







一、画图分析
这个东西会有一点点小难,并且以后用到的记录也很小,那为什么还要学呢?
其实就是因为想给大家开阔一下眼界,让你知道的更多,在写代码的时候考虑的事情更加的全面。
首先来看读取数据的底层原理,在读取数据的时候,肯定要有一个数据源,假设数据源的编码规则是 UTF-8,现在我们要利用字符输入流把数据读取到内存中,当我们创建了 FileReader对象 的时候,就好比是内存跟文件之间有了一个连接的通道,但是与此同时在创建 FileReader对象 的时候,在底层还创建了一个长度为 8192 的字节数组,这个字节数组我们也称之为 缓冲区。
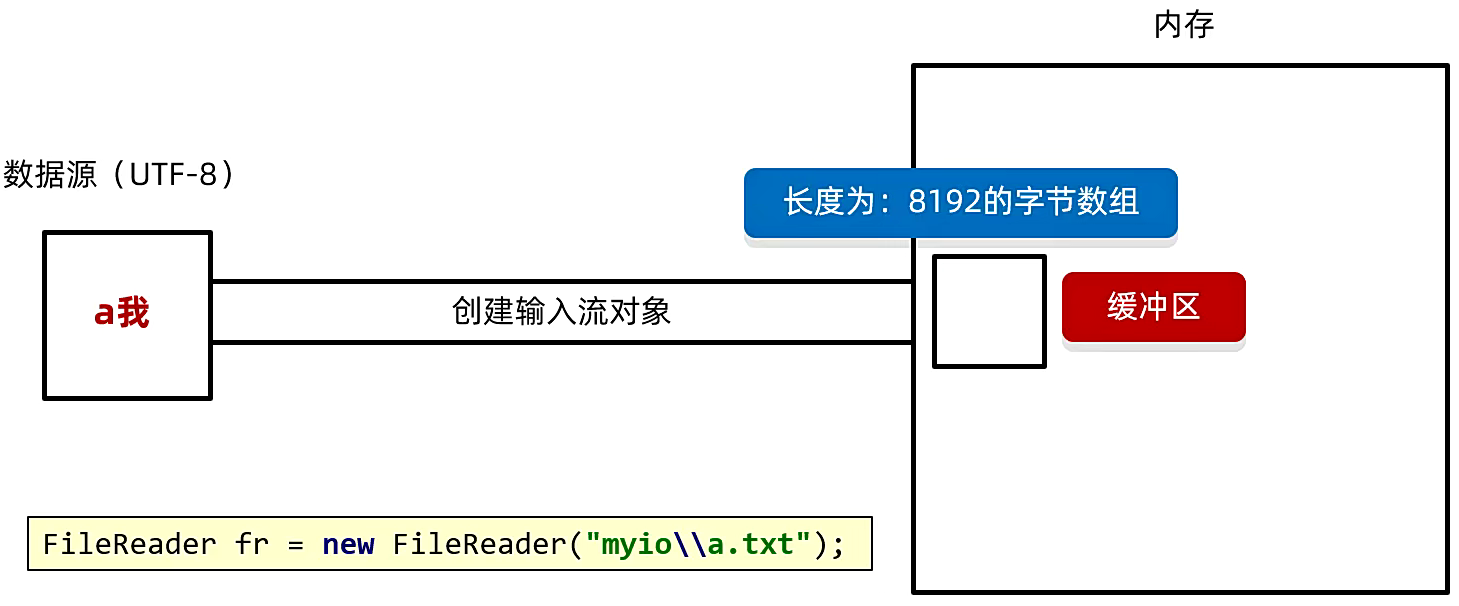
接下来我们会读下面的代码。
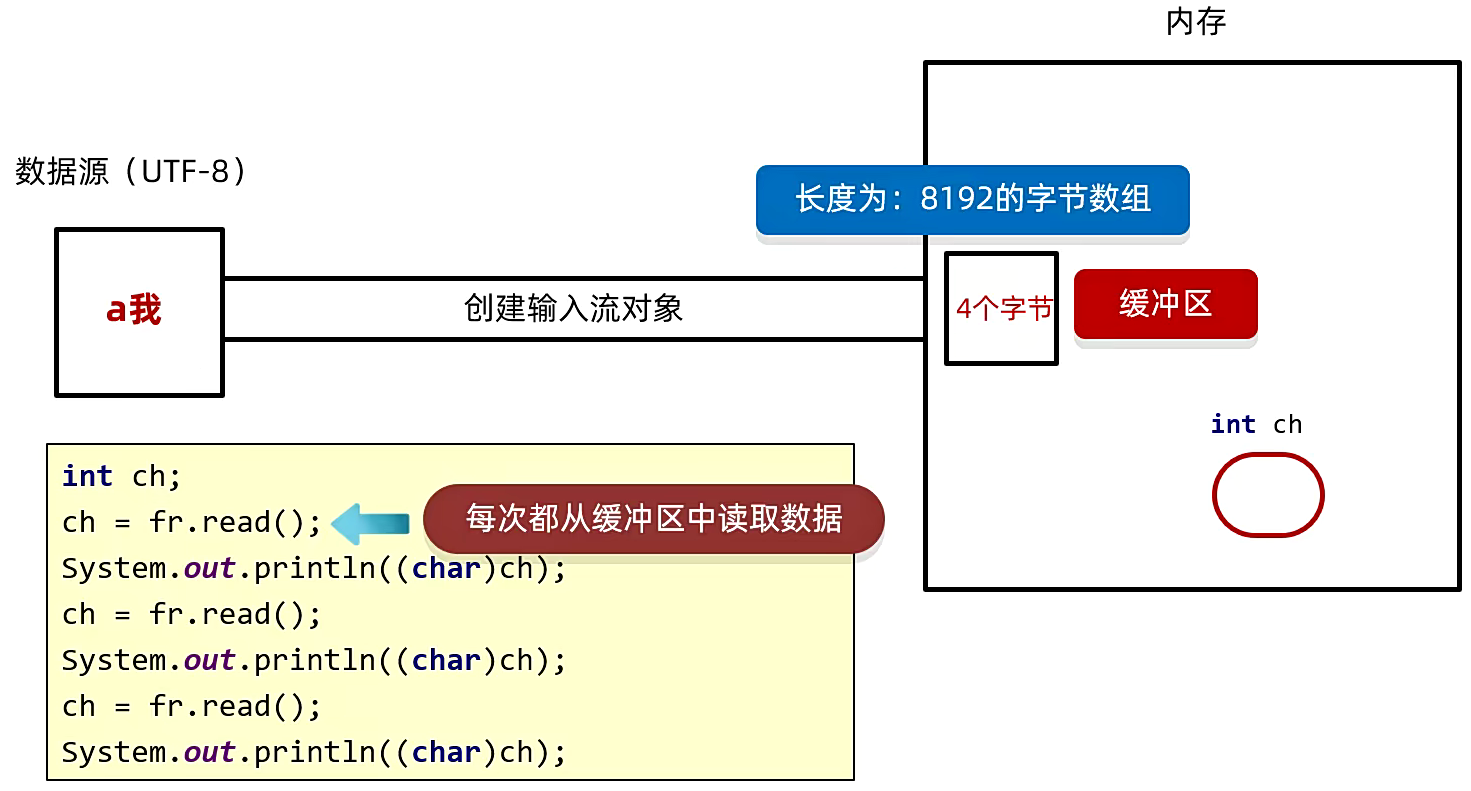
首先定义了一个 int类型的变量 ch,在内存中,这个变量就出现了,但是此时这个变量里面是没有赋值的,接下来利用空参的 read方法 第一次读取。
每次在读取的时候,它会去判断缓冲区中,是否有数据可以被读取。
由于现在是第一次读,第一次里面肯定是空的,没有任何数据。
如果没有,就会从文件中读取数据,装到缓冲区中,尽可能装满缓冲区。
因此此时它就会从文件中获取 8192个字节 放到缓冲区中,但是现在文件中没有那么多数据,只有 a我(一共四个字节),因此现在它就会将这四个字节放到缓冲区中。
接着每次读取的时候就会从缓冲区中读取数据,这样它的效率会更高,减少了频繁到硬盘中读取数据的过程,因此缓冲区就是为了提高效率的。
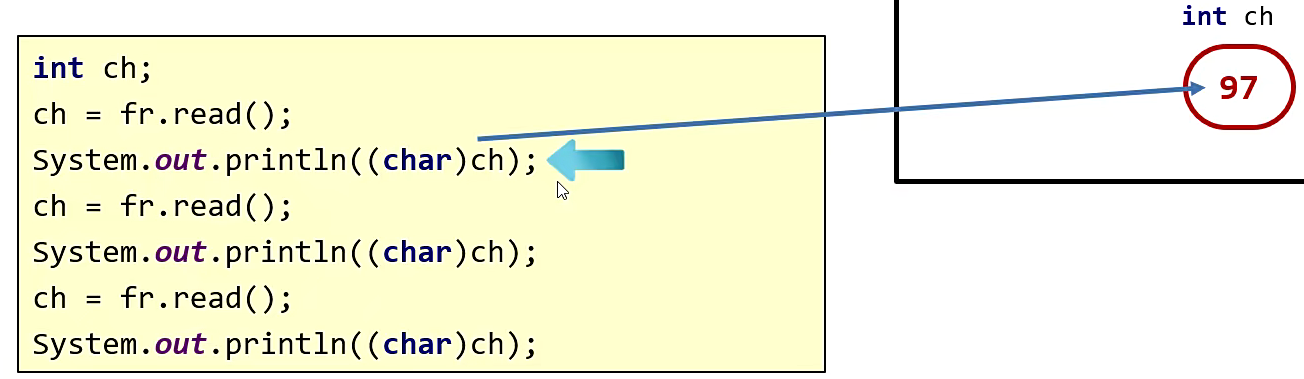
