






对于打工人来说,我们每天都会接触到大量的图片,其中不乏包含重要信息的文字。
无论是在旅行中偶遇的异国路标,还是工作学习中遇到的专业文献,文字往往承载着关键的线索和知识。

然而,语言的障碍有时却会让我们对这些信息望而却步。不过好在,现如今科技发达,获取图片信息已经变得简单又快捷。
接下来,我们将一起探索如何利用这一图片翻译文字功能,让图片中的文字信息不再受限于语言的边界。

软件①:全能翻译官
★浅浅介绍软件:
全能翻译官是一款功能全面的翻译软件,它集成了文字、图片、文档翻译等多种翻译工具。
★说说使用感受:
→翻译准确性:软件以其语言处理能力著称,尤其在专业术语和复杂句子结构的翻译上表现出色。
→多语言兼容性:支持世界上大多数主要语言互译,满足不同场景的翻译需求。
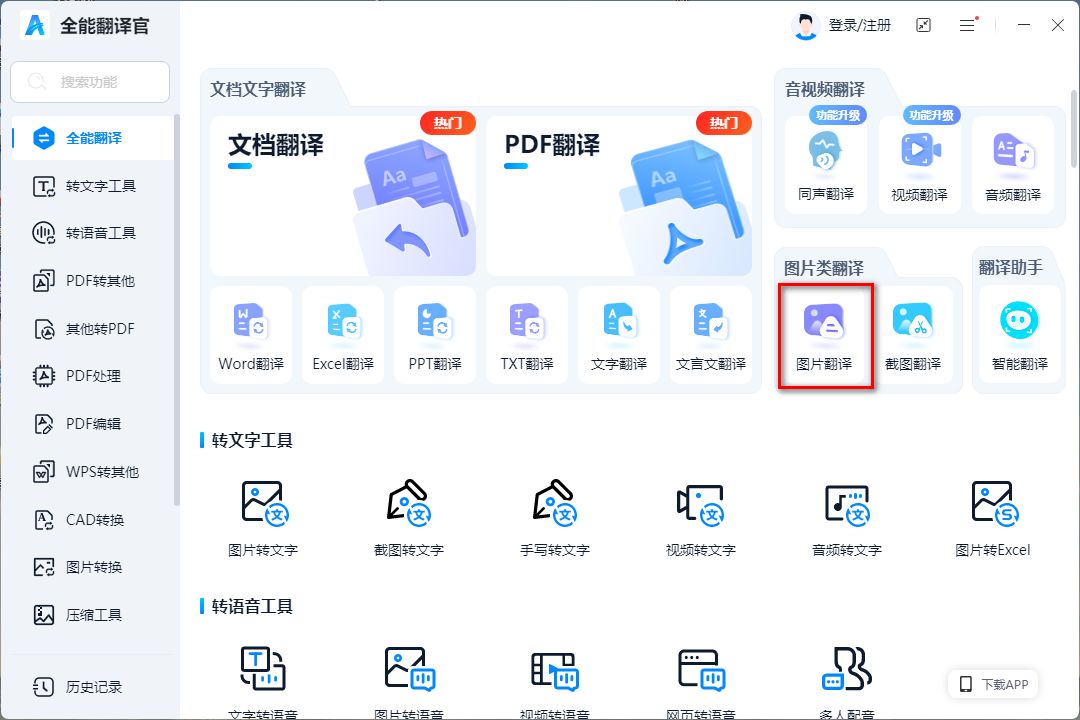
★讲讲操作步骤:
■打开应用▶找到“图片翻译”功能▶点击添加或拖拽图片至操作界面▶选择源语言和目标语言▶查看翻译结果,可开启双语对照功能校对。
软件②:Naver Papago
★浅浅介绍软件:
Naver Papago是一款支持多种语言翻译的软件,提供语音、文本等翻译功能。
★说说使用感受:
