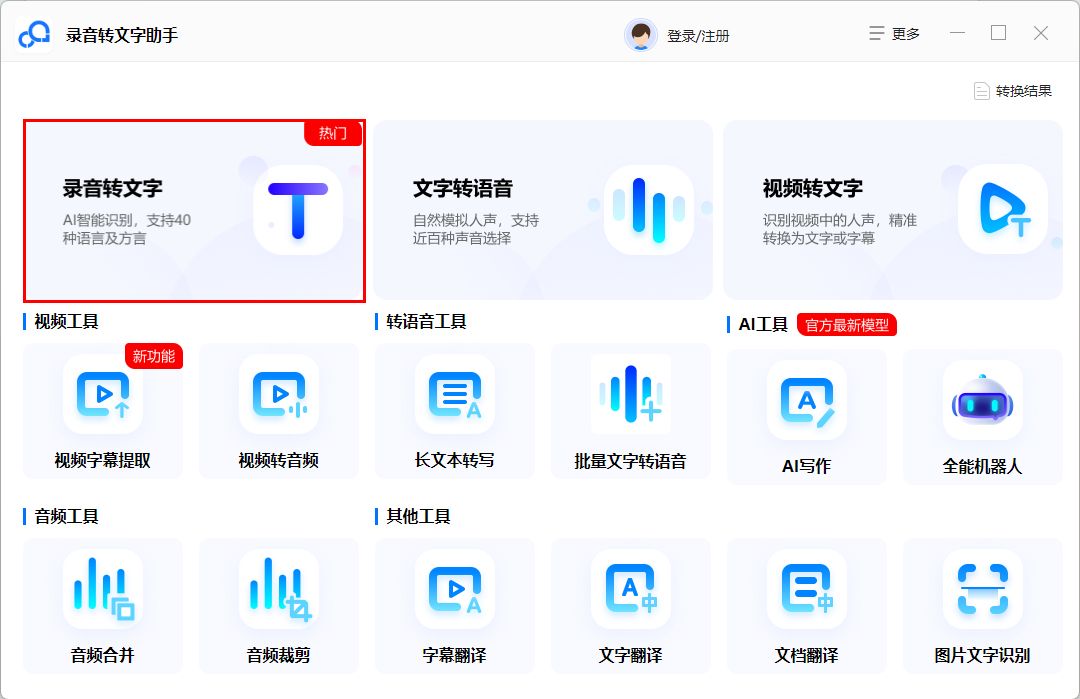
- 操作教程:
①打开“录音转文字助手”,选择对应的“录音转文字”功能;
②选择需要转写的音频文件;(软件支持批量上传,节省大家重复操作的时间)
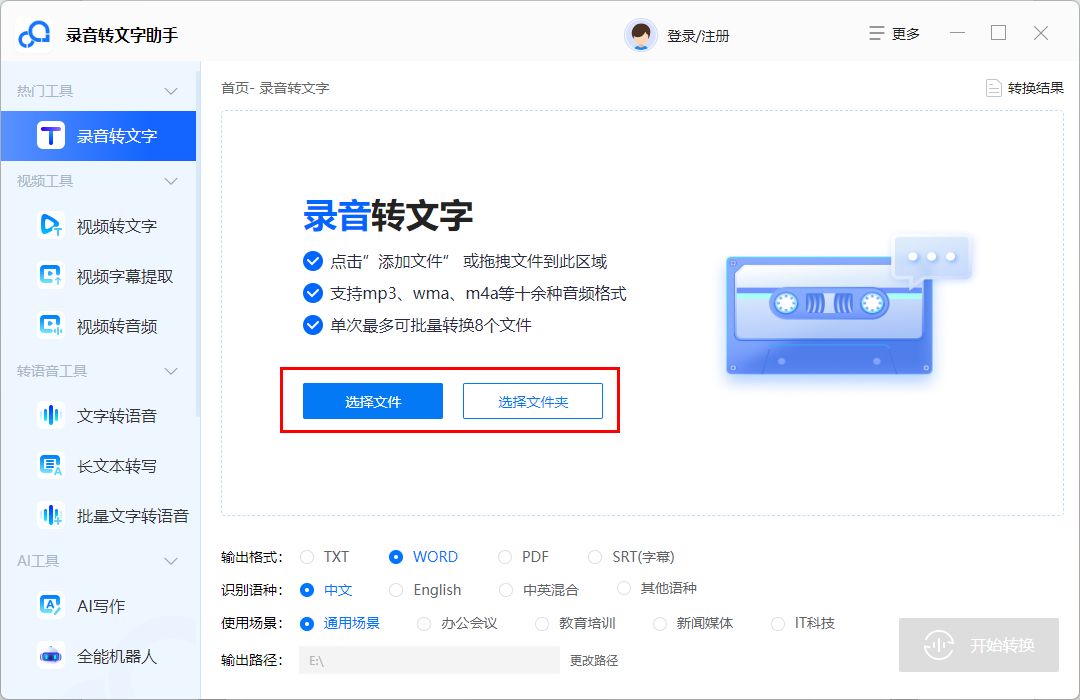
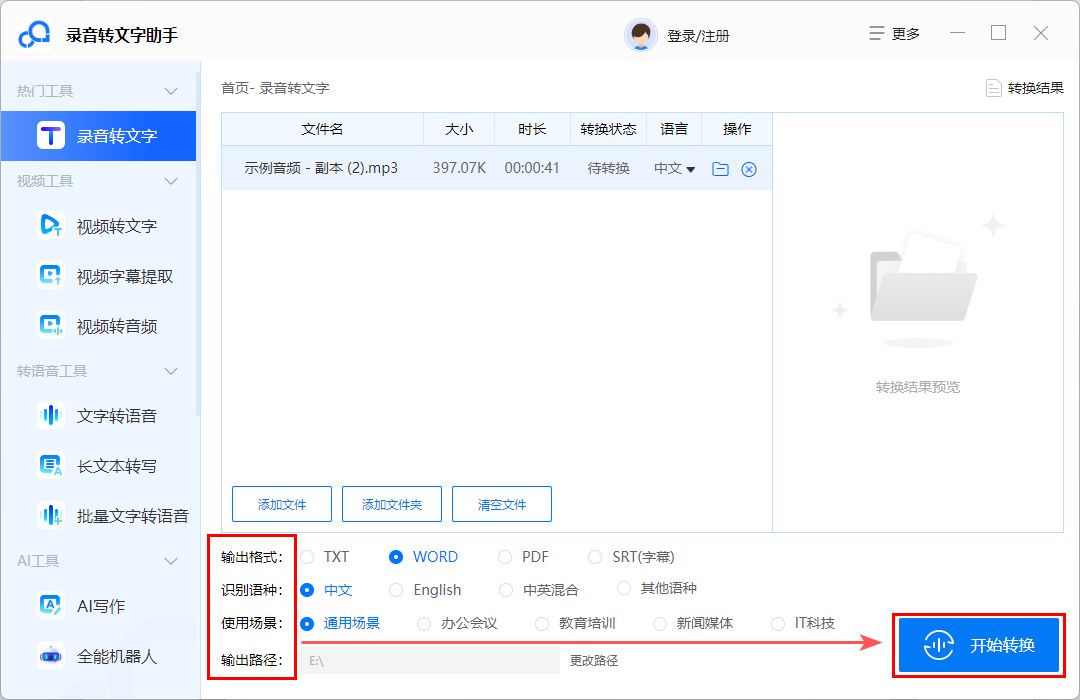
③根据需要设置好输出格式、识别语种、使用场景以及输出路径,完成后点击右下角的“开始转换”按钮;
④稍等片刻之后,大家就可以在右边的方框中看到转写结果。这时大家可以先对结果进行检查并编辑文本。确保准确无误后导出就好了。
