







文章目录
一、前言
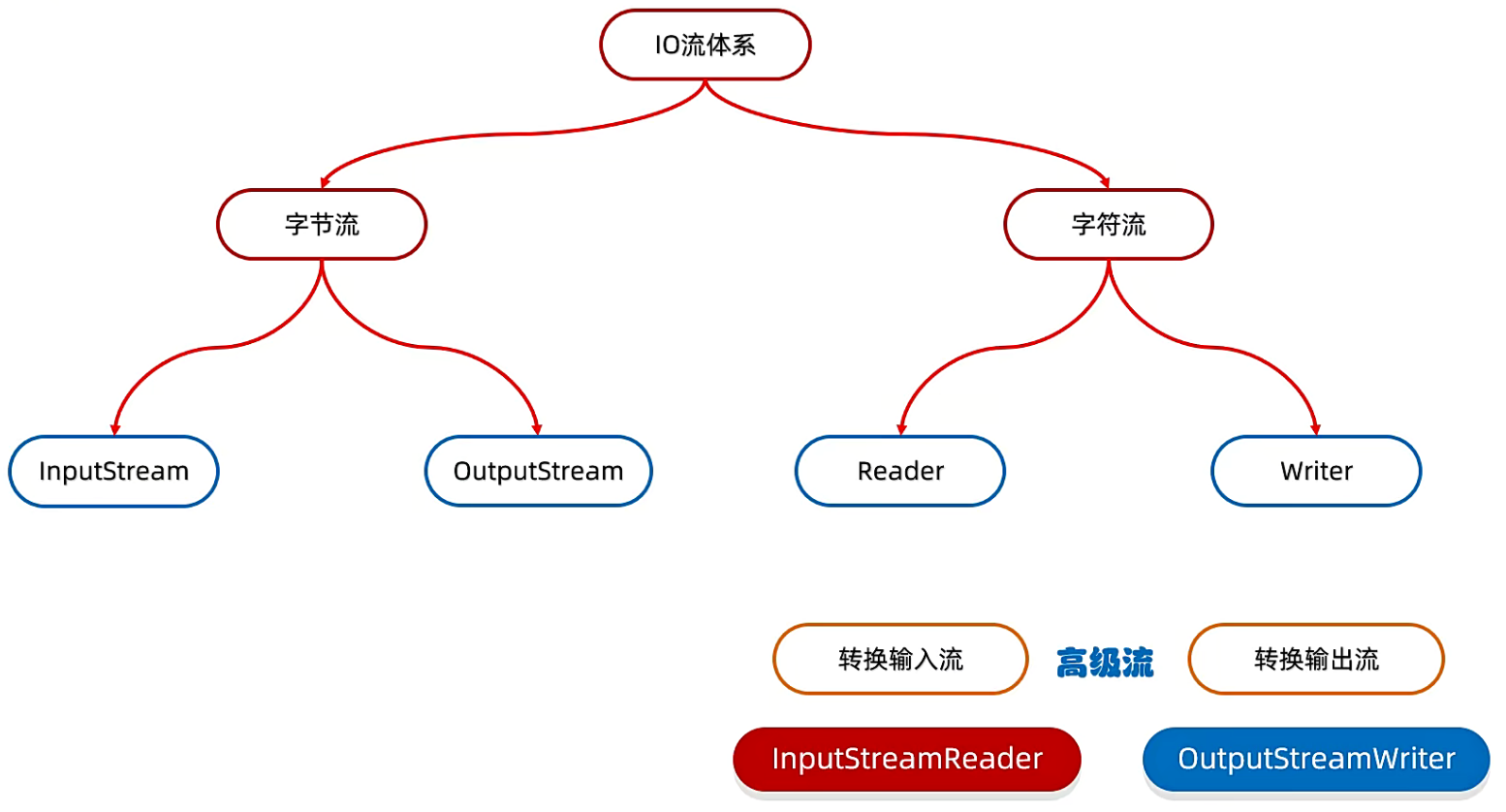
首先来看看转换流在 IO体系 中的位置。
转换流属于字符流,它本身也是一种高级流,用来包装基本流的。
其中输入流叫做 InputStreamReader,输出流叫做 OutputStreamWriter。
想要知道为什么要叫这个名字,我们还需要来看看它的作用。
二、作用
转换流:是字符流和字节流之间的桥梁。
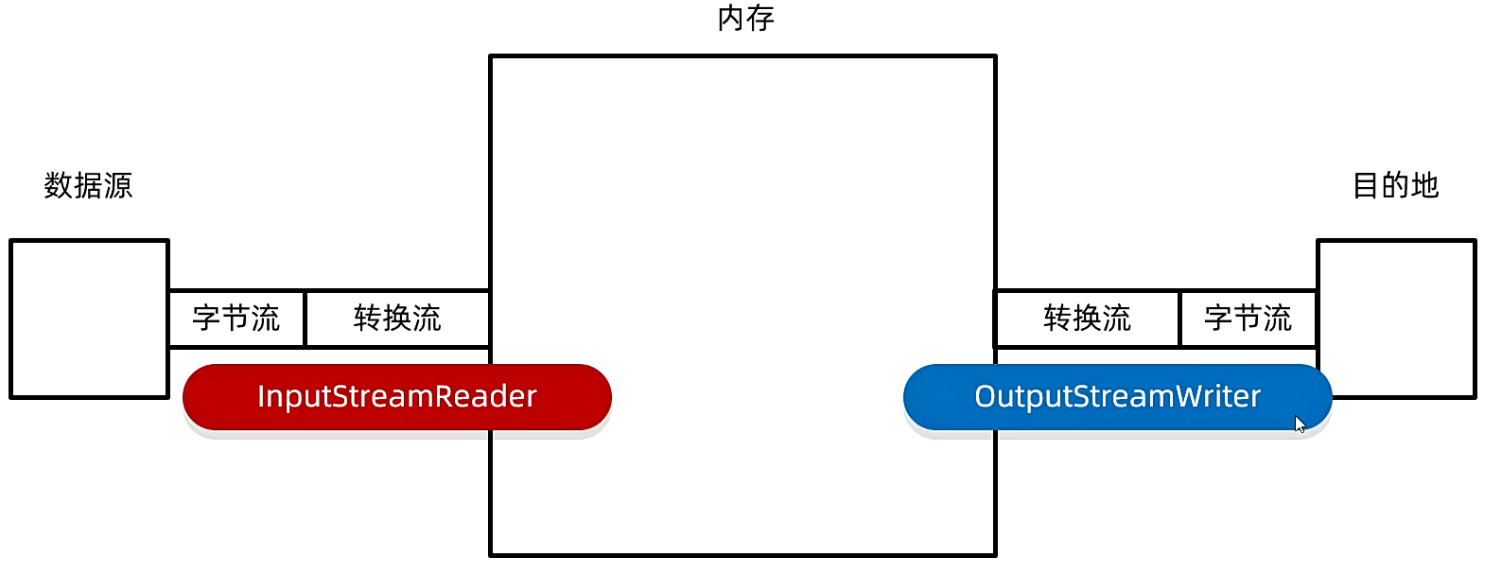
首先我们来看读取数据,读取数据首先要有一个数据源,在读取的时候就是将数据源的数据读取到内存中。
当我们创建了转换流对象的时候,其实是需要包装一个 字节输入流 的。在包装之后这个字节流就变成字符流了,就可以拥有字符流的特性了。
例如:读取数据不会乱码了、可以指定字符集一次读取多个字节。
所以转换流中的输入流叫做 InputStreamReader,前面的 InputStream 就表示它的作用是将 字节流 转换成 字符流,后面的 Reader 表示转换流本身它是 字符流 的一员,它的父类是 Reader。
接下来看输出,输出需要有一个目的地,当我们创建了转换流对象的时候,它里面是要包装 字节输出流 的,它的转换方式跟左边的读是相反的:输出流 是将 字符流 转换成 字节流。
因为在文件中,即目的地中,它真实存储的数据其实是一个又一个的字节,因此我们需要将内存中的数据转换成字节往外写出。
它的名字叫做 OutputStreamWriter,前面的 OutputStream 就表示它的作用是将 字符流 转换成 字节流,后面的 Writer 表示转换流本身它是 字符流 的一员,它的父类是 Writer。`
三、应用场景
