







一、代码实现
package com.hmdp.utils;
@Component // 定义成spring中的一个bean,方便我们后续使用
public class RedisIdWorker {
/**
* 开始时间戳,这个是使用main方法测试出来的
LocalDateTime now = LocalDateTime.of(2022, 1, 1, 0, 0 ,0);
long second = now.toEpochSecond(ZoneOffset.UTC);
System.out.println("second = " + second);
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数
*/
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
// 方法的返回值是Long,因为按照之前的策略,我们最终的id是一个64位的数字就是对应了Java的Long
// 参数keyPrefix:生成策略是基于redis的自增长,redis的自增肯定是需要有一个key,然后值不断自增。不同的业务肯定有不同的key,大家不能都去用同一个自增长,因此这里需要有前缀去区分不同的业务,例如订单业务可以传order过来
public long nextId(String keyPrefix) {
// 1.生成时间戳,时间戳是一个31位的数字,单位是秒,它的值需要有一个基础的日期作为开始时间,时间戳的值就是用基础时间减去当前时间得到的秒数
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1.获取当前日期,精确到天yyyyMMdd。这里用冒号分开,因为在redis中如果你的key用冒号分隔,这样在redis中就是分层级的
// 当我要统计某天、某月、某年的订单量的时候,就可以很方便的利用前缀统计,例如统计一个月就可以使用yyyy:MM作为前缀
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长
// icr表示自增长,然后拼上业务(keyPrefix),但是到这key还不能结束。
// 假设keyPrefix传进来的是order,就意味着整个订单业务它永远采用的是一个key来做自增长。也就是说不管你这个业务是经历了1年、2年,那么永远都是同一个key,但随着我们的业务逐渐发展,订单越来越多,那么自增的值也会越来越大。而redis单个key的自增长对应的数值是有一个上限的,2的64次方。虽然这个值已经非常非常大了,但是它也是有一个上限的,万一超过了这个上限怎么办?
// 而且你不要忘了,我们的key的策略里面,真正用来记录序列号的只有32个比特位,而reids是64比特位,超过64位很难,但是超过32位还是有可能的
// 所以尽管是同一个业务,也不能使用同一个key,否则就很有可能会超过上限。办法:在业务前缀的后面,拼上一个时间戳,这个时间戳精确到天。这样的好处是将来如果想统计这一天一共下了多少单,那么直接看key的日期对应的值就行了,因此它还有一个统计效果
// PS:这里可能会报黄,说你这里拆箱可能会有空指针。但实际上这个方法并不会导致空指针,因为如果这个key不存在,它就会自动取给你创建一个key,并且从0开始,第一次自增长之后就是1了,所以你根本不用管这个警告
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回,这个移动的位数COUNT_BITS最好别写死,定义为一个变量,因为现在是移动32位,但万一以后算法有变。因此可以定义为常量COUNT_BITS
return timestamp << COUNT_BITS | count;
}
}
二、测试
知识小贴士:关于countdownlatch
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
1、countDown
2、await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
由于这里我们需要测试一下并发情况下它生成id的性能,因此这里会准备一个线程池
@Resource
private RedisIdWorker redisIdWorker;
@Test
void testIdWorker() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300);
// 任务
Runnable task = () -> {
for (int i = 0; i < 100; i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task); // 提交300次,每个任务生成100个自增长id,因此一共3000个
}
latch.await();
long end = System.currentTimeMillis(); // 由于线程池是异步的,因此这里计时其实是没有意义的,因此这里会借助于CountDownLatch
System.out.println("time = " + (end - begin));
}
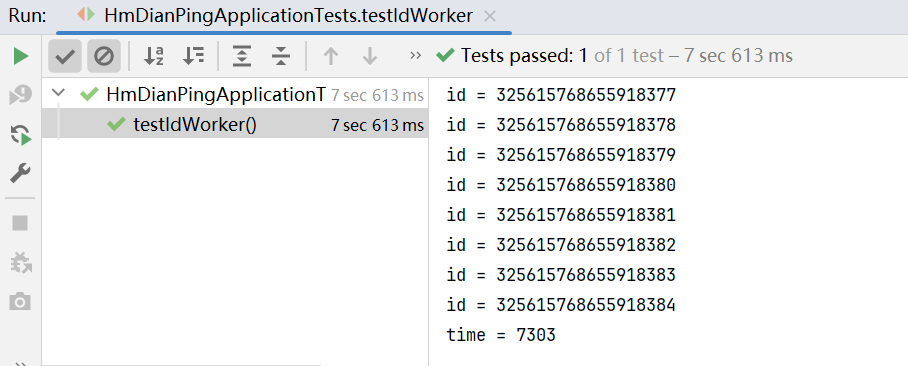
执行单元测试,可以看见成功生成了,并且查看前缀只有一个,也就是说大概只花费了一秒钟左右。
这里之所以显示三秒应该是是因为还有打印、计算还有其他时间的花费。
生成了多少个id呢?到redis中看看,可以发现生成了30000个id

三、总结
全局唯一ID生成策略:
-
UUID
这个直接利用JDK自带的工具类UUID工具类就能生成了。这种生成策略生成的其实是16进制的一长串的数值,因为这一长串是十六进制,因此它返回的结果其实是字符串结构,并且也不是单调递增的一种特性。因此虽然可以做唯一ID,但是并不够友好,没有满足之前我们所说的哪些特性,因此这种用的比较少。
-
Redis自增
这种方法相对来讲各种特性都能满足,而且整体是单调递增的,数值的长度也不大,总共也不超过long,而且它是一个数字类型它存储的数据库里占用的空间相对来讲也比较小,比较有好一些
-
snowflake算法
雪花算法,这种算法也是世界知名的全局唯一id的生成策略,它也是采用的是一种long类型的64位的数字。原理跟我们今天学的redis自增的原理是有点接近的,只不过它的自增采用的是当前机器的自增,内部维护的,因此它需要维护一个机器ID,因为我们用的是redis,不管你是任何的分布式系统,它都是用redis作为字段,所以它并不需要维护机器id,相对来将redis自增更简单一点。
雪花算法也是一个非常不错的算法,它不依赖redis,所以它的性能来讲理论上会比redis更好一点,但它也有缺点,就是对时钟依赖比较高,如果时间不准确,可能会出现异常问题。
-
数据库自增
这里并不是说在新增订单表的时候将用户的id设置为自增,而是单独整张表,这张表单独来做自增,这样一来你订单表不管是十张表还是八张表,它们的ID其实不是自动的,而是从专门用来做自动的那张表中获取,等于是这N张表用的是同一个表的自动ID,这样的话就可以实现唯一的效果了。原理跟redis自增很像,但是从性能上考虑,数据库自增肯定不如redis自增性能好。
因此企业中使用数据库自增的时候往往会采取一些方案:例如批量获取id,然后在内存中缓存起来,这样可以一定程度上提高他的性能。
后面三种方案企业都有应用,大家可以百度一下,研究一下不同点。
Redis自增ID策略:
每天一个key,方便统计订单量,并且它还可以限定key的值不会让它太大,以至于让它超出存储的上限。
ID构造是 时间戳 + 计数器
















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