那么现在,第一次从缓冲区中读,读的是第一个字节,它将第一个字节按照 UTF-8 的形式进行解码,并转成十进制,再赋值给变量 ch,因此 ch 中记录的就是 97。
然后再将 ch 强制转成字符再进行打印,因此打印出来的就是小写 a。
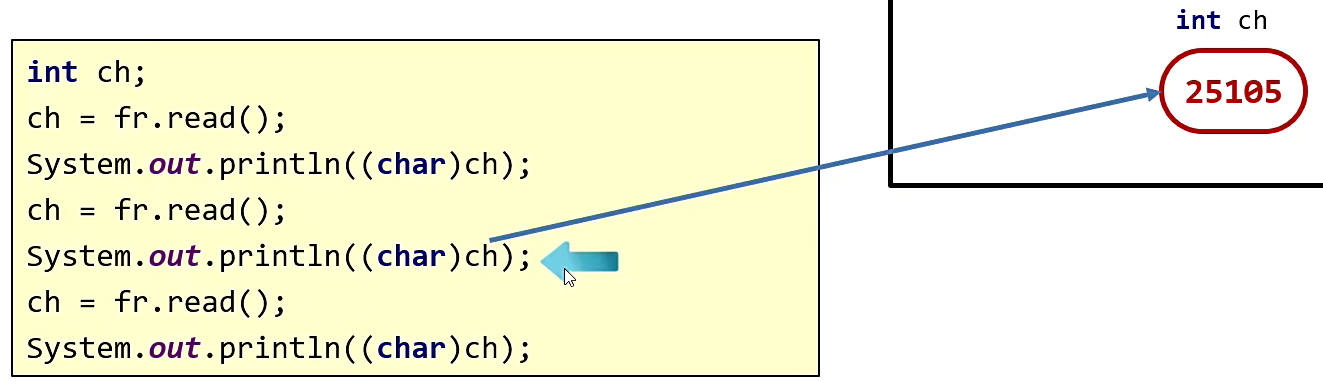
继续往下,第二次 read(),字符流在读取的时候,首先它都会去判断缓冲区中是否有数据可以被读取。
如果没有,就会从文件中读取数据,装到缓冲区中,尽可能装满缓冲区。
但是如果有数据,它就不会找文件了,而是直接从缓冲区中读取数据。
在第二次读取的时候它发现,这里的第二个字节是中文的,所以一次性会读取三个字节,并按照 UTF-8 的形式进行解码,转成十进制 25105 再赋值给变量 ch。
此时在代码中将 ch 强转为 字符,再进行打印,因此第二次打印的就是汉字 我。
继续往下第三次读取,首先它还是会先判断缓冲区中是否有数据可以被读取。
如果没有,就会从文件中读取数据,尽可能装满缓冲区。
但是文件里面也没有剩余的数据了,此时就返回 -1,再将 -1 赋值给 ch。

这个就是 read方法 完整的底层原理。
二、总结
① 当我们在创建字符输入流对象的时候,在底层它会关联文件,而且会创建一个缓冲区,所谓缓冲区就是一个 长度为8192的字节数组。
但是创建字节输入流(FileInputStream)它底层是没有缓冲区的。
② 读取数据的底层会比较麻烦
1、判断缓冲区中是否有数据可以被读取
2、如果缓冲区没有,就会从文件中读取数据,装到缓冲区中,尽可能装满缓冲区。
