







单列索引:即一个索引只包含单个列。
联合索引(组合索引):即一个索引包含了多个列。
我们先来看看 tb_user 表中目前的索引情况:

在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条SQL语句,看看其执行计划:
explain select id, phone, name from tb_user where phone = '17799990010' and name = '韩信';

通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是 最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
-- phone已经是唯一的了,加上个名字肯定也是唯一的,因此可以加上unique唯一索引
create unique index idx_user_phone_name on tb_user(phone,name);

此时再来查询,可以看见,可能使用的索引有 idx_user_phone,idx_user_phone_name,idx_user_name,但是MySQL选择了 idx_user_phone

多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询。
这里有单列索引的干扰,我们可以使用SQL提示来指定使用联合索引。
explain select id, phone, name from tb_user use index(idx_user_phone_name) where phone = '17799990010' and name = '韩信';

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
**在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引, 而非单列索引。**因为使用联合索引性能相对来说比较高,而且如果联合索引我们使用得当,也就是说如果我们使用覆盖索引,是可以避免回表查询的;而如果我们使用单列索引,那很容易就造成回表查询的情况,造成性能降低。
如果查询使用的是联合索引,具体的结构B+树示意图如下:它会先按照phone手机号进行排序,如果手机号一致,再按照name字段进行排序。
当然,所构建出来的联合索引也属于二级索引,叶子结点挂的是这一页行记录对应的主键
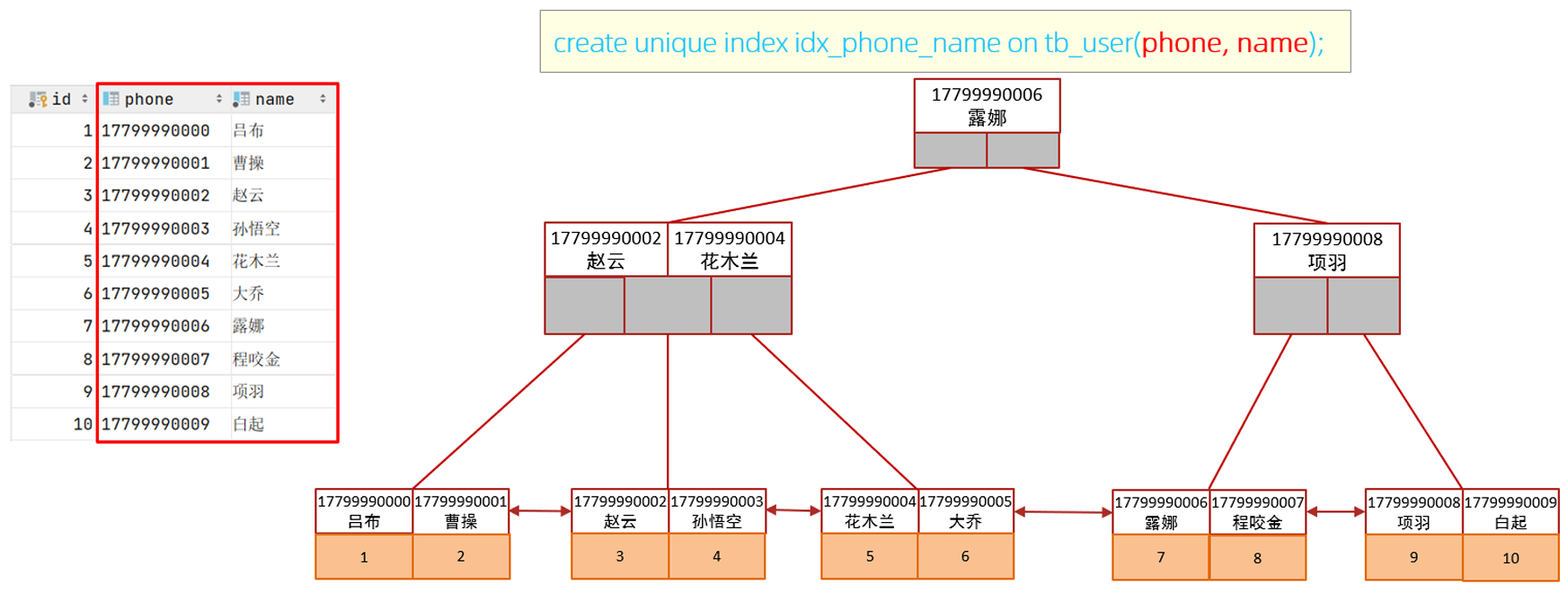
另外,我们创建联合索引的时候,哪一个字段放前面,哪个字段放后面,对于查询的结果是有影响的,因为我们之前提到了最左前缀法则,如果我们创建的是如上图的联合索引,那么每次查询都想用这个联合索引,phone这个列必须存在;如果phone和name交换位置,那么name这个列必须存在。所以在创建联合索引的时候,我们得考虑它的顺序。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









