







GitHub - Light-City/CPlusPlusThings: C++那些事
1.
① extern
(1) 如果全局变量不在文件的开头定义,其有效的作用范围只限于其定义处到文件结束。如果在定义点之前的函数想引用该全局变量,则应该在引用之前用关键字 extern 对该变量作“外部变量声明”,表示该变量是一个已经定义的外部变量。有了此声明,就可以从“声明”处起,合法地使用该外部变量。
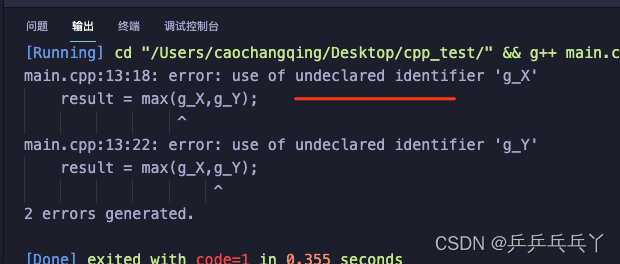
如下会报错:
#include <iostream>
int max(int x,int y);
int main(void)
{
int result;
result = max(g_X,g_Y);
printf("the max value is %d\n",result);
return 0;
}
// 定义两个全局变量
int g_X = 10;
int g_Y = 20;
int max(int x, int y)
{
return (x>y ? x : y);
}
修改如下:
#include <iostream>
int max(int x,int y);
// 定义两个全局变量
int g_X = 10;
int g_Y = 20;
int main(void)
{
int result;
result = max(g_X,g_Y);
printf("the max value is %d\n",result);
return 0;
}
int max(int x, int y)
{
return (x>y ? x : y);
} 
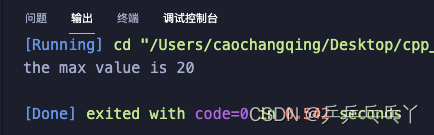
或使用extern:
#include <iostream>
int max(int x,int y);
int main(void)
{
int result;
extern int g_X; // 外部变量声明
extern int g_Y;
result = max(g_X,g_Y);
printf("the max value is %d\n",result);
return 0;
}
// 定义两个全局变量
int g_X = 10;
int g_Y = 20;
int max(int x, int y)
{
return (x>y ? x : y);
}
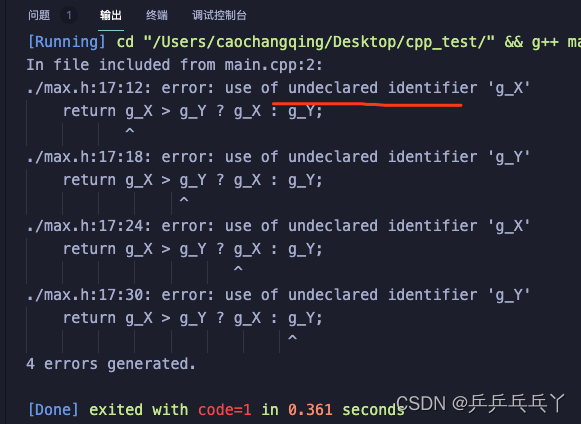
(2) 如果整个工程由多个源文件组成,在一个源文件中想引用另外一个源文件中已经定义的外部变量,同样只需在引用变量的文件中用 extern 关键字加以声明即可。对于多个文件的工程,都可以采用上面这种方法来操作。对于模块化的程序文件,可在其文件中预先留好外部变量的接口,也就是只采用 extern 声明变量,而不定义变量,以下max.cpp 文件中的 g_X 与 g_Y 就是如此操作的。
如下会报错:
max.h
#ifndef _MAX_H_
#define _MAX_H_
#include <iostream>
int max(){
return g_X > g_Y ? g_X : g_Y;
}
#endifmain.cpp
#include <iostream>
#include "max.h"
int g_X = 10;
int g_Y = 20;
int main(void)
{
int result = max();
printf("the max value is %d\n",result);
return 0;
}
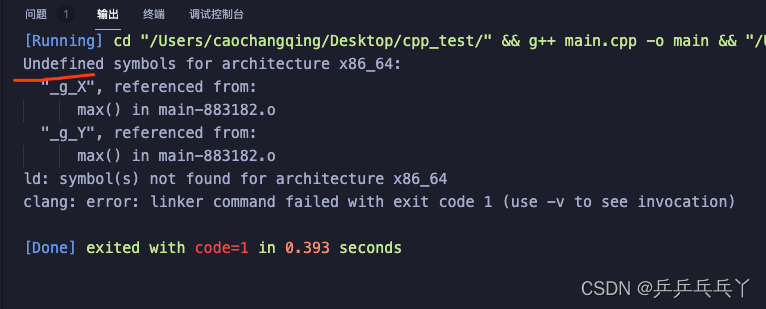
如下也会报错:
max.h
#ifndef _MAX_H_
#define _MAX_H_
#include <iostream>
extern int g_X;
extern int g_Y;
int max(){
return g_X > g_Y ? g_X : g_Y;
}
#endifmain.cpp
#include <iostream>
#include "max.h"
int main(void)
{
int g_X = 10; // 不是全局变量,头文件的extern不起作用
int g_Y = 20;
int result = max();
printf("the max value is %d\n",result);
return 0;
}
修改如下:
max.h
#ifndef _MAX_H_
#define _MAX_H_
#include <iostream>
extern int g_X;
extern int g_Y;
int max(){
return g_X > g_Y ? g_X : g_Y;
}
#endifmain.cpp
#include <iostream>
#include "max.h"
int g_X = 10; // 全局变量
int g_Y = 20;
int main(void)
{
int result = max();
printf("the max value is %d\n",result);
return 0;
}
② static
(1)静态变量
1)函数中的静态变量
使用静态变量的原因:
有时候,希望函数中的局部变量的值在函数调用结束时不消失而继续保留原值,即其占用的存储单元不释放,在下一次再调用该函数时,该变量已有值(就是上一次函数调用结束时的值)。这时就应该指定该变量为静态局部变量,用关键字“static”进行声明。
当变量声明为static时,空间将在程序的生命周期内分配。即使多次调用该函数,静态变量的空间也只分配一次,前一次调用中的变量值通过下一次函数调用传递。这对于需要存储先前函数状态的任何其他应用程序非常有用。
虽然静态局部变量在函数调用结束后仍然存在,但是其他函数是不能引用他的。因为他本质仍是局部变量,只能被本函数引用(只在其作用域内有效),而不能被其他函数引用。
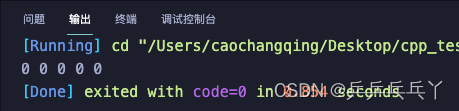
#include <iostream>
#include <string>
using namespace std;
void demo()
{
int count = 0;
cout << count << " ";
count++;
}
int main()
{
for (int i=0; i<5; i++)
demo();
return 0;
} 
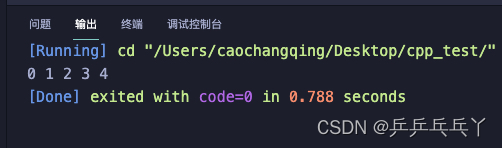
当把变量count声明为静态变量:
#include <iostream>
#include <string>
using namespace std;
void demo()
{
static int count = 0;
cout << count << " ";
count++;
}
int main()
{
for (int i=0; i<5; i++)
demo();
return 0;
} 
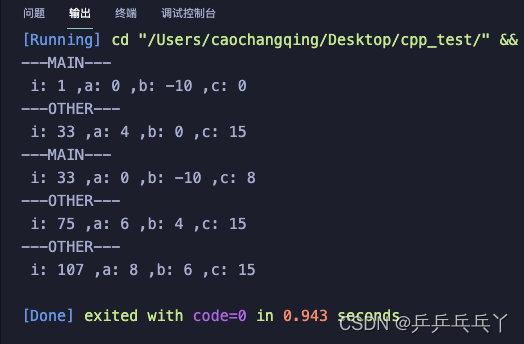
例1
#include<iostream>
using namespace std;
int i=1; // i为全局变量,具有静态生存期。
int main(void)
{
static int a; // 静态局部变量,有全局寿命,局部可见。
int b=-10; // b, c为局部变量,具有动态生存期。
int c=0;
void other(void);
cout<<"---MAIN---\n";
cout<<" i: "<<i<<" ,a: "<<a<<" ,b: "<<b<<" ,c: "<<c<<endl; // i: 1 a: 0 b: -10 c: 0
c=c+8;
other(); // i: 33 a: 4 b: 0 c: 15
cout<<"---MAIN---\n";
cout<<" i: "<<i<<" ,a: "<<a<<" ,b: "<<b<<" ,c: "<<c<<endl; // i: 33 a: 0 b: -10 c: 8
i=i+10;
other(); // i: 75 a: 6 b: 4 c: 15
other(); // i: 107 a: 8 b: 6 c: 15
return 0;
}
void other(void)
{
static int a=2;
static int b;
// a,b为静态局部变量,具有全局寿命,局部可见。只第一次进入函数时被初始化。
int c=10; // C为局部变量,具有动态生存期
//每次进入函数时都初始化。
a=a+2; i=i+32; c=c+5;
cout<<"---OTHER---\n";
cout<<" i: "<<i<<" ,a: "<<a<<" ,b: "<<b<<" ,c: "<<c<<endl;
b=a;
}
2) 类中的静态变量
由于声明为static的变量只被初始化一次,因为它们在单独的静态存储中分配了空间,因此类中的静态变量由对象共享。对于不同的对象,不能有相同静态变量的多个副本。也是因为这个原因,静态变量不能使用构造函数初始化,而是应由用户使用类外的类名和范围解析运算符显式初始化。
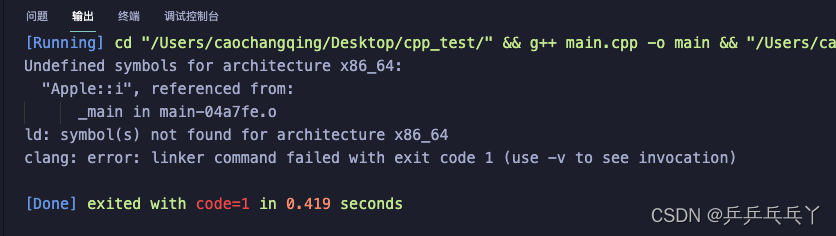
如下会报错:
#include<iostream>
using namespace std;
class Apple
{
public:
static int i;
Apple()
{
// Do nothing
};
};
int main()
{
Apple obj1;
obj1.i =2; // 类内静态变量没在类外初始化
cout << obj1.i;
} 
修改如下:
#include<iostream>
using namespace std;
class Apple
{
public:
static int i;
Apple()
{
// Do nothing
};
};
int Apple::i = 1; // 静态变量在类外做初始化
int main()
{
Apple obj1;
cout << obj1.i;
} 
例1
#include<iostream>
using namespace std;
class A
{
public:
static void f(); // 静态成员函数只能引用属于该类的静态数据成员或静态成员函数。
static void f(A a);
private:
int x;
};
void A::f(){
A a;
a.x = 6;
cout<<a.x<<"\n";
}
void A::f(A a)
{
// cout<<x; //对x的引用是错误的
cout<<a.x<<"\n"; //正确
}
int main(int argc, char const *argv[])
{
A a;
a.f(A());
cout<<"--------------\n";
a.f();
return 0;
}
例2
/*
学习知识:
静态数据成员
用关键字static声明
该类的所有对象维护该成员的同一个拷贝
必须在类外定义和初始化,用(::)来指明所属的类。
*/
#include <iostream>
using namespace std;
class Point
{
public:
Point(int xx=0, int yy=0) {X=xx; Y=yy; countP++; }
Point(Point &p);
int GetX() {return X;}
int GetY() {return Y;}
void GetC() {cout<<" Object id="<<countP<<endl;}
private:
int X,Y;
//静态数据成员,必须在外部定义和初始化,内部不能直接初始化!
static int countP;
};
Point::Point(Point &p)
{
X=p.X;
Y=p.Y;
countP++;
}
//必须在类外定义和初始化,用(::)来指明所属的类。
int Point::countP=0;
int main()
{
Point A(4,5);
cout<<"Point A: "<<A.GetX()<<", "<<A.GetY()<<endl;
A.GetC();
Point B(A);
cout<<"Point B: "<<B.GetX()<<", "<<B.GetY()<<endl;
B.GetC();
return 0;
} 
(2)静态函数
error: call to non-static member function without an object argument_舒泱的博客-CSDN博客
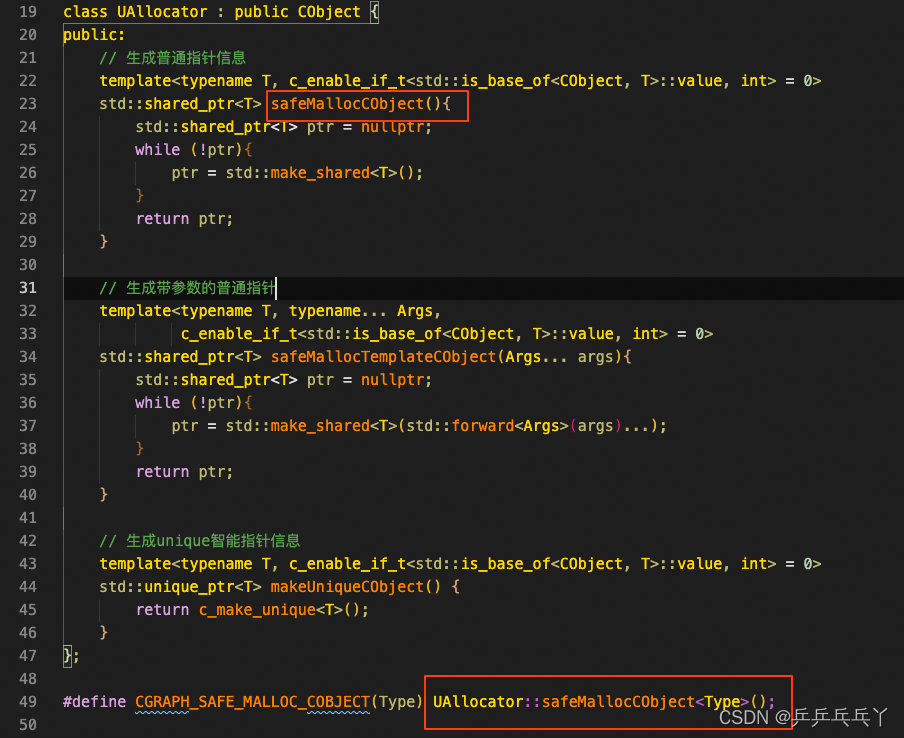
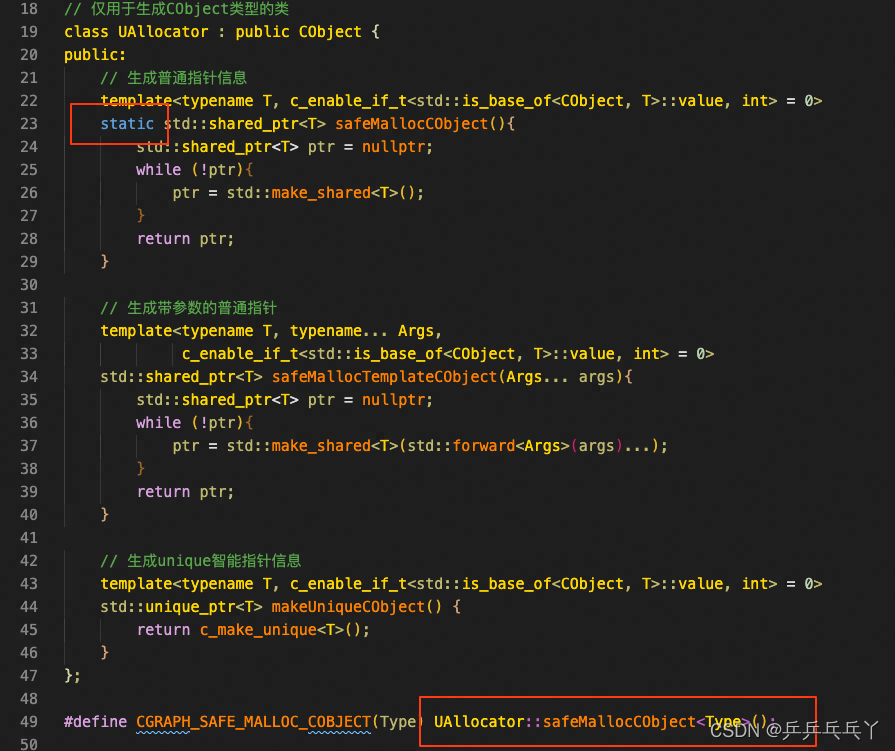
静态成员函数(或成员变量)可直接用“ 类::函数名”(或“ 类::成员变量”)调用,无需实例化。
报错如下: 错误:调用不带对象参数的非静态成员函数。
出现这个错误的原因是,类没有实例化 。
1)

修改如下:
2)
报错如下:

修改如下:
3)
举个栗子,例如:
// 自定义了一个类Student,里面有个函数getAge()
class Student
{
public:
int getAge();
};出现这个错误的原因,也许是你在调用函数getAge()的时候这样操作:
Student::getAge();
或者这样操作:
Student.getAge();
这样就是没有实例化类Student,就直接去调用了里面的成员函数。
改正方法一:先实例化一个对象
Student XiaoWang; //先实例化一个对象小王
int age = XiaoWang.getAge();
// 这样就对啦,先把类Student实例化成一个具体的对象XiaoWang小王,再调用函数getAge()得到小王的年龄改正方法二:把成员函数声明成静态函数
class Student
{
public:
static int getAge(); // 声明成了静态函数
};
// 然后你就可以这样不实例化类,直接调用函数了:
Student::getAge();
// 静态成员函数就可以直接用“ `类::函数名`”调用。下面我们来分析一下为什么可以这样改:
(1)为什么要实例化
仍然以上面的类Student为例。类Student表示学生,这是一个抽象的概念,表示的是所有学生。实例化一个对象Student XiaoWang;,这个对象表示的是具体的学生小王,你还可以实例化别的对象比如小张、小刘、小李、小周、小赵等等,这些对象都是具体的某个学生。
类的成员函数getAge()的意思是得到学生的年龄,我们最直观的理解就是,学生的年龄那肯定是某一个具体的学生的年龄,如果你用Student.getAge()的方法调用年龄函数,那究竟得到的是哪个学生的年龄呢?所以对于这种非静态成员函数,我们要实例化一个对象比如学生小王,我们调用XiaoWang.getAge()得到的就是小王的年龄。
(2)为什么调用静态函数不需要实例化
仍然以上面的类Student为例。如果现在我们要得到所有学生的平均年龄该怎么办呢?假如现在类Student里增加了一个函数getAverageAge(),我们想得到所有学生的平均年龄,难道还要先实例化一个对象表示具体的学生,再通过这个对象得到平均年龄吗?
