









最近在看老钱的《redis深度历险》,里面最后的章节介绍了zset的底层的数据结构,跳跃表。感觉这个跳跃表的设计非常好,在此记录一下。有理解错误的地方,还请路过的大神不吝赐教
其实,Redis的zset结构使用的是hash加上跳跃表的设计
hash结构用来存储value和score的关系
但是,zset可以根据score的范围获取value的列表,这个实现就要用到跳跃表的设计
跳跃表大概长下面这个样子
以下图片均借鉴自:https://www.cnblogs.com/thrillerz/p/4505550.html
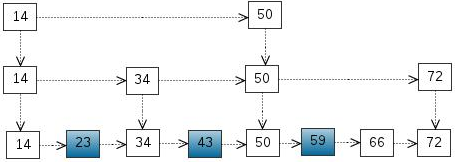
跳跃表的底层其实也就是一个双向的list结构。最下面一层是level1,然后往上是level2.如下图
跳跃表的查询操作
跳跃表其实是由双向链表衍生出来的。我们先初始化一个有序的链表

如果我们想要找到[23,43,59]这三个元素。需要的比较次数分别是[2,4,6]。23这个元素需要经过2次比较。
1 .和14比较,大于14
2 .和23比较,等于23。找到了
43和59元素的查找顺序同上
这样的话,总的查找次数为:2+4+6=12次。此时的复杂度为:O(n)。
好了,跳跃表闪亮登场
我们可以在链表的个别元素上增加一层,作为索引。
如下图所示,我们将14、34、50、72提取出来作为索引使用
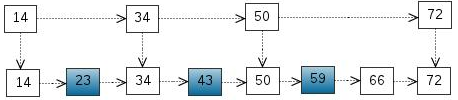
此时我们再次查找23,43,59这三个元素
找23这个元素
1 .和14比较,大于14
2 .和34比较,比34小。从14的下一层开始找,和23比较,等于23.找到
比较次数:2次
找43这个元素
1 .和14比较,大于14
2 .和34比较,大于34
3 .和50比较,小于50,。从34的下一层开始找,比较43.等于43,找到了
比较次数:4次
找59这个元素
1 .和14比较,大于14
2 .和34比较,大于34
3 .和50比较,大于50。
4 .和72比较,小于72,。从50的下一层元素开始找。和59比较,等于59.找到
比较次数:5次。比单层链表的比较次数少了1次。性能提高了。
元素少了,不足以显示跳跃表的优势。redis的最高层有64层,大数据量时优势非常明显
跳跃表的新增操作
先得到一个随机的层数,这个随机的层数是纯随机。redis官方的zset结构,50%概率被分到第一层。
然后越往上,概率减半。所以redis的zset结构,相对来说,更加的扁平化。需要遍历的次数比较多
我们得到随机层数之后,在每一层都插入该元素。如果该层数高于最高层,就更新一下跳跃表的最高层数
跳跃表的删除操作
先查询到元素的位置,然后使用标准的链表删除操作删除元素。同时注意更新一下最高层数
跳跃表的更新操作
如果value值存在,此时只是更新一下score值即可。如果更新的score值并不会带来排序上的变化,此时只更新一下score值即可。score是用来对跳跃表进行排序的依据。这里说明一下,redis中对于value值的更新操作不是这么做的,它是先删除,然后再添加,中间一共经历过2次查询操作。所以,这个地方,应该是有优化的空间的。
我猜测,score值在跳跃表中的作用。就是用来做比较用的。我们插入一个元素,就要插入一个score值。然后根据score值决定元素的位置。
查找元素时,根据score值定位元素的位置,然后取得元素即可
每一个元素都会存储一个跨度span值,代表当前节点到目标节点的跨度。这个跨度也就是RANK值
如果多个元素的score值相同,此时会再次比较value值的字节大小,根据value值的 字节大小进行排序















 1772
1772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









