






@author--HCF
环境安装
pip install requests os shutil multiprocessing img2pdf shutil re
requests库用于爬虫获取网页数据os, shutil库用于文件操作(代码中os库用于创建文件夹,shutil库用于删除文件夹)multiprocessing库用于异步爬虫,使用线程池加快下载速度img2pdf库用于将图片合并为pdf文件re库用于正则匹配,在代码中获取一个通用的url
参数设置
首先获取图片url,进入想下载的pdf页面,如下图
在当前页面中右键选择检查,然后点击弹出窗口的左上角进行元素定位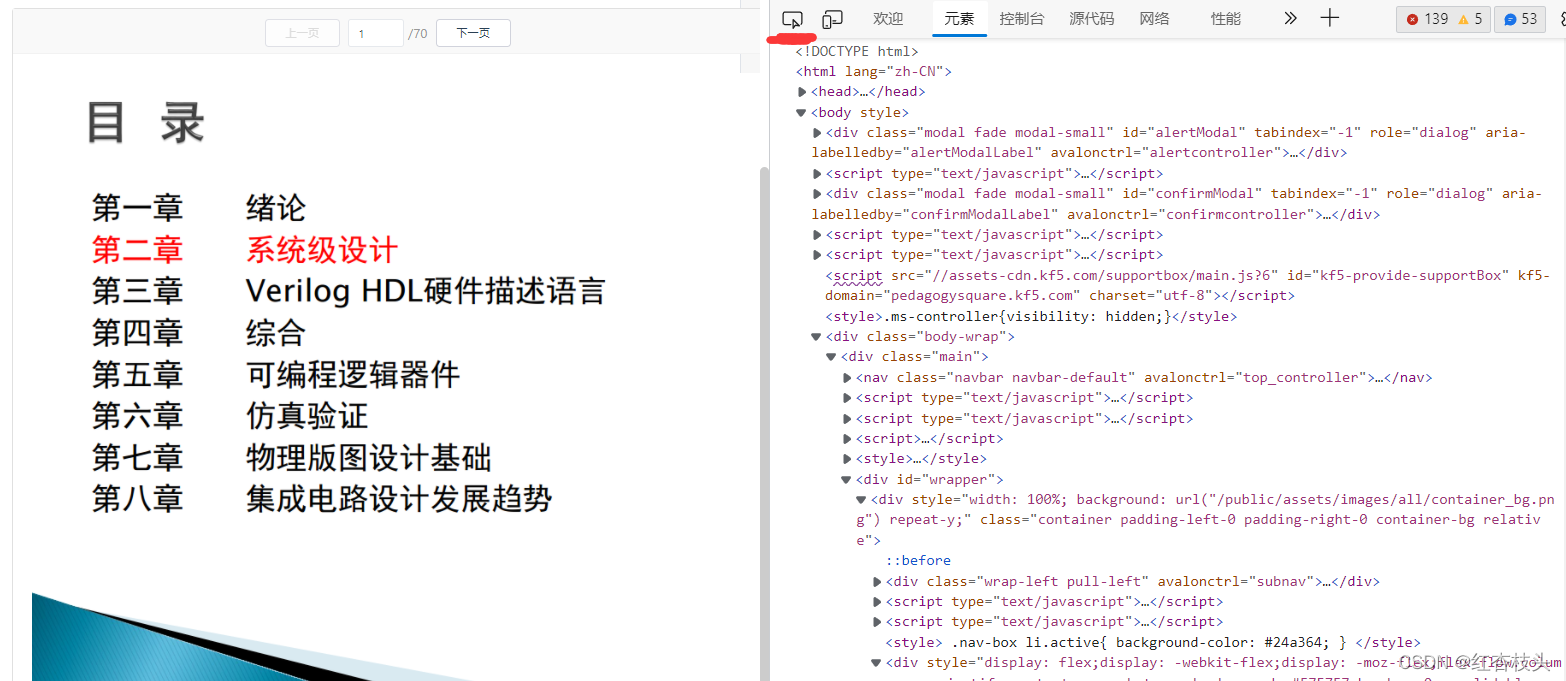
点击之后在原来页面中点击pdf界面,然后会定位到鼠标所在的标签,如图中所示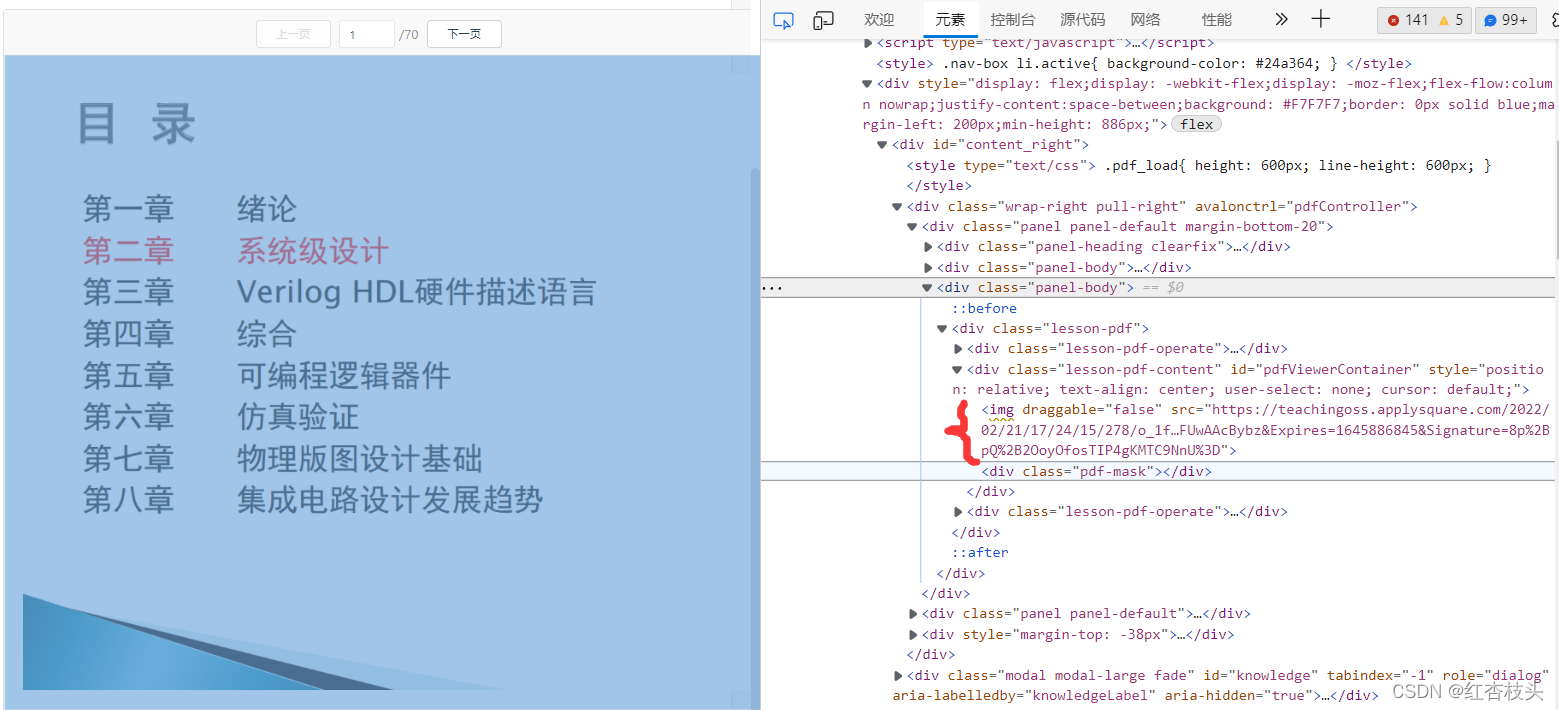
通过上面的定位可以发现img标签,里面的src属性则是我们想要的图片url,双击复制即可。
为确保程序正常运行,我们还需要设置图片数量,即

并在代码中修改文件名称。修改了上面三个地方就可以获取到pdf了!