- 但如果文件中也没有剩余的数据了,此时返回
-1,表示读到了文件的末尾。
3、但是如果缓冲区有数据,它就不会找文件了,而是直接从缓冲区中读取数据。
-
空参的
read方法:一次读取一个字节,遇到中文一次读多个字节,把字节解码并转成十进制进行返回而这里十进制的数字就是英文/汉字在字符集中所对应的数字。
因此如果你不想看到这些数字,而是真实的英文字母/汉字,还需要手动强转。
-
有参的
read方法:在刚开始的时候,有参的read方法也会去看缓冲区,但是它在读取的时候,将读取字节,解码,强转三步进行合并了,它会将强转后的字符放到数组中。
因此这两个 read方法 还是有区别的,有参的 read方法 多了一个强转;而空参 read方法 返回的是解码后的十进制数据,如果想看到那个字符,还需要我们自己手动进行强转。
三、验证结论
准备代码:关联 myio模块 下的 a.txt,然后读取四次,最后释放资源。
FileReader fr = new FileReader("myio\\a.txt");
int b1 = fr.read();
System.out.println(b1);
int b2 = fr.read();
System.out.println(b2);
int b3 = fr.read();
System.out.println(b3);
System.out.println((char) b3);
int b4 = fr.read();
System.out.println(b4);
fr.close();