所有学生的平均年龄,是学生类Student的一个共同特点,我们可以把得到平均年龄函数声明成静态函数,static int getAverageAge();,然后无需实例化对象,直接通过Student::getAverageAge();的方式调用。
类的静态函数表示的是这个类的一个共同特点,静态函数是类的所有对象所共享的,不是某一个对象特有的,就像平均年龄是所有学生所共有的而不是某个学生所特有的,因此,静态函数不需要实例化对象,直接通过类名::函数名的方式就能调用。
因此,在选择用上面两种方法中的哪一种方法的时候,需要根据你写的函数的意义。
- 如果你写的函数表示的是对象特有的特性,比如学生的年龄函数,用第一种方法,实例化对象再调用函数,更好。
- 如果你写的函数表示的是这个类的所有对象共享的特性,比如所有学生的平均年龄函数,用第二种方法,将该函数声明成静态函数,更好。
③ 纯虚函数与抽象类
(至少包含一个纯虚函数的类)
- 派生类中如果没有完全实现基类的所有纯虚函数,则此时的派生类也是抽象类,不能实例化对象。换言之,抽象类的派生类是允许不实现基类的所有纯虚函数的。
(1)抽象类只能作为基类来派生新类使用,不能创建抽象类的对象,抽象类的指针和引用->由抽象类派生出来的类的对象。
/**
* @brief 纯虚函数:没有函数体的虚函数
* 抽象类:包含纯虚函数的类
*/
#include<iostream>
using namespace std;
class A
{
private:
int a;
public:
virtual void show()=0; // 纯虚函数
};
int main()
{
/*
* 1. 抽象类只能作为基类来派生新类使用
* 2. 抽象类的指针和引用->由抽象类派生出来的类的对象!
*/
A a; // error 抽象类,不能创建对象
A *a1; // ok 可以定义抽象类的指针
A *a2 = new A(); // error, A是抽象类,不能创建对象
}(2)实现抽象类
抽象类中:在成员函数内可以调用纯虚函数,在构造函数/析构函数内部不能使用纯虚函数。
如果一个类从抽象类派生而来,它必须实现了基类中的所有纯虚函数,才能成为非抽象类。
/**
* @brief 抽象类中:在成员函数内可以调用纯虚函数,在构造函数/析构函数内部不能使用纯虚函数
* 如果一个类从抽象类派生而来,它必须实现了基类中的所有纯虚函数,才能成为非抽象类
*/
#include<iostream>
using namespace std;
// 抽象类
class A {
public:
virtual void f() = 0; // 纯虚函数
void g(){ this->f(); } // 在成员函数内可以调用纯虚函数
A(){}
};
// 非抽象类
class B:public A{
public:
void f(){ cout<<"B:f()"<<endl;}
};
int main(){
B b;
b.g();
b.f();
return 0;
}
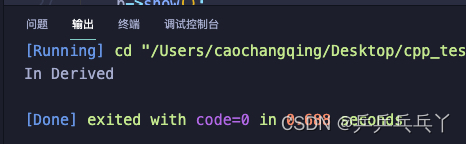
(3)
#include<iostream>
using namespace std;
// 抽象类至少包含一个纯虚函数
class Base{
public:
virtual void show() = 0; // 纯虚函数
int getX() { return x; } // 普通成员函数
private:
int x;
};
class Derived : public Base{
public:
Derived(){}
void show(){
std::cout << "In Derived\n";
}
};
int main(){
// Base b; // error! 不能创建抽象类的对象
// Base* b = new Base(); // error!
Base* b = new Derived(); // 抽象类的指针和引用 -> 由抽象类派生出来的类的对象
b->show();
return 0;
}
(4)抽象类可以有构造函数
#include<iostream>
using namespace std;
// 抽象类
class Base{
public:
virtual void f() = 0;
Base(int i){x = i;} // 构造函数
protected:
int x;
};
// 派生类
class Derived : public Base{
public:
void f(){std::cout << "x: " << x << ", y: " << y << "\n";}
Derived(int i, int j) : Base(i){y = j;} // 构造函数
private:
int y;
};
int main(){
Derived* d = new Derived(2, 4);
d->f();
return 0;
}
(5)构造函数不能是虚函数,析构函数可以是虚函数。
#include<iostream>
using namespace std;
// 抽象类
class Base{
public:
Base(){std::cout << "Constructor: Base\n";} // 构造函数不能是虚函数
virtual ~Base(){std::cout << "Destructor: Base\n";} // 析构函数可以是虚函数
virtual void f() = 0;
};
// 派生类
class Derived : public Base{
public:
Derived(){std::cout << "Constructor: Derived\n";}
~Derived(){std::cout << "Destructor: Derived\n";}
void f(){std::cout << "In Derived.f()\n";}
};
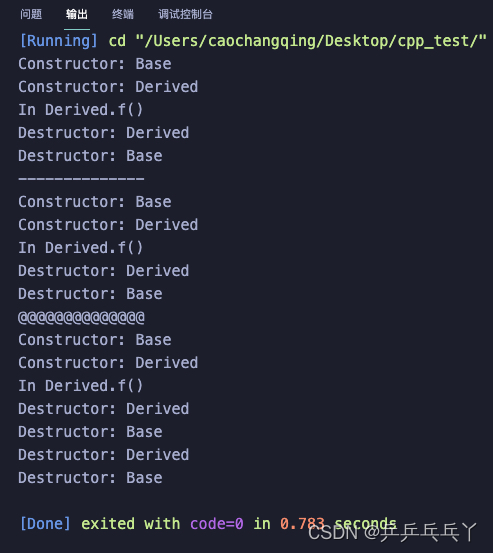
int main(){
Base* b = new Derived();
b->f();
b->~Base();
std::cout << "--------------\n";
Derived* d = new Derived();
d->f();
d->~Derived();
std::cout << "@@@@@@@@@@@@@@\n";
Derived d1;
d1.f();
d1.~Derived();
return 0;
}
(6)虚函数的默认参数的使用需要看指针或者应用本身的类型,而不是对象的类型!
/**
* @brief 虚函数中默认参数
* 规则:虚函数的默认参数的使用需要看指针或者应用本身的类型,而不是对象的类型!
*/
#include <iostream>
using namespace std;
class Base
{
public:
virtual void fun ( int x = 10 )
{
cout << "Base::fun(), x = " << x << endl;
}
};
class Derived : public Base
{
public:
virtual void fun ( int x = 20 )
{
cout << "Derived::fun(), x = " << x << endl;
}
};
int main()
{
Base* b = new Derived();
b->fun();
std::cout << "--------------------\n";
Derived* d = new Derived();
d->fun();
return 0;
}

(7)静态函数不可以声明为虚函数,同时也不能被const 和 volatile关键字修饰
④ volatile
-
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
-
volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
-
const 可以是 volatile (如只读的状态寄存器)
-
指针可以是 volatile
多线程应用中被多个任务共享的变量。 当多个线程共享某一个变量时,该变量的值会被某一个线程更改,应该用 volatile 声明。作用是防止编译器优化把变量从内存装入CPU寄存器中,当一个线程更改变量后,未及时同步到其它线程中导致程序出错。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
volatile bool bStop=false; //bStop 为共享全局变量
//第一个线程
void threadFunc1()
{
...
while(!bStop){...}
}
//第二个线程终止上面的线程循环
void threadFunc2()
{
...
bStop = true;
}要想通过第二个线程终止第一个线程循环,如果bStop不使用volatile定义,那么这个循环将是一个死循环,因为bStop已经读取到了寄存器中,寄存器中bStop的值永远不会变成FALSE,加上volatile,程序在执行时,每次均从内存中读出bStop的值,就不会死循环了。
是否了解volatile的应用场景是区分C/C++程序员和嵌入式开发程序员的有效办法,搞嵌入式的家伙们经常同硬件、中断、RTOS等等打交道,这些都要求用到volatile变量,不懂得volatile将会带来程序设计的灾难。
⑤ assert
断言主要用于检查逻辑上不可能的情况。例如,它们可用于检查代码在开始运行之前所期望的状态,或者在运行完成后检查状态。与正常的错误处理不同,断言通常在运行时被禁用(通过在文件的首行加上 #define NDEBUG )。
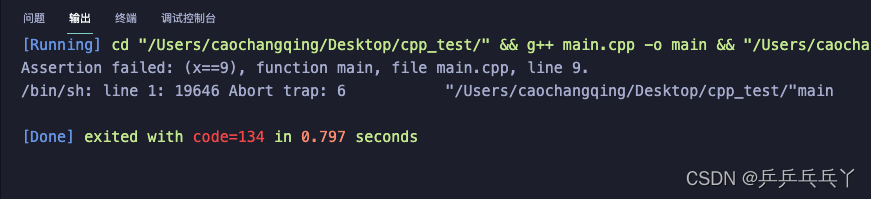
如下是assert起作用:
#include <iostream>
#include <assert.h>
int main()
{
int x = 7;
assert(x==9);
std::cout << "!!!!!!!!!!!!\n";
return 0;
} 
通过首行加上 #define NDEBUG 使断言失效:
#define NDEBUG
#include <iostream>
#include <assert.h>
int main()
{
int x = 7;
assert(x==9);
std::cout << "!!!!!!!!!!!!\n";
return 0;
} 
如果 #define NDEBUG 不在首行,则不能对断言起作用:
#include <iostream>
#include <assert.h>
#define NDEBUG
int main()
{
int x = 7;
assert(x==9);
std::cout << "!!!!!!!!!!!!\n";
return 0;
} 
⑥ extern "C"
在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。所以使用extern "C"全部都放在于cpp程序相关文件或其头文件中。
(1)C++调用C函数
//xx.h
extern int add(...)
//xx.c
int add(){
}
//xx.cpp
extern "C" {
#include "xx.h"
}(2)C调用C++函数
//xx.h
extern "C"{
int add();
}
//xx.cpp
int add(){
}
//xx.c
extern int add();不过与C++调用C接口不同,C++确实是能够调用编译好的C函数,而这里C调用C++,不过是把C++代码当成C代码编译后调用而已。也就是说,C并不能直接调用C++库函数。
⑦ struct
| C | C++ |
|---|---|
| 不能将函数放在结构体声明 | 能将函数放在结构体声明 |
| 在C结构体声明中不能使用C++访问修饰符。 | public、protected、private 在C++中可以使用。 |
| 在C中定义结构体变量,如果使用了下面定义必须加struct。 | 可以不加struct |
| 结构体不能继承(没有这一概念)。 | 可以继承 |
| 若结构体的名字与函数名相同,可以正常运行且正常的调用! | 若结构体的名字与函数名相同,使用结构体,只能使用带struct定义! |
(1)C中struct
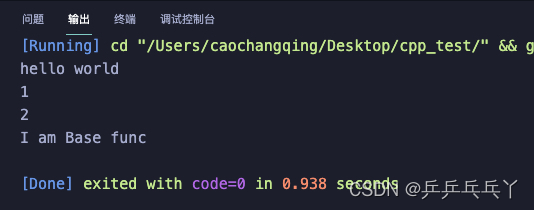
#include<stdio.h>
struct Base { // public
int v1;
// public: //error
int v2;
//private:
int v3;
//void print(){ // c中不能在结构体中嵌入函数
// printf("%s\n","hello world");
//}; //error!
};
void Base(){
printf("%s\n","I am Base func");
}
//struct Base base1; //ok
//Base base2; //error
int main() {
struct Base base;
base.v1=1;
//base.print();
printf("%d\n",base.v1);
Base();
return 0;
}输出:

(2)C++中struct
1)不使用typedef定义结构体别名
I. 未添加同名函数
struct Student {
};
struct Student s; //ok
Student s; //okII.添加同名函数
struct Student {
};
Student(){}
struct Student s; //ok
Student s; //error2)使用typedef定义结构体别名
typedef struct Base1 {
int v1;
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
}B;
//void B() {} //error! 符号 "B" 已经被定义为一个 "struct Base1" 的别名(3)struct与class区别
总的来说,struct 更适合看成是一个数据结构的实现体,class 更适合看成是一个对象的实现体。
最本质的区别就是默认的继承访问权限:struct 是 public 的,class 是 private 的。
例1 结构体继承举例
#include<iostream>
struct Base {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
virtual void print(){
printf("%s\n","Base");
};
};
// 结构体继承
struct Derived:Base {
public:
int v2;
void print(){
printf("%s\n","Derived");
};
};
int main() {
Base *b=new Derived();
b->print();
return 0;
}
例2 同名函数举例
#include<iostream>
struct Base {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
};
typedef struct Base1 {
int v1;
// private: //error!
int v3;
public: //显示声明public
int v2;
void print(){
printf("%s\n","hello world");
};
}B;
// 结构体的同名函数
void Base(){
printf("%s\n","I am Base func");
}
//void B() {} //error! 符号 "B" 已经被定义为一个 "struct Base1" 的别名
int main() {
struct Base base; //ok
//Base base1; // error!
