







文章目录
概念:中间操作的意思是,执行完此方法之后,Stream流依然可以继续执行其他操作
一、总述
常见方法会有以下六个
| 方法名 | 说明 |
|---|---|
Stream<T> filter(Predicate predicate) | 过滤 |
Stream<T> limit(long maxSize) | 获取前几个元素 |
Stream<T> skip(long n) | 跳过前几个元素 |
Stream<T> distinct() | 元素去重,依赖(hashCode() 和 equals()) |
static <T> Stream<T> concat(Stream a, Stream b) | 合并a和b两个流为一个大流 |
Stream<R> map(Function<T, R> mapper) | 转换流中的数据类型 |
注意1:中间方法会返回新的 Stream流,原来的 Steam流 只能使用一次,建议使用链式编程
注意2:修改 Steam流 中的数据,是不会影响原来集合或者数组中的数据
二、过滤
Stream<T> filter(Predicate predicate)
方法的形参是 Predicate,选中它跟进,可以发现它是一个函数式接口。

我们先使用匿名内部类,然后再使用 Lambda表达式 简化
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
//filter 过滤 把张开头的留下,其余数据过滤不要
list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
//如果返回值为true,表示当前数据留下
//如果返回值为false,表示当前数据舍弃不要
return s.startsWith("张");
}
}).forEach(s -> System.out.println(s));
简化为 Lambda表达式
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
注意1:中间方法会返回新的 Stream流,原来的 Steam流 只能使用一次,建议使用链式编程
例如下面不用链式编程,而是直接获取到返回值为 stream1,然后再使用 stream1 来进行过滤。
过滤完成后,再将数据打印,可以发现是没有任何的问题的。
Stream<String> stream1 = list.stream().filter(s -> s.startsWith("张"));
Stream<String> stream2 = stream1.filter(s -> s.length() == 3);
stream2.forEach(s -> System.out.println(s));
但是在下面的代码中,如果还想再次使用 stream1,可以发现就会报错:stream has already been operated upon or closed(流已经关闭了)
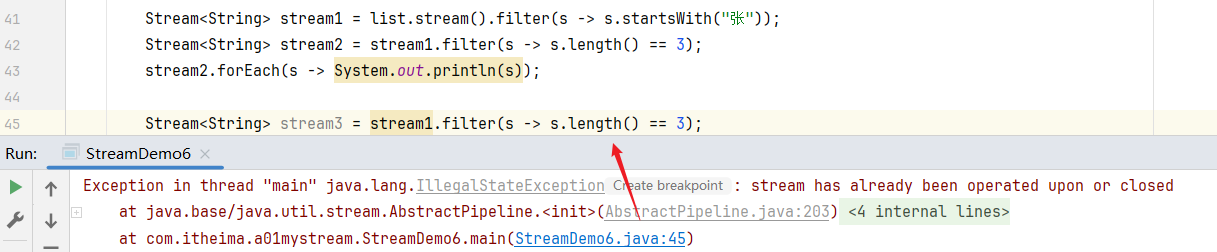
原因是因为,在 42行 这里,stream1 已经用过了,就不能再次使用了。
所以一定要切记:原来的 Steam流 只能使用一次。
既然只能使用一次,那么我们就没有必要再去用一个变量去记录了,因此建议使用链式编程。
因此当 Stream流 写熟了后发现,所以的操作一行就搞定了,代码非常的简单。
但是代码变少了也会有一个小弊端:代码的阅读性降低。
因此我们一般都会将链式编程的每一个操作都折行,这样就会提高代码的阅读性。
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
注意2:修改 Steam流 中的数据,是不会影响原来集合或者数组中的数据
例如上面我们对集合做了两次过滤,此时再来打印集合,此时集合里面的数据是不会改变的。
三、获取前几个元素
maxSize 跟索引没有关系,就是字面意思:几个元素
Stream<T> limit(long maxSize)
代码示例
// "张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤"
list.stream().limit(3).forEach(s -> System.out.println(s)); // 张无忌 周芷若 赵敏
四、跳过前几个元素
参数 n 表示的也是个数
Stream<T> skip(long n)
代码示例
// "张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤"
list.stream().skip(4).forEach(s -> System.out.println(s)); // 张三丰 张翠山 张良 王二麻子 谢广坤
五、limit 和 skip 练习
课堂练习:在 "张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤" 中获取以下元素
"张强", "张三丰", "张翠山"
代码示例
//第一种思路:
//先获取前面6个元素:"张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山",
//然后跳过前面3个元素
list.stream().limit(6).skip(3).forEach(s -> System.out.println(s));
//第二种思路:
//先跳过3个元素:"张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤"
//然后再获取前面3个元素:"张强", "张三丰", "张翠山"
list.stream().skip(3).limit(3).forEach(s -> System.out.println(s));
六、元素去重
Stream<T> distinct()
代码示例
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "张无忌","张无忌","张无忌", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
list1.stream().distinct().forEach(s -> System.out.println(s));
PS:distinct() 在底层是依赖 hashCode() 和 equals() 进行去重的。
由于在 String 中,Java已经帮我们重写好了这两个方法,因此我们直接使用就行了。
但如果集合中装的是 自定义对象,那么一定要手动重写。
我们可以简单看一下 distinct() 里面的源码,源码非常的复杂,我们只需要找里面的核心点就行了。
选中 distinct() ctrl + b,如果直接 ctrl +b ,那么它就是跳到接口里面的方法。
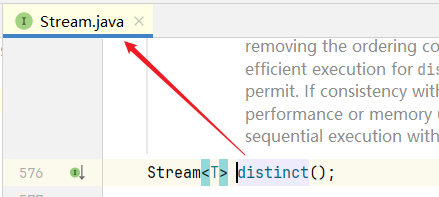
而我们需要看的是它的实体类,因此需要采用以下方法,或者 ctrl + alt + b
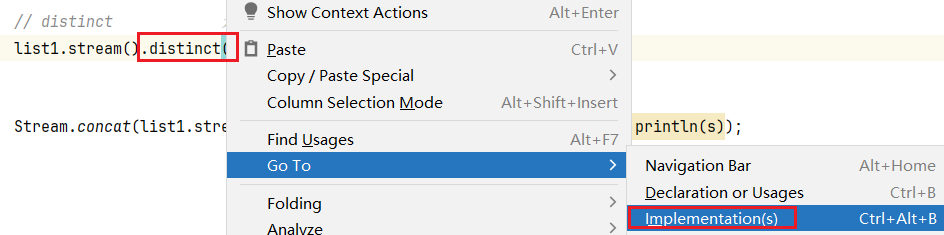
它底层会调用 makeRef(),继续跟进