方法二:借助“Happy Scribe”
转写速度:4.8/5
转写准确度:4.8/5
识别语言:葡萄牙语、意大利语、荷兰语等
- 使用感受:
它的界面友好,操作简单,而且转写速度快,准确率高,是大家工作中不可或缺的助手。
- 操作教程:
①访问“Happy Scribe”网站,创建账户并登录;
②点击“上传文件”,选择需要转写的音频,并设置好语言和转写选项,然后点击“开始转写”即可。
方法三:借助“网易见外工作台”
转写速度:4.7/5
转写准确度:4.7/5
识别语言:英语、中文
- 使用感受:
它不仅转写速度快,而且操作简便,是大家日常工作中的得力助手。
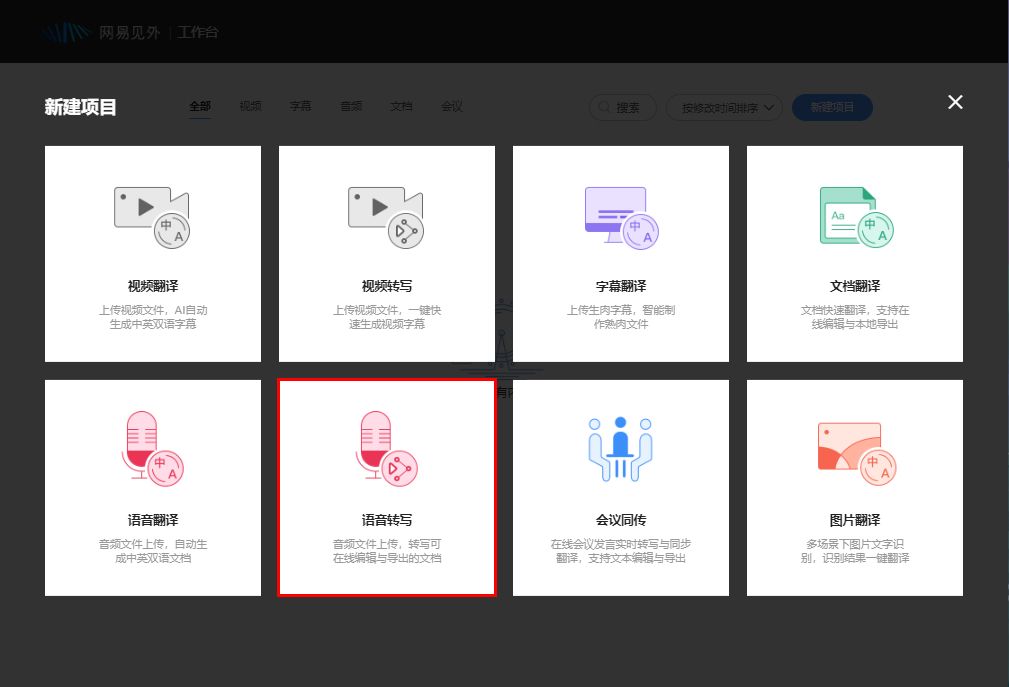