接下来我们要来验证,① 创建对象的时候它底层到底有没有那个缓冲区;② 第一次读取的时候它会不会把文件里面的数据撞到缓冲区中。
下面用 debug 的方式带你一步一步去查看,先打断点,然后右键 debug
此时第8行代码变成深蓝色了,表示这一行代码现在还没有执行,但准备要执行。

此时点击 下一步,这就表示创建对象的这行代码已经执行完毕。
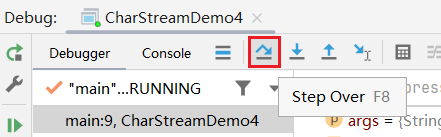
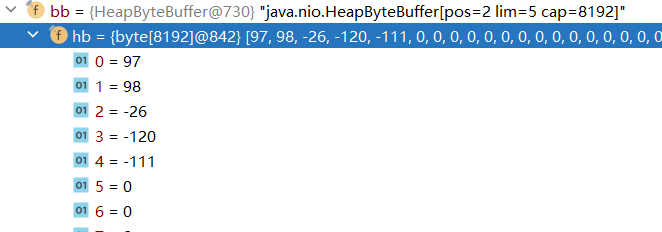
在 fr 里面它会有很多的数据,我们要一个一个打开,找找这里的 bb,这个 bb 就是我们刚刚所说的 缓冲区。
可以发现它是 byte字节类型 的,长度为 8192,因此我们就知道了,FileReader 底层的缓冲区其实就是一个 长度为8192的字节数组。
刚开始创建出来的时候,数组里什么都没有,都是 0。
接下来执行 read方法,第一次读取的时候,它会把文件里的字节装到缓冲区中,而且是尽可能将缓冲区装满。
现在在文件中只有 ab我,a 一个字节,b 一个字节,我 三个字节,因为IDEA默认是 UTF-8。
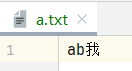
所以它总共只有五个字节,不够 8192,因此它就会将这五个字节全部装到缓冲区中。
可以发现前面的 97、98 就是 a跟b,下面的 -26/-120/-111 这三个字节其实就是 我。
此时我们就知道了,在第一次读取的时候,它会把文件里的数据放到缓冲区中,而且会尽可能将缓冲区装满。
但是如果文件里的数据比较少,此时就是有多少装多少。