base.v1=1;
base.v3=2;
base.print();
printf("%d\n",base.v1);
printf("%d\n",base.v3);
Base();
return 0;
}
⑧ explicit(显式)关键字
- explicit 修饰构造函数时,可以防止隐式转换和复制初始化
- explicit 修饰转换函数时,可以防止隐式转换,但按语境转换除外
#include <iostream>
using namespace std;
struct A
{
A(int) { }
// 类型转换函数
operator bool() const { return true; }
};
struct B
{
explicit B(int) {} // explicit修饰构造函数时,可以防止隐式转换和复制初始化
explicit operator bool() const { return true; } // explicit修饰转换函数时,可以防止隐式转换,但按语境转换除外
};
void doA(A a) {}
void doB(B b) {}
int main()
{
A a1(1); // OK:直接初始化
A a2 = 1; // OK:复制初始化
A a3{ 1 }; // OK:直接列表初始化
A a4 = { 1 }; // OK:复制列表初始化
A a5 = (A)1; // OK:允许 static_cast 的显式转换
doA(1); // OK:允许从 int 到 A 的隐式转换
if (a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a6(a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a7 = a1; // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a8 = static_cast<bool>(a1); // OK :static_cast 进行直接初始化
B b1(1); // OK:直接初始化
// B b2 = 1; // 错误:被 explicit 修饰构造函数的对象不可以复制初始化
B b3{ 1 }; // OK:直接列表初始化
// B b4 = { 1 }; // 错误:被 explicit 修饰构造函数的对象不可以复制列表初始化
B b5 = (B)1; // OK:允许 static_cast 的显式转换
// doB(1); // 错误:被 explicit 修饰构造函数的对象不可以从 int 到 B 的隐式转换
if (b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b6(b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
// bool b7 = b1; // 错误:被 explicit 修饰转换函数 B::operator bool() 的对象不可以隐式转换
bool b8 = static_cast<bool>(b1); // OK:static_cast 进行直接初始化
return 0;
}⑨ friend
友元提供了一种 普通函数或者类成员函数 访问另一个类中的私有或保护成员 的机制。也就是说有两种形式的友元:
- 友元函数:普通函数对一个访问某个类中的私有或保护成员。
- 友元类:类A中的成员函数访问类B中的私有或保护成员
优点:提高了程序的运行效率。
缺点:破坏了类的封装性和数据的透明性。
总结:
- 能访问私有成员
- 破坏封装性
- 友元关系不可传递:假如类B是类A的友元,类C是类B的友元,那么友元类C是没办法直接访问类A的私有或保护成员,也就是不存在“友元的友元”这种关系。
- 友元关系的单向性:友元关系没有继承性。假如类B是类A的友元,类C继承于类A,那么友元类B是没办法直接访问类C的私有或保护成员。
- 友元声明的形式及数量不受限制
(1)友元函数
友元函数只是一个普通函数,并不是该类的类成员函数,它可以在任何地方调用,友元函数中通过对象名来访问该类的私有或保护成员。
#include <iostream>
using namespace std;
class A
{
public:
A(int _a):a(_a){};
friend int geta(A &ca); // 友元函数
private:
int a;
};
int geta(A &ca)
{
return ca.a;
}
int main()
{
A a(3);
cout<<geta(a)<<endl;
return 0;
}
(2)友元类
类B是类A的友元,那么类B可以直接访问A的私有成员。
#include <iostream>
using namespace std;
class A
{
public:
A(int _a):a(_a){};
friend class B;
private:
int a;
};
class B
{
public:
int getb(A ca) {
return ca.a;
};
};
int main()
{
A a(3);
B b;
cout<<b.getb(a)<<endl;
return 0;
}
⑩ using
(1)局部与全局using
#include <iostream>
#define isNs1 0
// #define isGlobal 11
using namespace std;
void func()
{
cout<<"::func"<<endl;
}
namespace ns1 {
void func()
{
cout<<"ns1::func"<<endl;
}
}
namespace ns2 {
#ifdef isNs1
using ns1::func; // ns1中的函数
#elif isGlobal
using ::func; // 全局中的函数
#else
void func()
{
cout<<"other::func"<<endl;
}
#endif
}
int main()
{
ns2::func(); // 会根据当前环境定义宏的不同来调用不同命名空间下的func()函数
return 0;
}
#include <iostream>
// #define isNs1 0
#define isGlobal 11
using namespace std;
void func()
{
cout<<"::func"<<endl;
}
namespace ns1 {
void func()
{
cout<<"ns1::func"<<endl;
}
}
namespace ns2 {
#ifdef isNs1
using ns1::func; // ns1中的函数
#elif isGlobal
using ::func; // 全局中的函数
#else
void func()
{
cout<<"other::func"<<endl;
}
#endif
}
int main()
{
ns2::func(); // 会根据当前环境定义宏的不同来调用不同命名空间下的func()函数
return 0;
}
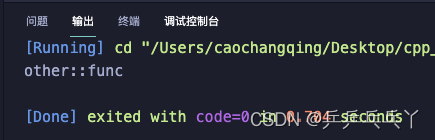
#include <iostream>
// #define isNs1 0
// #define isGlobal 11
using namespace std;
void func()
{
cout<<"::func"<<endl;
}
namespace ns1 {
void func()
{
cout<<"ns1::func"<<endl;
}
}
namespace ns2 {
#ifdef isNs1
using ns1::func; // ns1中的函数
#elif isGlobal
using ::func; // 全局中的函数
#else
void func()
{
cout<<"other::func"<<endl;
}
#endif
}
int main()
{
ns2::func(); // 会根据当前环境定义宏的不同来调用不同命名空间下的func()函数
return 0;
}
(2)取代typedef
C中常用typedef A B这样的语法,将B定义为A类型,也就是给A类型一个别名B
对应typedef A B,使用using B=A可以进行同样的操作。
typedef vector<int> V1; 等同于 using V2 = vector<int>;
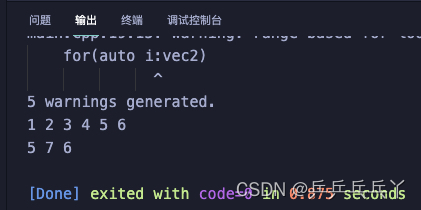
#include <iostream>
#include <vector>
using namespace std;
typedef vector<int> V1;
using V2 = vector<int>;
int main()
{
int nums1[] = {1,2,3,4,5,6};
V1 vec1(nums1, nums1+sizeof(nums1)/sizeof(int));
int nums2[] = {5,7,6};
V2 vec2(nums2, nums2+sizeof(nums2)/sizeof(int));
for(auto i:vec1)
cout<<i<<" ";
cout<<endl;
for(auto i:vec2)
cout<<i<<" ";
cout<<endl;
return 0;
}
2.
① :: 范围解析运算符
- 全局作用域符(::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间
- 类作用域符(class::name):用于表示指定类型的作用域范围是具体某个类的
- 命名空间作用域符(namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
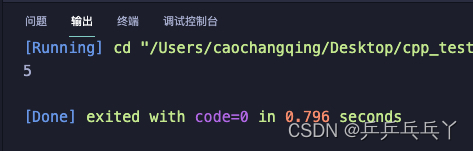
#include <iostream>
using namespace std;
int count=0; // 全局(::)的count
class A {
public:
static int count; // 类A的count (A::count)
};
// 静态变量必须在此处定义
int A::count;
int main() {
::count=1; // 设置全局的count为1
A::count=5; // 设置类A的count为2
cout<<A::count<<endl;
// int count=3; // 局部count
// count=4; // 设置局部的count为4
return 0;
}
② enum
(1)enum作用域不受限,会带来命名冲突的问题
- 会隐式转换为int
- 用来表征枚举变量的实际类型不能明确指定,从而无法支持枚举类型的前向声明。
#include <iostream>
using namespace std;
enum Color {RED,BLUE};
int main()
{
std::cout << Color::RED << "\n";
std::cout << Color::BLUE << "\n";
return 0;
}
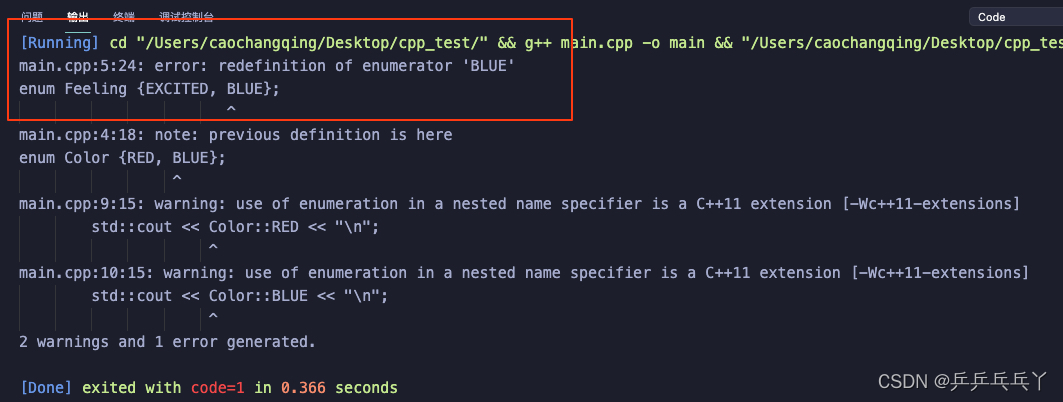
如下会报错:
#include <iostream>
using namespace std;
enum Color {RED, BLUE};
enum Feeling {EXCITED, BLUE};
int main()
{
std::cout << Color::RED << "\n";
std::cout << Color::BLUE << "\n";
return 0;
}
(2)解决作用域不受限带来的命名冲突问题的方法
1)给枚举变量命名时加前缀:如上面例子改成 COLOR_BLUE 以及 FEELING_BLUE。一般说来,为了一致性我们会把所有常量统一加上前缀。但是这样定义枚举变量的代码就显得累赘。
2)用命名空间来限定其作用域:
namespace Color
{
enum Type
{
RED=15,
YELLOW,
BLUE
};
};这样之后就可以用 Color::Type c = Color::RED; 来定义新的枚举变量了。
不过,因为命名空间是可以随后被扩充内容的,所以它提供的作用域封闭性不高。在大项目中,还是有可能不同人给不同的东西起同样的枚举类型名。
3)用一个类或结构体来限定其作用域:例如定义新变量的方法和上面命名空间的相同。不过这样就不用担心类在别处被修改内容。这里用结构体而非类,一是因为本身希望这些常量可以公开访问,二是因为它只包含数据没有成员函数。
struct Color1
{
enum Type
{
RED=102,
YELLOW,
BLUE
};
};(3)C++11 的枚举类
上面的做法解决了第一个问题,但对于后两个仍无能为力。庆幸的是,C++11 标准中引入了“枚举类”(enum class),可以较好地解决上述问题。
- 新的enum的作用域不在是全局的
- 不能隐式转换成其他类型
- 可以指定用特定的类型来存储enum
/**
* @brief C++11的枚举类
* 下面等价于enum class Color2:int
*/
enum class Color2
{
RED=2,
YELLOW,
BLUE
};
Color2 c2 = Color2::RED;
cout << static_cast<int>(c2) << endl; //必须转!enum class Color3:char; // 前向声明
// 定义
enum class Color3:char
{
RED='r',
BLUE
};
char c3 = static_cast<char>(Color3::RED);(4)类中的枚举类型
有时我们希望某些常量只在类中有效。 由于#define 定义的宏常量是全局的,不能达到目的,于是想到实用const 修饰数据成员来实现。而const 数据成员的确是存在的,但其含义却不是我们所期望的。
const 数据成员只在某个对象生存期内是常量,而对于整个类而言却是可变的,因为类可以创建多个对象,不同的对象其 const 数据成员的值可以不同。所以别指望 const 数据成员了,应该用类中的枚举常量来实现。例如:
class Person{
public:
typedef enum {
BOY = 0,
GIRL
}SexType;
};
//访问的时候通过,Person::BOY或者Person::GIRL来进行访问。枚举常量不会占用对象的存储空间,它们在编译时被全部求值。
枚举常量的缺点是:它的隐含数据类型是整数,其最大值有限,且不能表示浮点。
例1
#include <iostream>
using namespace std;
/**
* @brief namespace解决作用域不受限
*/
namespace Color
{
enum Type
{
RED=15,
YELLOW,
BLUE
};
};
/**
* @brief 上述如果 using namespace Color 后,前缀还可以省去,使得代码简化。
* 不过,因为命名空间是可以随后被扩充内容的,所以它提供的作用域封闭性不高。
* 在大项目中,还是有可能不同人给不同的东西起同样的枚举类型名。
* 更“有效”的办法是用一个类或结构体来限定其作用域。
*
* 定义新变量的方法和上面命名空间的相同。
* 不过这样就不用担心类在别处被修改内容。
* 这里用结构体而非类,一是因为本身希望这些常量可以公开访问,
* 二是因为它只包含数据没有成员函数。
*/
struct Color1
{
enum Type
{
RED=102,
YELLOW,
BLUE
};
};
/**
* @brief C++11的枚举类
* 下面等价于enum class Color2:int
*/
enum class Color2
{
RED=2,
YELLOW,
BLUE
};
enum class Color3:char; // 前向声明
// 定义
enum class Color3:char
{
RED='r',
BLUE
};
int main()
{
// 定义新的枚举变量
Color::Type c = Color::RED;
cout<<c<<endl;
/**
* 上述的另一种方法:
* using namespace Color; // 定义新的枚举变量
* Type c = RED;
*/
Color1 c1;
cout<<c1.RED<<endl;
Color1::Type c11 = Color1::BLUE;
cout<<c11<<endl;
Color2 c2 = Color2::RED;
cout << static_cast<int>(c2) << endl;
char c3 = static_cast<char>(Color3::RED);
cout<<c3<<endl;
return 0;
}
③ 引用与指针
| 引用 | 指针 |
|---|---|
| 必须初始化 | 可以不初始化 |
| 不能为空 | 可以为空 |
| 不能更换目标 | 可以更换目标 |
int &r; //不合法,没有初始化引用
int *p; //合法,但p为野指针,使用需要小心void test_p(int* p)
{
if(p != null_ptr) //对p所指对象赋值时需先判断p是否为空指针
*p = 3;
return;
}
void test_r(int& r)
{
r = 3; //由于引用不能为空,所以此处无需判断r的有效性就可以对r直接赋值
return;
}④ 宏
(1)宏内的特殊符号
1)字符串化操作符 (#)
#是“字符串化”的意思,出现在宏定义中的#是把跟在后面的参数转换成一个字符串。
下述代码给出了基本的使用与空格处理规则:
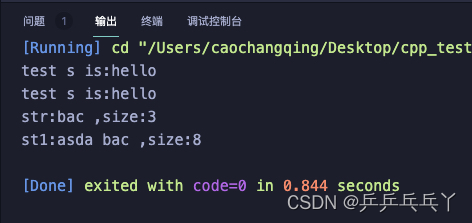
#include <iostream>
using namespace std;
#define exp(s) printf("test s is:%s\n", s)
#define exp1(s) printf("test s is:%s\n", #s)
#define exp2(s) #s
int main() {
exp("hello");
exp1(hello);
// 会忽略传入参数名前面和后面的空格。
string str = exp2( bac );
cout<<"str:"<<str<<" ,size:"<<str.size()<<endl;
string str1 = exp2( asda bac );
// 当传入参数名间存在空格时,编译器将会自动连接各个子字符串,用每个子字符串之间以一个空格连接,忽略剩余空格。
cout<<"st1:"<<str1<<" ,size:"<<str1.size()<<endl;
return 0;
}
2)符号连接操作符(##)
“##”是一种分隔连接方式,它的作用是先分隔,然后进行强制连接。将宏定义的多个形参转换成一个实际参数名。
- 当用##连接形参时,##前后的空格可有可无。
- 连接后的实际参数名,必须为实际存在的参数名或是编译器已知的宏定义。
- 如果##后的参数本身也是一个宏的话,##会阻止这个宏的展开。
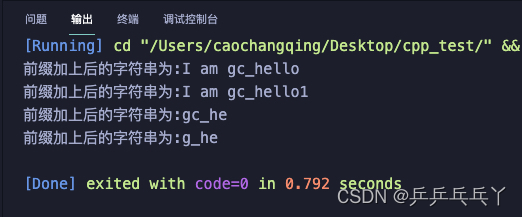
#include <iostream>
#define expA(s) printf("前缀加上后的字符串为:%s\n",gc_##s) //gc_s必须存在
// 注意事项2
#define expB(s) printf("前缀加上后的字符串为:%s\n",gc_ ## s) //gc_s必须存在
#define expC(cs) printf("前缀加上后的字符串为:%s\n",g_ ## cs)
// 注意事项1
#define gc_hello1 "I am gc_hello1"
int main() {
// 注意事项1
const char * gc_hello = "I am gc_hello";
expA(hello);
expB(hello1);
const char * gc_he = "gc_he";
expA(he);
const char * g_he = "g_he";
expC(he);
}
3)续行操作符(\)
当定义的宏不能用一行表达完整时,可以用”\”表示下一行继续此宏的定义。注意 \ 前留空格。
每个#define的最后一行是不能加反斜杠的。
#include <iostream>
using namespace std;
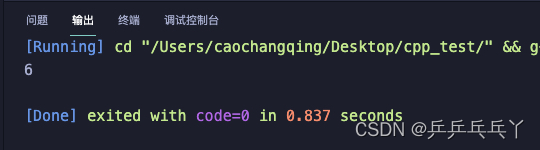
#define MAX(a,b) ((a)>(b) ? (a) \
:(b))
int main() {
int max_val = MAX(3,6);
cout<<max_val<<endl;
}
例1
因为如下的多个函数都在同一个#define下,所以反斜杠在每个函数的最后一行都是存在的。
#ifndef _CGRAPH_GPARAMMANAGERWRAPPER_H_
#define _CGRAPH_GPARAMMANAGERWRAPPER_H_
#include <iostream>
#include <string>
