







一、distinct关键字
我们在MySQL中查询数据时,有时候会需要得到某个字段重复的数据,而MySQL正好就提供了一个distinct关键字来让我们实现去重的操作。
二、distinct的使用
1. 创建一张表
简单创建一个用户表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_user
-- ----------------------------
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`age` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
结构如下:

2. 单列去重
select distinct age from t_user
结果如下:

使用group by达到同样效果:
select age from t_user group by age
可以看到,结果是一样的
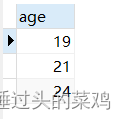
将重复的age都去除了,所以我们在实际应用中也可以使用cout来获取不重复数据的个数,就像下面这样
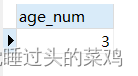
select count(distinct age) as age_num from t_user
结果如下
3. 多列去重
select distinct age,name from t_user
结果如下:

可以看到,这样写会把name和age都相同的记录去掉。所以不需要每个字段前面都加上distinct关键字,注意。
总结
distinct可以帮助我们去重,可以作为判断条件让我们获取不重复数据的个数,当然也可以使用group by达到同样的效果,两者的底层实现也是十分相像的。
还有一点需要注意的是在多表查询的时候一定要注意是否需要去重,即使用distinct关键字,不然会查出很多相同的数据。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