作用1:指定字符集读写数据,但是在JDK11后,这种方式淘汰了。因此对于这种方式我们了解一下就行了,真正要我们学习的是它的替代方案。
作用2:字节流想要使用字符流中的方法,因此就可以使用转换流转一下。
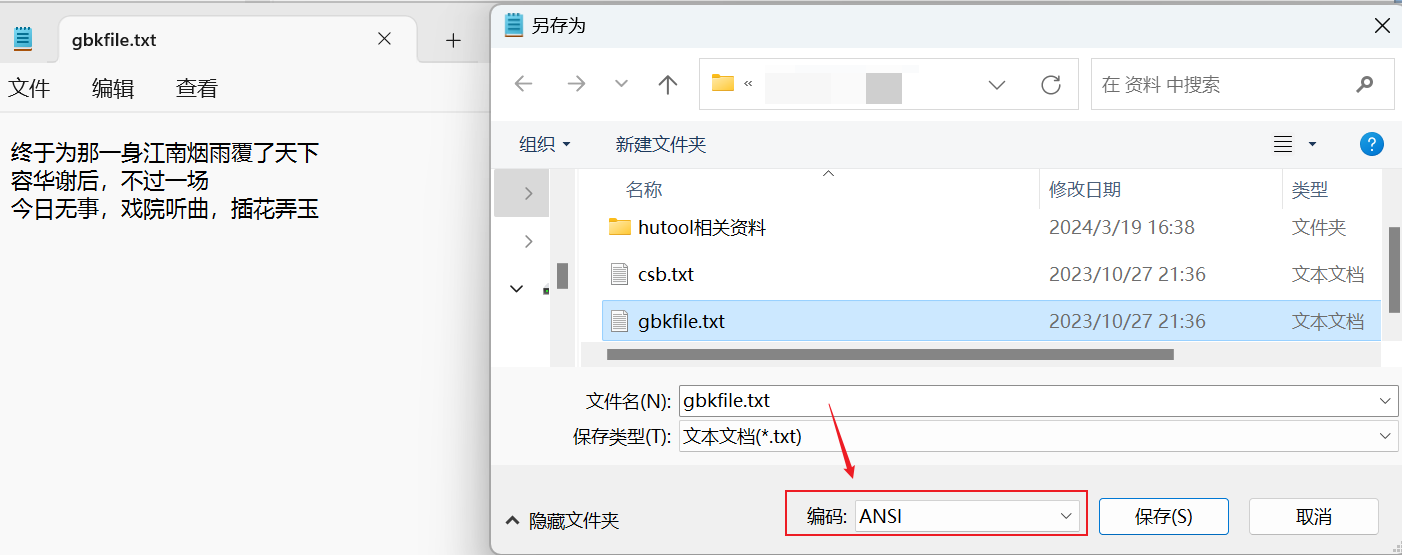
1)需求1:手动创建一个GBK的文件,把文件中的中文读取到内存中,不能出现乱码
如何区分该文件是否是GBK的?
如下图,如果是 ANSI,那就表示使用平台默认的,简体中文默认的就是GBK。
将这个文件粘贴到IDEA中,可以发现是乱码的,因为这个文件编码用的是GBK,但是IDEA默认使用的是 UTF-8。

① JDK11以前的方案
之前的 FileReader 和 FileWriter 还是不能指定编码的,因此我们只能使用转换流做。
ctrl + p 来看一下它构造方法的参数。
第一个:是一个参数的,它需要你去关联一个字节输入流,此时它是使用平台默认的字符编码。
但这并不是我想要的,我需要指定,此时就可以使用第二个构造,它除了让你关联字节输入流以外,还需要指定 charsetName(字符集名字)。
另外还有两个构造,它们也是以不同的形式去指定字符构造。
一般来讲用的都是第二个构造,因为它最简单,直接一个字符串就搞定了。

//1.创建对象并指定字符编码,指定编码是转换流的第二个参数
InputStreamReader isr = new InputStreamReader(new FileInputStream("myio\\gbkfile.txt"), "GBK");
//2.读取数据。转换流本身就是字符流,所以我们完全可以使用之前所学习的字符流的方式进行读取
int ch;
while ((ch = isr.read()) != -1){
System.out.print((char)ch);
}