#include <vector>
#include "GParam.h"
#include "GParamManager.h"
CGRAPH_NAMESPACE_BEGIN
#define CGRAPH_DECLARE_GPARAM_MANAGER_WRAPPER \
/*
* 创建param信息,如果创建成功,则直接返回ok
* @tparam TGParam
* @param key
* @param backtrace
* @return
*/
template<typename TGParam, \
c_enable_if_t<std::is_base_of<GParam, TGParam>::value, int> = 0> \
CStatus createGParam(const std::string& key, CBool backtrace = false) { \
CGRAPH_ASSERT_NOT_NULL(param_manager_) \
return param_manager_->create<TGParam>(key, backtrace); \
} \
/**
* 获取参数信息,如果未找到,则返回nullptr
* @tparam TGParam
* @param key
* @return
*/
template<typename TGParam, \
c_enable_if_t<std::is_base_of<GParam, TGParam>::value, int> = 0> \
std::shared_ptr<TGParam> getGParam(const std::string& key) { \
CGRAPH_ASSERT_NOT_NULL_RETURN_NULL(param_manager_) \
auto param = param_manager_->get<TGParam>(key); \
if (nullptr != param) { \
param->addBacktrace(GNodeInfo::name_.empty() ? session_ : name_); \
} \
return param; \
} \
/**
* 获取参数信息,如果未找到,则返回nullptr
* @tparam TGParam
* @param key
* @return
*/
template<typename TGParam, \
c_enable_if_t<std::is_base_of<GParam, TGParam>::value, int> = 0> \
std::shared_ptr<TGParam> getGParamWithNoEmpty(const std::string& key) { \
auto* param = getGParam<TGParam>(key); \
if (nullptr == param) { \
CGRAPH_THROW_EXCEPTION("param [" + key + "] is null") \
} \
return param; \
} \
/**
* 删除param信息
* @param key
* @return
*/
CStatus removeGParam(const std::string& key) { \
CGRAPH_ASSERT_NOT_NULL(param_manager_) \
return param_manager_->removeByKey(key); \
} \
/**
* 设置统一管控参数类
* @param pm
* @return
*/
void* setGParamManager(GParamManagerPtr pm) { \
// param_manager_ = pm;
param_manager_ = pm; \
return this; \
} \
/**
* 获取所有的keys信息
* @param keys
* @return
*/
CStatus getGParamKeys(std::vector<std::string>& keys) { \
CGRAPH_ASSERT_NOT_NULL(param_manager_) \
return param_manager_->getKeys(keys); \
} \
CGRAPH_NAMESPACE_END
#endif // _CGRAPH_GPARAMMANAGERWRAPPER_H_(2)do{...}while(0)的使用
1)避免语义曲解
例如:
#define fun() f1();f2();
if(a>0)
fun()这个宏被展开后就是:
if(a>0)
f1();
f2();本意是a>0执行f1 f2,而实际是f2每次都会执行,所以就错误了。
为了解决这种问题,在写代码的时候,通常可以采用{}块:
#define fun() {f1();f2();}
if(a>0)
fun();
// 宏展开
if(a>0)
{
f1();
f2();
};但是会发现上述宏展开后多了一个分号,实际语法不太对。(虽然编译运行没问题,正常没分号)。
2)避免由宏引起的警告
内核中由于不同架构的限制,很多时候会用到空宏,。在编译的时候,这些空宏会给出warning,为了避免这样的warning,我们可以使用do{...}while(0)来定义空宏:
#define EMPTYMICRO do{}while(0)3)定义单一的函数块来完成复杂的操作
如果你有一个复杂的函数,变量很多,而且你不想要增加新的函数,可以使用do{...}while(0),将你的代码写在里面,里面可以定义变量而不用考虑变量名会同函数之前或者之后的重复。 这种情况应该是指一个变量多处使用(但每处的意义还不同),我们可以在每个do-while中缩小作用域,比如:
#include <iostream>
using namespace std;
int fc()
{
int k1 = 10;
cout<<k1<<endl;
do{
int k1 = 100;
cout<<k1<<endl;
}while(0);
cout<<k1<<endl;
}
int main(){
fc();
return 0;
}
例1
#include <iostream>
#include <malloc.h>
using namespace std;
#define f1() cout<<"f1()"<<endl;
#define f2() cout<<"f2()"<<endl;
#define fun() {f1();f2();}
#define fun1() \
do{ \
f1();\
f2();\
}while(0)
int f() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
#ifndef DEBUG
int error=1;
#endif
if(error)
goto END;
// dosomething
END:
cout<<"free"<<endl;
free(p);
return 0;
}
int ff() {
int *p = (int *)malloc(sizeof(int));
*p = 10;
cout<<*p<<endl;
do{
#ifndef DEBUG
int error=1;
#endif
if(error)
break;
//dosomething
}while(0);
cout<<"free"<<endl;
free(p);
return 0;
}
int fc()
{
int k1 = 10;
cout<<k1<<endl;
do{
int k1 = 100;
cout<<k1<<endl;
}while(0);
cout<<k1<<endl;
}
int main() {
if(1>0)
fun();
if(2>0)
fun1();
f();
ff();
fc();
return 0;
}
⑤ 模版template
(1)函数模版
1)普通函数模版
// 函数模板参数可以是类属参数,也可以包括普通类型的参数
#include<iostream>
// 实现降序
template <class T>
void sort(T* a, int n){
for(int i = 0; i < n; i++){
int p = i;
for(int j = i; j < n; j++){
if(a[p] < a[j]){
p = j;
}
}
T t = a[i];
a[i] = a[p];
a[p] = t;
}
}
template <class T>
void display(T& a, int n){
for(int i = 0; i < n; i++){
std::cout << a[i] << "\t";
}
}
int main()
{
int a[] = {1, 41, 2, 5, 8, 21, 23};
char b[] = {'a','x','y','e','q','g','o','u'};
sort(a, 7);
display(a, 7);
std::cout << "\n";
sort(b, 8);
display(b, 8);
return 0;
} 
例1 显示指定函数模板实例化的参数类型
#include <iostream>
template <typename T>
T Max(T a,T b) {
return a > b ? a : b;
}
int main(){
// 显示指定函数模板实例化的参数类型
std::cout << "'aaa', 3的最大值是:" << Max<int>('aaa', 3);
}
2)特化函数模版(使用特化的前提是先实现了对应的普通函数模版)
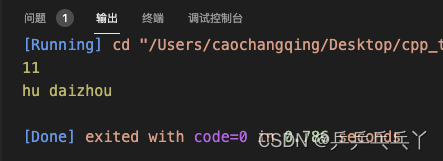
在学习模板的时候我们用模板来解决了一个add模板函数,实现不同类型的传参相加,实践证明,模板函数比普通函数好用。那么现在如果我们要新增一个需求,就是如果传入的是两个string类型的参数,我们不要简单的拼接,我们要在两个字符串之间添加一个空格,显然模板函数已经无法满足我们的要求,解决方法就是使用模板特化,简单说就是模板的一个特殊化,当传参为两个string类型的时候,不调用模板函数,而是调用特化模板函数,传入其它类型的时候,仍然使用模板函数,如下示例:
#include <iostream>
template <typename T>
T add(T a, T b){
return a + b;
}
// 模版特化
template<>
std::string add(std::string a, std::string b){
std::string c = " ";
return a + c + b;
}
int main(){
int a = 5, b = 6;
std::string c = "hu", d = "daizhou";
std::cout << add(a, b) << "\n";
std::cout << add(c, d) << "\n"; // 执行特化的模版
return 0;
}
模板特化的实现类似于函数重载,模板特化发生在编译时,而非运行时,所以效率高。
特化的模板声明,前面一般是template<>,方括号为空。当同时出现同名、同参的普通函数和特化模板函数,及同名模板函数时,编译器优先使用普通函数,再是特化模板函数,最后才是模板函数。
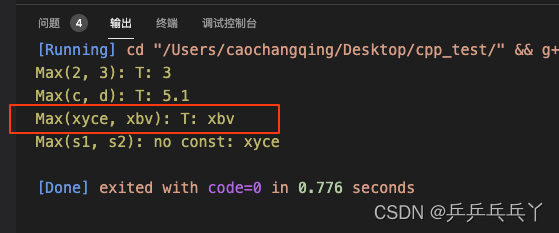
例1
#include <iostream>
template <typename T>
T Max(T a, T b){
std::cout << "T: ";
return a > b ? a : b;
}
template <>
char* Max(char* a, char* b){
std::cout << "no const: ";
return std::strcmp(a, b) >=0 ? a : b;
}
int main(){
float c = 5.1, d = 3.2;
char s1[] = "xyce", s2[] = "xbv";
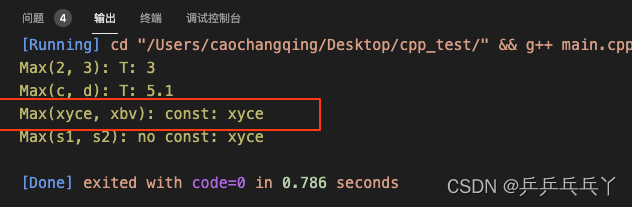
std::cout << "Max(2, 3): " << Max(2, 3) << "\n";
std::cout << "Max(c, d): " << Max(c, d) << "\n";
// "xyce"是常量,不符合特化模版template <>char* Max(char* a, char* b),所以走的是普通模版template <typename T> T Max(T a, T b)
std::cout << "Max(xyce, xbv): " << Max("xyce", "xbv") << "\n";
std::cout << "Max(s1, s2): " << Max(s1, s2) << "\n";
return 0;
}
可修改如下:
#include <iostream>
template <typename T>
T Max(T a, T b){
std::cout << "T: ";
return a > b ? a : b;
}
template <>
char* Max(char* a, char* b){
std::cout << "no const: ";
return std::strcmp(a, b) >=0 ? a : b;
}
template <>
const char* Max(const char* a, const char* b){
std::cout << "const: ";
return std::strcmp(a, b) >=0 ? a : b;
}
int main(){
float c = 5.1, d = 3.2;
char s1[] = "xyce", s2[] = "xbv";
std::cout << "Max(2, 3): " << Max(2, 3) << "\n";
std::cout << "Max(c, d): " << Max(c, d) << "\n";
// "xyce"是常量,走的是特化模版template <>const char* Max(const char* a, const char* b)
std::cout << "Max(xyce, xbv): " << Max("xyce", "xbv") << "\n";
std::cout << "Max(s1, s2): " << Max(s1, s2) << "\n";
return 0;
}
(2)类模版(必须显示指类数模板实例化的参数类型)
1)普通类模板
/*
设计一个堆栈的类模板Stack,在模板中用类型参数T表示栈中存放的数据,用非类型参数MAXSIZE代表栈的大小。
*/
#include<iostream>
// 类模版
template <typename T, int MAXSIZE>
class Stack{
public:
Stack(){top = 0;} // 栈的0是起点
void push(T e);
T pop();
bool empty(){
if(top < 0){
return true;
}else{
return false;
}
}
void setEmpty(){
top = -1;
}
bool full(){
if(top >= MAXSIZE -1){
return true;
}else{
return false;
}
}
private:
int top;
T elem[MAXSIZE];
};
template <typename T, int MAXSIZE>
// void Stack::push(T e) // 错
void Stack<T, MAXSIZE>::push(T e){
if(full()){
std::cout << "栈已满,不能再添加元素了!\n";
}
elem[++top] = e;
}
template <typename T, int MAXSIZE>
// T Stack<T, MAXSIZE>::pop() // 错
T Stack<T, MAXSIZE>::pop(){
if(empty()){
std::cout << "栈已空,不能再弹出元素了!\n";
return 0;
}
return elem[--top];
}
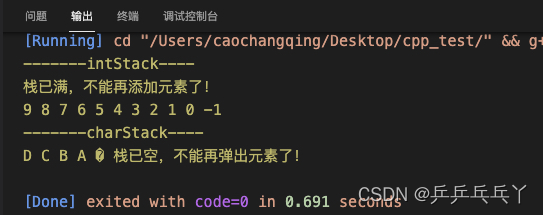
int main(){
Stack<int, 10> iStack;
Stack<char, 10> cStack;
// Stack dStack; // 错
iStack.setEmpty();
cStack.setEmpty();
std::cout << "-------intStack----\n";
for(int i = 0; i < 11; i++){
iStack.push(i);
}
for(int i = 0; i < 11; i++){
std::cout << iStack.pop() << "\t";
}
std::cout << "\n-------charStack----\n";
cStack.push('A');
cStack.push('B');
cStack.push('C');
cStack.push('D');
cStack.push('G');
for(int i = 0; i < 6; i++){
std::cout << cStack.pop() << "\t";
}
return 0;
}
2)特化
//设计一通用数组类,它能够直接存取数组元素,并能够对数组进行从大到小的排序。
#include<iostream>
#include<cstring>
const int Size = 5;
// lei
template<typename T>
class Array{
public:
Array(){
for(int i = 0; i < Size; i++){
a[i] = 0;
}
}
T& operator[](int idx);
void Sort();
private:
T a[Size];
};
template<typename T>
T& Array<T>::operator[](int idx){
if(idx < 0 || idx > Size -1){
std::cout << "数组下标越界!\n";
exit(1);
}
return a[idx];
}
template<typename T>
void Array<T>::Sort(){
int p;
for(int i = 0; i < Size - 1; i++){
p = i;
for(int j = i; j < Size; j++){
if(a[p] < a[j])
p = j;
}
T t = a[p];
a[p] = a[i];
a[i] = t;
}
}
// 特化函数模版
template<>
void Array<char*>::Sort(){
int p;
for(int i = 0; i < Size - 1; i++){
p = i;
for(int j = i; j < Size; j++){
if(std::strcmp(a[p], a[j]) < 0)
p = j;
}
char* t = a[p];
a[p] = a[i];
a[i] = t;
}
}
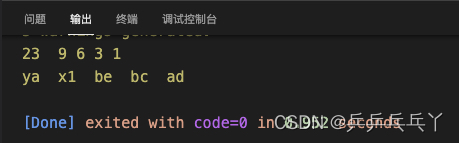
int main(){
Array<int> a;
a[0] = 1;
a[1] = 23;
a[2] = 6;
a[3] = 3;
a[4] = 9;
a.Sort();
for(int i = 0; i < 5; i++){
std::cout << a[i] << "\t";
}
std::cout << "\n";
Array<char*> c;
c[0] = "x1";
c[1] = "ya";
c[2] = "ad";
c[3] = "be";
c[4] = "bc";
c.Sort();
for(int i = 0; i < 5; i++){
std::cout << c[i] << "\t";
}
std::cout << "\n";
return 0;
}
注:模版嵌套时,留意模版形参不要重复。
报错 declaration of template parameter 'T' shadows template parameter
https://www.cnblogs.com/heitaiheizi/p/16042277.html

⑥ 异常处理
1.catch捕获异常时,不会进行数据类型的默认转换。
2.限制异常的方法
- 当一个函数声明中不带任何异常描述时,它可以抛出任何异常。例如:
int f(int,char); //函数f可以抛出任何异常
- 在函数声明的后面添加一个throw参数表,在其中指定函数可以抛出的异常类型。例如:
int g(int,char) throw(int,char); //只允许抛出int和char异常。
- 指定throw限制表为不包括任何类型的空表,不允许函数抛出任何异常。如:
int h(int,char) throw(); //不允许抛出任何异常
3.捕获所有异常 在多数情况下,catch都只用于捕获某种特定类型的异常,但它也具有捕获全部异常的能力。其形式如下:
catch(…) {
