







本文资料收集于互联网,内容大部分为转载+汇总,主要是针对不平衡数据的处理进行一个总结,以便日后翻阅。
常用的分类算法一般假设不同类的比例是均衡的,但是现实生活中经常遇到不平衡的数据集,比如广告点击预测(点击转化率一般都很小)、商品推荐(推荐的商品被购买的比例很低)、信用卡欺诈检测等等。对于不平衡数据集,一般的分类算法都倾向于将样本划分到多数类,体现在模型整体的准确率很高,但是对于极不均衡的分类问题,比如1%-99%的比例,模型会将所有样本都分到99%的类里,这样的模型是没有用的,于是在类不平衡情况下, 一般是对模型使用F值或者AUC值。处理不平衡数据,可以从两方面考虑:一是改变数据分布,从数据层面使得类别更为平衡;二是改变分类算法,在传统分类算法的基础上对不同类别采取不同的加权方式,使得模型更看重少数类。
改变数据分布的方式就是重采样,重采样有三种,一种是欠采样:减少多数类样本的数量,第二种是过采样:增加少数类样本的数量;第三种是综合采样:将过采样和欠采样结合。
欠采样:减少多数类样本数量最简单的方法是随机剔除多数类样本,可以事先设置多数类与少数类最终的数量比例ratio,在保留少数类样本不变的情况下, 根据ratio随机选择多数类样本。还有Tomek links方法。将Tomek link对中属于多数类的样本剔除。欠采样的优点在于操作简单、只依赖于样本分布,不依赖于任何距离信息,属于非启发式方法。缺点在于会丢失一部分多数类样本信息,无法充分利用已有信息。
过采样:过采样的最简单的方法是随机复制少数类样本,事先设置多数类与少数类最终的数量比例ratio,在保留多数类样本不变的情况下,根据ratio随机复制少数类样本。过采样的优点在于操作简单,只依赖于样本分布,不依赖于任何距离信息,属于非启发式方法。缺点是重复样本过多,容易噪声分类器的过拟合。过采样中有一类常用的方法是SMOTE(synthetic minority over-sampling technique),主要思想来源于手写字识别:对于手写字的图片而言,旋转、扭曲等操作是不会改变原始类别的,因此可以产生更多的样本。SMOTE的主要思想是通过在一些位置相近的少数类样本中生成新样本达到平衡类别的目的,由于不是简单地复制少数类样本,因此可以在一定程度上避免分类器的过拟合。
SMOTE算法流程:
- 设置向上采样的倍率为N,即对每个少数类样本都需要产生对应的N个少数类新样本。
- 对少数类中的每个样本x,搜索得到其K(通常取5)个少数最近邻样本,并且从中随机选择N个样本,记为y1,y2,…,yN(可能有重复)。
- 构造新的少数类样本 r j = x + r a n d ( 0 , 1 ) × ( y j − x ) r_j = x + rand(0,1)\times(y_j-x) rj=x+rand(0,1)×(yj−x),其中rand(0,1)表示区间(0,1)内的随机数。
SMOTE算法代码:
1. 生成类别不平衡数据
#使用sklearn的make_classification生成不平衡数据样本
from sklearn.datasets import make_classification
#生成一组0和1比例为9比1的样本,X为特征,y为对应的标签
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.9, 0.1], n_informative=3,
n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
2. 查看数据分布
from collections import Counter
#查看所生成的样本类别分布,0和1样本比例9比1,属于类别不平衡数据
print(Counter(y))
#Counter({0: 900, 1: 100})
3. SMOTE算法核心语句
#使用imlbearn库中上采样方法中的SMOTE接口
from imblearn.over_sampling import SMOTE
#定义SMOTE模型,random_state相当于随机数种子的作用
smo = SMOTE(random_state=42)
X_smo, y_smo = smo.fit_sample(X, y)
4. 查看经过SMOTE之后的数据分布
print(Counter(y_smo))
#Counter({0: 900, 1: 900})
https://blog.csdn.net/dzysunshine/article/details/89046831
SMOTE算法对所有的少数类样本都是一视同仁的,但实际建模过程中发现那些处于便捷位置的样本更容易被错分,因此利用边界位置的样本信息产生新样本可以给模型带来更大的提升,Borderline SMOTE就是将原始SMOTE算法和边界信息结合的算法,它有两个版本:Borderline SMOTE-1和Borderline SMOTE-2.