//3.释放资源,同样只需要关闭高级流就行了,里面这些基础流是不需要关闭的,因为在高级流的底层会帮我们一起关闭
isr.close();
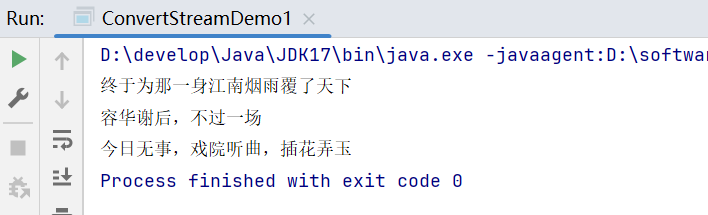
运行程序,可以发现读取的数据跟文件里面的数据一模一样。
这种方式是不需要你掌握的,只需要你了解一下,因为在JDK11的时候,这种方式已经被淘汰了。
它的替代方案我们需要掌握。
② 替代方案
在JDK11后,FileReader 中添加了一个新的构造,这个构造就可以指定字符编码
选中 FileReader 跟进看看,参数一:传递本地文件;参数二:指定字符编码。
并且这个构造不是所有版本都有的,而是 JDK11 才出来的。
在指定字符编码的时候,需要使用 Charset 调用里面的静态方法 forName(),然后往这个方法中指定字符编码即可。
在指定的时候可以写小写的,也可以写大写的,但是为了专业一点,还是写成大写的,因为GBK是多个单词的英文首字母合起来的。
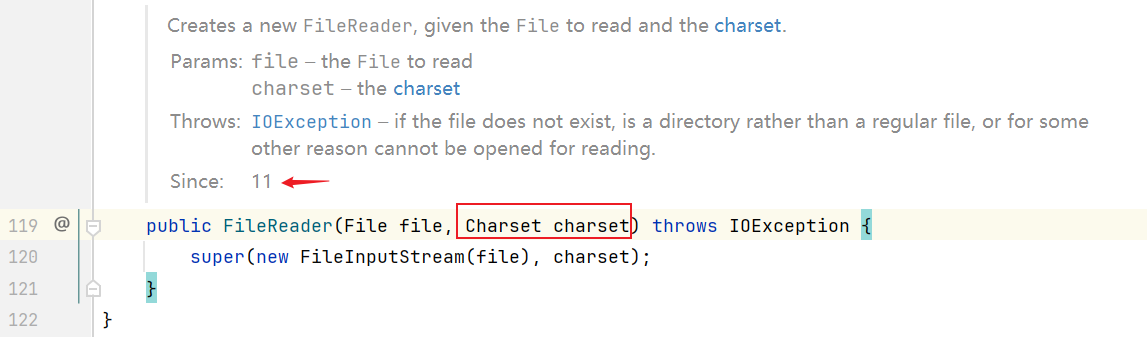
在构造的底层,其实还是调用了父类的构造,并且它的父类其实就是转换流。

转换流的父类是 Reader

FileReader fr = new FileReader("myio\\gbkfile.txt", Charset.forName("GBK"));
//2.读取数据
int ch;
while ((ch = fr.read()) != -1){
System.out.print((char)ch);
}
//3.释放资源
fr.close();
2)需求2:把一段中文按照GBK的方式写到本地文件
① JDK11以前的方案
同样先来看构造方法,看见它需要关联一个 字节输出流,如果不传入第二个参数,就表示使用平台默认的编码方式进行写出。