…… //异常处理代码
}
4.再次抛出异常 如是catch块无法处理捕获的异常,它可以将该异常再次抛出,使异常能够在恰当的地方被处理。再次抛出的异常不会再被同一个catch块所捕获,它将被传递给外部的catch块处理。要在catch块中再次抛出同一异常,只需在该catch块中添加不带任何参数的throw语句即可。 5.异常的嵌套调用 try块可以嵌套,即一个try块中可以包括另一个try块,这种嵌套可能形成一个异常处理的调用链。
例1
#include<iostream>
void temperature(int t){
try{
if(t == 100){
throw "It's at the boiling point.";
}else if(t == 0){
throw "It reached the freezing point";
}else{
std::cout << "the temperature is OK...\n";
}
}
catch(int x){
std::cout << "11111111111\n";
std::cout << "temperature: " << x << "\n";
}catch(const char* s){
std::cout << "22222222222\n";
std::cout << s << "\n";
}
}
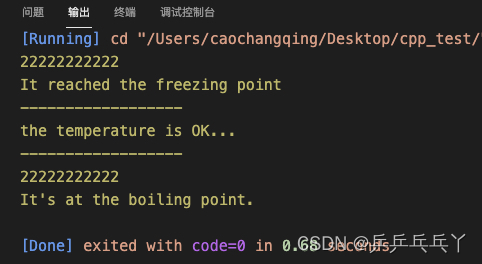
int main(){
temperature(0);
std::cout << "------------------\n";
temperature(10);
std::cout << "------------------\n";
temperature(100);
return 0;
}
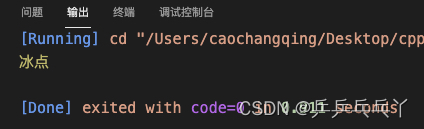
例2
#include<iostream>
void temperature(int t){
if(t == 100){
throw "沸点";
}else if (t == 0)
{
throw "冰点";
}else{
std::cout << "temperature: " << t << "\n";
}
}
int main(){
try{
temperature(0);
std::cout << "--------------\n";
temperature(10);
std::cout << "--------------\n";
temperature(100);
}catch(const char* s){
std::cout << s << "\n";
}
return 0;
}
例3
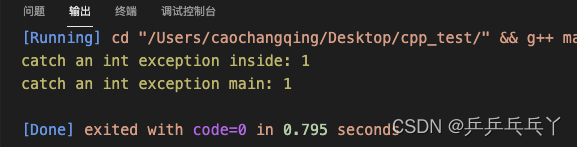
#include<iostream>
void Errhandler(int n){
try{
if(n == 1){
throw n;
}
std::cout << "all is ok\n";
}catch(int n){
std::cout << "catch an int exception inside: " << n << "\n";
throw n; // 再次抛出本catch捕获的异常
}
}
int main(){
try{
Errhandler(1);
}catch(int x){
std::cout << "catch an int exception main: " << x << "\n";
}
return 0;
}
例4
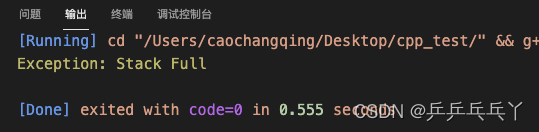
1)
#include <iostream>
const int MAX = 3;
class Full{}; // 定义堆栈满时抛出的异常类
class Empty{}; // 定义堆栈空时抛出的异常类
class Stack{
public:
Stack(){top = -1;}
void push(int x);
int pop();
private:
int top;
int s[MAX];
};
void Stack::push(int x){
if(top > MAX){
throw Full();
}
s[top++] = x; // 错
}
int Stack::pop(){
if(top < 0){
throw Empty();
}
return s[top--];
}
int main(){
Stack s;
try{
s.push(10);
s.push(20);
s.push(30);
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
}catch(Full){
std::cout << "Exception: Stack Full\n";
}catch(Empty){
std::cout << "Exception: Stack Empty\n";
}
return 0;
}
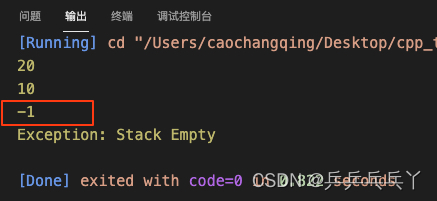
2)
#include <iostream>
const int MAX = 3;
class Full{}; // 定义堆栈满时抛出的异常类
class Empty{}; // 定义堆栈空时抛出的异常类
class Stack{
public:
Stack(){top = -1;}
void push(int x);
int pop();
private:
int top;
int s[MAX];
};
void Stack::push(int x){
if(top > MAX){
throw Full();
}
// s[top++] = x; // 错
s[++top] = x;
}
int Stack::pop(){
if(top < 0){
throw Empty();
}
return s[--top]; // 错
}
int main(){
Stack s;
try{
s.push(10);
s.push(20);
s.push(30);
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
}catch(Full){
std::cout << "Exception: Stack Full\n";
}catch(Empty){
std::cout << "Exception: Stack Empty\n";
}
return 0;
}
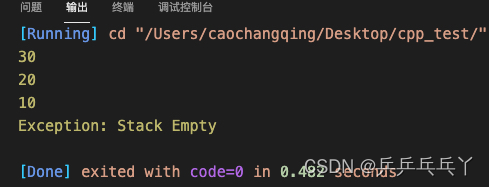
3)
#include <iostream>
const int MAX = 3;
class Full{}; // 定义堆栈满时抛出的异常类
class Empty{}; // 定义堆栈空时抛出的异常类
class Stack{
public:
Stack(){top = -1;}
void push(int x);
int pop();
private:
int top;
int s[MAX];
};
void Stack::push(int x){
if(top > MAX){
throw Full();
}
// s[top++] = x; // 错
s[++top] = x;
}
int Stack::pop(){
if(top < 0){
throw Empty();
}
// return s[--top]; // 错
return s[top--];
}
int main(){
Stack s;
try{
s.push(10);
s.push(20);
s.push(30);
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
std::cout << s.pop() << "\n";
}catch(Full){
std::cout << "Exception: Stack Full\n";
}catch(Empty){
std::cout << "Exception: Stack Empty\n";
}
return 0;
} 
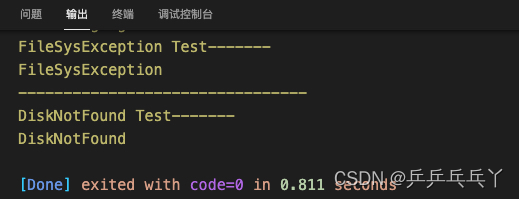
4)
#include <iostream>
class BasicException{
public:
char* Where(){
return "BasicException";
}
};
class FileSysException : public BasicException{
public:
char* Where(){
return "FileSysException";
}
};
class FileNotFound : public FileSysException{
public:
char* Where(){
return "FileNotFound";
}
};
class DiskNotFound : public FileSysException{
public:
char* Where(){
return "DiskNotFound";
}
};
int main(){
try{
std::cout << "FileSysException Test-------\n";
throw FileSysException();
}catch(DiskNotFound d){
std::cout << d.Where() << "\n";
}catch(FileNotFound f){
std::cout << f.Where() << "\n";
}catch(FileSysException f){
std::cout << f.Where() << "\n";
}catch(BasicException b){
std::cout << b.Where() << "\n";
}
std::cout << "--------------------------------\n";
try{
std::cout << "DiskNotFound Test-------\n";
throw DiskNotFound();
}catch(DiskNotFound d){
std::cout << d.Where() << "\n";
}catch(FileNotFound f){
std::cout << f.Where() << "\n";
}catch(FileSysException f){
std::cout << f.Where() << "\n";
}catch(BasicException b){
std::cout << b.Where() << "\n";
}
return 0;
} 
⑦ RAII机制
(资源获取就是初始化)C++中的RAII机制?_c++中raii机制_sixstar666的博客-CSDN博客
定义:
RAII是Resource Acquisition Is Initialization(wiki上面翻译成 “资源获取就是初始化”)的简称,是C++语言的一种管理资源、避免泄漏的惯用法。利用的就是C++构造的对象最终会被自动销毁的原则。RAII的做法是使用一个对象(类的实例),在其构造时获取对应的资源,在对象生命期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。
为什么要使用RAII:
上面说到RAII是用来管理资源、避免资源泄漏的方法。那么,用了这么久了,也写了这么多程序了,口头上经常会说资源,那么资源是如何定义的?在计算机系统中,资源是数量有限且对系统正常运行具有一定作用的元素。比如:网络套接字、互斥锁、文件句柄和内存等等,它们属于系统资源。由于系统的资源是有限的,就好比自然界的石油,铁矿一样,不是取之不尽,用之不竭的,所以,我们在编程使用系统资源时,都必须遵循一个步骤:
1 申请资源;
2 使用资源;
3 释放资源。
第一步和第二步缺一不可,因为资源必须要申请才能使用的,使用完成以后,必须要释放,如果不释放的话,就会造成资源泄漏。
一个最简单的例子:
#include <iostream>
int main() {
int* testArray = new int[10];
// here do something ...
delete[] testArray;
return 0;
}但是如果程序很复杂的时候,需要为所有的new 分配的内存delete掉,导致极度臃肿,效率下降,更可怕的是,程序的可理解性和可维护性明显降低了,当操作增多时,处理资源释放的代码就会越来越多,越来越乱。如果某一个操作发生了异常而导致释放资源的语句没有被调用,怎么办?这个时候,RAII机制就可以派上用场了。
如何使用RAII:
当我们在一个函数内部使用局部变量,当退出了这个局部变量的作用域时,这个变量也就被销毁了;当这个变量是类对象时,这个时候,就会自动调用这个类的析构函数,而这一切都是自动发生的,不要程序员显示的去调用完成。这个也太好了,RAII就是这样去完成的。
由于系统的资源不具有自动释放的功能,而C++中的类具有自动调用析构函数的功能。如果把资源用类进行封装起来,对资源操作都封装在类的内部,在析构函数中进行释放资源。当定义的局部变量的生命结束时,它的析构函数就会自动的被调用,如此,就不用程序员显示的去调用释放资源的操作了。
例1
不使用RAII(没有使用类的思想)的代码如下:
#include <iostream>
bool OperationA(){return false;}
bool OperationB(){return true;}
int main() {
int* testArray = new int[10];
if (!OperationA()) {
delete[] testArray;
testArray = NULL;
return 0;
}
if (!OperationB()) {
delete[] testArray;
testArray = NULL;
return 0;
}
delete[] testArray;
testArray = NULL;
return 0;
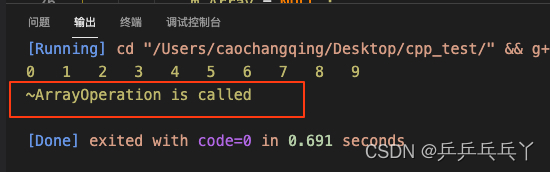
} 使用RAII机制(类的思想)的代码:
#include <iostream>
class ArrayOperation {
public :
ArrayOperation() {
m_Array = new int[10];
}
void InitArray() {
for (int i = 0; i < 10; ++i) {
*(m_Array + i) = i;
}
}
void ShowArray() {
for (int i = 0; i <10; ++i) {
std::cout << m_Array[i] << "\t";
}
std::cout << "\n";
}
~ArrayOperation() { // 通过class对象的析构函数的自动调用实现RAII
std::cout << "~ArrayOperation is called\n";
if (m_Array != NULL ) {
delete[] m_Array;
m_Array = NULL ;
}
}
private :
int* m_Array;
};
int main() {
ArrayOperation arrayOp;
arrayOp.InitArray();
arrayOp.ShowArray();
return 0;
}
例2
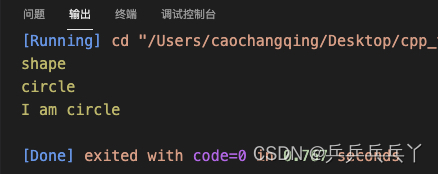
不使用RAII(没有使用类的思想)的代码如下:
#include <iostream>
namespace st{
enum shape_type{
circle,
triangle,
rectangle
};
}
class shape{
public:
shape(){std::cout << "shape\n";}
virtual void print(){std::cout << "I am shape\n";}
virtual ~shape(){}
};
class circle : public shape{
public:
circle(){std::cout << "circle\n";}
void print(){std::cout << "I am circle\n";}
};
class triangle : public shape{
public:
triangle(){std::cout << "triangle\n";}
void print(){std::cout << "I am triangle\n";}
};
class rectangle : public shape{
public:
rectangle(){std::cout << "rectangle\n";}
void print(){std::cout << "I am rectangle\n";}
};
shape* create_shape(st::shape_type type){
switch (type){
case st::circle:
return new circle();
case st::triangle:
return new triangle();
case st::rectangle:
return new rectangle();
}
}
int main(){
shape* c = create_shape(st::circle);
c->print();
delete c; // 手动释放指针
return 0;
}
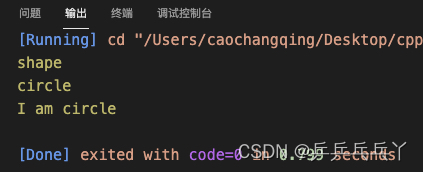
使用RAII机制(类的思想)的代码:
#include <iostream>
namespace st{
enum shape_type{
circle,
triangle,
rectangle
};
}
class shape{
public:
shape(){std::cout << "shape\n";}
virtual void print(){std::cout << "I am shape\n";}
virtual ~shape(){}
};
class circle : public shape{
public:
circle(){std::cout << "circle\n";}
void print(){std::cout << "I am circle\n";}
};
class triangle : public shape{
public:
triangle(){std::cout << "triangle\n";}
void print(){std::cout << "I am triangle\n";}
};
class rectangle : public shape{
public:
rectangle(){std::cout << "rectangle\n";}
void print(){std::cout << "I am rectangle\n";}
};
shape* create_shape(st::shape_type type){
switch (type){
case st::circle:
return new circle();
case st::triangle:
return new triangle();
case st::rectangle:
return new rectangle();
}
}
// RAII ---------------------------------------
class shape_wrapper{
public:
shape_wrapper(shape* sp) : sPtr(sp){}
~shape_wrapper(){delete sPtr;}
shape* get(){return sPtr;}
private:
shape* sPtr;
};
void foo(){
shape_wrapper sw(create_shape(st::circle));
sw.get()->print();
}
int main(){
foo();
return 0;
}
⑧ 右值引用(&&)
右值可以看作程序运行中的临时结果,右值引用可以避免复制提高效率。
例1
#include <iostream>
struct Foo {
~Foo() {std::cout << "destruction" << std::endl;}
};
Foo FooFactory() {
return Foo();
}
int main() {
std::cout << "before copy constructor...\n";
Foo foo1 = FooFactory();
std::cout << "after copy constructor...\n";
// 引用右值,避免生成新对象
Foo&& foo2 = FooFactory();
std::cout << "life time ends!\n";
return 0;
}用clang编译器编译上述代码, 运行结果如下:
before copy constructor...
destruction
destruction
after copy constructor...
destruction
life time ends!
