







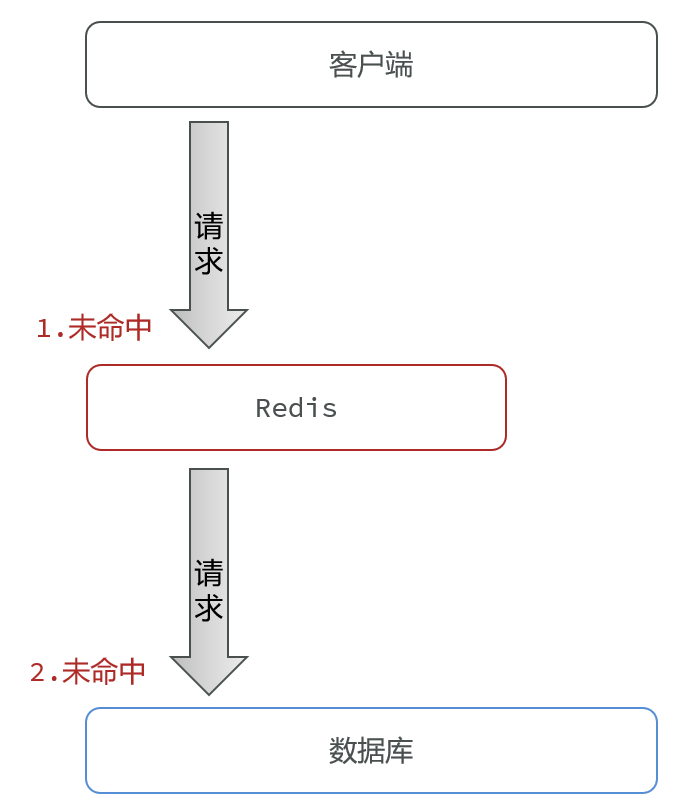
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,既然都不存在,那它永远都不可能建立缓存,因此只要有人去请求,它一定会到达数据库。
例如根据id查询店铺,查询缓存和数据库中数据都不存在,也就是说用户传过来的就是一个根本不存在的id。当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,如果是一个不怀好意的人,它整了无数的线程,并发的向这个不存在的数据发起请求,这样所有的请求都会到达数据库,很有可能就将我们的数据库搞垮,这就是缓存穿透带来的危害了。
常见的解决方案有两种:
-
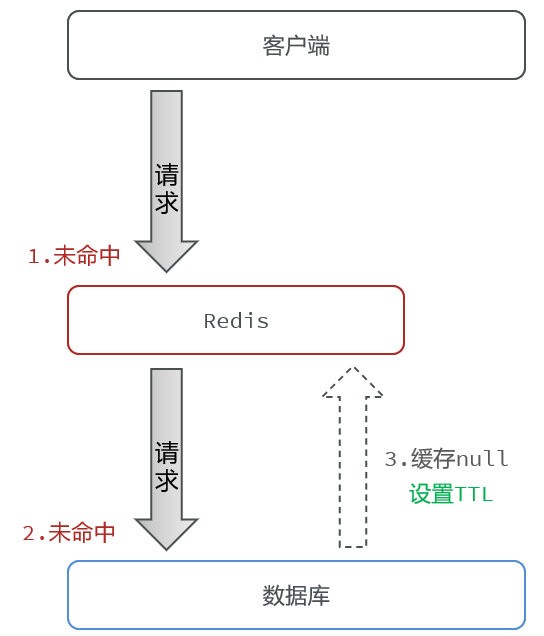
缓存空对象。这是一种简单暴力的处理方法。
思路:你来请求我,redis中没有,然后去数据库中查也没有,为了让你不再请求我了,我就把这个空的值缓存到redis中。也就是说你请求的时候传了个id,这个id是根本没有的,我也给你缓存起来,这样下次你再来的时候,redis就命中了,尽管命中是个null,至少也是命中了,这样就不会请求我们的数据库了,是不是简单粗暴的一个思路。
-
优点:实现简单,维护方便
-
缺点:
-
额外的内存消耗。不存在的id都缓存起来了,这样会导致redis中缓存了很多很多垃圾。不过针对这个问题其实也能解决:缓存null的时候加一个比较短的ttl,五分钟甚至两分钟,在这两分钟内缓存是有效的,当有恶意的用户来请求的时候,也会起到一定的保护作用,同时它的有效期也不长,因此这些垃圾数据过段时间就会清除。
-
可能造成短期的不一致。
例如用户请求一个id,这个id刚好不存在,我们给它设置为null,但就在此时,我们真的给这个id插入了一条店铺的数据,这个时候等于数据库中已经有了,但我们却缓存了一个null,此时用户来查查到的是null,而实际上是存在的,此时就出现不一致了,只有当ttl过期后,用户才能查到最新的这样一个数据。
针对这个问题其实我们只需要去控制ttl的时间,在一定程度上其实是可以缓解的,不一致的时期只要足够短,其实也是可以接受的。
当然如果你实在无法接受这个不一致,你也可以这么做:当我们新增一条数据的时候,我们主动将这条数据插入缓存中,覆盖之前的null。
