







顺序表(Sequential List)
顺序表是一种线性表(Linear List)的实现方式,它使用一块连续的存储空间存储数据元素。每个数据元素按顺序存储在表中,具有随机访问的特性。
顺序表的定义
特点:
- 连续存储:顺序表使用一段连续的内存空间存储元素。
- 随机访问:通过数组下标可以快速访问任意位置的元素,时间复杂度为 O(1)。
- 固定容量:由于内存是连续分配的,表的容量在初始化时固定,动态扩容需要额外操作。
- 插入和删除效率:
- 插入和删除操作需要移动元素(平均时间复杂度为 O(n)),尤其是在表头或表中间操作时。
- 插入和删除效率低于链表,但顺序表通过连续存储可以更高效地利用 CPU 缓存。
适用场景:
- 数据量较小,或者数据存储后不会频繁插入和删除。
- 需要快速随机访问数据的场景(如数组、固定大小的队列/栈等)。
顺序表以数组为原型,将其展开在堆空间上,让其存储一系列的数据
一、继承数组和堆空间申请的概念:
1> 数组 :空间紧挨,数据相连。
2> 堆: 完全由程序员操作,需要考虑申请与释放。
二、顺序表的声明/创建原型
1> 第一种:最简单
使用数组来实现顺序表(栈区):int arr[N];—> 缺点:占用空间大,会对栈区有负担;没办法遍历有效数据,只能全部遍历数据。
2> 第二种:相对简单
通过结构体来实现。
struct seq{
int arr[N]; //保存数据
int len; //记录数组中有效数据的个数
};
3> 第三种:完全体 —> 最后用来实现顺序表的结构体
struct seq{
int *arr; //指针变量保存的是变长数组的入口
int len; //记录数组中有效数据的个数
int size; //数组的总容量
};
优点:
查找和替换很方便
缺点:
插入和删除运算耗时,存在数据元素在存储器中成片移动的现象
需要一块比较大的连续空间
顺序表的基本操作
顺序表的基本操作包括:
- 初始化:创建一个空的顺序表。
- 插入:在指定位置插入元素。
- 删除:删除指定位置的元素。
- 查找:按位置或按值查找元素。
- 遍历:依次访问顺序表中的每个元素。
- 扩容:当顺序表空间不足时,进行动态扩容。
以下是顺序表的详细代码实现。分为C语言和Python两种实现方式:前者在Linux系统中运行;后者在Windows中运行:
C语言
seqlist.h(头文件)
#ifndef __SEQLIST_H__ //避免头文件被重复包含 宏保护
#define __SEQLIST_H__ //定义头文件
#include <stdio.h>
#include <stdlib.h>
#define N 10 //用宏定义的N去限制变长数组的大小
typedef struct seq{ //typedef 取别名
int *arr; //指针变量 保存着数组的入口
int len; //记录数组中有效数据的个数
int size; //数组的容量
}seq_t;
/*函数申明区*/
extern seq_t *seq_init(void);
// extern void seq_init1(seq_t * p);
// extern void seq_init2(seq_t ** p);
extern void seq_insert(seq_t *pp,int data,int loc);
extern void display(seq_t *p);
extern void seq_del(seq_t *p,int data);