destruction
destruction从输出结果看,第二种写法少了一次destruction输出。这意味着通过右值引用(&&),foo2直接引用FooFactory返回的对象,避免了对象复制。
⑨
(1)内存空间配置器allocator
C++内存空间配置器allocator_allocator<>_物随心转的博客-CSDN博客
(2)new操作符(new operator)与 operator new、placement new
new与operator new_huang714的博客-CSDN博客
1)new操作符调用operator new
- 你想在堆上建立一个对象,应该用new操作符。它既分配内存又为对象调用构造函数。
- 假设你只想分配内存,就应该调用operator new函数;它不会调用构造函数。
- 假设你想定制自己的在堆对象被建立时的内存分配过程,你应该写你自己的operator new函数。然后使用new操作符,new操作符会调用你定制的operator new。
// 操作符operator new将返回一个指针,指向一块足够容纳一个string类型对象的内存
// 就象malloc一样,operator new的职责仅仅是分配内存
void* rawMemory = operator new(sizeof(string));
string* ps = static_cast<string*>(rawMemory); // 使ps指针指向新的对象2)placement new(定位new)是一种特殊的operator new,作用于一块已分配但未处理或未初始化的raw内存。
placement new就是在用户指定的内存位置上(这个内存是已经预先分配好的)构建新的对象,因此这个构建过程不需要额外分配内存,只需要调用对象的构造函数在该内存位置上构造对象即可。
//先分配一对内存
int* buff = new int;
memset(buff,0,sizeof(int));
//此处new的placement new,在buff的内存上构造int对象,不需要分配额外的内存
int *p = new (buff)int(3);
std::cout << *p << std::endl; //3(3)new与::new 区别
普通的new运算符是在类级别实现的,可以被覆盖和替换。而::new是在全局级别实现的,不能被覆盖。
(4)移除类型中的引用 remove_reference
int main(){
int a = 3;
int &r = a;
// decltype(r)得到int&
std::remove_reference<decltype(r)>::type d; // 等价于 int d;
d = 6;
std::cout << d;
}
(5)=delete 用于防止某个函数被调用
1)防止隐式转换
2)希望类不能被拷贝(之前的做法是把类的构造函数定义为private)
#include <iostream>
#include <cstdio>
class TestClass{
public:
void func(int data) { printf("data: %d\n", data); }
};
int main(){
TestClass t;
t.func(99);
t.func(99.99);
return 0;
}
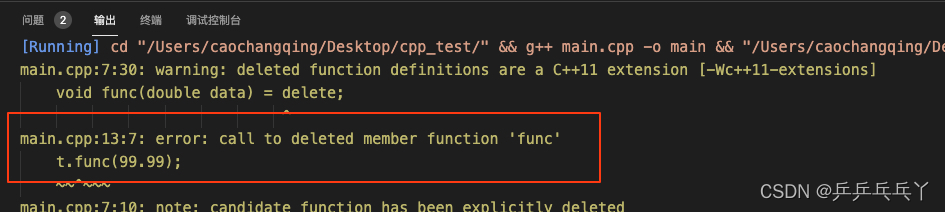
这是因为隐式转换,把double类型的99.99转换为int类型的99导致的。若想防止隐式转换:
#include <iostream>
#include <cstdio>
class TestClass{
public:
void func(int data) { printf("data: %d\n", data); }
void func(double data) = delete;
};
int main(){
TestClass t;
t.func(99);
t.func(99.99);
return 0;
}
(6)#ifdef 与 #if defined 对比
#ifdef vs #if defined 的差异_#ifdef和#if defined_Data-Mining的博客-CSDN博客
当我们想要判断单个宏是否被定义时,使用 #ifdef 和 #if defined 的效果是一样的,但是当我们要判断复杂的条件和情况时,就只能用 #if defined。其实,#ifdef 是 #if defined 的简化版,只是判断单个宏是否被定义时可以用 #ifdef,其它复杂条件和情况可以用 #if defined。尽管, #ifdef 和 #if defined 两个预处理命令有很多不一样的地方,但是在使用过程,它们有一个共同需要注意的地方就是要搭配 #endif 预处理命令一起使用。
(7)Linux信号量semaphore
Linux信号量semaphore_linux semaphore_Strange_Head的博客-CSDN博客
信号量(Semaphore)是一种用于线程同步和进程间同步的机制。它是一种整数值,用于控制访问共享资源的线程数量。
信号量有两种操作:V(sem_post)操作和 P(sem_wait)操作。V操作会将信号量的值加1,P操作会将信号量的值减1。当信号量的值为0时,再执行P操作就会阻塞,直到信号量的值变为正数。
信号量可以用于实现各种同步机制,如生产者和消费者模型,读者和写者模型等等。
semaphore.h中的一些常用函数包括:
sem_init():初始化信号量
sem_wait():执行P操作,即将信号量的值减1
sem_post():执行V操作,即将信号量的值加1
sem_getvalue():获取信号量的当前值
sem_destroy():销毁信号量
例1
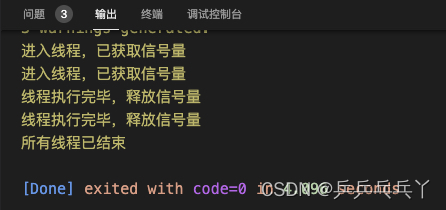
#include <iostream>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
sem_t sem; // 定义信号量
void* thread_function(void*){
sem_wait(&sem); // 等待信号量
std::cout << "进入线程,已获取信号量\n";
sleep(3); // 模拟线程执行的操作
std::cout << "线程执行完毕,释放信号量\n";
sem_post(&sem);
}
int main(){
// 初始化信号量,第一个参数为信号量对象,第二个参数为0表示进程内使用,1表示进程间使用,第三个参数为信号量的初始值
sem_init(&sem, 0, 1);
pthread_t thread1, thread2;
pthread_create(&thread1, nullptr, thread_function, nullptr);
pthread_create(&thread2, nullptr, thread_function, nullptr);
pthread_join(thread1, nullptr); // 等待线程结束
pthread_join(thread2, nullptr);
std::cout << "所有线程已结束\n";
sem_destroy(&sem); // 销毁信号量
return 0;
}
(8)std::thread与pthread对比
std::thread是C++11接口,使用时需要包含头文件#include <thread>,编译时需要支持c++11标准。thread中封装了pthread的方法,所以也需要链接pthread库 。
pthread是C++98接口且只支持Linux,使用时需要包含头文件#include <pthread.h>,编译时需要链接pthread库。
std::thread对比于pthread的优缺点:
优点
1. 简单,易用
2. 跨平台,pthread只能用在POSIX系统上(其他系统有其独立的thread实现)
3. 提供了更多高级功能,比如future
4. 更加C++(跟匿名函数,std::bind,RAII等C++特性更好的集成)
缺点
1. 没有RWlock。有一个类似的shared_mutex,不过它属于C++14,你的编译器很有可能不支持。
2. 操作线程和Mutex等的API较少。毕竟为了跨平台,只能选取各原生实现的子集。如果你需要设置某些属性,需要通过API调用返回原生平台上的对应对象,再对返回的对象进行操作。
(9)条件变量 condition_variable
C++条件变量使用详解_c++ 条件变量_瞻邈的博客-CSDN博客
1)
在C++11中,我们可以使用条件变量(condition_variable)实现多个线程间的同步操作;当条件不满足时,相关线程被一直阻塞,直到某种条件出现,这些线程才会被唤醒。
为了防止竞争,条件变量的使用总是和一个互斥锁结合在一起;通常情况下这个锁是std::mutex,并且管理这个锁只能是 std::unique_lockstd::mutex RAII模板类。
上面提到的两个步骤,分别是使用以下两个方法实现:
等待条件成立使用的是condition_variable类成员wait,wait_for 或 wait_until。
给出信号使用的是condition_variable类成员notify_one或者notify_all函数。
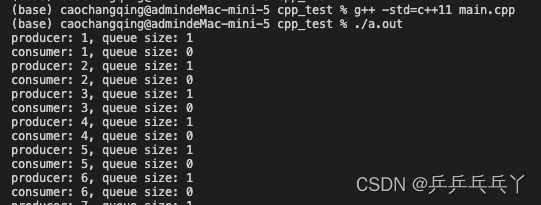
例1 生产者消费者问题
#include <iostream>
#include <condition_variable>
#include <mutex>
#include <thread>
#include <deque>
class PCModle{
public:
PCModle() : work_(true), max_num(10), next_index(0){}
// 生产者线程
void producer_thread(){
while (work_){
std::this_thread::sleep_for(std::chrono::milliseconds(500));
// 加锁
std::unique_lock<std::mutex> lk(cvMutex);
// 当队列未满时,继续添加数据
cv.wait(lk, [this](){
return this->data_deque.size() <= this->max_num;
}); // return false才会wait
next_index++;
data_deque.push_back(next_index);
std::cout << "producer: " << next_index << ", queue size: "
<< data_deque.size() << "\n";
// 唤醒其他线程
cv.notify_all();
}
}
// 消费者线程
void consumer_thread(){
while (work_){
// 加锁
std::unique_lock<std::mutex> lk(cvMutex);
// 检测条件是否达成
cv.wait(lk, [this](){
return !this->data_deque.empty();
});
// 互斥操作,消息数据
int data = data_deque.front();
data_deque.pop_front();
std::cout << "consumer: " << data << ", queue size: "
<< data_deque.size() << "\n";
// 唤醒其他线程
cv.notify_all();
}
}
private:
bool work_;
std::mutex cvMutex;
std::condition_variable cv;
std::deque<int> data_deque; // 缓存区
size_t max_num; // 缓存区最大数目
int next_index; // 数据
};
int main(){
PCModle obj;
std::thread ProducerThread = std::thread(&PCModle::producer_thread, &obj);
std::thread ConsumerThread = std::thread(&PCModle::consumer_thread, &obj);
ProducerThread.join();
ConsumerThread.join();
return 0;
}
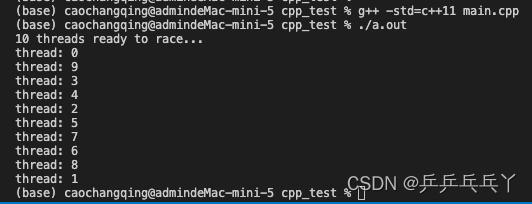
例2 多线程抢占
报错如下:error: calling a private constructor of class 'std::__1::thread'
#include <iostream>
#include <mutex>
#include <thread>
#include <condition_variable>
std::mutex m_mutex;
std::condition_variable cv;
void print_id(int i){
// 首先执行到这一句的第一个线程会lk.lock(), 其他线程则会卡在这一句;
std::unique_lock<std::mutex> lk(m_mutex);
cv.wait(lk);
std::cout << "thread: " << i << "\n";
}
void go(){
std::unique_lock<std::mutex> lk(m_mutex);
cv.notify_all();
}
int main(){
std::thread threads[10];
for(int i = 0; i < 10; i++){
threads[i] = std::thread(print_id, i);
}
std::cout << "10 threads ready to race...\n";
go();
for(auto threadi : threads){ // 报错:必须auto&
threadi.join();
}
return 0;
}
正解如下:
#include <iostream>
#include <mutex>
#include <thread>
#include <condition_variable>
std::mutex m_mutex;
std::condition_variable cv;
void print_id(int i){
// 首先执行到这一句的第一个线程会lk.lock(), 其他线程则会卡在这一句;
std::unique_lock<std::mutex> lk(m_mutex);
cv.wait(lk);
std::cout << "thread: " << i << "\n";
}
void go(){
std::unique_lock<std::mutex> lk(m_mutex);
cv.notify_all();
}
int main(){
std::thread threads[10];
for(int i = 0; i < 10; i++){
threads[i] = std::thread(print_id, i);
}
std::cout << "10 threads ready to race...\n";
go();
for(auto& threadi : threads){
threadi.join();
}
return 0;
}
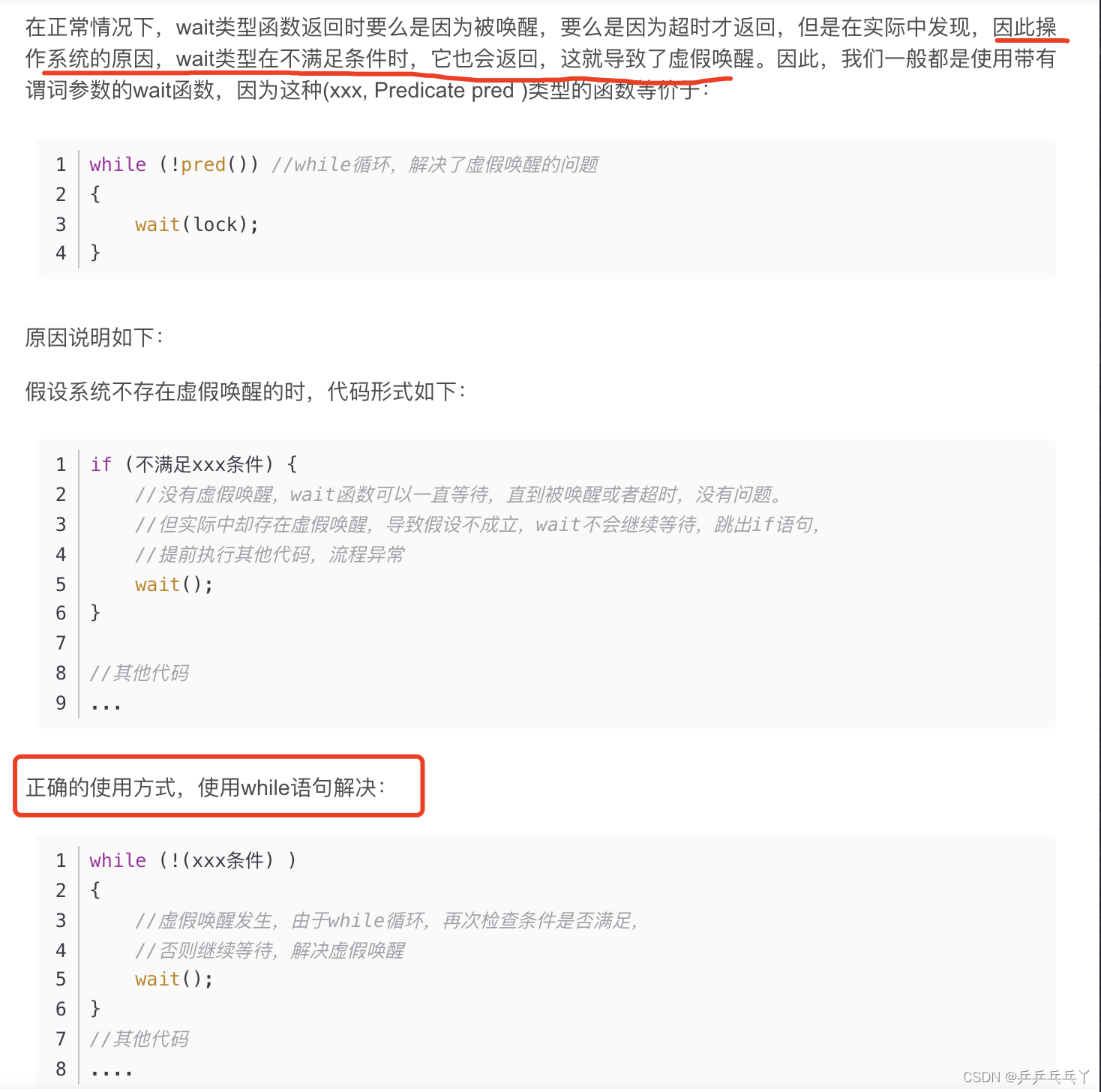
2)虚假唤醒与解决
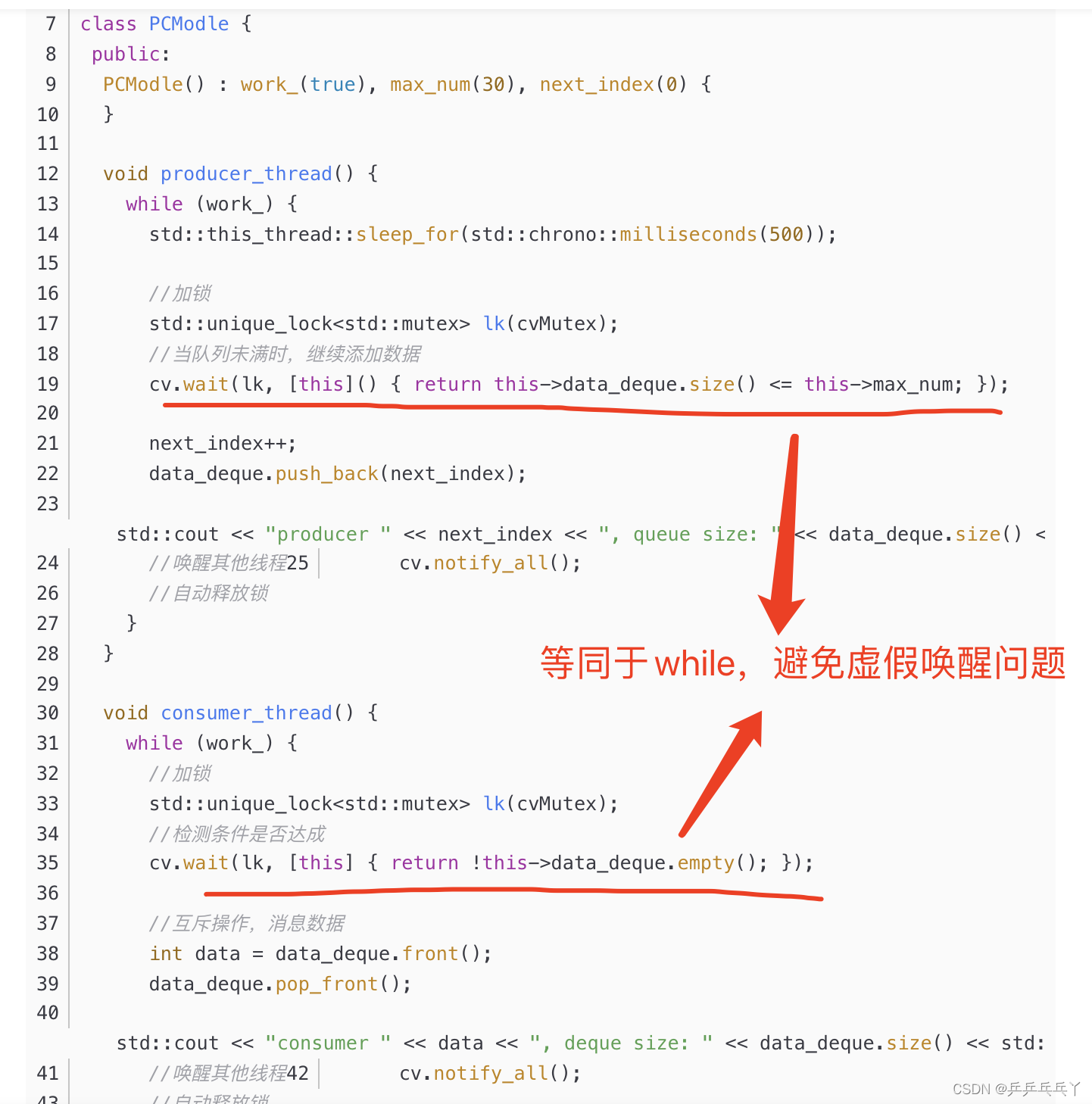
(10)对私有构造析构函数的思考:new一个类对象vs直接创建类对象
【C++学习】对私有构造析构函数的思考:new一个类对象vs直接创建类对象_私有析构函数_xuanweiace的博客-CSDN博客
首先我们要知道:
new的类对象需要手动delete。且使用堆空间。且只能用指针接收。
直接创建的类对象创建在栈中(或说堆栈)。不需要手动delete,随着生存周期的结束(如所在的函数return了)而释放,和堆栈空间一起释放了。
把析构函数定义为私有的,就阻止了用户在类域外对析构函数的使用。这表现在如下两个方面:
- 禁止用户对此类型的变量进行定义,即禁止在栈内存空间内创建此类型的对象。要创建对象,只能用 new 在堆上进行。
- 禁止用户在程序中使用 delete 删除此类型对象。对象的删除只能在类内实现,也就是说只有类的实现者才有可能实现对对象的 delete,用户不能随便删除对象。如果用户想删除对象的话,只能按照类的实现者提供的方法进行。
可见,这样做之后大大限制了用户对此类的使用。一般来说不要这样做;通常这样做是用来达到特殊的目的,比如在singleton(单例模式)的实现上。
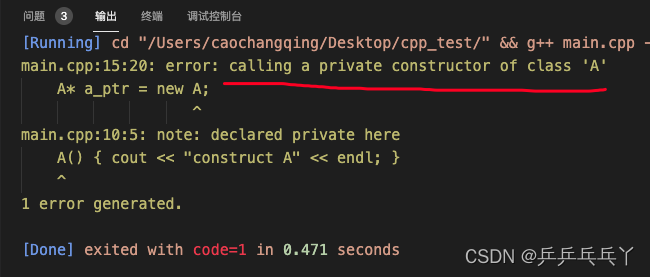
例1
报错如下:
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
private:
A() { cout << "construct A" << endl; }
~A() { cout << "xigou A" << endl; }
};
int main() {
A* a_ptr = new A;
return 0;
}new A 会调用构造函数A(),但其定义为私有的了
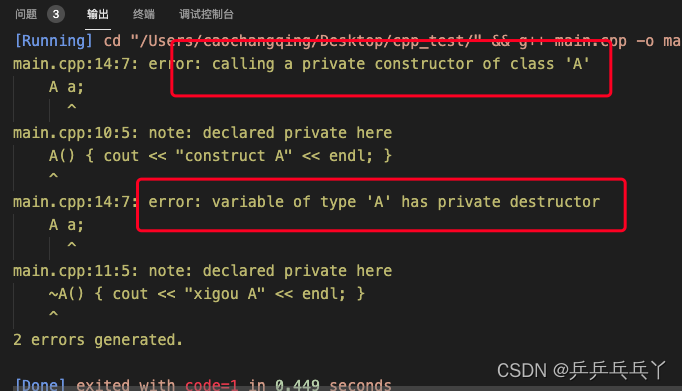
例2
报错如下
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
private:
A() { cout << "construct A" << endl; }