Borderline SMOTE-1算法流程:
- 记整个训练集合为T,少数类样本集合为P,多数类样本集合为N。对P中的每一个样本 x i x_i xi,在整个训练集合T中搜索得到最近的m个样本,记其中少数类样本数量为 m i m_i mi。
- 若 m i = 0 m_i=0 mi=0,即 x i x_i xi附近的m个最近的样本均是多数类,认为 x i x_i xi为噪声点,不进行任何操作;若 m i > m 2 m_i> \frac{m}{2} mi>2m,认为 x i x_i xi为安全点,也不进行任何操作,若 0 < m i < m 2 0<m_i<\frac{m}{2} 0<mi<2m,认为 x i x_i xi处于少数类的边界为之,将其加入危险集DANGER。
- 对DANGER中的每一个样本点,采用普通的SMOTE算法生成新的少数类样本。
Borderline SMOTE-2和Borderline SMOTE-1是很类似的,区别是在得到DANGER集合之后,对于DANGER中的每一个样本点 x i x_i xi:
- Borderline SMOTE-1:从少数类样本集合P中得到k个最近邻样本,再随机选择样本点和 x i x_i xi作随机的线性插值产生新的少数类样本(和普通SMOTE算法流程相同)
- Borderline SMOTE-2:从少数类样本集合P和多数类样本集合N中分别得到k个最近邻样本 P k P_k Pk和 N k N_k Nk。设定一个比例 α \alpha α,在 P k P_k Pk中选出 α \alpha α比例的样本点和 x i x_i xi作随机的现行插值产生新的少数类样本。方法同Borderline SMOTE-1;在 N k N_k Nk中选出 1 α \frac{1}{\alpha} α1比例的样本点和 x i x_i xi作随机的现行插值产生新的少数类样本,此处的随机数范围选择的是(0,0.5),即产生的新的样本点更靠近少数类样本。
综合采样:目前为止我们使用的重采样方法都是只针对某一类样本:多多数类样本欠采样,对少数类样本过采样。
普通SMOTE方法生成的少数类样本是通过线性差值得到的,在平衡类别分布的同时也扩张了少数类的样本空间,产生的问题是可能原本属于多数类样本的空间被少数类“入侵”,容易噪声模型的过拟合。于是有人提出将欠采样和过采样综合的方法,解决样本类别分布不平衡和过拟合问题,有两种常用的方法:SMOTE+Tomek links 和SMOTE+ENN。