如果不想用默认的,想自己指定,就需要给它传第二个参数。
//1.创建转换流的对象
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("myio\\b.txt"),"GBK");
//2.写出数据
//OutputStreamWriter它本身是一个字符流,所以在往外写出的时候,write方法跟字符流里面是完全一样的
osw.write("你好你好");
//3.释放资源
osw.close();
程序运行结束,可以发现 b.txt 中是乱码,因为IDEA默认使用 UTF-8 进行打开的,但是这个文件真正的字符编码是 GBK,两者不一样,所以就乱码。
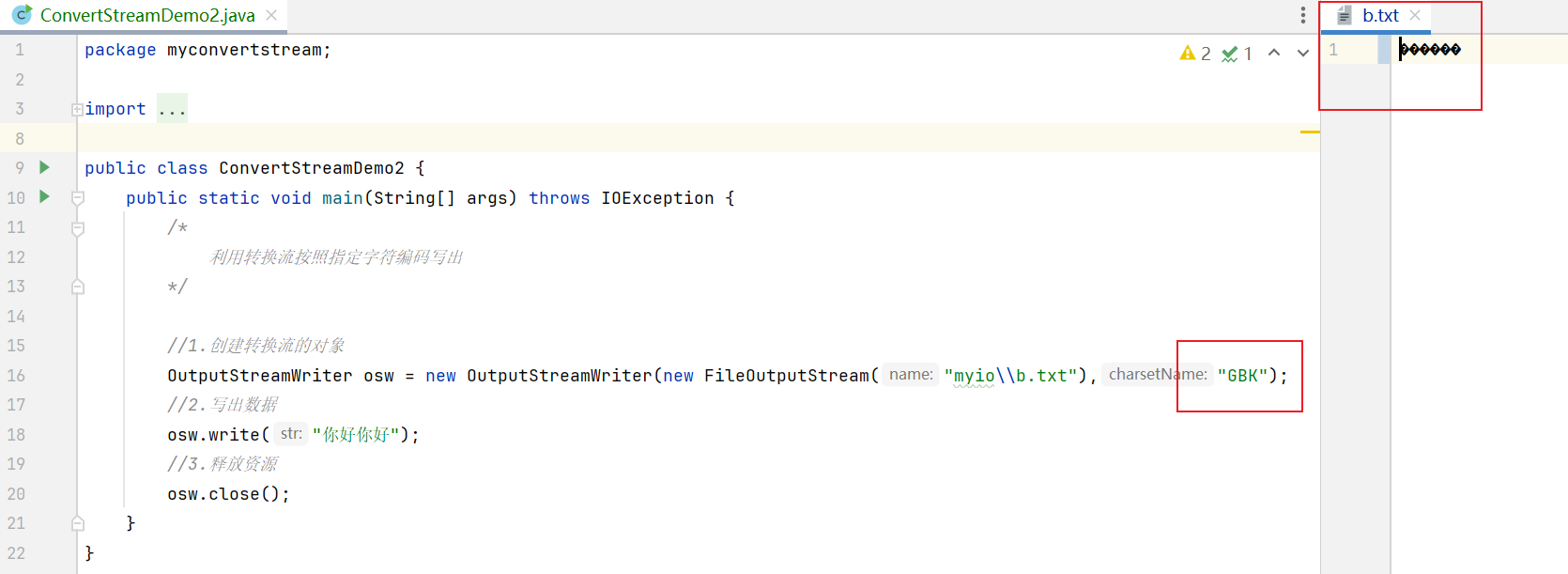
PS:千万不要到IDEA中修改字符编码,因为一旦修改了,有可能会有很多奇奇怪怪的问题。
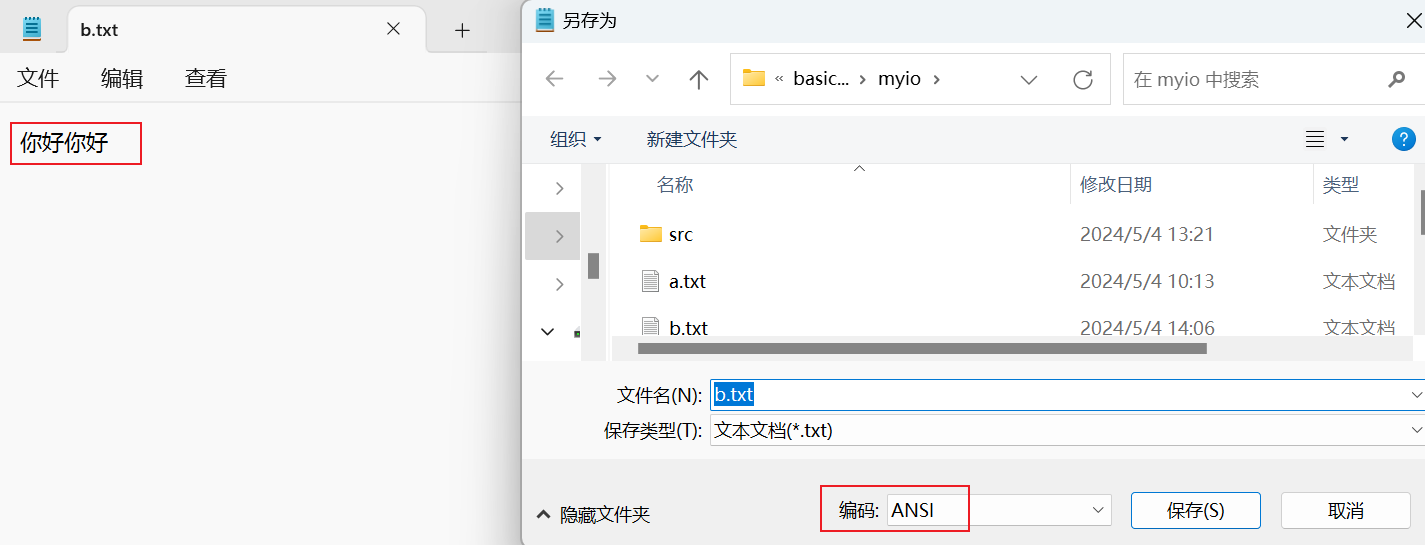
如果一定要查看这个文件,那么我们可以在本地进行查看。

数据成功加载,并且编码也是平台默认的,即 GBK。
这种方式同样也是被淘汰了,所以上的代码了解一下就行了,我们要知道它的替代方案。
② 替代方法
替代方案其实也是在JDK11的时候在 FileWriter(基本流) 中增加了一个新的构造,在这个构造里面可以指定字符编码。
如下图,版本11。
参数有两个,参数一:关联本地文件;参数二:指定字符编码。
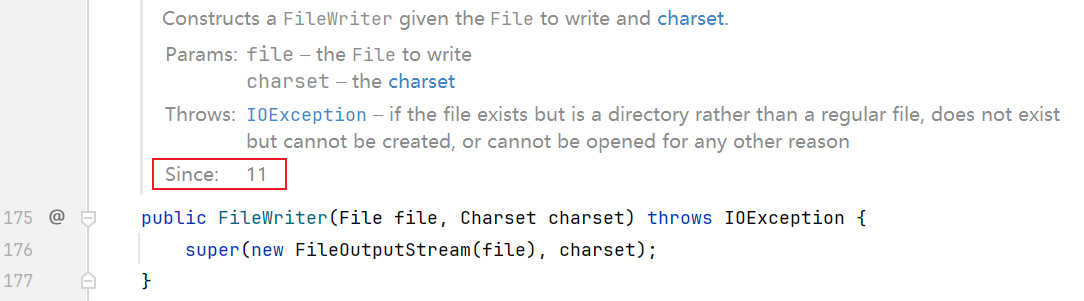
//指定编码的时候不要写字符串,而是通过 `forName()` 静态方法指定字符编码
FileWriter fw = new FileWriter("myio\\c.txt", Charset.forName("GBK"));