~A() { cout << "xigou A" << endl; }
};
int main() {
A a;
return 0;
}A a 创建类的对象会调用构造A()与析构~A(),但二者都是私有的
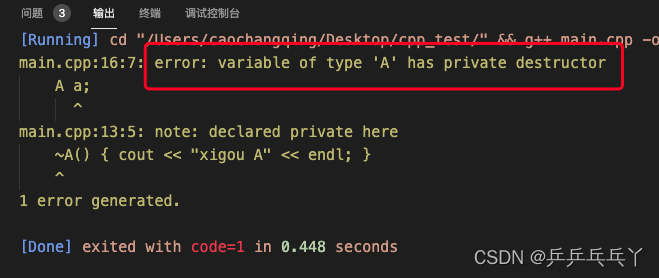
例3
报错如下:
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
public:
A() { cout << "construct A" << endl; }
private:
~A() { cout << "xigou A" << endl; }
};
int main() {
A a;
return 0;
}构造是公有的,可以。但析构是私有的,不行
例4
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
public:
A() { cout << "construct A" << endl; }
private:
~A() { cout << "xigou A" << endl; }
};
int main() {
A* a_ptr = new A;
return 0;
}new A 只调用构造函数,但不会调用析构函数(因为new对象需手动释放),所以正确

例5
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
private:
A() { cout << "construct A" << endl; }
~A() { cout << "xigou A" << endl; }
};
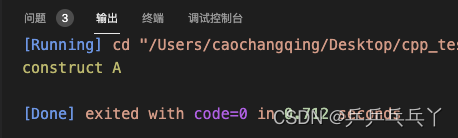
int main() {
A* a_ptr = A::getInstance();
return 0;
}
#include <iostream>
using namespace std;
class A {
public:
static A* getInstance() { return new A; }
void Distroy() { delete this; }
private:
A() { cout << "construct A" << endl; }
~A() { cout << "xigou A" << endl; }
};
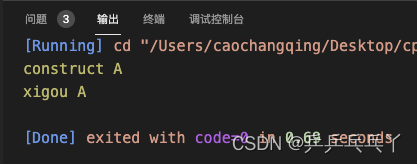
int main() {
A* a_ptr = A::getInstance();
a_ptr->Distroy(); // 这句没有也可以正常编译,因为对象是new出来的,所以需要手动delete
return 0;
}
⑩ 举例
(1)运算符重载举例
例1 ( )重载
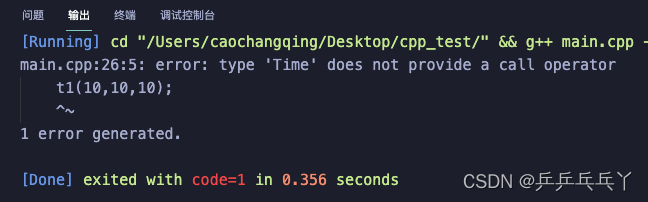
如下会报错:
#include <iostream>
using namespace std;
class Time{
private:
int hh,mm,ss;
public:
Time(int h=0,int m=0,int s=0):hh(h),mm(m),ss(s){}
void ShowTime(){
cout<<hh<<":"<<mm<<":"<<ss<<endl;
}
};
int main(){
Time t1(12,10,11);
t1.ShowTime();
t1(10,10,10);
t1.ShowTime();
return 0;
}
可修改如下:
#include <iostream>
using namespace std;
class Time{
private:
int hh,mm,ss;
public:
Time(int h=0,int m=0,int s=0):hh(h),mm(m),ss(s){}
void operator()(int h,int m,int s) { // ()重载
hh=h;
mm=m;
ss=s;
}
void ShowTime(){
cout<<hh<<":"<<mm<<":"<<ss<<endl;
}
};
int main(){
Time t1(12,10,11);
t1.ShowTime();
t1(10,10,10);
t1.ShowTime();
t1.operator()(23,20,34);
t1.ShowTime();
return 0;
}
例2 ++或--重载
1)
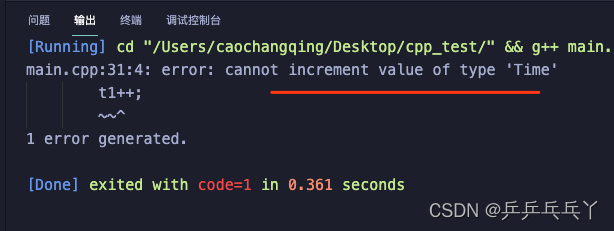
如下会报错:
#include <iostream>
class Time{
public:
Time(int h = 0, int m = 0, int s = 0) : hour(h), minute(m), second(s){}
Time operator++(); // 只能前置
void showTime(){std::cout << "当前时间:" << hour << ":" << minute << ":" << second << "\n";}
private:
int hour, minute, second;
};
Time Time::operator++(){
second++;
if(second == 60){
second = 0;
minute++;
if(minute == 60){
minute = 0;
hour++;
if(hour == 24){
hour = 0;
}
}
}
return *this;
}
int main(){
Time t1(23, 59, 59);
t1++; // ++后置会报错
t1.showTime();
return 0;
}
可修改如下:
#include <iostream>
class Time{
public:
Time(int h = 0, int m = 0, int s = 0) : hour(h), minute(m), second(s){}
Time operator++(); // 只能前置
void showTime(){std::cout << "当前时间:" << hour << ":" << minute << ":" << second << "\n";}
private:
int hour, minute, second;
};
Time Time::operator++(){
second++;
if(second == 60){
second = 0;
minute++;
if(minute == 60){
minute = 0;
hour++;
if(hour == 24){
hour = 0;
}
}
}
return *this;
}
int main(){
Time t1(23, 59, 59);
++t1;
t1.showTime();
return 0;
} 
另有:
#include <iostream>
class Time{
public:
Time(int h = 0, int m = 0, int s = 0) : hour(h), minute(m), second(s){}
Time operator++(); // 只能前置
Time operator++(int); // 后置(形参只能是int)
void showTime(){std::cout << "当前时间:" << hour << ":" << minute << ":" << second << "\n";}
private:
int hour, minute, second;
};
Time Time::operator++(){
second++;
if(second == 60){
second = 0;
minute++;
if(minute == 60){
minute = 0;
hour++;
if(hour == 24){
hour = 0;
}
}
}
return *this;
}
Time Time::operator++(int){
Time time = *this;
++(*this); // 此处的++是Time operator++()
return time;
}
int main(){
Time t1(23, 59, 59);
++t1; // 此处的++是Time operator++()
t1.showTime();
++t1;
t1.showTime();
t1++; // 此处的++是Time operator++(int)
t1.showTime();
return 0;
}
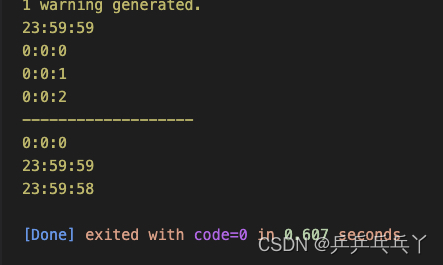
2)
//设计一个时间类Time,它能够完成秒钟的自增运算。
#include<iostream>
class Time{
public:
Time(int h, int m, int s);
Time operator++(); // 只能前置
Time operator++(int); // 后置(形参只能是int)
// 以友元方式重载运算符时,形参列表中至少有一个参数必须是自定义数据类型
friend Time operator--(Time& t); // 只能前置
friend Time operator--(Time& t, int); // 后置
void display();
private:
int hour, minute, second;
};
Time::Time(int h, int m, int s){
hour = h;
minute = m;
second = s;
if(hour >= 24){
hour = 0;
}
if(minute >= 60){
minute = 0;
}
if(second >= 60){
second = 0;
}
}
Time Time::operator++(){
++second;
if(second >= 60){
second = 0;
++minute;
if(minute >= 60){
minute = 0;
++hour;
if(hour >= 24){
hour = 0;
}
}
}
return *this;
}
Time Time::operator++(int){
Time time = *this;
++(*this); // Time operator++()
return time;
}
Time operator--(Time& t){
--t.second;
if(t.second < 0){
t.second = 59;
--t.minute;
if(t.minute < 0){
t.minute = 59;
--t.hour;
if(t.hour < 0){
t.hour = 23;
}
}
}
}
Time operator--(Time& t, int){
return --t; // friend Time operator--(Time& t)
}
void Time::display(){
std::cout << hour << ":" << minute << ":" << second << "\n";
}
int main(){
Time t1(23, 59, 59);
t1.display();
++t1; // 隐式调用 Time operator++()
t1.display();
t1.operator++(); // 显式调用 Time operator++()
t1.display();
t1++; // 隐式调用 Time operator++(int i)
t1.display();
std::cout << "-------------------\n";
Time t2(24, 60, 60);
t2.display();
--t2;
t2.display();
t2--;
t2.display();
return 0;
}
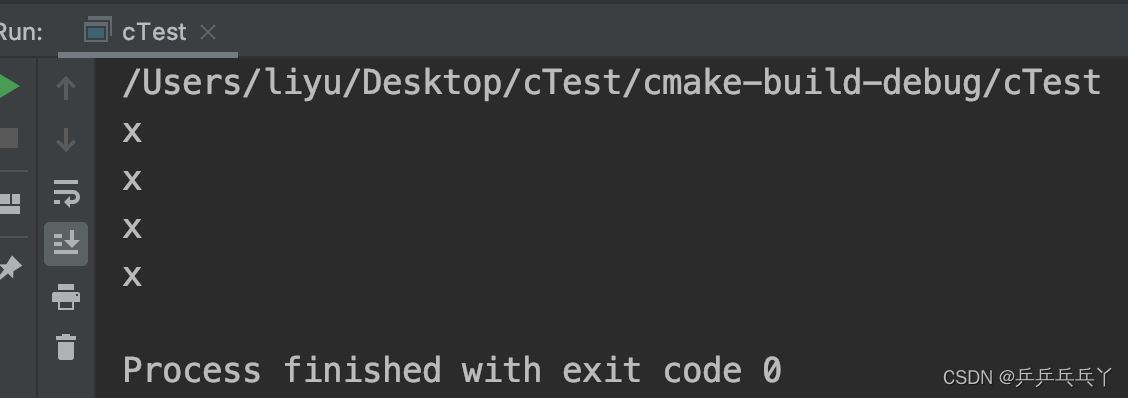
例3 =重载
#include <iostream>
using namespace std;
class X{
public:
X& operator=(const X& x){
std::cout << "x\n";
return *this;
};
};
int main ()
{
X x1, x2, x3;
x1 = x2;
x1.operator=(x3);
x1 = x2 = x3;
return 0;
}
例4 类运算符重载
//有复数类Complex,利用运算符重载实现复数的加、减、乘、除等复数运算。
#include<iostream>
class Complex{
public:
Complex(double R = 0, double I = 0) : r(R), i(I){};
Complex operator+(Complex b);
Complex operator-(Complex b);
Complex operator*(Complex b);
Complex operator/(Complex b);
void display();
private:
double r, i;
};
Complex Complex::operator+(Complex b){
return Complex(r+b.r, i+b.i);
}
Complex Complex::operator-(Complex b){
return Complex(r-b.r, i-b.i);
}
Complex Complex::operator*(Complex b){
return Complex(r*b.r-i*b.i, r*b.i+i*b.r);
}
Complex Complex::operator/(Complex b){
double x = 1 / (b.r*b.r+b.i*b.i);
return Complex(x*(r*b.r+i*b.i), x*(i*b.r-r*b.i));
}
void Complex::display(){
std::cout << r;
if(i > 0) std::cout << "+";
if(i != 0) std::cout << i << "i\n";
}
int main() {
Complex c1(1,2), c2(3,4), c3, c4, c5, c6, a, b(2,3);
a = b + 2;
// a = 2 + b; // 错
a.display();
c3 = c1 + c2;
c3.display();
c4 = c1 - c2;
c4.display();
c5 = c1 * c2;
c5.display();
c6 = c1 / c2;
c6.display();
return 0;
}
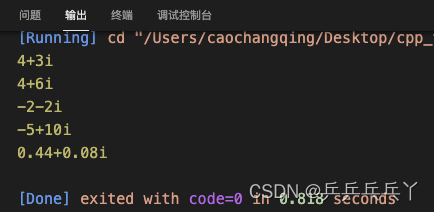
以上类运算符重载的最大问题是参数顺序问题(a=b+2可以,但a=2+b就不行),可以通过友元运算符重载来解决这个问题:
#include<iostream>
class Complex{
public:
Complex(double R = 0, double I = 0) : r(R), i(I){};
Complex operator+(Complex a);
// 以友元方式重载运算符时,形参列表中至少有一个参数必须是自定义数据类型
friend Complex operator+(Complex a, double b); // 等价于Complex operator+(Complex a),只能实现顺序a = b + 2
friend Complex operator+(double b, Complex a); // 只能实现顺序a = 2 + b
void display();
private:
double r, i;
};
Complex Complex::operator+(Complex a){
return Complex(r+a.r, i+a.i);
}
Complex operator+(Complex a, double b){
return Complex(a.r + b, a.i);
}
Complex operator+(double b, Complex a){
return Complex(a.r + b, a.i);
}
void Complex::display(){
std::cout << r;
if(i > 0) std::cout << "+";
if(i != 0) std::cout << i << "i\n";
}
int main() {
Complex a, b(2,3), c;
a = b + 2; // Complex operator+(Complex a) 或 friend Complex operator+(Complex a, double b)
a.display();
c = 8 + b; // friend Complex operator+(double b, Complex a)
c.display();
return 0;
}
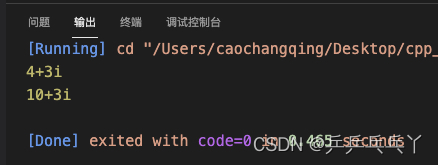
例5 字符串类的相关运算符重载
//设计一个字符串类String,通过运算符重载实现字符串的输入、输出以及+=、==、!=、<、>、>=、[ ]等运算。
#include <iostream>
#include <cstring>
class String{
public:
String(char* = "");
String& operator=(String& s){ // 赋值运算符=重载
length = s.length; // 长度赋值
std::strcpy(sPtr, s.sPtr); // 首地址赋值
return *this;
};
String& operator+=(String& s); // 字符串的连接 +=
