






[python]将Xmind用例转成excel用例
Xmind用例和excel用例在实际的项目工作中,作为测试人员我们都会使用到,在用例评审时使用XMIND会更高效,在用例存贮或是用例任务管理时,excel用例又更加清晰。
在一位大佬的基础上修改,制作了实用于我们项目的转换工具,效果如下:
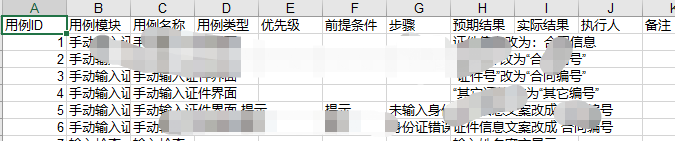
修改后的原码如下(支持所有层级的XMIND文件,大于6个节点后,中间节点会当前提条件):
前期可以让测试人员将XMIND风格统一:
#coding=utf-8
import xlwt
from xmindparser import xmind_to_dict
def resolvePath(dict,lists,title):
# title去除首尾空格
title = title.strip()
# 如果title是空字符串,则直接获取value
if len(title) == 0:
concatTitle = dict['title'].strip()
else:
concatTitle = title + '\t' + dict['title'].strip()
if dict.__contains__('topics')==False:
lists.append(concatTitle)
else:
for d in dict['topics']:
resolvePath(d,lists,concatTitle)
def xmind_cat(list ,excelname,groupname):
f = xlwt.Workbook()
sheet = f.add_sheet(groupname , cell_overwrite_ok=True)
row0 = ["用例ID", "用例模块", "用例名称", "用例类型", "优先级", "前提条件", "步骤", "预期结果", "实际结果", "执行人", "备注"]
# 生成第一行中固定表头内容
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
# 增量索引
index = 0
for h in range(0,len(list)):
lists = []
resolvePath(list[h], lists, '')
for j in range(0, len(lists)):
lists[j] = lists[j].split('\t')
for n in range(0, len(lists[j])):
sheet.write(j+index+1, 0, j+index+1)
# sheet.write(j+index+1, 1, groupname)
sheet.write(j + index + 1, 1, lists[j][0])
if len(lists[j]) == 1:
sheet.write(j+index+1, 2, lists[j][0])
elif len(lists[j]) == 2:
sheet.write(j + index + 1, 2, lists[j][0])
sheet.write(j + index + 1, 7, lists[j][1])
elif len(lists[j]) == 3:
sheet.write(j + index + 1, 2, lists[j][0]+'-'+str(lists[j][1]))
sheet.write(j + index + 1, 6, lists[j][1])
sheet.write(j + index + 1, 7, lists[j][2])
elif len(lists[j]) == 4:
sheet.write(j + index + 1, 2, lists[j][0]+'-'+str(lists[j][1]))
sheet.write(j + index + 1, 5, lists[j][1])
sheet.write(j + index + 1, 6, lists[j][2])
sheet.write(j + index + 1, 7, lists[j][3])
elif len(lists[j]) == 5:
sheet.write(j + index + 1, 2, lists[j][0]+'-'+str(lists[j][1]))
sheet.write(j + index + 1, 5, str(lists[j][1])+'-'+str(lists[j][2]))
sheet.write(j + index + 1, 6, lists[j][3])
sheet.write(j + index + 1, 7, lists[j][4])
else:
sheet.write(j + index + 1, 2, lists[j][0] +'-' +str(lists[j][1]))
vl = ''
for num in range(2,len(lists[j])-2):
vl = vl + '-' + str(lists[j][num])
sheet.write(j + index + 1, 5,str(vl).lstrip('-'))
sheet.write(j + index + 1, 6, lists[j][len(lists[j])-2])
sheet.write(j + index + 1, 7, lists[j][len(lists[j])-1])
# 遍历结束lists,给增量索引赋值,跳出for j循环,开始for h循环
if j == len(lists) - 1:
index += len(lists)
f.save(excelname)
def maintest(filename,excelname):
out = xmind_to_dict(filename)
groupname = out[0]['topic']['title']
xmind_cat(out[0]['topic']['topics'],excelname,groupname)
if __name__ == '__main__':
try:
# path = r"G:\智能收款\智能收款测试用例\2.智能收款测试用例Xmind版本\通联扫码支付.xmind"
path = input('建议打开cmd将exe文件拖入后回车,再将xmind用例文件路径拖到这里 :')
filename = path
excelname = path.rstrip('xmind') + 'xls'
maintest(filename, excelname)
print('SUCCESS!\n生成用例成功,用例目录:%s' % excelname)
except:
print('请确认后重试:\n1.用例文件路径中不能有空格\n2.请使用python3运行\n3.检查xmind文件中不能有乱码或无法识别的字符(xmind自带表情字符除外)')














 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