extern void seq_replace(seq_t *p,int old,int new);
#endif
seqlist.c(顺序表函数)
#include "seqlist.h"
/*
* 初始化seq_init
* 无参:在函数中创建好改结构体并赋好值,之后,直接将此结构体的指针返回出来供我们调用即可
* 返回值seq_t * 结构体指针
*/
seq_t *seq_init(void)
{
//1> 向堆空间申请结构体的空间
seq_t *p = (seq_t *)malloc(sizeof(seq_t));
if(NULL == p){
perror("malloc error");
return NULL; //注意返回值是指针类型
}
//printf("结构体的地址%p\n",p);
//2>给结构体的第一个成员int *的指针赋值 (数组的首地址)
p->arr = (int *)malloc(sizeof(int) * N); //数组总大小 N*4(int)
if(p->arr == NULL){
perror("malloc error");
return NULL; //注意返回值是指针类型
}
//3>第二个成员赋值
p->len = 0;
//4>第三个成员赋值
p->size = N;
return p; //当前结构体中所以成员都赋值完毕
}
#if 0
void seq_init1(seq_t * p) {
// p = (seq_t *)malloc(sizeof(seq_t));
p->arr = (int*)malloc(sizeof(int) * N);
p->len = 0;
p->size = N;
}
void seq_init2(seq_t ** p) { //结构体指针的地址
*p = (seq_t *)malloc(sizeof(seq_t)); //二级指针,通过传入一级指针获取p的值,操作后往回一级指针的地址,外部调用一级指针的地址,避免使用栈区的空间
(*p)->arr = (int*)malloc(sizeof(int) * N);
(*p)->len = 0;
(*p)->size = N;
}
#endif
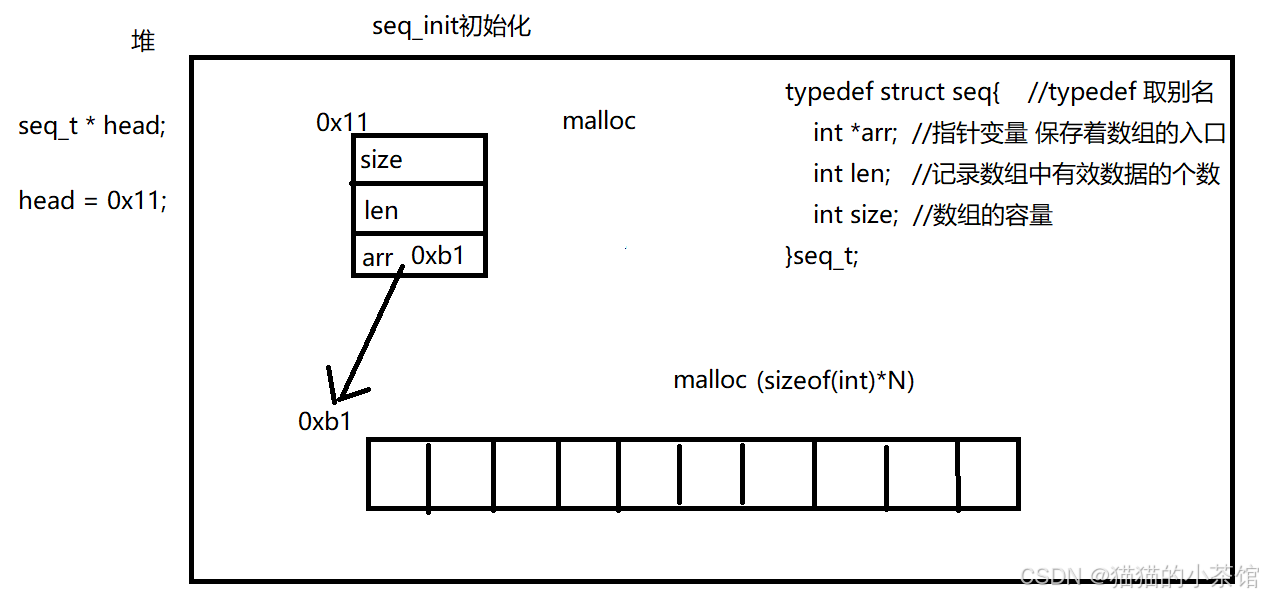
/*
* 初始化seq_insert:往顺序表中插入数据
* 参数:结构体地址(p)、数据(data)、位置(loc)
* 返回值seq_t * 结构体指针
*/
void seq_insert(seq_t *pp,int data,int loc)
{
//1>判断插入位置是否合法
if(loc < 0 || loc > pp->len)
{
printf("插入位置不合法\n");
return;
}
//2>判断是否存满
if(pp->len == pp->size)
{
pp->size += N;
// printf("不好意思,满了...\n");
// return;
/* void *realloc(void *ptr,size_t size)
ptr: 万能指针类型,需要扩容或缩容的起始地址
size: 扩容或缩容的大小
注意:扩容后返回的地址会发生变化,这是因为堆空间找了另外适合你需要大小的地址*/
pp->arr = (int *)realloc(pp->arr,pp->size*sizeof(int));
}
//3>插入数据,移动其他数据,腾出空位
for(int i = pp->len-1;i>=loc;i--)
{