bool operator==(String& s); // 字符串的相等比较 ==
bool operator!=(String& s); // 字符串的不等比较 !=
bool operator!(); // 判定字符串是否为空
bool operator<(String& s); // 字符串的小于比较 <
bool operator>(String& s); // 字符串的大于比较 >
bool operator>=(String& s); // 字符串的大于比较 >=
char& operator[](int); // 字符串的下标运算
~String(){};
private:
int length; //字符串长度
char* sPtr; //存放字符串的指针
void setString(char* s);
friend std::ostream& operator<<(std::ostream& os, String& s){ // 输出运算符<<重载
return os << s.sPtr;
}
friend std::istream& operator>>(std::istream& is, String& s){ // 输入运算符>>重载
return is >> s.sPtr;
}
};
String::String(char* s){
length = std::strlen(s);
sPtr = new char[std::strlen(s) + 1];
std::strcpy(sPtr, s);
}
String& String::operator+=(String& s){
length += s.length;
char* tmp = sPtr;
sPtr = new char[length + 1];
std::strcpy(sPtr, tmp);
std::strcat(sPtr, s.sPtr);
delete[] tmp;
return *this;
}
bool String::operator==(String& s){
return std::strcmp(sPtr, s.sPtr) == 0;
}
bool String::operator!=(String& s){
return !(*this == s);
}
bool String::operator!(){
return length == 0;
}
bool String::operator<(String& s){
return std::strcmp(sPtr, s.sPtr) < 0;
}
bool String::operator>(String& s) { return s < *this; } // 此处的<是bool operator<(String& s)
// bool String::operator>(String& s){ return *this > s; } // 错:无>的重载实现
bool String::operator>=(String& s){
return !(*this < s);
}
char& String::operator[](int idx){
return sPtr[idx];
}
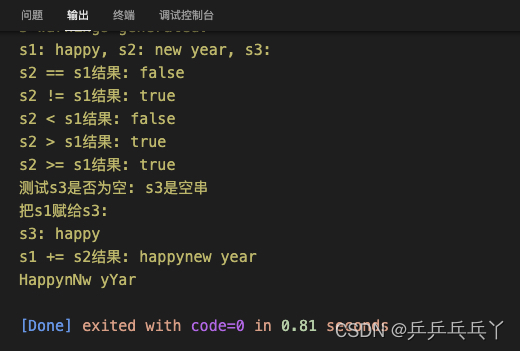
int main(){
String s1("happy"), s2("new year"), s3;
std::cout << "s1: " << s1 << ", s2: " << s2 << ", s3: " << s3 << "\n";
std::cout << "s2 == s1结果: " << (s2 == s1 ? "true" : "false") << "\n";
std::cout << "s2 != s1结果: " << (s2 != s1 ? "true" : "false") << "\n";
std::cout << "s2 < s1结果: " << (s2 < s1 ? "true" : "false") << "\n";
std::cout << "s2 > s1结果: " << (s2 > s1 ? "true" : "false") << "\n";
std::cout << "s2 >= s1结果: " << (s2 >= s1 ? "true" : "false") << "\n";
std::cout << "测试s3是否为空: ";
if(!s3){
std::cout << "s3是空串\n";
std::cout << "把s1赋给s3:\n";
s3 = s1; // String& operator=(String& s)
std::cout << "s3: " << s3 << "\n" ;
}
std::cout << "s1 += s2结果: ";
s1 += s2;
std::cout << s1 << "\n";
s1[0] = 'H';
s1[6] = 'N';
s1[10] = 'Y';
std::cout << s1 << "\n";
return 0;
}
(2)基类与派生类举例
#include <iostream>
class A {
int a;
public:
void setA(int x){ a=x; }
int getA(){ return a;}
};
class B:public A{
int b;
public:
void setB(int x){ b=x; }
int getB(){ return b;}
};
void f1(A a, int x){ a.setA(x); }
void f2(A *pA, int x){ pA->setA(x); }
void f3(A &rA, int x){ rA.setA(x); }
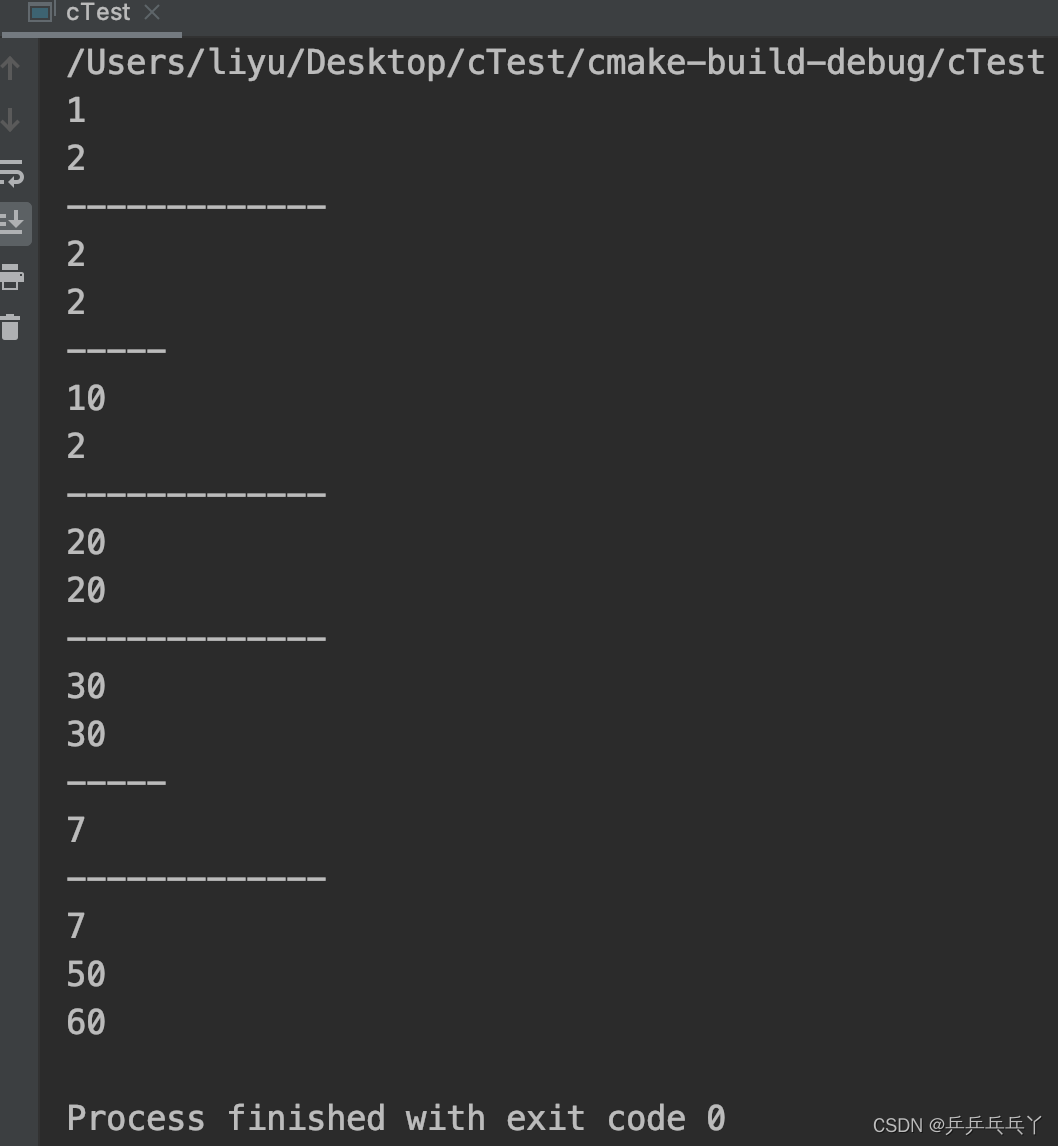
int main(){
A a1;
B b1;
a1.setA(1);
b1.setA(2);
std::cout << a1.getA() << "\n"; // 1
std::cout << b1.getA() << "\n"; // 2
std::cout << "-------------\n";
a1 = b1; // 把派生类对象赋值给基类对象
std::cout << a1.getA() << "\n"; // 2
std::cout << b1.getA() << "\n"; // 2
std::cout << "-----\n";
a1.setA(10);
std::cout << a1.getA() << "\n"; // 10
std::cout << b1.getA() << "\n"; // 2
std::cout << "-------------\n";
A* pA = &b1; // 把派生类对象的地址赋值给基类指针
pA->setA(20);
std::cout << pA->getA() << "\n"; // 20
std::cout << b1.getA() << "\n"; // 20
std::cout << "-------------\n";
A& ra = b1; // 用派生类对象初始化基类对象的引用
ra.setA(30);
std::cout << ra.getA() << "\n"; // 30
std::cout << b1.getA() << "\n"; // 30
std::cout << "-----\n";
b1.setA(7);
std::cout << b1.getA() << "\n"; // 7
std::cout << "-------------\n";
f1(b1, 40);
std::cout << b1.getA() << "\n"; // 7
f2(&b1, 50);
std::cout << b1.getA() << "\n"; // 50
f3(b1, 60);
std::cout << b1.getA() << "\n"; // 60
return 0;
}
例4 [ ]重载
如下会报错:
#include <iostream>
struct Person //职工基本信息的结构
{
double salary;
char* name;
};
class SalaryManage{
public:
SalaryManage(int Max = 0){
max = Max;
n = 0;
employ = new Person[max];
}
void display(){
for(int i = 0; i < n; i++){
std::cout << employ[i].name << " " << employ[i].salary << "\n";
}
}
private:
Person* employ; //存放职工信息的数组
int max; //数组下标上界
int n; //数组中的实际职工人数
};
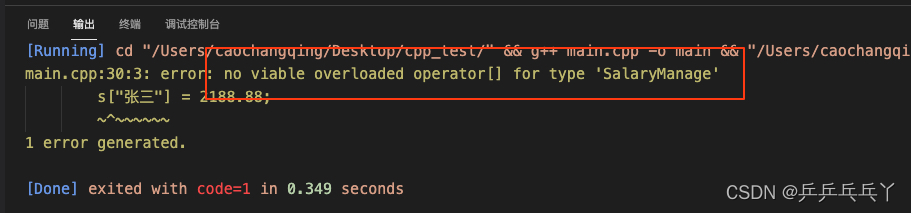
int main(){
SalaryManage s(3);
s["张三"] = 2188.88; // 错:[]没重载
s.display();
return 0;
}
可修改如下:
#include <iostream>
#include <cstring>
struct Person // 职工基本信息的结构
{
double salary;
char* name;
};
class SalaryManage{
public:
SalaryManage(int Max = 0){
max = Max;
n = 0;
employ = new Person[max];
}
void display(){
for(int i = 0; i < n; i++){
std::cout << employ[i].name << " " << employ[i].salary << "\n";
}
}
double& operator[](char* Name){ // 重载[],返回引用
std::cout << "00000000000\n";
Person* p;
for(p = employ; p < employ + n; p++){
std::cout << "111111111111111111\n";
// 如果employ数组的键(name)已有该Name,则值(salary)被覆盖
if(std::strcmp(p->name, Name) == 0){
std::cout << "22222222222222222\n";
return p->salary;
}
}
p = employ + n++;
std::cout << "44444444444\n";
p->name = new char[strlen(Name)+1]; // 必须有
std::cout << "55555555555\n";
std::strcpy(p->name, Name);
p->salary = 0;
return p->salary;
}
private:
Person* employ; // 存放职工信息的数组
int max; // 数组下标上界
int n; // 数组中的实际职工人数
};
int main(){
SalaryManage s(3);
s["张三"] = 1111;
std::cout << "-------------------------\n";
s["里斯"] = 2222;
std::cout << "-------------------------\n";
s["王无"] = 3333;
std::cout << "-------------------------\n";
s["王无"] = 4444;
std::cout << "-------------------------\n";
s.display();
return 0;
}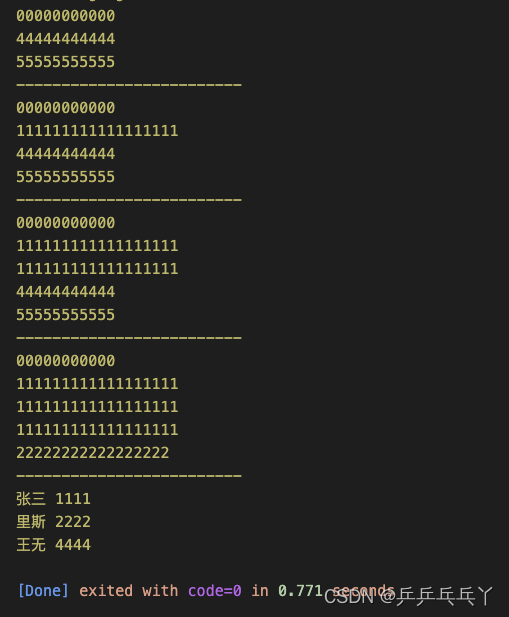
(3)继承访问权限举例 (类内部、类的使用者、类的派生类成员)
例1 保护成员
/*
基类中protected的成员
类内部:可以访问
类的使用者:不能访问
类的派生类成员:可以访问
*/
#include<iostream>
class B
{
private:
int i;
protected:
int j;
public:
int k;
};
class D: public B
{
public:
void f()
{
// i=1; // 错: 派生类不可访问基类私有成员
j=2; //派生类可以访问基类保护成员
k=3;
}
};
int main()
{
B b;
// b.i=1; // 错: 私有成员,类的使用者不能访问
// b.j=2; // 错: 保护成员,类的使用者不能访问
b.k=3;
return 0;
}例2 保护继承
#include <iostream>
using namespace std;
class Base{
int x;
protected:
int getx(){ return x; }
public:
void setx(int n){ x=n; }
void showx(){ cout<<x<<endl; }
};
// 保护继承, 基类的public成员在派生类中会变成protected成员
class Derived:protected Base{
int y;
public:
void sety(int n){ y=n; }
void sety(){ y=getx();}
void showy(){ cout<<y<<endl; }
};
int main(){
Derived obj;
// obj.setx(10); //错误: 外部去使用保护成员的时候会报错,所以setx与showx访问错误
// obj.showx(); //错误
obj.sety(20);
obj.showy();
}
例3 私有继承
#include <iostream>
using namespace std;
class Base{
int x;
public:
void setx(int n){x=n;}
int getx(){return x;}
void showx(){cout<<x<<endl;}
};
// 私有继承, 基类的中的public成员在派生类中是private, private成员在派生类中不可访问
class derived:private Base{
int y;
public:
void sety(int n){y=n;}
void sety(){y=getx();}
void showy(){cout<<y<<endl;}
};
int main(){
derived obj;
// obj.setx(10); // 错
// obj.showx(); // 错
obj.sety(20);
obj.showy();
}
例4 虚拟继承
1)
#include<iostream>
using namespace std;
class A {
public:
void vf() {
cout<<"I come from class A"<<endl; }
};
class B: public A{};
class C: public A{};
class D: public B, public C{};
int main()
{
D d;
// d.vf (); // 错
return 0;
}
2)
#include<iostream>
using namespace std;
class A {
public:
void vf() {
cout<<"I come from class A"<<endl; }
};
class B: virtual public A{}; // 虚拟继承
class C: virtual public A{};
class D: public B, public C{};
int main()
{
D d;
d.vf (); // okay
return 0;
}
(4)抽象类举例
#include<iostream>
using namespace std;
// 抽象类
class Figure{
protected:
double x,y;
public:
void set(double i, double j){
x=i;y=j;
}
virtual void area()=0;
};
// 派生类
class Trianle:public Figure{
public:
void area(){
cout<<"三角形面积:"<<x*y*0.5<<endl;
}
};
class Rectangle:public Figure{
public:
void area(){
cout<<"这是矩形,它的面积是:"<<x*y<<endl;
}
};
int main()
{
// Figure f1; // 错:抽象类不能被实例化
Trianle t;
t.set(10,20);
Figure* pF = &t; // 定义抽象类指针
pF->area();
Rectangle r;
r.set(10,20);
pF = &r;
pF->area();
Rectangle& rR = r; // 定义抽象类引用
rR.set(20,20);
rR.area();
return 0;
}
(5)动态数组举例
#include<iostream>
int main() {
const char* s = "hello";
char* sPtr = new char[std::strlen(s) + 1];
std::strcpy(sPtr, s);
std::cout << "sPtr: " << sPtr;
return 0;
}















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