代码
import requests
import os
from tqdm import tqdm
from multiprocessing.dummy import Pool
import time
import img2pdf
import shutil
import re
# ========================以下地方需要修改====================
total_page = 70
pdf_name = "pdfName"
url = "https://xxxxxxxxxxxxxxx/0.png?xxxxxxxxxxxxxxxxx"
# ========================以上地方需要修改====================
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
def get_image(url_dict):
new_url = url_dict['url']
img_name = url_dict['img_name']
data = requests.get(url=new_url, headers=headers).content
with open(img_name, 'wb') as fp:
fp.write(data)
def main():
# 判断文件名是否以.pdf结尾
global pdf_name
if not pdf_name.endswith('.pdf'):
pdf_name = pdf_name + '.pdf'
# 新建一个文件夹用于存放每张图片
img_path = "./tmp_data"
if not os.path.exists(img_path):
os.mkdir(img_path)
# 获取一个通用的url
global url
url = re.sub(r'\d+\.png\?', '{0}.png?', url)
# 所有图片相关信息-url和名称
url_list = [{"url": url.format(i), "img_name": img_path + '/%03d' % (i + 1) + '.png'} for i in range(total_page)]
# # 单线程下载
# for i in tqdm(range(total_page)):
# new_url = url.format(i)
# img_name = img_path + '%03d' % (i + 1) + '.png'
# data = requests.get(url=new_url, headers=headers).content
# with open(img_name, 'wb') as fp:
# fp.write(data)
# 线程池下载
start_time = time.time()