pp->arr[i+1] = pp->arr[i];
}
pp->arr[loc] = data;
//因为插入数据,有效len自增
pp->len++;
//此处附上了解释图:
//写代码需要有图形思维,在写代码的时候,脑海中要存在数据在内存映射中的变化的情况 ——> 同理。在工作中编写程序时,前提是要精通业务 ——>后续才是代码实现
}
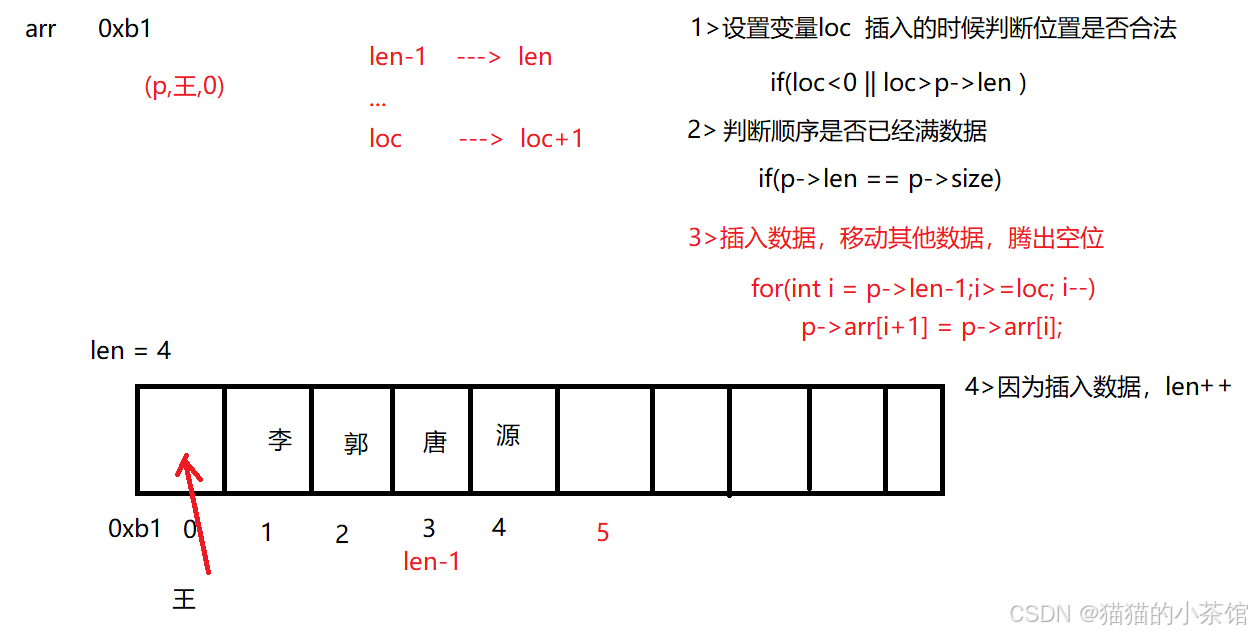
/*
* 删除数据seq_del
* 参数:结构体地址(p)
* 无需返回值
*/
void seq_del(seq_t *p,int data)
{
int i = 0,loc = 0; //i用来遍历,loc用来移动数据
// 1>遍历顺序表
while(i<p->len) //当顺序表有数据,就可以循环
{
//2>找到你要删除的数据的下标
if(p->arr[i] == data)
{
//删除数据,数据往前移动覆盖
for(loc = i+1;loc<=p->len-1;loc++)
{
p->arr[loc-1] = p->arr[loc];
}
//有效数据长度len自减
p->len--;
}
i++; //自增是为了往后继续遍历,找到相同对应数据
}
}
/*
* 修改seq_replace
* 参数:结构体地址(p)旧数据(old)新数据(new)
* 不需要返回值
*/
void seq_replace(seq_t *p,int old,int new)
{
//1>遍历顺序表
for(int i = 0;i<p->len;i++)
{
if(p->arr[i] == old) //找到旧数据所在顺序表中的下标
{
//用新数据直接覆盖旧数据
p->arr[i] = new;
}
}
}
/*
* 遍历顺序表display
* 参数:结构体地址(p)
* 无需返回值
*/
void display(seq_t *p)
{
if(p->len == 0)
{
printf("顺序表为空\n");
return;
}
//遍历for循环
for(int i = 0;i<p->len;i++)
{
printf("%d ",p->arr[i]);
}
printf("\n");
}
main.c(主函数)
#include "seqlist.h"
int main(void)
{
#if 0
seq_t *p = NULL; //避免野指针
//seq_init1(&p);
seq_init2(&p);
printf("结构体的地址%p\n",p);
#endif
//1>调用函数进行结构体初始化
seq_t *p = seq_init();
if(NULL == p)
return -1;
printf("初始化成功\n");
int data,loc,ret;
while(1)
{
printf("请输入数据和数据要插入的位置\n");
ret = scanf("%d %d",&data,&loc); //如果输入字符则会返回0
if(ret == 0)
break;
seq_insert(p,data,loc);
display(p);
}
//避免换行符将删除操作直接关闭
getchar(); //吃掉缓冲区的换行符
while(1)
{
printf("请输入要删除的数据\n");
ret = scanf("%d",&data); //如果输入字符则会返回0
if(ret == 0)
break;
seq_del(p,data);
display(p);
}
