






维普论文检测系统网址:https://vpcs.fanyu.com/
第一步:复制网址到浏览器打开,出现如下界面,点击“我是个人用户”。
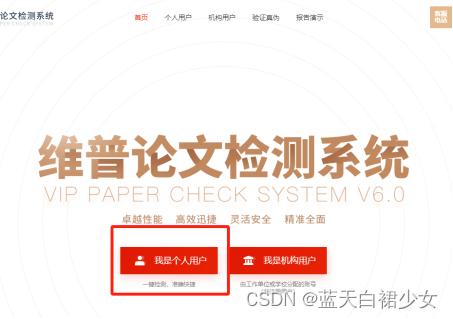
第二步:点击“大学生版”。
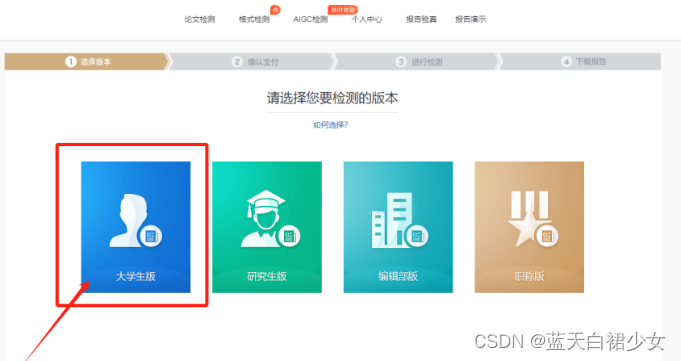
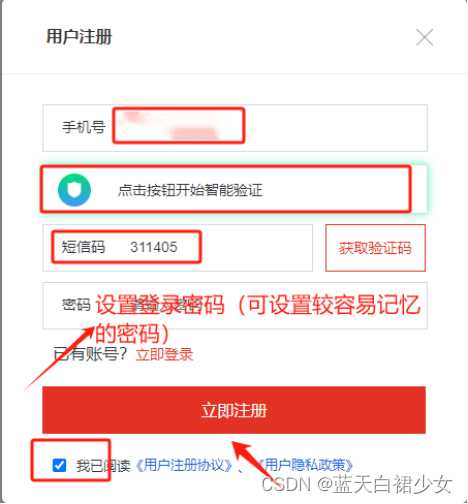
第三步:出现登录界面,选择“免费注册”。

第四步:进入注册页面后,使用手机号码注册,并输入相应的验证码,设置登录密码,勾选“我已同意《用户注册协议》、《用户隐私政策》”,点击“立即注册”按钮。
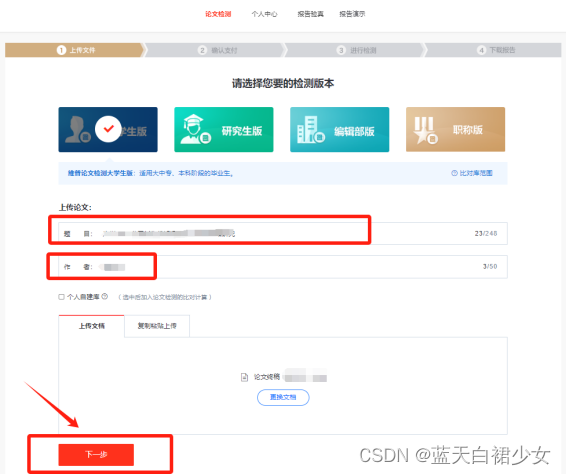
第五步:注册成功后,进入上传论文界面,正确填写论文题目(不能超过248个字)、作者信息(不能超过50个字),点击“上传文档”,然后点击“下一步”。
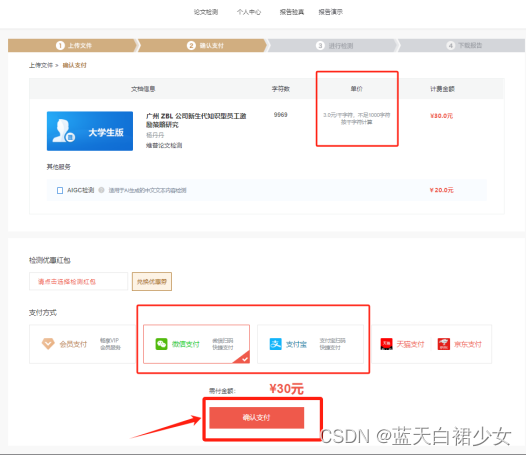
第六步:进入支付页面,费用按照3.0元/千字符,不足1000字符按千字符计算,可选择常规的支付方式(微信或者支付宝),点击“确认支付”。
第七步:支付成功后,进行论文检测,检测完成后下载检测报告。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