fw.write("你好你好");
fw.close();
3)将本地文件中的GBK文件,转成UTF-8
IDEA默认使用的是 UTF-8,因此我们不管是读取数据,还是写出数据,在之前用的都是默认的 UTF-8。
如果文件是 GBK,就不能使用默认的了,我们需要手动指定。
① JDK11以前的方案
InputStreamReader isr = new InputStreamReader(new FileInputStream("myio\\b.txt"),"GBK");
// 写入的时候可以指定编码,也可以不指定编码,因为IDEA默认就是UTF-8,但是为了跟上面保持统一,这里还是写上
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("myio\\d.txt"),"UTF-8");
int b;
while((b = isr.read()) != -1){
osw.write(b);
}
osw.close();
isr.close();
② 替代方案
FileReader fr = new FileReader("myio\\b.txt", Charset.forName("GBK"));
FileWriter fw = new FileWriter("myio\\e.txt",Charset.forName("UTF-8"));
int b;
while ((b = fr.read()) != -1){
fw.write(b);
}
fw.close();
fr.close();
4)利用字节流读取文件中的数据,每次读一行,而且不能出现乱码
字节流里面是没有读一整行方法的,读一整行是字符缓冲流的,此时就需要利用转换流去转一下。
① 方便阅读的代码
FileInputStream fis = new FileInputStream("myio\\a.txt");
InputStreamReader isr = new InputStreamReader(fis); // 此时用isr读取中文就不会乱码了
BufferedReader br = new BufferedReader(isr); // BufferedReader中的readLine()可以读取一整行
String str = br.readLine();
System.out.println(str);
br.close();
② 最终代码
//BufferedReader对里面的字符流进行了保证,InputStreamReader对里面的字节流进行了转换
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("myio\\a.txt")));
String line;
while ((line = br.readLine()) != null){
System.out.println(line);
}
br.close();
四、总结
1、转换流的名字是什么?
- 字符串输入流:InputStreamReader
- 字符转换输出流:OutputStreamWriter
2、转换流的作用是什么?
-
指定字符集读写数据(JDK11之后已淘汰,了解即可)
因为在实际开发中,还是有很多人在使用JDK8,他们是用不了JDK11的API的,因此以前的方式也需要知道。
-
字节流想要使用字符流中的方法了
















 2921
2921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