-
-
-
布隆过滤
布隆过滤准确来讲是一种算法,它的做法是在客户端与redis之间又加入了一层这样的拦截器,叫做
布隆过滤器,当用户请求来了后,不是上来就查redis,而是先去找布隆过滤,问一问这个数是存在还是不存在,如果这个数据不存在,会直接拒绝,就不给你机会往下走了。如果布隆过滤器告诉你存在,此时它才会去redis中查询,去redis查询后,剩下的逻辑就跟以前一样了。如果redis中有,直接返回;如果redis没有,就查询数据库,数据库有就缓存到redis,并且将数据返回。
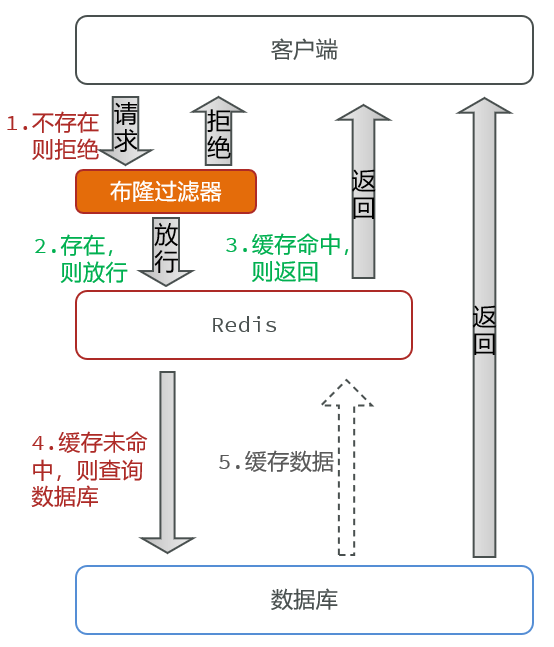
那布隆过滤器它怎么知道我这个数据有还是没有呢?难道布隆过滤器里存储了数据库中所有的数据吗?并不是的,如果是这样,我们就多余存储了很多数据了。布隆过滤器的原理,你可以简单理解为是一个byte数组,里面存的就是二进制位。当我们去判断数据库中的数据是否存在的时候,并不是真的把数据存储到布隆过滤器,而是将这些数据基于某一种哈希算法,计算出哈希值,然后再将这些哈希值转化为二进制位,保存到布隆过滤器中。然后我们去判断数据是否存在的时候,其实就是判断对应的位置是0还是1,以此来去判断数据是否存在,这种存在与否是一种概率上的统计,它并不是真的百分之百的准确,因此当你问布隆过滤器是否存在,它说不存在的时候,那就是真的不存在,但是当它告诉你存在的时候,其实不一定就是存在的,因为只要有哈希思想,就可能存在哈希冲突。
因此如果我现在来请求布隆过滤器,它告诉我说这个数据存在,放行了,然后我去redis查询没发现,然后去数据库查询,又没发现,就又一次出现穿透了,因此还是有一定穿透风险的。
- 优点:内存占用较少,不用像之前那样缓存大量空数据,它只是用一个二进制位的形式保存数据,所以它的空间占用非常小。
- 缺点:
- 实现复杂。如果你想自己实现布隆过滤器,其实还是挺麻烦的,好在redis中其实提供了Bitmap (位图),是它自带的一种不能过滤的实现,可以帮助我们简化开发。
- 存在误判可能
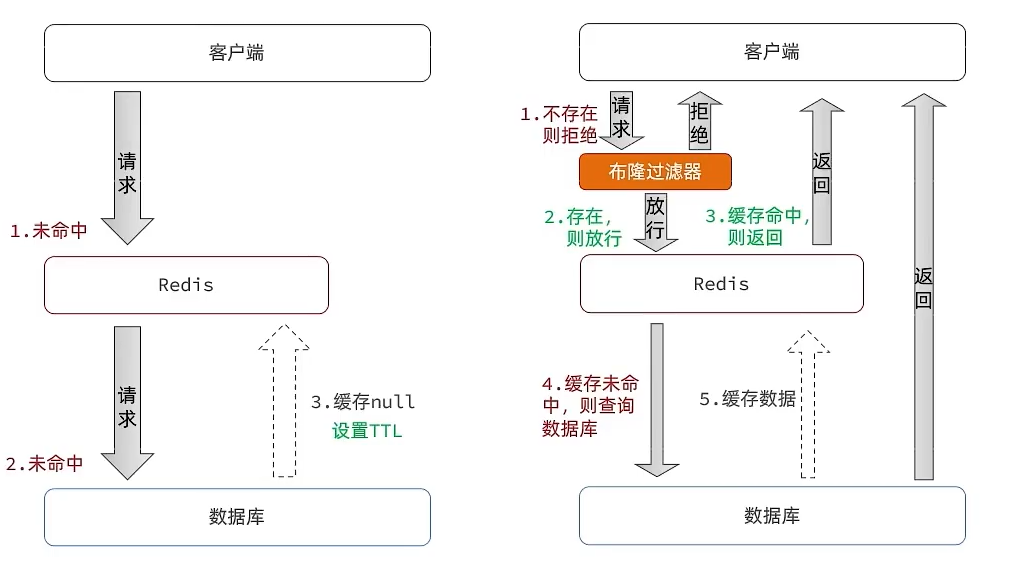
因此在我们开发过程中会选择方案一:缓存空对象。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









