







一、引入

这种带权重的随机是非常常见的,例如现在最后的微服务架构,就用到了这种随机算法。
其中这里的 带权重随机算法 还是很重要的:在以后,我们会学习到微服务架构,那为什么会有微服务呢?
其实就是因为现在上网的人太多了,一台服务器扛不住了,就需要将一个大项目拆分成n个小项目,部署在n个服务器中。
但是这就会有一个小问题:用户在上网的时候,我也不知道访问哪个服务器。
所以在中间就会有一个服务网关,它会根据一些算法计算出,现在哪台服务器的压力还比较小。
其中有一个算法叫做:带权重的随机,随机到哪台服务器,用户就会去访问所对应的服务器,这样的好处就是可以能让我们的项目去被更多的人访问。
一开始我们可以给每台服务器都设置权重为1,那就表示每台服务器所随机到的概率是一样的。
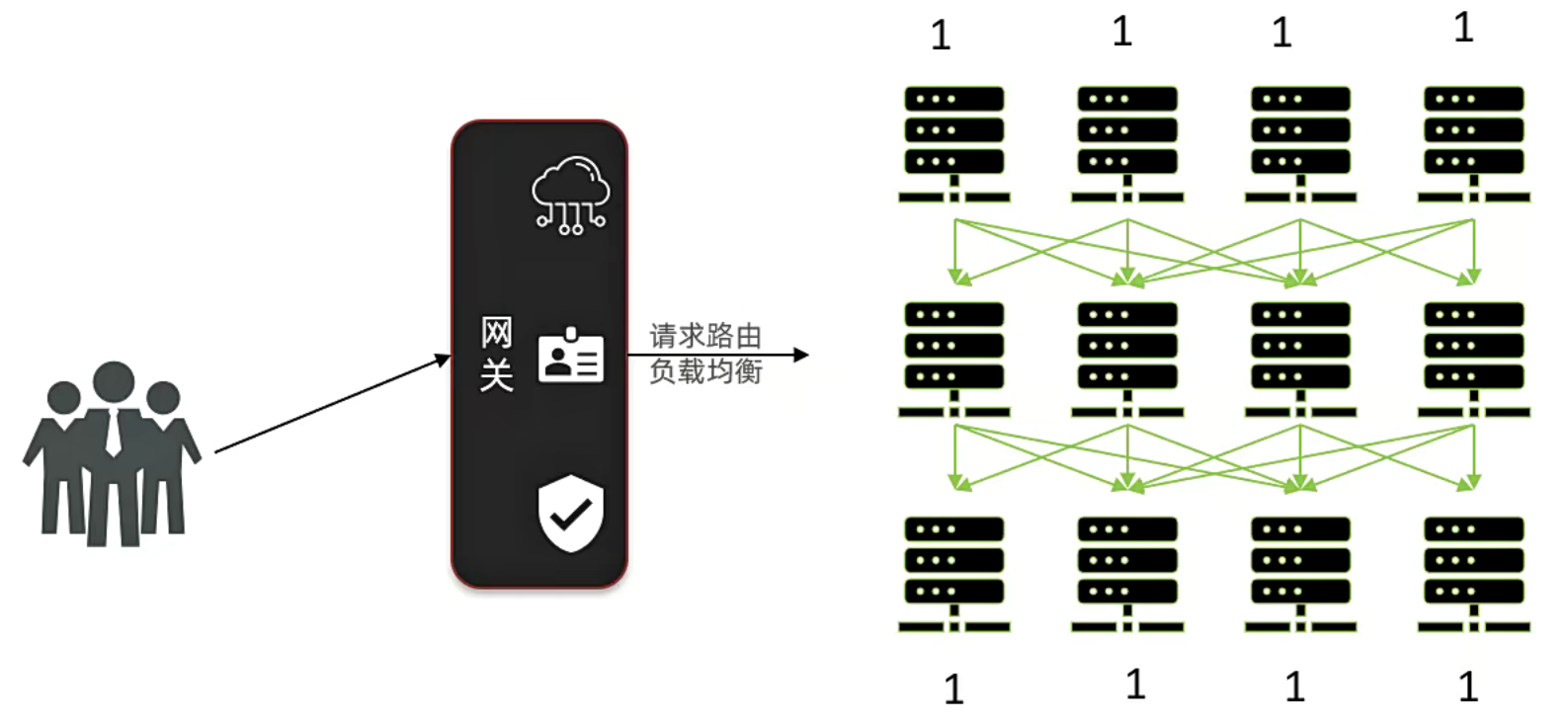
但是假设,现在有一台服务器访问的人数太多了,此时我们就可以将它的权重降低,如果降到0的话,就不会再随机到这台服务器了。
二、梳理过程
在本地文件中,在准备数据的时候,需要给每个学生都设置权重,最初每个学生的权重都是1,就表示每个人被随机到的概率是一样的。
这个概率我们也会称之为 权重比,使用 个人权重 ÷ 总权重 = 每个人的权重占比。
现在在文件中总共有十个人,总权重就是 10,它里面每个人的权重占比就是 0.1,即 10% 的概率。
那么这 10% 的概率怎么去计算呢?
在之前我们曾经说了一个办法, 70%的概率随机到男生、30%的概率随机到女生,此时我们可以往一个集合中添加 7个1,和3个0,根据 1 和 0 的占比情况来决定概率,这种方法是可以的,但是它是适合于数据量比较少的情况,一旦数据比较多,就不合适了。
男生、女生只有两种,可以用 1 和 0 来表示,那如果有十种数据、一百种数据呢,就没有办法进行表示了。
因此我们需要来学习一种新办法:求出每一种数据的权重占比范围。
画个数轴来理解一下,既然每个学生概率都是 10%,此时就可以将数轴中的 0.0 到 1.0 去分成十等分,每一个学生占据其中的一份。