pool = Pool(40)
pool.map(get_image, url_list)
pool.close()
pool.join()
print("图片下载完成!共耗时:%.2fs" % (time.time() - start_time))
# 将下载的所有图片合并为pdf
start_time = time.time()
photo_list = [(img_path + '/%03d' % (i + 1) + '.png') for i in range(total_page)]
a4inpt = img2pdf.mm_to_pt(794), img2pdf.mm_to_pt(1122)
# layout_fun = img2pdf.get_layout_fun(a4inpt)
with open(pdf_name, "wb") as fp:
fp.write(img2pdf.convert(photo_list))
print("PDF合成完成!共耗时:%.2fs" % (time.time() - start_time))
# 删除图片
shutil.rmtree(img_path)
if __name__ == "__main__":
main()
注意事项
- 此代码仅供参考,非必要不建议传播老师课件,后果自负
- 代码仅针对发布的pdf文件,其他文件的爬取可以使用类似方法
- 代码有待改进,有空再来
使用selenium库模拟浏览器操作,具体可参考这里
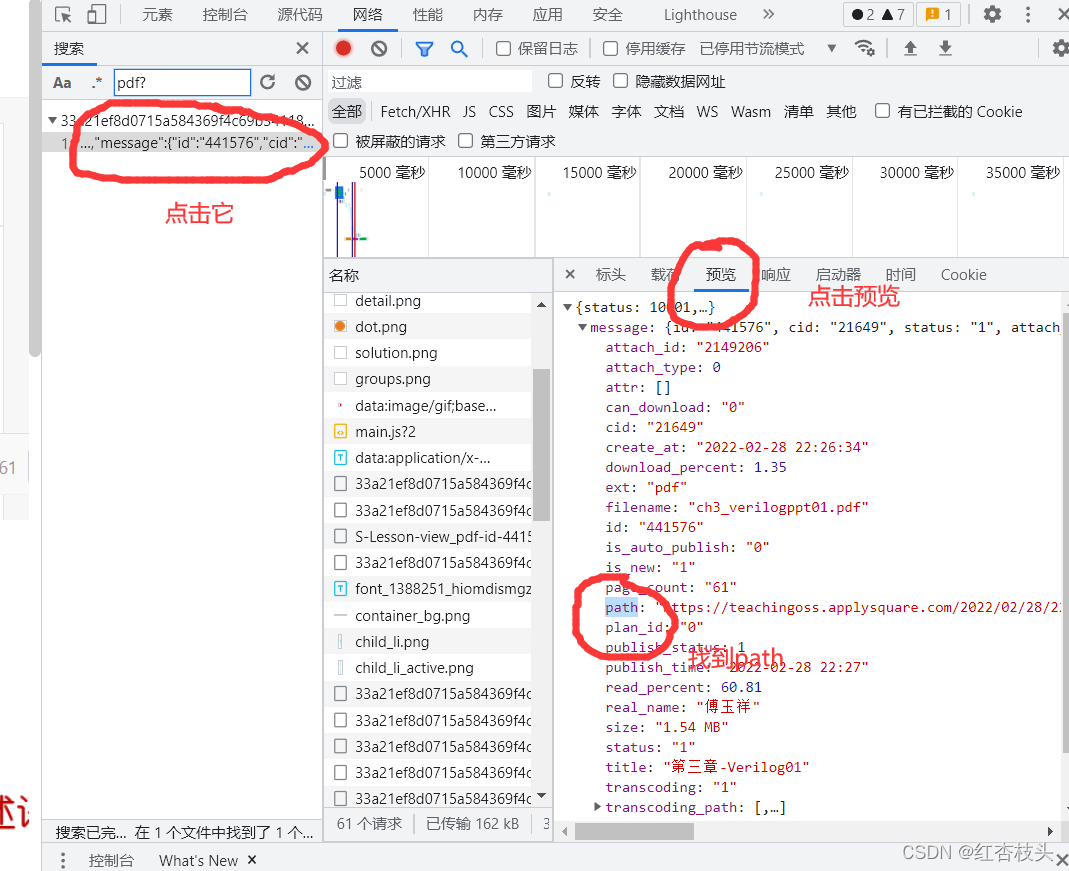
直接在所需pdf页面右键打开抓包工具(点击检查),然后点击网络,再点击弹出界面的左上角的第二个图标清除接收到的数据包,再点击刷新,重新抓取数据包,然后随便点击一个数据包,按Ctrl+F搜索文件,此时会弹出搜索框
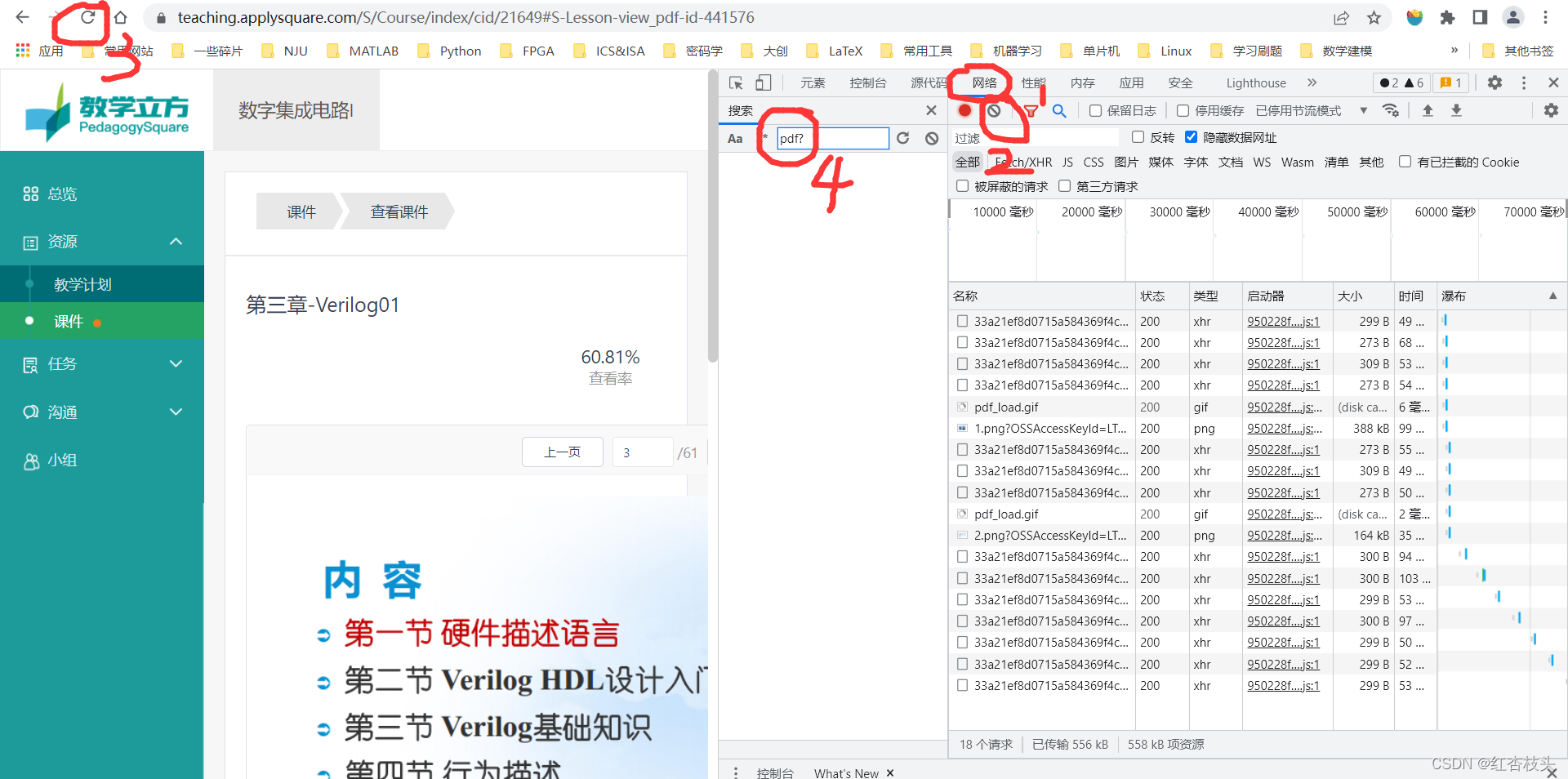
输入pdf?然后Enter点击对应的数据包,之后会显示数据包详细信息,点击预览并找到里面的path属性,后面对应的url就是我们想要的文件的地址,复制然后在新的页面中打开即可自动弹出下载页面,之后则可下载。

















 6549
6549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