- 操作教程:
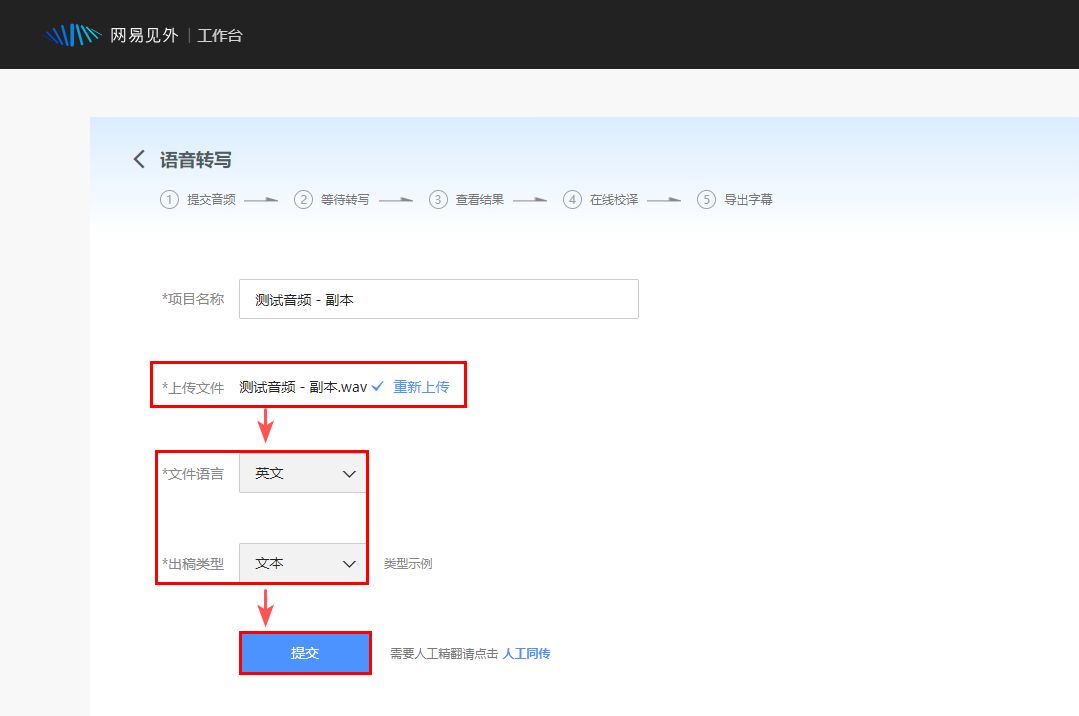
①登录“网易见外工作台”,选择“语音转文字”服务;
②上传你的音频文件,并选择文件语言和出稿类型;
③点击“提交”按钮,等待转写完成便可保存或分享了。
通过今天的分享,相信大家应该也知道录音怎么转换成文字了吧!无论出于纪念还是证据保留,现在你都可以轻松地将声音转化为文本,让信息的存储和检索变得更加简单和高效。















 1618
1618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