→翻译准确性:在翻译亚洲语言上表现出色,尤其是韩、中、英等语言间的互译。
→多兼容性:支持拍照翻译、语音翻译、文本翻译等操作。
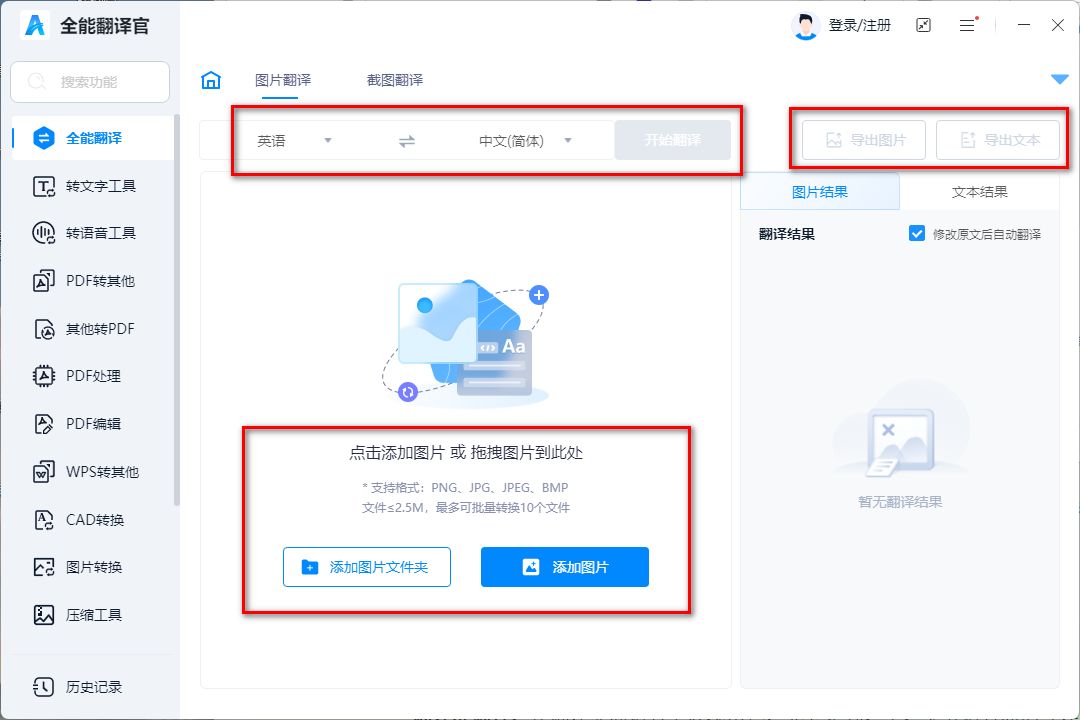
★讲讲操作步骤:
■打开软件▶选择“拍照翻译”功能▶选择要进行互译的语言▶拍摄需要翻译的图片▶获取翻译结果,并根据需要进行校对。
软件③:Waygo
★浅浅介绍软件:
Waygo是一款专为旅行者设计的翻译软件,能够即时翻译拍摄的图片中的文字。
★说说使用感受:
→翻译准确性:即时翻译,适合翻译菜单、指示牌等。
→多语言兼容性:支持多种语言,提高旅行体验。
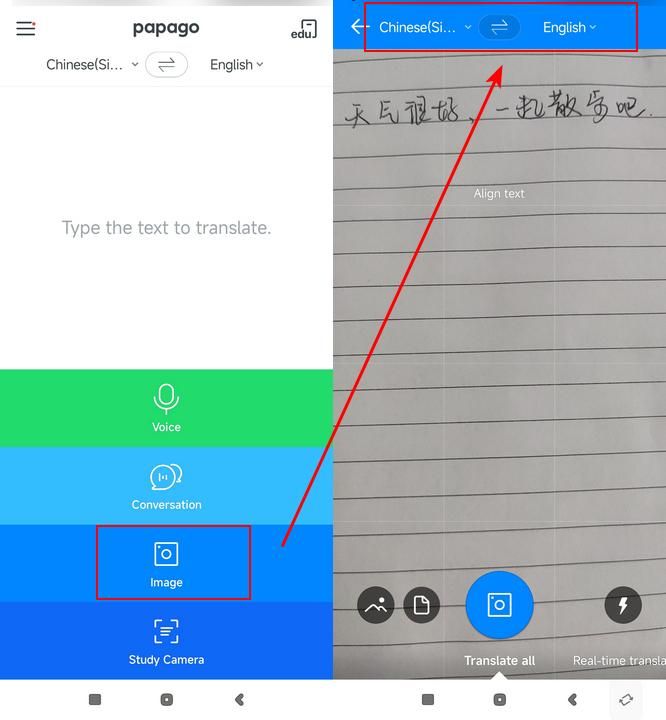
★讲讲操作步骤:
■打开Waygo应用▶使用拍照或上传图片功能▶选择需要翻译的语言▶获得即时翻译结果▶根据翻译理解文字信息。
以上便是关于“图片翻译文字怎么操作”的全部内容啦,谢谢大家的观看!
通过上面这些介绍,小伙伴们可以根据自己的需求选择最合适的翻译软件,无论是日常使用还是专业场合,都能找到适合的解决方案。















 2469
2469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









