







 本文深入剖析MapReduce的核心思想与工作流程,重点解析Shuffle过程,包括为何进行Shuffle、何时触发以及详细步骤。讨论了环形缓冲区大小、分区与排序策略、Combiner使用及Reduce数据存储等问题,并探讨了MapReduce程序中的优化点,如切片机制与分区策略。
本文深入剖析MapReduce的核心思想与工作流程,重点解析Shuffle过程,包括为何进行Shuffle、何时触发以及详细步骤。讨论了环形缓冲区大小、分区与排序策略、Combiner使用及Reduce数据存储等问题,并探讨了MapReduce程序中的优化点,如切片机制与分区策略。
目录
1、环形缓冲区的大小/shuffle过程的瓶颈,你会怎么解决
2、为什么在Map和Reduce阶段系统默认必须要对Key进行排序?
4、如果分区数不是1,但是ReduceTask为1,是否执行分区过程
一、MapReduce的核心思想
(1)分布式的运算程序往往需要分成至少 2 个阶段。
(2)第一个阶段的 MapTask 并发实例,完全并行运行,互不相干。
(3)第二个阶段的 ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有 MapTask 并发实例的输出。
(4)MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。
二、MapReduce的整个工作流程
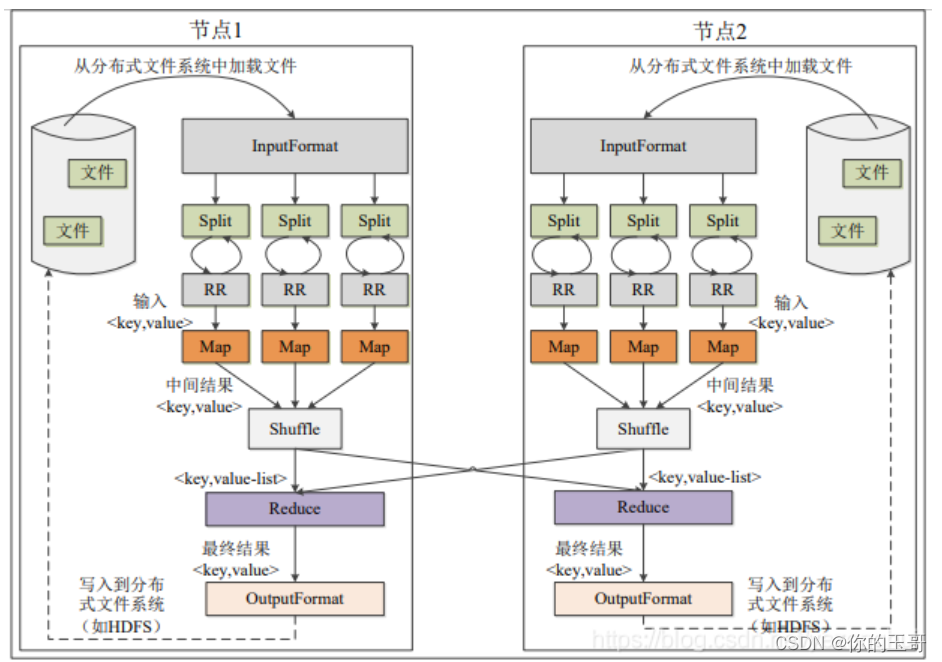
1、MapReduce框架使用InputFormat模块做map前的数据预处理,该模块包括两个方法:RecorderReader进行读取,还有一个方法用来判断是否可以切割。InputSplit是MapReduce对文件进行处理和运算的基本单位,只是逻辑切分,而非物理切分,它只包含一些元数据信息,比如数据起始位置,数据长度,数据所在节点等。
2、RecordReader(RR)根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并将其转换为适合Map任务读取的键值对,输入给Map任务。
3、客户端再提交之前会向yarn提交申请运行MRappmaster的资源,之后yarn会分配资源启动mrappmaster,mrappmaster会根据客户端的资源提交路径(hdfs路径),包括切片等信息,来计算MapTask的数量,之后向yarn申请资源开始执行maptask;
4、运行map任务,Map任务会根据用户自定义的映射规则,输出一系列的<key , value>到内存缓冲区中。开始Shuffle。
5、为了让Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区(Partition),排序(Sort),合并(Combine),归并(Merge)等操作。得到<key, value-list>形式的中间结果,再交给对应的Reduce来处理。从无序的<key, value>到有序的<key , value-list>这个过程称为shuffle。
6、Reduce以一系列<key, value-list>中间结果作为输入,执行用户定义的逻辑,输出结果交给OutputFormat模块,OutputFormat模块会验证输出目录是否已经存在,如果满足,就输出Reduce中的结果到分布式文件系统存储。
三、Shuffle的过程
3.1 为什么要进行Shuffle
为了让reduce可以并行处理Map的结果。因为对于reduce来说,处理函数的输入是key相同的所有value,但是这些value的所在的数据集(也就是map的输出)在不同的节点上,因此需要对map的输出进行重新组织,使得同样的key进入相同的reducer,也就是说需要把map产生的无序的<key , value>转换成有序的<key, value-list>.
3.2什么时候需要Shuffle
shuffle移动了大量的数据,对计算、内存、网络和磁盘都有巨大的消耗,因此,只有确实需要shuffle的地方才应该进行shuffle,否则尽可能避免shuffle。这也是为什么有些任务能只在map端完成就在map端完成,因为此时不需要Shuffle,效率会高。
什么时候需要Shuffle?
1、去重操作:distinct等;2、聚合,byKey类操作:group By Key、sort By Key等;3、排序操作:sort By Key等;4、join操作:两个表进行join,就必须将相同join key的数据,shuffle到同一个节点上,然后进行相同key的两个表数据的笛卡尔乘积。
3.2 Shuffle的详细过程
当运行map任务输出一系列<k, v>到内存缓冲区中,Shuffle开始:(环形缓冲区 数组)
1、当环形缓冲区达到80%时,开始溢写到本地磁盘;--->默认缓冲区大小是多少,可以不可以增大
2、在溢写的过程中,会调用partitioner进行分区,(先按照分区编号partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序)。并针对每个分区内部按key进行排序(快速排序);---->为什么分区、分区的原理、为什么是快速排序
3、可以选择Combiner进行合并,提前进行聚合,在写入文件之前,对每个分区中的数据进行一次聚集操作;---->所有任务都适合Combiner合并吗
4、当某一个maptask溢写完成之后,这个maptask产生的多个溢写文件会合并成大的溢写文件放在本地磁盘,在合并过程中,会对同一分区的数据根据key进行归并排序,形成分区间有序; 让一个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
注意这里:

5、ReduceTask会根据自己的分区号,从各个maptask机器上提取自己分区的数据;--->这些数据抓取过来放到哪了 内存or磁盘?
6、reducetask会抓取到同一分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)形成大文件,shuffle结束;后面进入ReduceTask 的逻辑运算过
程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8604
8604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