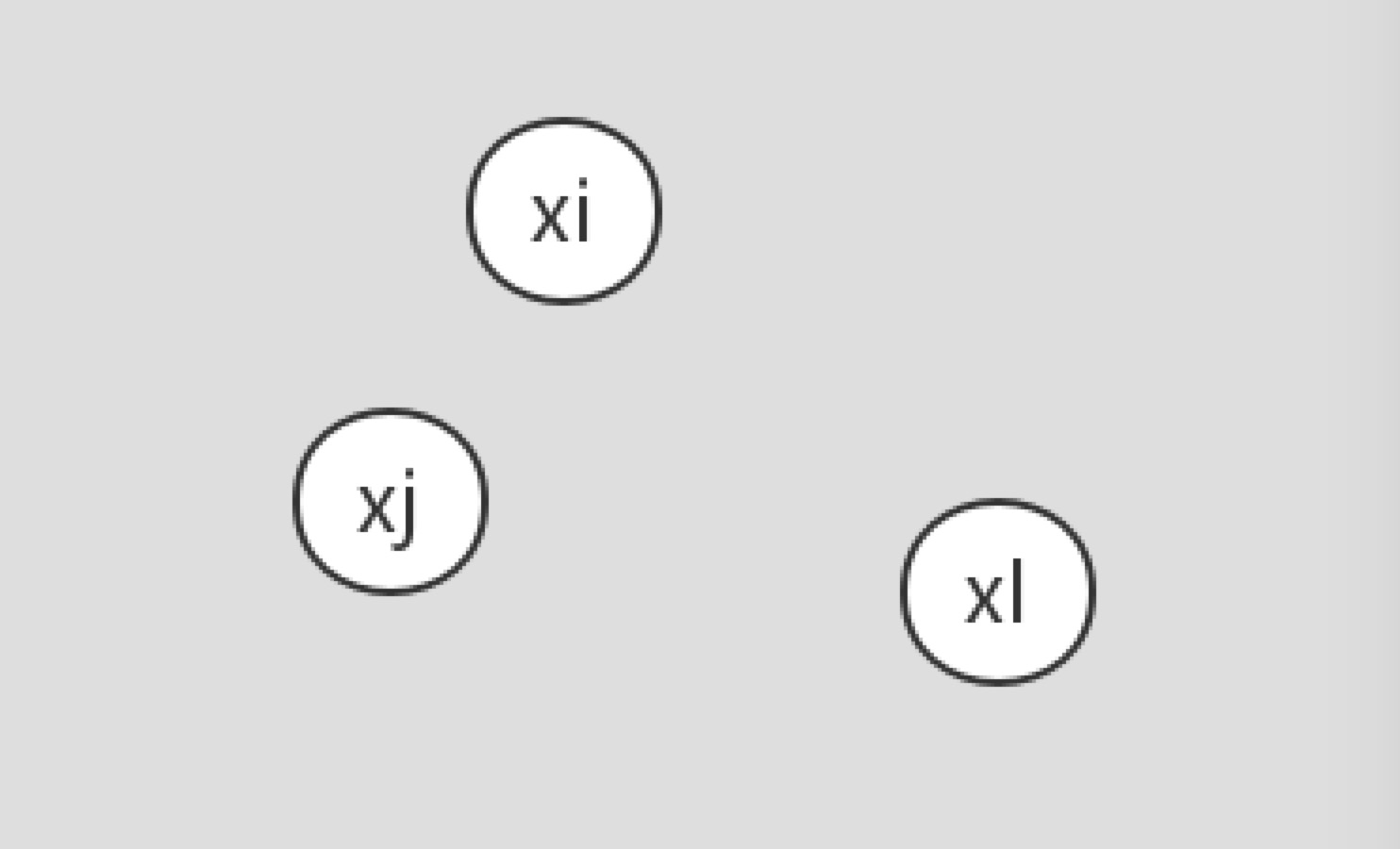
首先介绍Tomek links的定义,假设样本点 x i x_i xi和 x j x_j xj属于不同的类别, d ( x i , x j ) d(x_i,x_j) d(xi,xj)表示两个样本点之间的距离。称 ( x i , x j ) (x_i,x_j) (xi,xj)为一个Timek link对,如果不存在第三个样本点使得 d ( x l , x i ) < d ( x i , x j ) d(x_l,x_i)<d(x_i,x_j) d(xl,xi)<d(xi,xj)或者 d ( x l , x j ) < d ( x i , x j ) d(x_l,x_j)<d(x_i,x_j) d(xl,xj)<d(xi,xj)成立。也就是说 x i x_i xi和 x j x_j xj距离是最近的,但是它们属于不同的类。容易看出,如果两个样本点为Tomek link对,则其中某个样本为噪声(偏离正常分布太多或者两个样本都在两类的边界上)。
SMOTE+Tomek links方法的算法流程非常简单:①利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T。②剔除T中的Tomek links对。
SMOTE+ENN方法和SMOTE+Tomek links的想法和过程都是非常类似的:①利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T。②对T中的每一个样本使用KNN(一般k取3)方法预测,若预测结果和实际类别标签不符,则剔除该样本。
KNN算法的分类预测过程:存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。
https://blog.csdn.net/hajk2017/article/details/82862788
https://www.cnblogs.com/zcjcsl/p/10472771.html
http://www.360doc.com/content/17/0110/15/18144428_621538252.shtml


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