getchar(); //吃掉缓冲区的换行符
int old,new;
while(1)
{
printf("请输入要修改的旧数据和新数据\n");
ret = scanf("%d%d",&old,&new); //如果输入字符则会返回0
if(ret == 0)
break;
seq_replace(p,old,new);
display(p);
}
return 0;
}
Python语言
顺序表的定义与初始化:
class SequentialList:
def __init__(self, capacity=10):
"""
初始化顺序表
:param capacity: 顺序表的初始容量
"""
self.data = [None] * capacity # 用固定大小的列表模拟顺序表
self.capacity = capacity # 当前容量
self.size = 0 # 当前顺序表的大小(元素个数)
def __str__(self):
"""
返回顺序表的字符串表示
"""
return str(self.data[:self.size])
# self.data 是用于存储元素的数组,初始容量为 capacity。
# self.size 表示当前顺序表中的有效元素个数。
# __str__ 用于打印顺序表中的有效元素。
插入操作:
def insert(self, index, value):
"""
在指定位置插入元素
:param index: 插入位置,0 <= index <= self.size
:param value: 要插入的值
"""
if index < 0 or index > self.size:
raise IndexError("Index out of bounds.")
# 如果容量不足,扩容
if self.size >= self.capacity:
self._resize()
# 从后往前移动元素,为新元素腾出空间
for i in range(self.size, index, -1):
self.data[i] = self.data[i - 1]
# 插入新元素
self.data[index] = value
self.size += 1
def _resize(self):
"""
扩容顺序表
"""
new_capacity = self.capacity * 2
new_data = [None] * new_capacity
for i in range(self.size):
new_data[i] = self.data[i]
self.data = new_data
self.capacity = new_capacity
代码逻辑拆分:
- 检查插入索引是否合法(0 <= index <= size)。
- 如果容量不足,则调用 _resize 进行扩容。
- 从 size-1 到 index 的位置,将元素右移一位,为新元素腾出空间。
- 在 index 位置插入元素,并更新 size。
扩容策略:
- 扩容时,将容量翻倍(capacity * 2),从而减少频繁扩容的开销。
删除操作:
def delete(self, index):
"""
删除指定位置的元素
:param index: 要删除的元素位置,0 <= index < self.size
"""
if index < 0 or index >= self.size:
raise IndexError("Index out of bounds.")