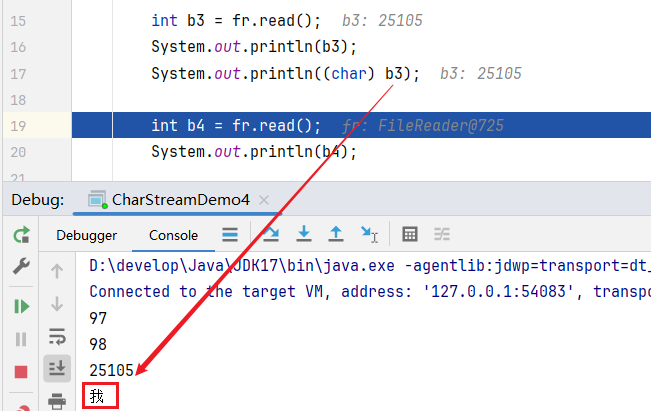
接下来就会从缓冲区中读取数据,第一次读取到的就是 97。

在继续往下,第二次读的时候 98。

第三次在读取的时候,读到了 -26,此时就知道了,当前是一个中文,中文在 UTF-8 中是占三个字节的,因此第三次会把 -86/-120/-111 三个字节一起读取并进行解码,再转成十进制,转完后就是 25105,再赋值给 b3。

而 25105 就是 我 这个汉字在 Unicode 中所对应的数字,如果不想看到这个数字,就需要进行手动强转。
此时控制台中就打印出了 我
继续往下,第四次读取的时候,缓冲区里面其实已经没有数据再让你去读了,此时它会再次到文件中看文件里是否还有剩余的数据。
如果文件里面也没有了,此时方法会返回 -1,此时 b4 就是 -1,表示文件已经读完。

最后就是 close() 关流,整个资源就释放掉了。
四、扩展1
如果文件中数据比较多的时候,它是怎么读取的呢?
准备了 b.txt ,它的大小为 8193,里面写了 8192个a 和 1个b 刚好多出一个字节
FileReader fr = new FileReader("myio\\b.txt");
fr.read();//会把文件中的数据放到缓冲区当中
//清空文件
FileWriter fw = new FileWriter("myio\\b.txt");
//在循环里面读8192次
for (int i = 0; i < 8192; i++) {
fr.read();
}
//在循环外面再去读第8193次
fr.read();
fr.close();
