







有的时候namenode会出现无法启动的问题,我们在无法解决这个问题的时候往往会干一件事:

但我们会发现:

然后我们就会干一件更加丧心病狂的事:

不好意思,发错了,是格式化namenode。格式化后

但datanode不见了。这是为啥呢?

我们每次在格式化namenode时都会产生一个新的集群ID,如果格式化成功,在命令行输出信息里就有新产出的集群ID,大家找一下,我这不方便再格式化一遍(懒),但它大概长这么个样子:

第一次配置Hadoop时我们会格式化一次,这时就产生了一个集群ID,并且这时datanode就会“记住”这个ID,就像认老大一样,datanode认了具有特定集群ID的namenode做老大,只听它的调遣。如果某一天我们又格式化了一遍namenode,好比老大改头换面了,那小弟们自然就不认识了,datanode“记住”的依然还是第一次格式化时产生的集群ID,不能跟新产生的集群ID相匹配,那它自然启动不了。
我们先不谈解决办法,先学习一下怎么查看集群ID。
我们都应该在core-site.xml文件里配置了hadoop.tmp.dir参数,这个参数的属性值的子文件是dfs,dfs里面有name和data两个子文件夹,里面分别存放namenode和daranode节点的数据。它们各自的集群ID信息分别存放在name(data)下的current文件夹里的VERSION文件里。
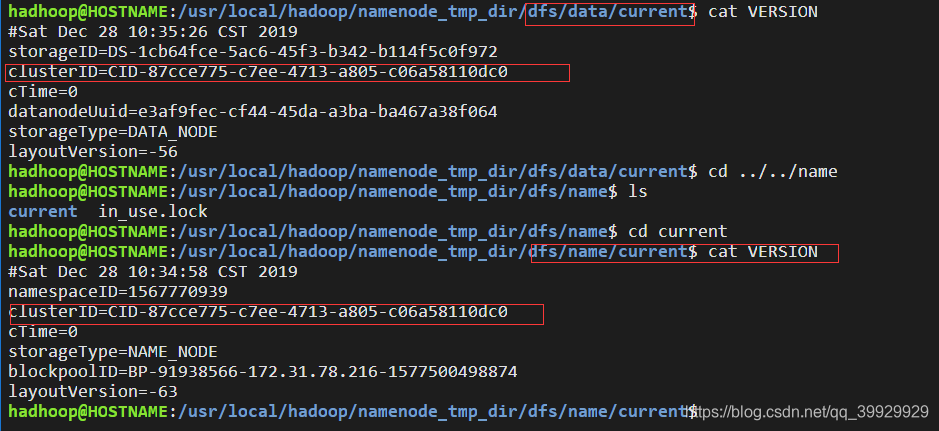
解决datanode无法启动的方法很简单,就是把上述name和data文件夹里的所有东西全部删除,一个不留。然后再进行一遍namenode的格式化就OK了。然后重启Hadoop服务,datanode就回来了。我们又可以愉快的写代码了。

还没完,提一嘴正确格式化的方法。
- 关闭集群
- 清空name和data文件夹里的所有东西
- hdfs namenode -format 格式化namenode
- 重启。大功告成

那还不快点!!!!!!!!!!!!!!!!!!















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