# 从 index 开始,将后面的元素左移一位
for i in range(index, self.size - 1):
self.data[i] = self.data[i + 1]
# 清除最后一个元素并更新大小
self.data[self.size - 1] = None
self.size -= 1
代码逻辑拆分:
- 检查索引是否合法。
- 将 index 之后的元素依次左移,覆盖被删除的元素。
- 将最后一个元素置为 None,并更新 size。
查找操作:
def get(self, index):
"""
按索引获取元素
:param index: 要获取的元素位置,0 <= index < self.size
:return: 索引对应的元素
"""
if index < 0 or index >= self.size:
raise IndexError("Index out of bounds.")
return self.data[index]
def find(self, value):
"""
按值查找元素
:param value: 要查找的值
:return: 找到的索引位置,未找到返回 -1
"""
for i in range(self.size):
if self.data[i] == value:
return i
return -1
- 按索引查找(get):时间复杂度为 O(1),直接访问数组下标。
- 按值查找(find):时间复杂度为 O(n),需要线性遍历顺序表。
遍历顺序表:
def traverse(self):
"""
遍历顺序表中的所有元素
:return: 顺序表中所有元素的列表
"""
return [self.data[i] for i in range(self.size)]
代码逻辑: 遍历 data 数组,从索引 0 到 size-1 获取所有有效元素。
下面是顺序表的完整代码和使用顺序表的代码:(复制粘贴即可使用)
完整代码:
class SequentialList:
def __init__(self, capacity=10):
self.data = [None] * capacity
self.capacity = capacity
self.size = 0
def __str__(self):
return str(self.data[:self.size])
def insert(self, index, value):
if index < 0 or index > self.size:
raise IndexError("Index out of bounds.")
if self.size >= self.capacity:
self._resize()
for i in range(self.size, index, -1):
self.data[i] = self.data[i - 1]
self.data[index] = value
self.size += 1
def _resize(self):
new_capacity = self.capacity * 2
new_data = [None] * new_capacity
for i in range(self.size):
new_data[i] = self.data[i]
self.data = new_data
self.capacity = new_capacity
def delete(self, index):
if index < 0 or index >= self.size:
raise IndexError("Index out of bounds.")
for i in range(index, self.size - 1):
self.data[i] = self.data[i + 1]
self.data[self.size - 1] = None
self.size -= 1
def get(self, index):
if index < 0 or index >= self.size:
raise IndexError("Index out of bounds.")
return self.data[index]
def find(self, value):
for i in range(self.size):
if self.data[i] == value:
return i
return -1
def traverse(self):
return [self.data[i] for i in range(self.size)]
使用:
# 创建顺序表
seq_list = SequentialList()
# 插入元素
seq_list.insert(0, 10)
seq_list.insert(1, 20)
seq_list.insert(1, 15)
print("After insertions:", seq_list) # 输出: [10, 15, 20]
# 删除元素
seq_list.delete(1)
print("After deletion:", seq_list) # 输出: [10, 20]
# 查找元素
print("Element at index 1:", seq_list.get(1)) # 输出: 20
print("Index of 20:", seq_list.find(20)) # 输出: 1
# 遍历顺序表
print("Traverse:", seq_list.traverse()) # 输出: [10, 20]
顺序表复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 插入 | O(n) | 最坏情况需要移动 n 个元素(插入在表头)。 |
| 删除 | O(n) | 最坏情况需要移动 n 个元素(删除表头元素)。 |
| 查找(按位置) | O(1) | 直接通过下标访问,时间复杂度为常数。 |
| 查找(按值) | O(n) | 需要线性遍历顺序表,复杂度为 O(n)。 |
| 遍历 | O(n) | 遍历顺序表的所有元素。 |
| 扩容 | O(n) | 扩容时需要复制所有现有元素到新数组中。 |
总之,顺序表是一个简单而高效的数据结构,适用于需要快速随机访问的场景。它在插入和删除操作上不如链表高效,但通过连续存储空间,可以更高效地利用缓存,且实现较为简单。在实际应用中,顺序表的变种(如动态数组、栈)被广泛使用。
综上。希望该内容能对你有帮助,感谢!
以上。仅供学习与分享交流,请勿用于商业用途!转载需提前说明。
我是一个十分热爱技术的程序员,希望这篇文章能够对您有帮助,也希望认识更多热爱程序开发的小伙伴。
感谢!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