因此这里的权重占比可以这么去理解:假设现在随机到 0.0 到 0.1 之间就表示是第一位同学;随机到 0.1 到 0.2 之间就表示是第一位同学…以此类推

三、代码实现
首先检查数据,注意除了姓名、性别、年龄外,还需要有权重
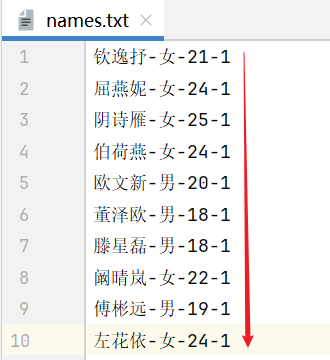
由于现在学生中的属性比较多,因此我们最好新建一个JavaBean类,在JavaBean类中定义四个属性,统一管理,这样会更方便一些。
成员变量里面的属性顺序 最好跟 文件中的顺序保持一致
Student.java
public class Student {
private String name;
private String gender;
private int age;
private double weight;
//空参构造、全参构造、set/get方法
//改写toString的原因结合下面代码观看
public String toString() {
return name + "-" + gender + "-" + age + "-" + weight;
}
}
测试类
//1.把文件中所有的学生信息读取到内存中,并封装成一个Student对象,再方法集合里面,这样我们才能统一的进行管理
ArrayList<Student> list = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("myiotest\\src\\com\\itheima\\myiotest6\\names.txt"));
String line;
while((line = br.readLine()) != null){
String[] arr = line.split("-");
Student stu = new Student(arr[0], arr[1],Integer.parseInt(arr[2]), Double.parseDouble(arr[3]));
list.add(stu);
}
br.close();
//接下来就是要将每个人的权重占比给算出来:个人权重 ÷ 总权重 = 每个人的权重占比
//2.计算权重的总和
double weight = 0;
for (Student stu : list) {
weight = weight + stu.getWeight();
}
//3.计算每一个人的实际占比存起来,这里可以用数组也可以用集合
//[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]
double[] arr = new double[list.size()];
int index = 0;
for (Student stu : list) {
arr[index] = stu.getWeight() / weight;
index++;
}
//4.计算每一个人的权重占比范围
//第一个人的范围是0 ~ 0.1,第二个人的范围是0.1~0.2,我们需要想清楚0.2是怎么来的,是不是前一个人0.1的基础上,再去加上自己本身?
//第三个人的范围也是在前一个人的基础上(0.2)加上自己本身的范围0.1,就变成了0.3
for (int i = 1; i < arr.length; i++) {
arr[i] = arr[i] + arr[i - 1];
}
//此时如果直接打印arr,有些小数是不精确的,但是这个不精确对结果影响的不是很大,是在我们能接受范围之内的。
//5.随机抽取
//获取一个0.0~1.0之间的随机数
double number = Math.random();
//判断number在arr中的位置
//由于在arr中数据是升序排列的,因此可以使用二分查找法
//方法回返回: - 插入点 - 1
//插入点 = -方法回返回 - 1
//获取number这个数据在数组当中的插入点位置
int result = -Arrays.binarySearch(arr, number) - 1;
//获取到插入点的位置后,我们就知道是哪个学生了
Student stu = list.get(result);
System.out.println(stu);
//6.修改当前学生的权重
double w = stu.getWeight() / 2;
stu.setWeight(w);
//7.把集合中的数据再次写到文件中
BufferedWriter bw = new BufferedWriter(new FileWriter("myiotest\\src\\com\\itheima\\myiotest6\\names.txt"));
//需要按照指定的格式进行拼接太麻烦了,此时我们可以直接改写toString方法,此时我们就不需要多次调用get方法进行拼接了。
for (Student s : list) {
bw.write(s.toString());
bw.newLine();
}
bw.close();
















 2874
2874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