点进去后,可以发现它的源码超级多,但不要慌,我们真正看的是里面的一个核心点:keys = new HashSet<>(keys);。
所以我们就知道,在底层是通过 HashSet 进行去重的。

HashSet 在存储自定义元素的时候,需要重写 hashCode() 和 equals()。
七、合并a和b两个流为一个大流
在合并的时候,尽可能要保证两个流中的数据类型是一致的。
如果第一个流数据类型是 a,第二个流数据类型是 b,那么这个时候在合并的时候,它的类型就是 a 跟 b 共同的父类了,这样就相当于它做了一个类型的提升,在提升之后,它是无法使用子类里面的特有功能的。
static <T> Stream<T> concat(Stream a, Stream b)
这个方法是 Stream 里面的静态方法,所以在使用的时候需要使用类名调用
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "张无忌","张无忌","张无忌", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2, "周芷若", "赵敏");
// 方法参数中传递需要合并的两个流,程序运行完毕发现,前面是第一个流里面的数据,后面就是第二个流中的
Stream.concat(list1.stream(),list2.stream()).forEach(s -> System.out.println(s)); // 张无忌 张无忌 张无忌 张强 张三丰 张翠山 张良 王二麻子 谢广坤 周芷若 赵敏
八、转换流中的数据类型
Stream<R> map(Function<T, R> mapper)
需求:只获取里面的年龄并进行打印
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-15", "周芷若-14", "赵敏-13", "张强-20", "张三丰-100", "张翠山-40", "张良-35", "王二麻子-37", "谢广坤-41");
分析:流里面原本的数据是 String 类型的,最终我需要获得 int 类型的。
因此需求其实就是将 String 变成 int类型。
map() 的形参是 Function,而 Function 又是函数式接口。接口中有一个 apply()
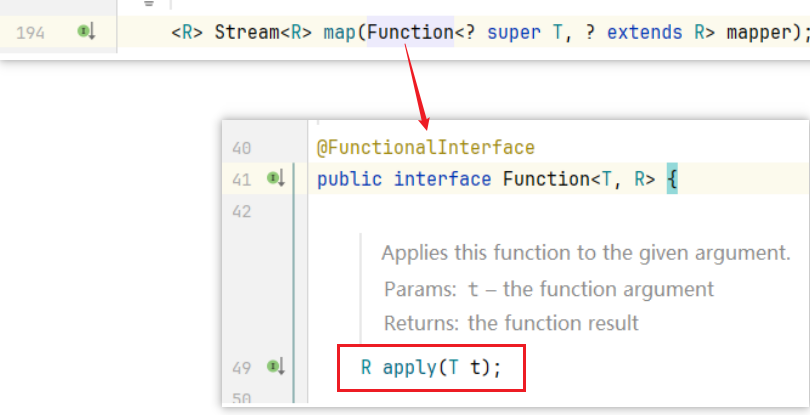
在 Function 中有两个泛型:
- 第一个类型:流中原本的数据类型
- 第二个类型:要转成之后的类型
apply的 形参s:依次表示流里面的每一个数据;返回值:表示转换之后的数据。
我们的需求是将字符串变成 int类型,但是不能直接将 int 写在泛型里,因为泛型里面不能写基本数据类型。

因此正确写法应该是写成:Integer,同样 apply() 的返回值需要与 Function 的泛型相对应,这两个都表示转换之后的类型。
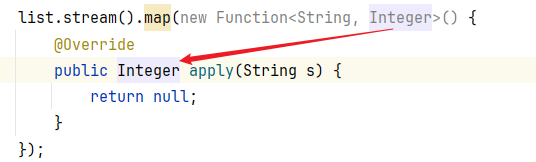
list.stream().map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
String[] arr = s.split("-");
String ageString = arr[1];
int age = Integer.parseInt(ageString);
return age;
}
})
//当map方法执行完毕之后,流上的数据就变成了整数
//所以在下面forEach当中,s依次表示流里面操作完毕后的每一个数据,这个数据现在就是整数了
.forEach(s-> System.out.println(s));
改成 Lambda表达式
list.stream()
.map(s-> Integer.parseInt(s.split("-")[1]))
.forEach(s-> System.out.println(s));
















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