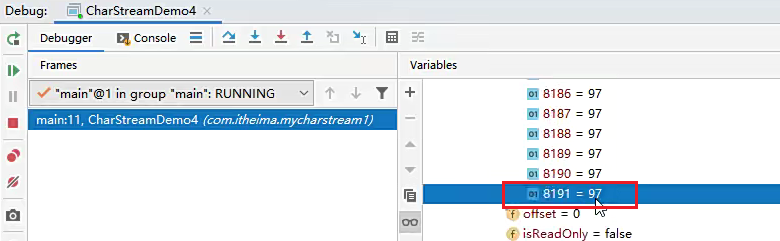
打断点,第一次读取的时候会将文件中的数据读取到缓冲区,尽可能装满缓冲区,可以发现数组的最后一个装的还是 97。
因此在缓存区中已经将文件里面前面 8197个a 全都放进去了。
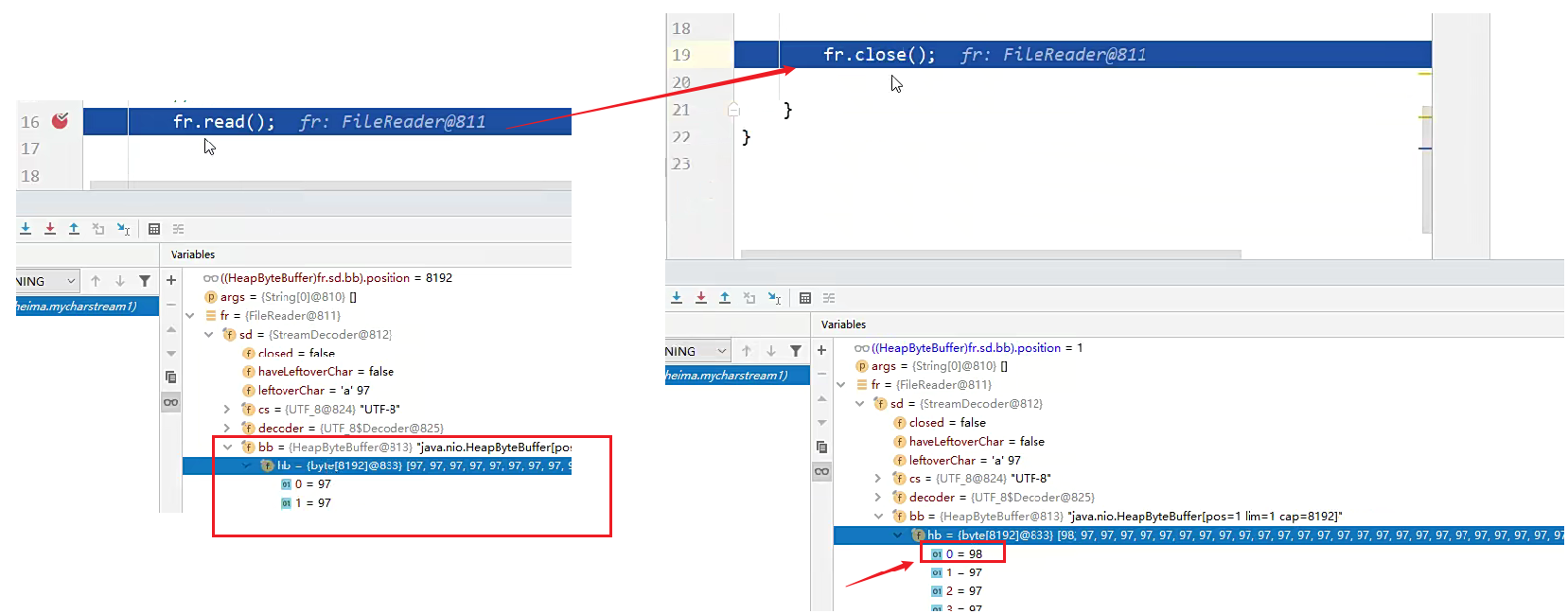
前面的读取都是先从缓冲区中读取,直到缓冲区中的数据全部读取完,它才会到缓冲区中拿。
如果要验证它是怎么从缓冲区中拿的,此时我们可以将可以将断点打在 16行 的前面。
读取完后,发现它将 b 读取到了,并放到了缓冲区中。
五、扩展2
FileReader fr = new FileReader("myio\\b.txt");
fr.read();//会把文件中的数据放到缓冲区当中
//清空文件
FileWriter fw = new FileWriter("myio\\b.txt"); // 但是它只能清空文件,不能清空缓冲区
//请问,如果我再次使用fr进行读取,会读取到数据吗?
//此时循环读取的时候,会把缓冲区中的数据全部读取完毕,读完了才会去文件中看
//正确答案:
//会打印,但是只能读取缓冲区中的数据,文件中剩余的数据无法再次读取
int ch;
while((ch = fr.read()) != -1){
System.out.println((char)ch);
}
fw.close();
fr.close();
















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









