







广度优先
广度优先遍历也叫广度优先搜索(Breadth First Search)。它的遍历规则:
- 先访问完当前顶点的所有邻接点。(应该看得出广度的意思)
- 先访问顶点的邻接点先于后访问顶点的邻接点被访问。
具体点,给定一图G=<V,E>,用visited[i]表示顶点i的访问情况,则初始情况下所有的visited[i]都为false。假设从顶点V0开始遍历,且顶点V0的邻接点下表从小到大有Vi、Vj...Vk。按规则1,接着应遍历Vi、Vj和Vk。再按规则2,接下来应遍历Vi的所有邻接点,之后是Vj的所有邻接点,...,最后是Vk的所有邻接点。接下来就是递归的过程...
在广度遍历的过程中,会出现图不连通的情况,此时也需按上述情况二来进行:测试visited[i]...。
在上述过程中,可以看出需要用到队列。
举个例子,还是同样一幅图:
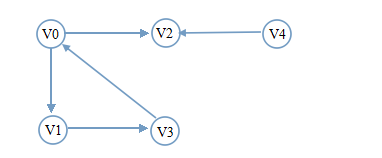
从V
0
开始遍历
遍历分析:V0有两个邻接点V1和V2,于是按序遍历V1、V2。V1先于V2被访问,于是V1的邻接点应先于V2的邻接点被访问,那就是接着访问V3。V2无邻接点,只能看V3的邻接点了,而V0已被访问过了。此时需检测visited[i],只有V4了。广度遍历完毕。
遍历序列是
遍历序列是
V0->V1->V2->V3->V4。
从其它顶点出发的广度优先遍历序列是
V1->V3->V0->V
2
->
V
4
。
V2->V0->V1->V3->V4。
V3->V0->V1->V2->V4。
V4->V2->V0->V1->V3。
以上结果,我们同样用于测试程序。
在邻接矩阵下,图的广度遍历算法
public class BFSearch {
/**
* 广度优先搜索
* BFSearch
* @param node
* 搜索的入口节点
*/
public void searchTraversing(GraphNode node) {
List<GraphNode> visited = new ArrayList<GraphNode>(); // 已经被访问过的元素
Queue<GraphNode> q = new LinkedList<GraphNode>(); // 用队列存放依次要遍历的元素
q.offer(node);
while (!q.isEmpty()) {
GraphNode currNode = q.poll();
if (!visited.contains(currNode)) {
visited.add(currNode);
System.out.println("节点:" + currNode.getLabel());
for (int i = 0; i < currNode.edgeList.size(); i++) {
q.offer(currNode.edgeList.get(i).getNodeRight());
}
}
}
}
} 















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









